

Multi-Modal Sarcasm Detection via Cross-Modal Graph Convolutional Network
1)Multi-Modal Sarcasm Detection via Cross-Modal Graph Convolutional Network
基于跨模态图卷积网络的多模态讽刺识别
论文作者:梁斌 徐睿峰 哈尔滨工业大学 2022ACL
论文地址:https://aclanthology.org/2022.acl-long.124.pdf
2)Multi-Modal Sarcasm Detection with Interactive In-Modal and Cross-Modal Graphs
基于交互式模态内和跨模态图的多模态讽刺识别
论文作者:梁斌 徐睿峰 哈尔滨工业大学 2021ACM
论文地址:https://dl.acm.org/doi/pdf/10.1145/3474085.3475190
一、摘要
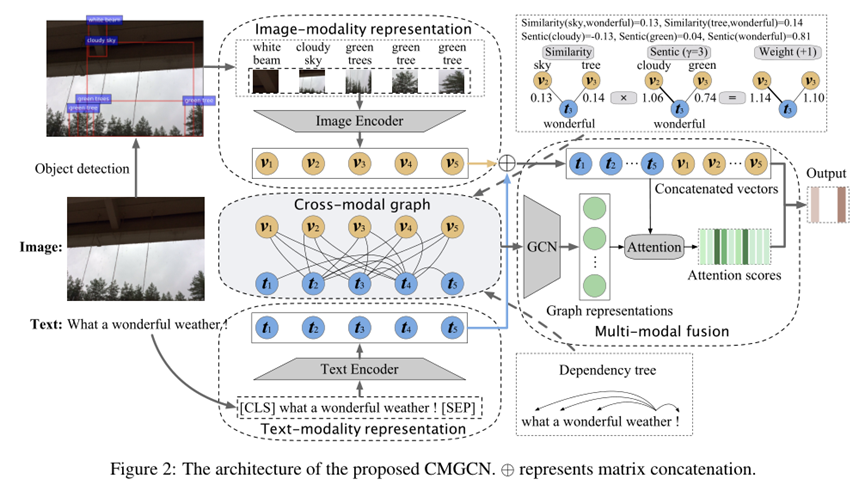
本文提出了一种有效的基于跨模态图的多模态讽刺识别模型。我们发现,在多模态讽刺识别任务中,对于图片模态,直接学习整个图片的信息很困难,且图片中存在很多与讽刺识别无关的视觉信息。为此,首先使用目标检测(object detection)来识别图片中的重要视觉块以及视觉块的对应描述。随后,将视觉块的描述作为一座桥梁,将离散的视觉块和文本连接起来,构造跨模态关系图。同时,通过引入外部情感知识,进一步挖掘不同模态间的情感不一致性,从而有效识别多模态数据中的讽刺信息。在公开数据集的实验结果表明,本文提出的模型取得了最佳性能。
模型
文章提出的模型CMGCN包含四个组成部分:
1)文本模态表示
2)图片模态表示
3)跨模态图
模型图右上角权重计算公式:
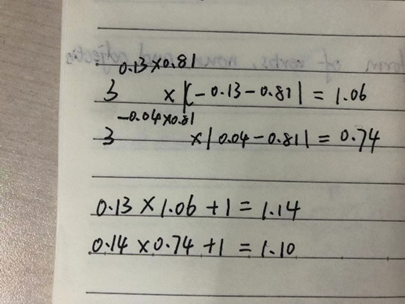
4)多模态融合
二、摘要
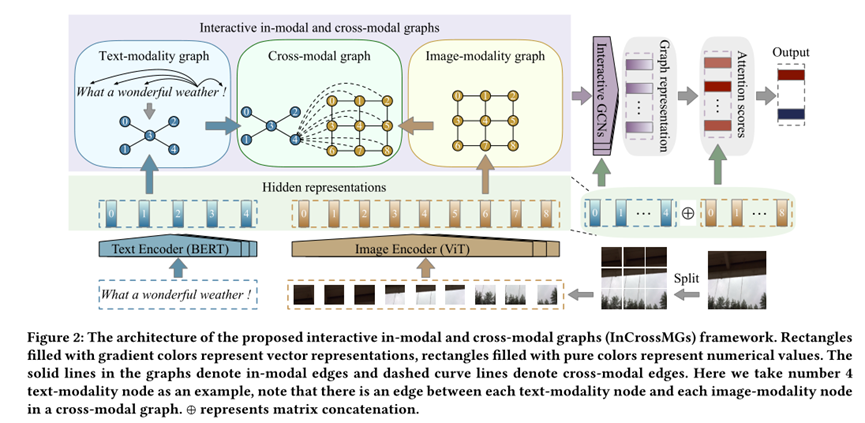
为每个多模态构造异构模态内和跨模态图(InCrossMGs)来确定特定模态内和不同模态之间的情感不一致。在此基础上,探索了一种交互式图卷积网络 (GCN) 结构,以联合交互地学习模态内和跨模态图的不协调关系,以确定讽刺检测中的重要线索。
模型
文章提出的模型InCrossMG包含四个组成部分:
1)文本模态表示
2)图片模态表示
3)构建模态内和跨模态图
4)图表示
两篇文章的创新点:


粗略阅读了文章,2022ACL这篇的新颖之处是多模态图的边引入了情感和相似性合成的权重。
2022这篇公式(11)r转置这个公式的维数硬是没有对上,没有代码参考,所以我也不知道自己错在哪里~
说实话看到一半发现作者公开的代码链接里面是空的就很失望不想看了,虽然我也没打算复现……
