


Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter (LEBERT)
论文翻译
作者:Wei Liu ,Wenming Xiao DAMO Academy, Alibaba Group 2021ACL
论文地址:https://aclanthology.org/2021.acl-long.454.pdf
Abstract
由于各自的优势,词典信息和预训练模型(如BERT)已被结合起来探索中文序列标注任务。然而,现有的方法仅通过浅层和随机初始化的序列层来融合词典特征,而没有将它们集成到BERT的底层。在本文中,我们提出了用于中文序列标注的Lexicon增强BERT(LEBERT),它通过Lexicon适配器层将外部Lexicon知识直接集成到BERT层中。与现有方法相比,我们的模型有助于在BERT的较低层进行深度词典知识融合。在包括命名实体识别、分词和词性标注在内的三项任务的十个中文数据集上的实验表明,LEBERT达到了最先进的结果。
1 Introduction
序列标注是NLP中的一项经典任务,为序列中的每个单元分配一个标签。众多重要语言处理任务可以转为词性标注(POS)、命名实体识别(NER)和文本分块。序列标注的SOTA结果已经通过神经网络方法获得。
由于中文句子中缺乏明确的词边界,中文序列标注更具挑战性。执行中文序列标注的一种方法是首先执行中文分词(CWS),然后再应用中文序列标注。然而,这种标注可能会受到CWS传播分割误差的影响。因此,一些方法直接在字符级别执行中文序列标注,这已被经验证明更有效。
最近有两种工作方式增强了基于字符的中文序列标注,第一种考虑将单词信息集成到基于字符的序列编码器中,以便可以显式地建模单词特征。第二种考虑了大规模预训练的上下文嵌入的集成,例如BERT,它已被证明可以捕获隐含的单词级句法和语义知识。
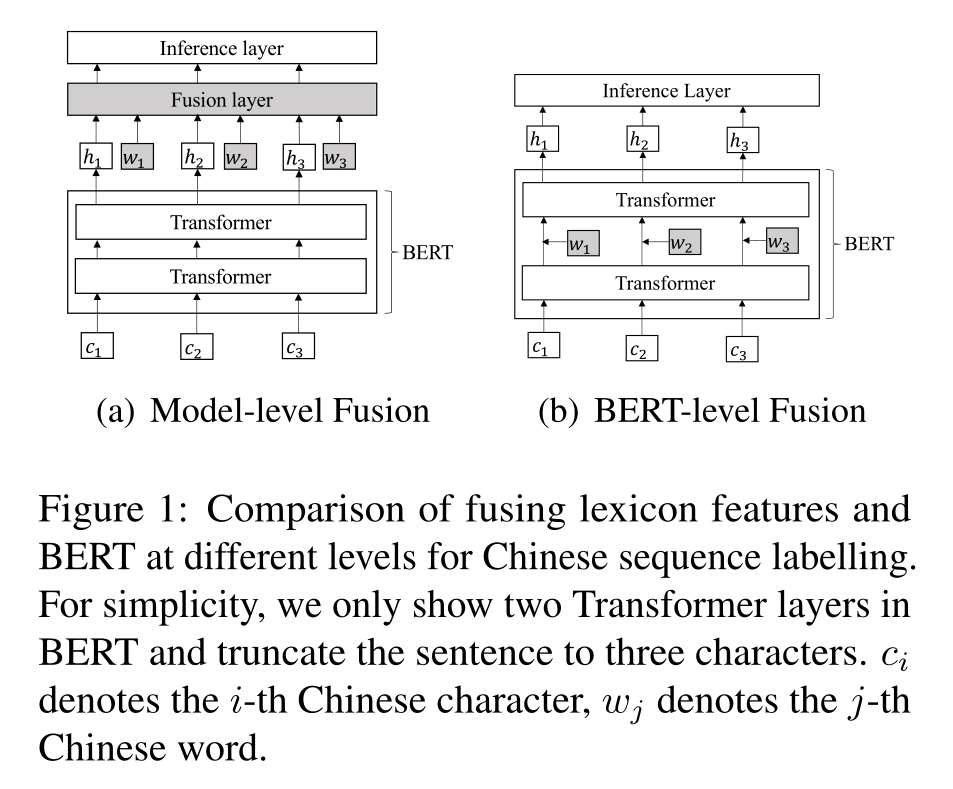
由于离散和神经表示的不同性质,这两条工作线是互补的。最近的工作考虑了词汇特征和BERT在中文NER、中文分词和中文词性标注中的结合。主要思想是将BERT和词汇特征的上下文表示集成到神经序列标注模型中(如图1(a)所示)。然而,这些方法没有充分利用BERT的表示能力,因为外部特征没有集成到底层。
受BERT适配器工作的启发,我们提出了Lexicon增强型BERT(LEBERT),以直接集成BERT的Transformer层之间的词典信息。具体而言,通过将中文句子与现有词典匹配,将其转换为特征词对序列。词典适配器被设计为使用字符到单词双线性注意机制为每个字符动态提取最相关的匹配单词。词典适配器应用于BERT中的相邻Transformers之间(如图1(b)所示),以便词典特征和BERT表示通过BERT内的多层编码器充分交互。我们在训练期间对BERT和词典适配器进行了微调,以充分利用单词信息,这与BERT适配器(它固定BERT参数)有很大不同。
我们研究了LEBERT在三个中文序列标注任务上的有效性,包括中文NER、中文分词和中文POS标注。在十个基准数据集上的实验结果表明了我们模型的有效性,在所有数据集上,每个任务都达到了最先进的性能。此外,我们提供了全面的比较和详细的分析,这从经验上证实了底层特征集成有助于跨度边界检测和跨度类型确定。
2 Related Work
我们的工作与现有的神经网络方法有关,这些方法使用词汇特征和预训练的模型来改进中文序列标注。
Lexicon-based.基于词典的模型旨在利用词典信息增强基于字符的模型。Zhang和Yang(2018)介绍了一种新的LSTM,用于对中文NER的字符和单词进行编码。通过在训练效率、模型退化、图结构和消除词典依赖性方面的努力,它得到了进一步的改进。词典信息也被证明有助于中文分词(CWS)和词性标注(POS)。Yang等人(2019)将lattice LSTM应用于CWS,显示出良好的性能。Zhao等人(2020)通过词汇增强的适应性注意改进了CWS的结果。Tian等人(2020b)提出多头注意力N-gram,增强了基于字符的中文POS标注模型。
Pre-trained Model-based. 基于Transformer的预训练模型,如BERT,在中文序列标注方面表现出了优异的性能。Yang(2019)只是在BERT上添加了一个softmax,在CWS上实现了最先进的性能。Meng等人(2019);Hu和V erberne(2020)表明,使用BERT中的字符特征的模型在中文NER和中文POS标注方面大大优于基于静态嵌入的方法。
Hybrid Model. 最近的工作试图通过利用各自的优势来整合词典和预先训练的模型。Ma等人(2020)连接了单独的特征、BERT表示和词汇信息,并将它们输入到中文NER的浅融合层(LSTM)中。Li等人(2020)提出了一种浅Flat-Lattice Transformer来处理字符-词图,其中融合仍然处于模型级别。类似地,字符N-gram特征和BERT向量被连接用于联合训练CWS和POS标注(Tian等人,2020b)。我们的方法与上述尝试将词汇信息与BERT相结合的方法一致。不同之处在于,我们将词汇整合到底层,从而允许BERT内部进行深入的知识交互。
此外,还开展了使用词典指导预训练的工作。ERNIE(Sun等人,2019a,b)利用实体级和单词级掩蔽以隐式方式将知识集成到BERT中。Jia等人(2020)提出了实体增强BERT,进一步使用特定领域的语料库和实体集以及精心设计的角色实体转换器对BERT进行预训练。ZEN(***等人,2019)使用多层N-gram编码器增强了中文BERT,但受限于N-gram词汇的小尺寸。与上述预训练方法相比,我们的模型使用适配器将词典信息集成到BERT中,这更有效,不需要原始文本或实体集。
BERT Adapter. BERT适配器(Houlsby等人,2019)旨在学习下游任务的任务特定参数。具体地说,他们在预先训练的模型的层之间添加适配器,并针对特定任务仅调整添加的适配器中的参数。Bapna和Firat(2019)将特定于任务的适配器层注入到神经网络机器翻译的预训练模型中。MAD-X(Pfeiffer等人,2020)是一种基于适配器的框架,能够实现对任意任务的高可移植性和参数效率传输。Wang等人(2020)提出KADAPTER,通过进一步的预训练将知识注入预训练模型。与它们类似,我们使用词典适配器将词典信息集成到BERT中。主要区别在于,我们的目标是在底层更好地融合词汇和BERT,而不是高效的预训练。为了实现这一点,我们对BERT的原始参数进行微调,而不是固定它们,因为直接将词典特征注入BERT会由于这两种信息之间的差异而影响性能。
3 Method
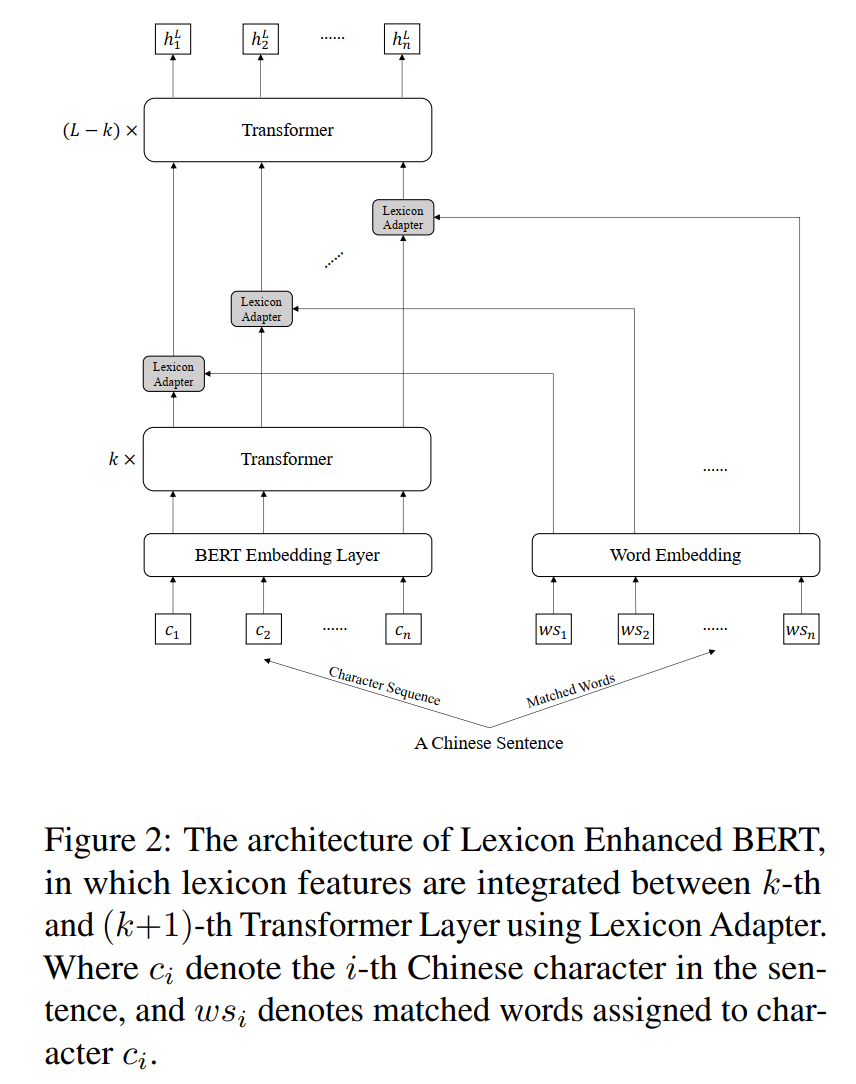
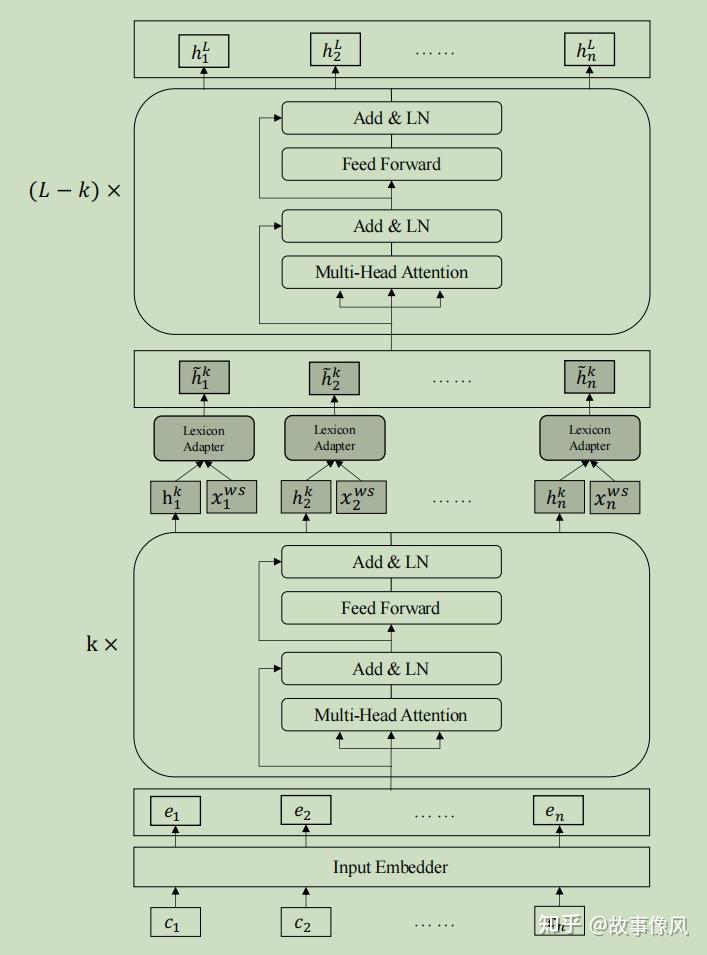
Lexicon增强BERT的主要架构如图2所示。与BERT相比,LEBERT有两个主要区别。首先,LEBERT将中文句子转换为字符-词对序列,同时将字符和词汇特征作为输入。其次,在Transformer层之间附加了一个词典适配器,使词典知识有效地集成到BERT中。
在本节中,我们描述:1)字符-单词对序列(第3.1节),它将单词自然地合并到字符序列中;2) 词典适配器(第3.2节),通过将外部词典特征注入BERT;3)Lexicon增强BERT,通过将Lexicon适配器应用于BERT(第3.3节)。
3.1 Char-Words Pair Sequence
中文句子通常表示为一个字符序列,只包含字符级特征。为了利用词典信息,我们将字符序列扩展为字符-词对序列。
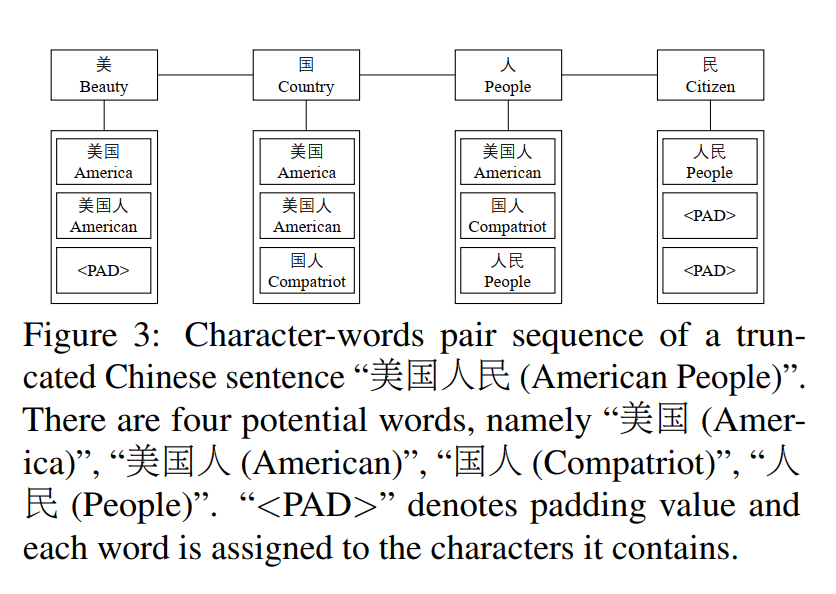
给定一个中文词典\(\mathbf{D}\)和一个具有\(n\)个字符\(s_c=\left\{c_1,c_2,…,c_n\right\}\)的中文句子,我们通过将字符序列与\(\mathbf{D}\)匹配来找出句子中的所有潜在单词。具体来说,首先基于\(\mathbf{D}\)创建一个Trie树结构,然后遍历句子的所有字符子序列,并将它们与Trie树匹配以获得所有潜在单词。例如,取截短的句子“美国人民 “,我们可以找出四个不同的单词,即”美国“,”美国人“,”国人“,”人民”。随后,对于每个匹配的单词,我们将其分配给它包含的字符。如图3所示,匹配的单词“美国“分配给字符”美” 和“国” 因为它们构成了那个词。最后,我们将每个字符与分配的单词配对,并将中文句子转换为字符-单词对序列,即\(s_{cw}=\left\{(c_1,ws_1),(c_2,ws_2),…,(c_n,ws_n)\right\}\),其中\(c_i\)表示句子中的第\(i\)个字符,\(ws_i\)表示分配给\(c_i\)的匹配单词。(我理解的是\(ws_i\)中单词数量是一个或多个)
3.2 Lexicon Adapter
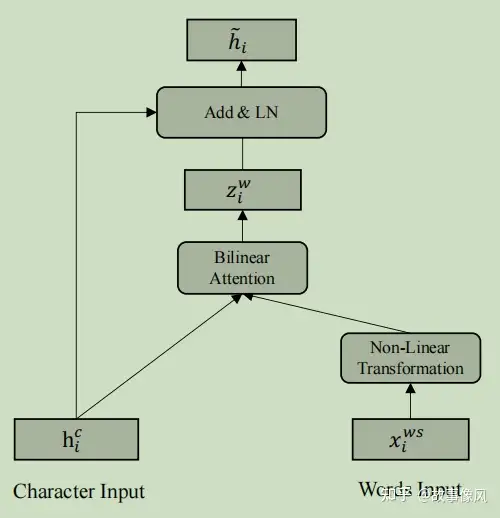
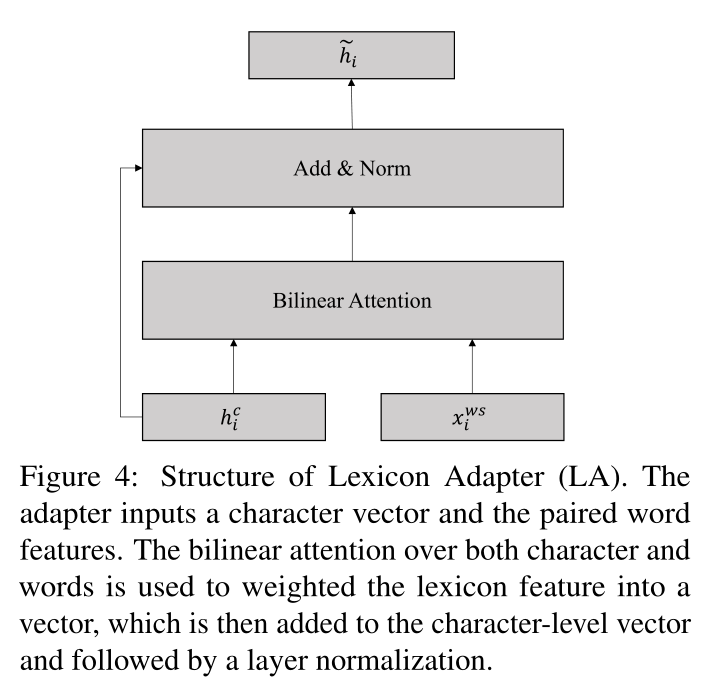
句子中的每个位置由两种类型的信息组成,即字符级和单词级特征。根据现有的混合模型,我们的目标是将词汇特征与BERT相结合。具体而言,受最近关于BERT适配器的研究(Houlsby等人,2019;Wang等人,2020)的启发,我们提出了一种新颖的词汇适配器(LA),如图4所示,它可以将词汇信息直接注入BERT。
Lexicon适配器接收两个输入,一个字符和成对的单词。对于字符-词对序列中的第\(i\)个位置,输入表示为\((h^c_i,x^{ws}_i)\),其中\(h^c_i\)是字符向量,BERT中某个transformer层的输出,\(x^{ws}_i=\left\{x^w_{i1},x^w_{i2},…,x^w_{im}\right\}\)是一组词嵌入。\(x^{ws}_i\)中的第\(j\)个单词表示如下:
此处\(\mathbf{e}^w\)是预训练的词嵌入查找表,\(w_{ij}\)是\(ws_i\)中第\(j\)个单词。
为了对齐这两种不同的表示,我们对单词向量应用非线性变换:
\(\mathbf{W}_{1} \in \mathbb R^{d_c\times d_w}\),\(\mathbf{W}_{2} \in \mathbb R^{d_c\times d_c}\),\(b_1\)和\(b_2\)是bias。\(d_w\)和\(d_c\)分别表示单词嵌入的维度和BERT的隐藏层大小。
如图3所示,每个字符与多个单词配对。然而,每个任务的贡献因单词而异。例如,对于中文POS标签,单词“美国“和”人民“比”美国人“和”国人”更重要,因为他们更符合现实。为了从所有匹配的单词中选出最相关的单词,我们引入了一种字符到单词的注意机制。
具体来说,我们将分配给第\(i\)个字符的所有\(v^w_{ij}\)表示为\(V_{i}=\left(v_{i 1}^{w}, \ldots, v_{i m}^{w}\right)\),其大小为\(\mathbb R^{m\times d_c}\),\(m\)是分配的字的总数。每个单词的相关性可以计算为:
\(\mathbf{W}_{attn}\in \mathbb R^{d_c\times d_c}\),因此,我们可以通过以下方式获得所有单词的加权和:
最后,通过以下方式将加权词典信息注入到字符向量中:
随后是dropout层和层归一化。
3.3 Lexicon Enhanced BERT
Lexicon增强型BERT(LEBERT)是Lexicon适配器(LA)和BERT的组合,其中LA应用于图2所示的BERT的某一层。具体而言,LA连接在BERT内的某些transformers之间,从而将外部词汇知识注入BERT。
给定一个具有\(n\)个字符\(s_c=\left\{c_1,c_2,…,c_n\right\}\)的中文句子,我们构建相应的字符-词对序列\(s_{cw}=\left\{(c_1,ws_1),(c_2,ws_2),…,(c_n,ws_n)\right\}\),如第3.1节所述。字符\(\left\{c_1,c_2,…,c_n\right\}\)首先被输入到输入嵌入器,该输入嵌入器通过添加标注、段和位置嵌入来输出\(E=\left\{e_1,e_2,…,e_n\right\}\)。然后我们将\(E\)输入到Transformer编码器中,每个Transformer层的作用如下:
\(H^{l}=\left\{h_{1}^{l}, h_{2}^{l}, \ldots, h_{n}^{l}\right\}\)表示第\(l\)层的输出,且\(H^{0}=E\),\(LN\)是层归一化,\(MHAttn\)是多头注意力机制,\(FFN\)是一个以ReLU为隐藏激活函数的两层前馈网络。
为了在第\(k\)个和第\((k+1)\)个变换器之间注入词典信息,我们首先在\(k\)个连续的transformer层之后获得输出\(H^{k}=\left\{h_{1}^{k}, h_{2}^{k}, \ldots, h_{n}^{k}\right\}。\)然后,每对\((h^k_i,x^{ws}_i)\)通过Lexicon适配器,该适配器将第\(i_{th}\)对转换为\(\tilde{h}^{k}_{i}\):
由于BERT中有L=12个transformer层,我们将\(\widetilde{H}^{k}=\left\{\tilde{h}_{1}^{k}, \tilde{h}_{2}^{k}, \ldots, \tilde{h}_{n}^{k}\right\}\)输入到剩余的\((L−k)\)transformers。最后,我们得到了序列标注任务的第\(L\)个transformer \(H^L\)的输出。
3.4 Training and Decoding
考虑到连续标注之间的依赖性,我们使用CRF层来进行序列标注。给定最后一层的隐藏输出\(H^L=\left\{h^L_1,h^L_2,…,h^L_n\right\}\),我们首先计算得分\(P\)如下:
对于标签序列\(y=\left\{y_1,y_2,…,y_n\right\}\),我们将其概率定义为:
其中\(T\)是转换分数矩阵,\(\tilde{y}\)表示所有位置标签序列。
给定\(N\)个标注数据\(\left\{s_j,y_j\right\}|^N_{j=1}\),我们通过最小化句子级负对数似然损失来训练模型,如下:
在解码时,我们使用Viterbi 算法找出获得最高分数的标签序列。
4 Experiments
我们进行了一系列广泛的实验来研究LEBERT的有效性。此外,我们的目的是在相同的环境下对模型级和BERT级融合进行实证比较。标准F1-score(F1)用作评估指标。
4.1 Datasets
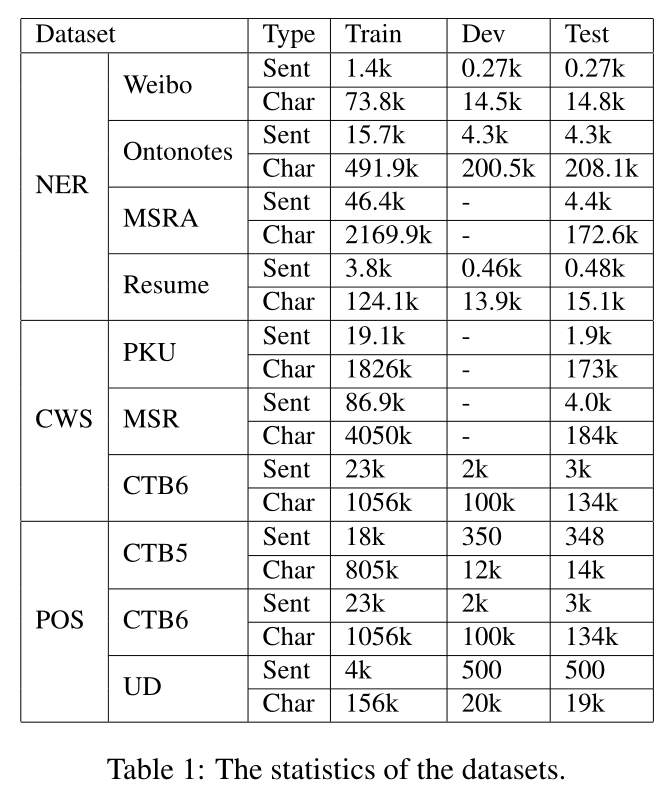
我们在三个不同序列标注任务的十个数据集上评估了我们的方法,包括中文NER、中文分词和中文POS标注。数据集的统计数据如表1所示。
Chinese NER. 我们在四个基准数据集上进行了实验,包括Weibo NER(Peng和Dredze,2015,2016)、OntoNotes(Weischedel等人,2011)、Resume NER(Zhang和Yang,2018)和MSRA(Levow,2006)。Weibo NER是一个社交媒体领域数据集,来自新浪微博;而OntoNotes和MSRA数据集在新闻领域。Resume NER数据集由高管简历组成,由Zhang和Yang(2018)注释。
Chinese Word Segmentation. 对于中文分词,我们在实验中使用了三个基准数据集,即PKU、MSR和CTB6,其中前两个来自SIGHAN 2005 Bakeoff(Emerson,2005),最后一个来自Xue等人(2005)。对于MSR和PKU,我们遵循他们的官方训练/测试数据划分。对于CTB6,我们使用与Yang和Xue(2012)中所述相同的分割;Higashiyama等人(2019)。
Chinese POS Tagging. 对于POS标注,使用了三个中国基准数据集,包括来自Penn Chinese TreeBank的CTB5和CTB6(Xue等人,2005)和通用依赖关系的中国GSD TreeBank(UD)(Nivre等人,2016)。CTB数据集为简体中文,UD数据集为繁体中文。根据Shao等人(2017),我们首先在POS标注实验之前将UD数据集转换为简体中文。此外,UD具有通用和特定语言的POS标签,我们遵循先前的工作(Shao等人,2017;Tian等人,2020a),将具有两个标签集的语料库分别称为UD1和UD2。我们在实验中使用了train/dev/test的官方拆分。
4.2 Experimental Settings
我们的模型基于BERTBASE(Devlin等人,2019)构建,具有12层transformer,并使用huggingface的Chinese-BERT checkpoint 进行初始化。我们使用了Song等人(2018)的200维预训练单词嵌入,该嵌入是使用定向跳格模型在新闻和网页文本上训练的。
本文使用的词典\(\mathbf{D}\)是预先训练的单词嵌入的词汇。我们在BERT中的第1和第2层Transformer之间应用Lexicon适配器,并在训练期间微调BERT和预训练的单词嵌入。
Hyperparameters. 我们使用Adam优化器,BERT的原始参数的初始学习率为1e-5,LEBERT引入的其他参数为1e-4,所有数据集上的训练最大epoch为20。序列的最大长度设置为256,MSRA NER的batch size为20,其他数据集为4。
Baselines. 为了评估所提出的LEBERT的有效性,我们在实验中将其与以下方法进行了比较。
•BERT. 在中文序列标注任务上直接微调预训练的中文BERT。
•BERT+Word. 一种强模型级融合基线方法,它输入BERT向量和双线性注意力加权词向量的级联,并分别使用LSTM和CRF作为融合层和推理层。
•ERNIE(Sun等人,2019a). BERT的一种扩展,使用实体级MASK来指导预训练。
•ZEN. ***等人(2019)通过额外的多层N-gram Transformer编码器和预训练,明确地将N-gram信息集成到BERT中。
此外,我们还比较了每个任务的SOTA模型。
4.3 Overall Results
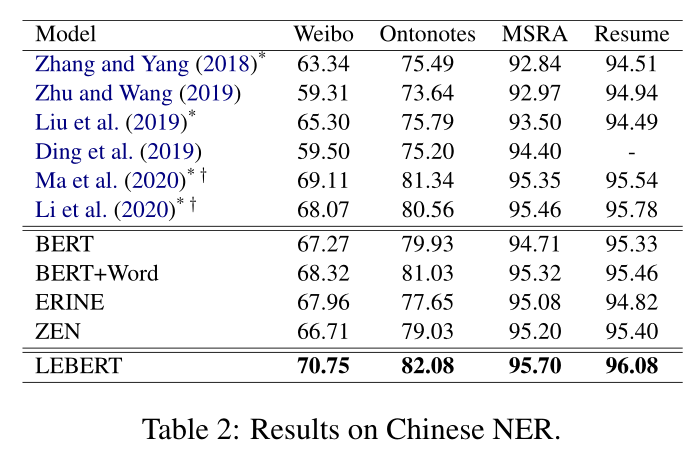
Chinese NER. 表2显示了中文NER数据集的实验结果。第一块中的前四行(Zhang和Y ang,2018;Zhu和Wang,2019;Liu等人,2019;Ding等人,2019)显示了基于词汇增强字符的中文NER模型的性能,第一块中的最后两行(Ma等人,2020;Li等人,2020)是使用浅融合层来集成词汇信息和BERT的SATO模型。混合模型,包括现有的SATO模型BERT+Word和所提出的LEBERT,比词典增强模型和BERT基线实现了更好的性能。这证明了BERT和词汇特征相结合对中文NER的有效性。与模型级融合模型((Ma等人,2020;Li等人,2020)和BERT+Word)相比,我们的BERT级融合模型LEBERT在不同领域的所有四个数据集上的F1得分都有所提高,这表明我们的方法在整合Word和BERT方面更有效。结果还表明,我们的基于适配器的方法LEBERT(仅具有额外的预训练单词嵌入)优于这两个词典引导的预训练模型(ERNIE和ZEN)。这可能是因为ERNIE中词汇的隐式集成和ZEN中预定义的n-gram词汇大小限制了效果。
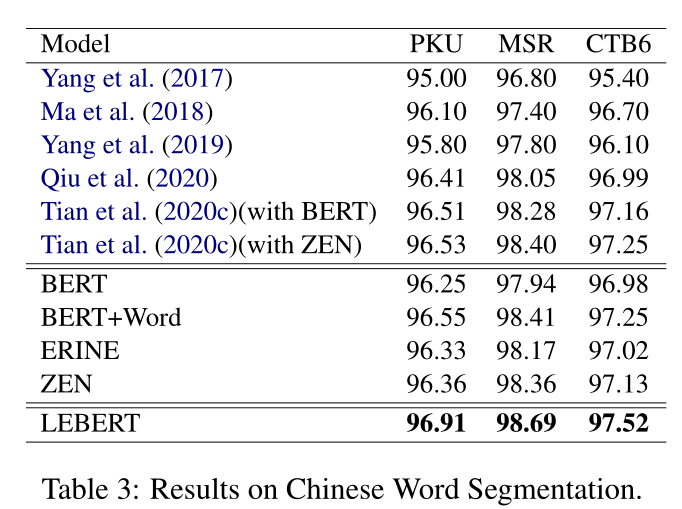
Chinese Word Segmentation. 表3中给出了我们的模型的F1分数和中文分词的基线方法。Yang等人(2019)应用lattice LSTM将单词特征集成到基于字符的CWS模型中。邱等人(2020)研究了多个异质分割标准对单标准中文分词的益处。Tian等人(2020c)设计了一个单词记忆网络,以将单词信息纳入基于预训练的CWS模型中,并显示出良好的性能。与这些方法相比,结合词汇特征和BERT的模型(BERT+Word和LEBERT)表现更好。此外,我们提出的LEBERT优于模型级融合基线(BERT+Word)和词典引导的预训练模型(ERNIE和ZEN),获得了最佳结果。
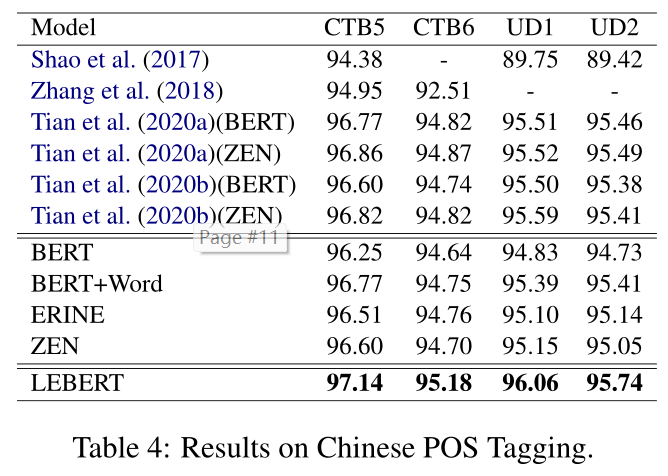
Chinese POS Tagging. 我们在表4中报告了四个中文POS标注基准的F1得分。最先进的模型(Tian等人,2020a)使用双向注意力联合训练中文分词和中文POS标注,以结合自动分析的知识,如POS标签、句法成分和依赖关系。与BERT+Word基线相似,Tian等人(2020b)使用多渠道注意力在模型级别将人物Ngram特征与BERT相结合。如表4所示,结合单词信息和BERT的混合模型((Tian等人,2020b),BERT+Word,LEBERT)优于BERT基线,表明词汇特征可以进一步提高BERT的性能。
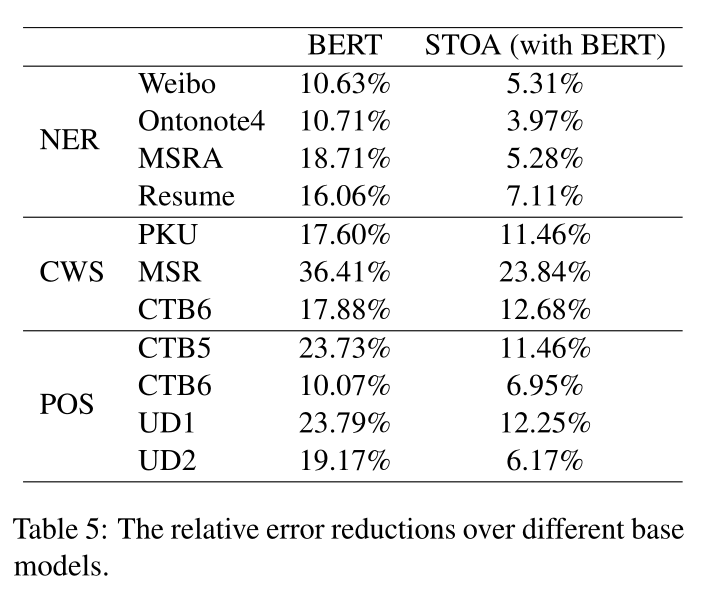
LEBERT在这些方法中取得了SOTA,这证明了BERT级融合的有效性。与中文NER和CWS的结果一致,我们基于BERT适配器的方法优于词典引导的预训练方法(ERNIE和ZEN)。我们提出的模型在所有数据集上都取得了SOTA。为了更好地展示我们方法的优势,我们还在表5中总结了BERT基线和基于BERT的最先进模型的相对误差减少。结果表明,与基线模型相比,相对误差显著降低。
4.4 Model-level Fusion vs. BERT-level Fusion
与模型级融合模型相比,LEBERT将词汇特征直接集成到BERT中。我们根据Span F1、Type Acc和句子长度来评估这两种类型的模型,选择BERT+Word作为模型级融合基线,因为它在所有数据集上都表现良好。我们还与BERT基线进行了比较,因为LEBERT和BERT+Word都基于此进行了改进。
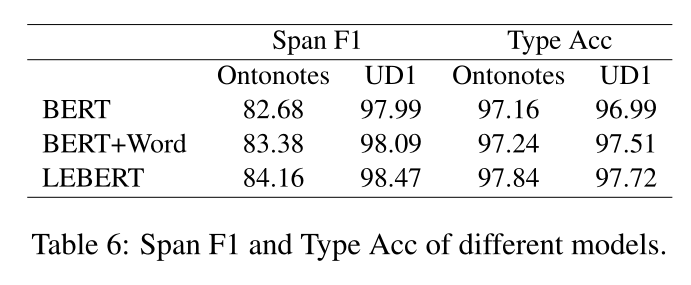
Span F1 & Type Acc.Span F1表示NER中实体或POS标注中单词的跨度正确性,而Type Acc表示完全正确预测与跨度正确预测的比例。表6显示了Ontonotes和UD1数据集上三个模型的结果。我们可以发现,在两个数据集上,BERT+Word和LEBERT在Span F1和Type Acc方面的表现都优于BERT。结果表明,词典信息有助于跨边界检测和跨分类。具体而言,在Ontonotes上,Span F1的改善大于Acc型,但在UD1上则较小。与BERT+Word相比,LEBERT实现了更多的改进,证明了通过BERT级融合增强词典特征的有效性。
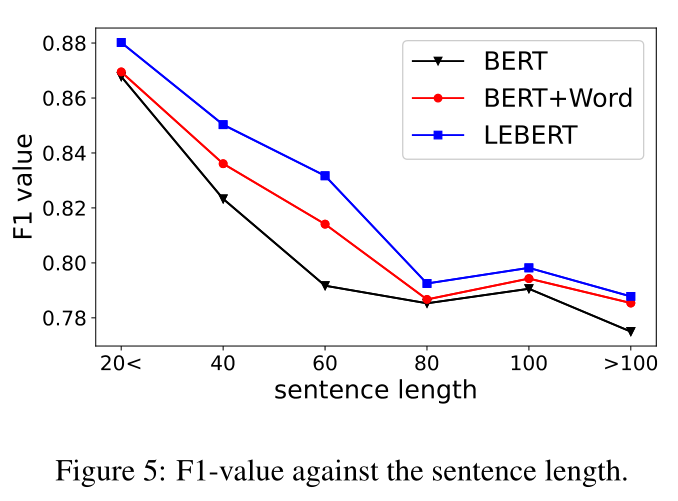
Sentence Length. 图5显示了Ontonotes数据集上基线和LEBERT的F1值趋势。所有模型都显示出相似的表现长度曲线,随着句子长度的增加而减少。我们推测,由于语义复杂,长句更具挑战性。即使是词典增强模型也可能无法选择正确的单词,因为随着句子变长,匹配单词的数量会增加。BERT的F1分数相对较低,而BERT+Word由于使用了词典信息而获得了更好的性能。与BERT+Word相比,LEBERT表现得更好,并且在句子长度增加时表现出更强的鲁棒性,证明了词典信息的更有效使用。
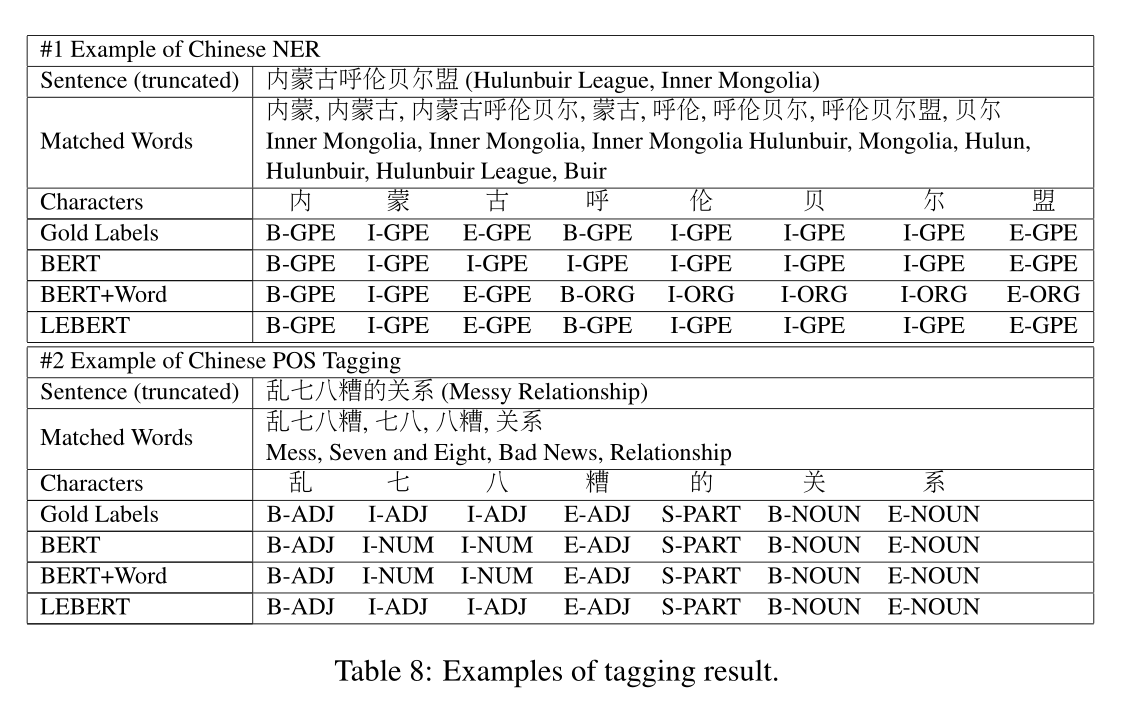
Case Study. 表8分别显示了Ontonotes和UD1数据集上的中文NER和中文POS标注结果的示例。在第一个示例中,BERT不能确定实体边界,但BERT+Word和LEBERT可以正确分割实体边界。然而,BERT+Word模型无法预测实体的类型“呼伦贝尔盟”,而LEBERT做出了正确的预测。这很可能是因为较低层的融合有助于捕获BERT和词典提供的更复杂的语义。在第二个例子中,三个模型可以找到正确的跨度边界,但BERT和BERT+Word都对跨度类型做出了错误的预测。虽然BERT+Word可以使用单词信息,但它被不相关的单词“七八”预测为NUM。相比之下,LEBERT不仅可以整合词汇特征,还可以选择正确的单词进行预测。
4.5 Discussion

Adaptation at Different Layers.我们探讨了在Ontonotes数据集上BERT的不同Transformer层之间应用Lexicon适配器(LA)的效果。评估不同的设置,包括在Transformer的一个、多个和所有层之后应用LA。对于一层,我们在\(k \in \left\{1,3,6,9,12\right\}\)层之后应用LA;以及用于多层的\(\left\{1,3\right\}\),\(\left\{1,3,6\right\}\),\(\left\{1,3,6,9\right\}\)层。所有层表示BERT中每个Transformer层之后使用的LA。结果如表7所示。浅层实现了更好的性能,这可能是因为浅层促进了词汇特征和BERT之间更分层的交互。在BERT的多层应用LA会损害性能,一个可能的原因是多层集成会导致过度拟合。
Tuning BERT or Not.直观地说,在不进行微调的情况下,将词典集成到BERT中可以更快(Houlsby等人,2019),但由于词典特征和BERT的不同特性(离散表示与神经表示),性能更低。为了评估其影响,我们在Ontonotes和UD1数据集上进行了有和无微调BERT参数的实验。从结果中,我们发现,如果不对BERT进行微调,F1得分将下降7.03分(82.08→ 75.05)和3.75分(96.06→ 92.31),说明了微调BERT对我们词汇整合的重要性。
5 Conclusion
在本文中,我们提出了一种新的方法,将词典特征和BERT集成到中文序列标注中,该方法使用词典适配器在BERT中的Transformer层之间直接注入词典信息。与模型级融合方法相比,LEBERT允许在BERT级深度融合词汇特征和BERT表示。大量实验表明,所提出的LEBERT在三个中文序列标注任务的十个数据集上达到了SOTA。

