

Tackling Fake News Detection by Continually Improving Social Context Representations using Graph Neural Networks
Tackling Fake News Detection by Continually Improving Social Context Representations using Graph Neural Networks
基于持续增强社交上下文表示的图神经网络虚假新闻检测
论文作者:Nikhil Mehta, Maria Leonor Pacheco, Dan Goldwasser 2022ACL 普渡大学
论文地址: https://aclanthology.org/2022.acl-long.97.pdf
代码和数据集:https://github.com/hockeybro12/FakeNews_Inference_Operators
摘要
本文将假新闻检测视为在图框架中对源、文章以及在社交媒体上吸引用户之间的关系进行推理。在对这些信息进行嵌入后,制定了推理算子,通过揭示其元素之间未观察到的交互(例如文档内容和用户参与模式之间的相似性)来增强图边缘。我们在两项具有挑战性的假新闻检测任务上的实验表明,使用推断算子可以更好地理解支持假新闻传播的社交媒体框架,从而提高性能。
1 引言
这篇论文中作者探索了一种不同的方法,这是由社会同质性原则驱动的,指的是个人与分享其观点和偏好的其他人形成社会联系的趋势。我们观察到,文本中表达的政治观点和偏见将反映在用户参与其中的行为中。它们一起形成信息社区,根据用户的内容偏好将用户彼此联系起来,并与提供内容的来源联系起来。在这种高度关联的结构中,即使是将用户偏好与虚假叙述联系起来的少量证据也可以传播,并有助于判断他们所关注和参与的源。图1展示了用户、文章及其源之间的交互。
不幸的是,这些丰富的社会信息中的大部分都无法直接观察到,或者由于这些交互的数量而无法完全采样。为了帮助缓解这个问题并获取这些知识,我们提出了一组推理算子,每个推理算子都使用超出最初所见的不同关系来扩充信息图。通过迭代地应用这些推理算子,我们能够捕获更多隐藏的关系,这些关系使虚假新闻能够通过社交媒体传播,并且对于检测它至关重要。
从技术角度来看,我们将假新闻检测视为信息图的推理问题。我们使用我们现有的高与低真实性内容知识(即训练数据)提供的证据,根据观察到的和预测的链接捕获它们的联系来评估未知内容的真实性。这个转换过程是使用关系图神经网络 (R-GCN)(Schlichtkrull 等人,2018 年)完成的,它创建了由图结构上下文的节点的分布式表示,使我们能够使用图嵌入任务将信息从观察到的证据节点传递到未知源节点。我们使用基于学习图嵌入定义的相似性度量的推理算子来增加连接两种节点类型的边数。这两个相互依赖的步骤是迭代完成的。
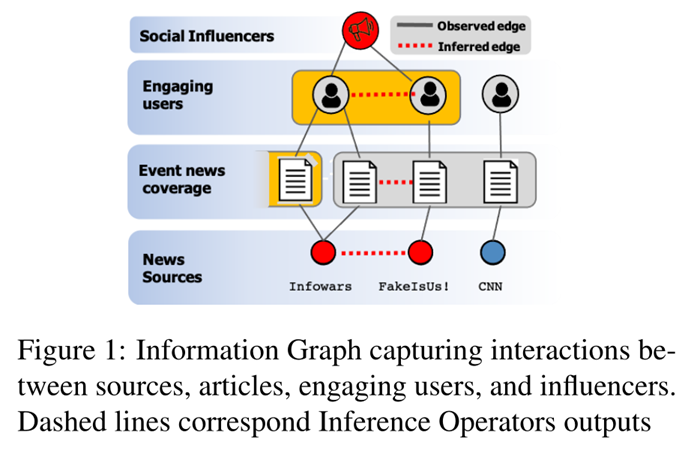
如图1,观察到的用户关系用黑线显示,例如用户与所发布的文章交互。基于信息图中的观察数据,我们可以通过图嵌入训练为每个节点创建初始的图上下文表示。我们可以看到,对于当前训练的模型,有三篇在内容和嵌入方面相似的文章,图中通过共享灰色背景来表示。两篇是“假新闻”文章,由红色背景的低真实性新闻来源(“FakeIsUs”和“InfoWars”)发布,而最右边的一篇是由高真实性来源发布。假设模型不熟悉它们的源真实性级别,那么基于观察到的图形信息可能无法区分它们。因此,在这项工作中,我们建议通过推理算子基于学习的知识来扩充图。直观地说,我们的推理算子的目标是提供额外的图边缘(如红色虚线所示),这样,图上下文嵌入将捕获两个低真实性文章之间的相似性以及与高真实性文章相比的差异。例如,与左侧两篇文章互动的用户关注同一个社交影响者的用户,他是高活跃度用户。在最初的图形训练中,这种观察到的关系将增加这些用户的学习节点相似性(黄色背景),从而推理操作将他们连接到一个由同质性用户组成的强大信息社区中,这是初始结构观察不到的,因此不容易通过图嵌入来表示。这种新推断的关系可以通过信息图传播,使我们能够获得更多关于这些新连接的用户与之交互的其他文章、源、用户的信息,从而更好地检测假新闻。总的来说,本文创新处如下:
l 将虚假新闻检测公式化为信息图上的推理问题
l 提出了一种基于推理的图形表示学习方法,该方法通过对用户的社交信息和内容偏好的推断逐步增强图形
l 对源级别和内容级别进行了广泛的实验,证明了基于推理的图形表示方法在两种情况下都能提高性能,即使是弱监督也有效
2 相关工作
虚假新闻检测
利用社交媒体检测假新闻是最近一个热门的研究课题。它通常作为一项监督学习任务进行研究,其中分类器使用新闻及其社会背景的表示来训练,以预测内容的真实性。不幸的是,这些方法无法捕捉用户和在社交媒体上分享假新闻的来源之间的互动,这对于更好地了解假新闻的传播方式并最终发现它是必要的。
由于上述限制,研究人员最近开始使用图形神经网络(GNN)(对图形进行建模)来完成这项任务。由于它们包含社交媒体实体作为节点,并基于观察到的交互通过边缘将它们链接起来,因此图能够更好地捕捉社交上下文。更具体地说,通过边缘交互,图中的节点可以增强其他节点的表示,从而增强整体信息质量。最近,Han等人利用GNN的持续学习来捕捉Twitter上虚假新闻的传播级联。然而,与我们的工作不同,这些和其他图形模型一样不能揭示或建模数据中的隐藏关系。
与我们最相似的是Nguyen等人提出了事实新闻图(FANG),并通过训练模型以更好地捕捉社会背景,在图框架中对来源、文章和用户之间的关系进行建模。然而,FANG修改了他们在训练图时使用的损失函数,以更好地捕捉已经存在的用户-用户和用户-文章交互,而不是像我们使用推理算子那样迭代地添加新的显式边来揭示图中的隐藏交互。尽管这是有效的,但它没有对原始数据中没有观察到的图形交互进行建模,而我们的方法也可以揭示这些隐藏的关系,从而更有力地捕捉社交媒体上的假新闻传播现象(我们明确的信息社区可以帮助更好地建模其他内容)。此外,我们的框架允许图形不断增强,因此我们可以捕获比原始图形中构建的关系更多的关系(如源到源),因此能不断实现性能改进。
迭代图学习
最近,也有关于学习增强图的工作,例如通过使用为最终任务优化的端到端神经模型。虽然这些工作确实迭代地扩充了与我们类似的图,但通过端到端地进行,它们可能倾向于特定于任务(边缘可能仅为实现更高的分类精度而创建),而不是学习高质量的社交媒体表示。这可能会导致测试或感应设置出现问题。在我们的案例中,当我们基于学习到的图形相似性添加边时,我们正在加强已经存在的信息社区,同时发现隐藏的信息社区。此外,我们可以轻松控制关系和数量的添加。
3 模型
我们将假新闻检测视为对信息图中来源、文章和吸引用户之间关系的推理。我们假设,同质性原则会导致在线社区形成的社会关系将捕捉社区内部和社区之间内容偏好的异同。
我们使用第3.1节中定义的异质图捕捉社会信息和新闻内容之间的交互,并使用关系图卷积网络(R-GCN)创建用于真实性预测的矢量化节点表示。第3.2节中定义的R-GCN通过创建上下文的节点表示来捕捉不同的社会社区。例如,文章节点使用其内容、来源以及与参与其中的用户的关系来表示(也使用其与其他节点的关系来表达)。我们通过R-GCN成功捕捉社会社区取决于拥有强大的社会信息(即,图形边缘)来描述他们。提供这些信息可能不是直截了当的,因为大规模收集社会信息可能成本高昂,而且噪音很大。相反,我们提出了第3.3节中定义的推理算子,该算子使用学习节点表示之间的相似性来评估其兼容性,从而用新的边来扩充图。这使得R-GCN能够丰富每个新连接的节点的上下文表示,从而改进真实性分类。在第3.4节中,我们描述了一个推理框架,该框架使用推理算子不断迭代从而丰富图,并基于更新的图计算更新节点表示。框架如图2所示。
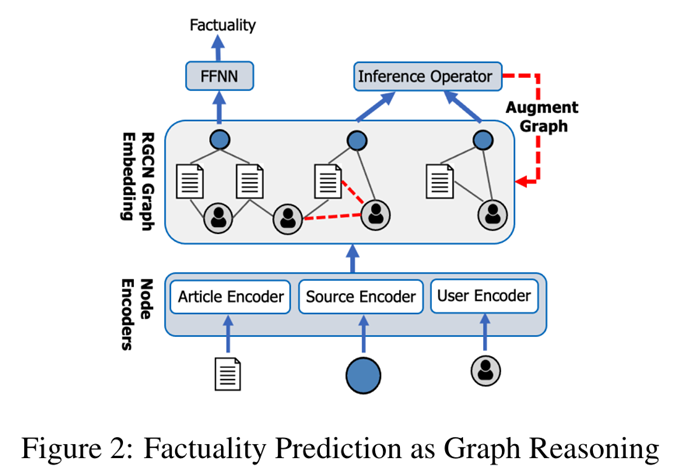
3.1 使用社交上下文创建图
我们的图由以下节点组成:(1)S,新闻发布源,每个源的si向量由其在Twitter和YouTube上的简介嵌入组成。(2)A,由源发布的文章,每个文章ai向量使用SBERT和RoBERTa模型提取其内容,因为模型提供了强大而有意义的句子嵌入。(3)U,与文章和源交互的Twitter用户,由他们提供社交上下文。该描述适用于源级别和内容级别设置,其中S和A中的元素是我们分类的目标,用户向量与上面提到的Twitter嵌入相同。
图通过首先将源添加为单个节点而形成的,然后将每个源连接到最多300篇文章e={si,aj}。接下来通过与源交互的Twitter用户将社交上下文添加到图中:(1)关注源:添加多达5000个关注源的用户,将每个用户连接到他们关注的新闻源e={si,uj},这可能表明了一种积极关系。(2)讨论文章:我们将每篇文章与在3个月内发布其标题/链接的用户联系起来e={ai,uj},这些用户提供了虚假(和真实)新闻传播的手段,使我们能够模拟这一过程。最后,社交互动是分析假新闻传播的一个重要组成部分,它通过收集每个Twitter用户多达5000名粉丝,并将现有用户与边缘联系起来(如果他们一个追随另一个)来捕获。
3.2 图嵌入
给定图中观察到的交互,我们训练GNN学习嵌入函数,该函数将由推理算子使用。
节点嵌入函数我们选择了关系图卷积网络(R-GCN)(Schlichkull等人,2018),它将传统的GCN推广到处理不同的关系类型,从而使我们能够更好地捕捉它们的交互并改进它们的表示。直观地说,R-GCN通过图卷积考虑图结构来创建上下文的节点表示,并学习合成函数:
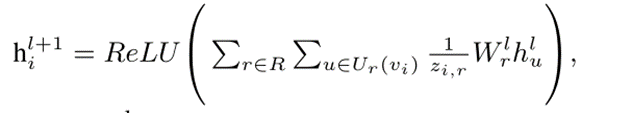
其中,hli是层l处的第i个节点的隐藏表示,h0i=vi(节点编码器的输出);Ur(vi)表示由关系类型r连接的vi的相邻节点;zi,r表示归一化;并且W lr表示可训练参数。为了获得用于捕获真实性的有意义的节点表示,我们优化了假新闻检测的节点分类(NC)目标。从R-GCN获得源表示后,我们将其通过softmax激活函数,然后使用类别交叉熵损失进行训练,其中标签为真实性。
3.3 推理算子
我们定义了多个推理算子,这些算子能够基于学习到的信息图推理来创建新的边。不同的算子捕捉了关于连接不同类型的节点对将如何促进可信度传播的直觉。例如,在图中没有明确连接(即,彼此不跟随)但共享具有相似真实性级别的文章的用户对可能具有相似的不可信程度。连接它们将为它们所连接的节点提供更多信息。一个推理算子根据嵌入空间中的节点相似性添加用户-用户边。
对于下面讨论的每种推理算子类型,我们通过计算所有节点对之间的相似性分数(使用图节点嵌入-被FAISS证明有效(Johnson等人,2017)),并基于模型将节点与前k个相似性分数节点连接起来。
3.3.1 基于社交信息的算子
第一种推理算子类型以与推荐引擎类似的方式在图形实体之间添加边,建议实体基于它们的图形关系相互交互。
用户-源:使用嵌入空间中前k个最相似的源/用户对,在用户和源之间添加边(e={ui,sj})。
用户-用户:以类似方式与新闻交互的成对用户是连接的(e={ui,uj})。这些用户可能有相同的信念,如果他们了解到对方的个人资料,他们甚至可能会想追随对方。
用户-文章:在文章和可能感兴趣的用户之间添加边缘(e={ui,aj})。这个推断可以基于目标用户与类似文章的交互,或者与共享这些文章的其他用户的交互。
3.3.2 基于新闻上下文的算子
第二种类型推理算子基于上下文相似性连接实体。与前一组不同,这些类型的边最初没有在图中观察到,基于潜在关系进行推断,这些潜在关系是信息传播的基础,例如不同源之间的协调、在多篇文章中发布类似内容的泛滥信息以及“不良影响者”,持续传播低质量内容者。
源-源:可能在同等事实水平上发布类似内容的源是关联的(e={si,sj})。
文章-文章:内容彼此相似的文章可能是连接的(e={ai,aj})。为了有效地做到这一点,我们首先确定讨论同一事件的文章对,使用发表日期和标题中的实体是否重叠进行相似度计算。其次,我们使用蕴含模型(Parikh 等人,2016 年;Gardner 等人,2017 年)仅连接相互蕴含的文章,因为它们更有可能谈论相似的内容。
影响者:假新闻通常由拥有大量追随者的“不良影响者”传播。多年来,Twitter发起了旨在通过暂停此类用户来减少假新闻传播的活动。该推理算子旨在通过以下步骤实现同样的目的:(1)使用训练数据,通过计算具有给定真实性标签的源的路径来标记用户。(2)将关注者群体中没有显著标签差异的用户识别为潜在的“新闻影响者”。我们避免用户大多是高度真实的追随者。(3)在推理时,我们将新用户连接到这个初始集合中的影响者,使用一个特殊的边缘类型,表示与影响者的相似性。我们添加了前k位用户,实验设置为500(附录A.2.5)。
3.4 联合推理和表达
定义的推理算子使用图嵌入函数来识别新的关系,这些关系可能会提高嵌入质量,并允许在学习期间更好地传播信息。这两个步骤显然是相互依存的。现在,我们描述了基于这种依赖关系的迭代图学习框架,并通过应用推理算子,然后重新训练图,不断学习图中更好的社会上下文表示。可以在算法1中看到,并运行以下步骤:
(1)初始表示:在该步骤中,我们使用第3.2节中描述的框架来训练图G,以获得初始图表示。
(2)推理步骤:基于学习的表示应用推理算子(第3.3节)。
(3)学习步骤:之后,我们继续图形的训练过程。
不断迭代这两个步骤,直到收敛。附录A和C中提供了有关该过程的其他详细信息。完成后,基于通过应用推断算子所揭示的最终图形重新训练模型。通过迭代不断改进社交媒体框架的表达,该框架支持假新闻传播,并揭示对理解假新闻传播至关重要的隐藏关系。

4 实验
基于两个具有挑战性的任务评估模型预测假新闻的能力:假新闻源分类和文章分类。
4.1 数据集和数据收集
为了评估我们的模型预测新闻媒体真实性的能力,我们使用了 Media Bias/Fact Check 数据集(Baly 等人,2018 年,2020b)。数据集包含 859 个来源,每个来源都按照 3 分的真实性等级进行标记:低、混合和高。使用 Twitter API,为每篇文章平均收集了 27 次用户参与(第 3.1 节)。最终图由 69,978 个用户、93,191 篇文章、164,034 个节点和 7,196,808 条边组成。有关我们在训练图形时使用的设置(使用开发集选择)和我们的抓取协议的详细信息,请参见附录 A。我们的代码可用。
为了评估假新闻文章检测,使用了由 (Nguyen et al, 2020) 发布的数据集,使用谣言分类(Kochkina et al, 2018; Ma et al, 2016) 和假新闻检测 (舒等人,2018)的相关工作。对于每篇文章,数据集都提供其来源和参与用户列表。我们还收集了每个用户的关注者,得出一个包含 48,895 个用户、442 个来源和 1,050 篇文章的图表。
4.2 虚假新闻源分类
表 1 显示了我们在源分类方面的结果。
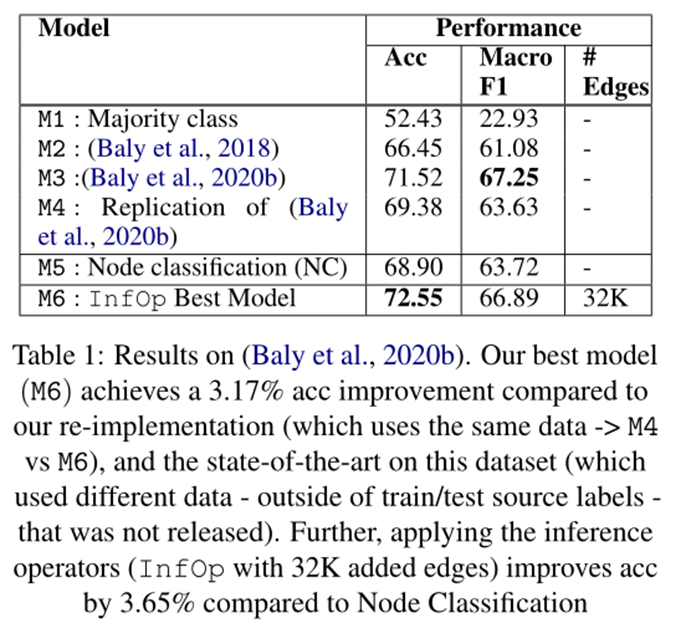
根据 (Baly et al, 2020b) 发布的所有 5 个数据拆分的平均值来评估我们的模型,使用 20% 的训练集源作为开发集。我们报告准确性和宏观 F1score 的结果与 (Baly et al, 2020b, 2018) (M2, 3) 进行比较,本文模型在该数据集上实现了最强的性能。由于(Baly 等人,2020b)没有发布他们使用的文章和社交媒体数据,我们使用我们抓取的数据(和他们的代码)复制他们的设置,并与之进行比较(M4)。尽管我们优化了他们的模型,但我们的结果比他们发布的性能要差,所以我们假设他们在我们的设置上的数据可能会带来更好的整体性能。
当使用节点分类 (NC) 假新闻损失和相同数据 (Baly et al, 2020b) 仅使用观察到的数据训练我们的初始图时,我们获得了与他们的方法相似的性能(M5 vs M4)。当我们应用我们的推理算子,然后以相同的方式训练图形(如在 M5 中)时,得到 3.65% 的 acc提升。改进(M5 与 M6),显示我们的推理算子设置在此任务上的明显好处,并回答我们的研究问题,即添加的信息有帮助。此外,此设置在 (Baly et al, 2020b) 上实现了最先进的水平,超过了我们使用相同数据的复现结果(按 3.17% 的比例)和他们公布的结果(按 1.03% 的比例)。
4.3 虚假新闻文章分类
文章分类结果在表 2 中。
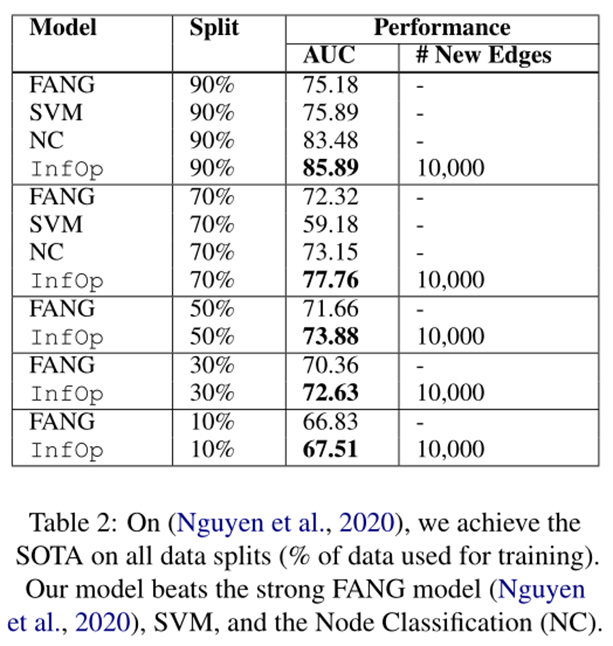
我们与据我们所知表现最好的 (Nguyen et al, 2020) (FANG) 进行比较,并与他们工作中的几个竞争基线进行比较 (Ruchansky et al, 2017)。Nguyen 等人与我们最相似(如第 2 节所述,他们也训练 GNN),但他们没有明确表示未观察到的交互,而是修改了训练时使用的损失函数以更好地捕捉它们。我们的设置与 (Nguyen et al, 2020) 的强设置相同(我们使用他们发布的数据和数据拆分),只是我们使用不同的 Twitter 和文章表示,并且我们还考虑了 Twitter 关注形成的边。此外,FANG(Nguyen 等人,2020 年)从时间轴上考虑了推文传播方式,我们没有考虑,我们假设这可能会提高我们的表现。出于这个原因,与 FANG 相比,除了我们考虑 Twitter 用户关注者这一事实外,我们使用的数据更少。为了进行适当的比较,我们还通过训练 SVM 和 App 来评估我们的表示。标签8,我们使用与 FANG 相同的表示来评估我们的模型。我们在标签2 中评估了他们所有的数据拆分(90% -> 90% 的数据用于训练,10% 用于测试,等等)。 使用节点分类评估我们的模型性能。我们展示了最佳结果(扩展结果和详细信息在附录C),并且可以看出,应用推理算子还提高了所有数据拆分上假新闻文章分类的性能(高达 4.61% AUC),明确地加强了这一点在图中学习和创建未观察到的关系使我们能够更好地检测假新闻内容。此外,我们平均实现了 4.26% 的 SOTA。
5 讨论
在本节中,我们通过回答以下研究问题来分析我们使用推理运算符(表 1 M6)进行假新闻源检测的最佳模型(Baly 等人,2020b):
(1)消融研究:每个推理算子的贡献是什么?
(2) 我们的模型可以在有限的数据上学习吗?我们基于推理的表示有帮助吗?
(3) 我们可以学习有意义的用户社区吗?
(4) 我们的模型对每个推理算子做出什么类型的推理?
(5) 我们能否检测新内容的真实性?
(6) 我们学习了哪些嵌入? (App. B.1)
(7) 我们应该为每个算子添加多少条边。(App. B.2)
(8) 运行推理算子需要多少时间?(附录B.3)
5.1 消融实验
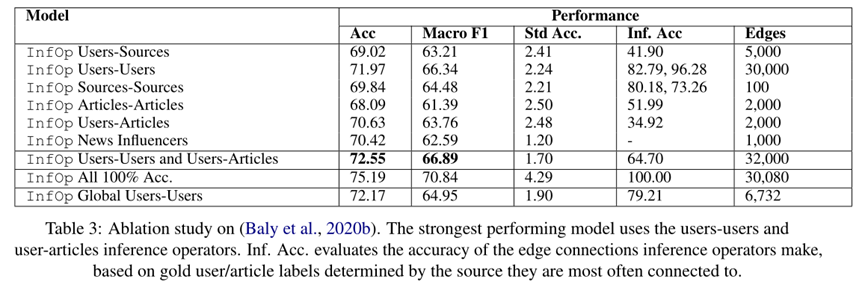
在表 3 中,我们评估了每个推理算子,使用我们的联合学习和推理算法训练最多两次迭代。为了评估我们在应用推理算子(“Inf.Acc”)时所做的边缘连接的准确性,我们比较了由推断边缘连接的两个节点的标签(即,准确的决策连接具有相似标签的节点)。由于标签仅在数据中与源相关联,因此我们根据在初始图中直接连接到的所有源中最常见的黄金标签定义了用于计算文章和用户节点标签的启发式方法(例如:用户关注的3 个高真实性来源被分配了高真实性标签)。我们还报告了每个设置中连接的边数(所有参数的开发集)。
我们注意到,我们几乎所有具有推理算子的模型都会导致性能优于基线(选项卡 1 M4、5),这表明捕获这些隐藏关系并使用新边缘使它们显式有助于假新闻检测。此外,我们的几个推理算子(用户-用户/源-源)实现了高精度,同时所有性能都优于随机,表明我们可以在学习初始信息图后进行有用的边缘连接。此外,通过我们的设置(推理算子 Users-Users 和 Users-Articles)在多次迭代中应用多个推理算子会获得此任务的最强性能。
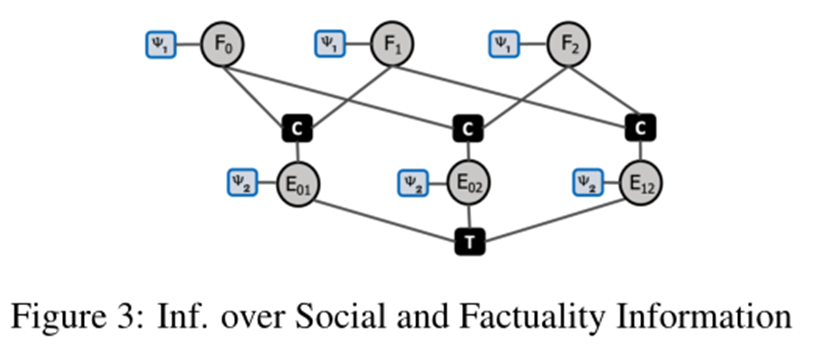
全局推理算子 未来工作的一个有趣方向是捕获推理算子应用之间的相互依赖性。我们建议第一步,基于概率推理(Pacheco 和 Goldwasser,2021),如图 3用户-用户算子。我们定义了两种决策变量类型,F 与用户的真实性预测相关,E 与用户对的推理运算符结果相关。每个都与评分函数相关联,ψ1 对用户的真实性分配进行评分,而 ψ2 则基于嵌入相似性对用户对进行评分。使用两组约束连接分配:C,确保通过预测边连接的用户的事实标签一致性, T确保跨边对的传递性,共享节点。我们使用 MAP 推理来识别解决方案边集。表3中的结果展示了与局部推理 (71.97) 相比的改进程度 (72.17),并且边缘数量少(6.7K 与 30K 相比)。实验性地展示了使用全局概率推理更智能地确定要连接的边的好处,而不是像我们之前那样仅使用嵌入相似性(这里我们还考虑了用户真实性,将来可以添加其他决策变量/评分函数)。附录 D 中提供了此设置的详细信息和其他潜在好处。
5.2 弱监督训练
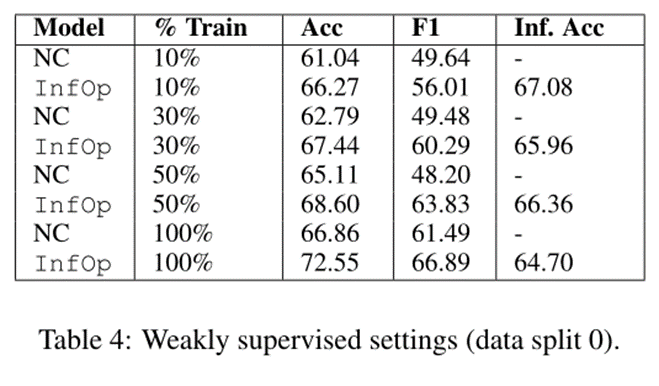
接下来,在表 4 中,我们通过在较小的源集上进行训练(仍然使用整个图和完整的测试集)来评估我们的模型使用有限的训练数据进行假新闻源分类。在这里,我们看到我们的推理算子能够显著提高性能(节点分类与推理算子),因为它们揭示了模型在弱监督环境中无法以其他方式学习的关系,这表明我们的系统如何可用于检测最近发布的新闻。
5.3 学习信息社区
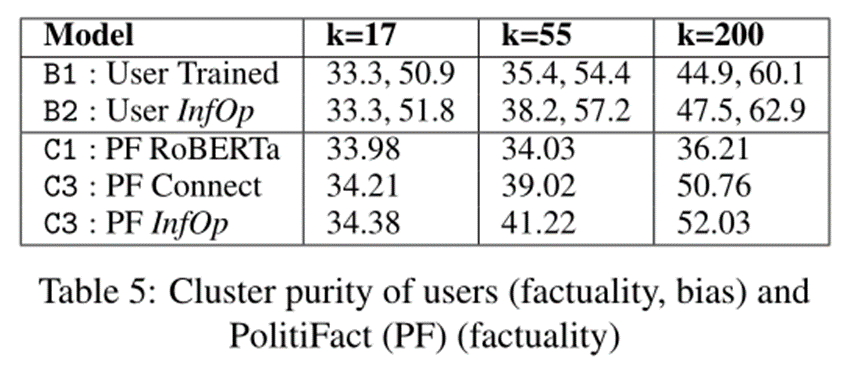
现在,分析用户-用户推理算子如何让我们了解用户的信息社区(表 5)。为此,我们在应用推理运算符之前 (B1) 和之后 (B2) 对用户进行聚类(表 5 显示不同的 K 值),并根据用户标签评估聚类纯度。为了计算纯度,每个集群都被分配到集群中出现频率最高的类别,然后测量其准确性。使用5.1节中描述的相同启发式方法为用户分配标签。 5.1在应用推理运算符(甚至通过偏差标签)后,用户聚类效果更好,表明可以使用它们来形成信息社区。
5.4 模型是如何学习连接的
在这里,我们通过分析所建立的特定边缘连接来分析推理算子。我们看到该模型在连接可能属于同一信息社区的节点时做出了明智的选择。例如(附录 B.4 中有更多内容),一篇将民主党人讨论为“dangerous open border fanatics”的低真实性文章与生物“BuildtheWall ... DEMONRA TS”的用户相关联。
5.5 纳入新的新闻内容
最后,我们通过聚类来自 PolitiFact的 1500 个经过事实核查的声明来评估我们的模型如何很好地整合看不见的新闻内容。在表 5 中,首先对这些声明的初始 RoBERTa 嵌入进行聚类 (C1),然后通过将它们连接到五个具有相似嵌入的图文章 (C2) 将它们添加到图中。接下来,使用用户文章推理算子将这些文章中的每一篇连接到用户 (C3)。很明显,RoBERTa 嵌入语句不能很好地按事实聚类。但是,一旦将它们添加到图中 (C2) 并通过推理算子 (C3) 将它们连接起来,它们就能很好地按事实聚类。这进一步展示了我们的框架,尤其是通过推理算子,如何允许更好地检测看不见的新闻内容(在本例中为声明)。我们不仅可以确定它的真实性,还可以确定其他用户可能会与之交互的内容。
6 总结和展望
我们提出了一种通过不断改进社会背景表征来解决假新闻检测的方法。为实现这一目标,我们开发了一个迭代表示学习和推理框架,该框架学习初始图嵌入,然后应用不同的推理算子来揭示图中隐藏的关系。我们不断获取更多关于允许假新闻传播的社会动态的知识。我们在多个数据集和设置中展示了假新闻检测的强大性能。
我们目前的工作着眼于通过添加外部知识来提高推理算子的准确性。我们开始探索这个方向,方法是使用蕴含模型使用内容相似性来推断文章关系。我们还探索了其他方法来联合建模推理运算符并捕获它们之间的依赖关系。
我们相信这项工作有助于研究文本分析与其社会背景之间的相互关系,可以适应于许多 NLP 任务。
附录A 假新闻源检测
在本节中,我们提供了假新闻源检测模型的实现细节。我们使用的数据集有 859 个源:452 个高真实性、245 个混合真实性和 162 个低真实性。该数据集不包含任何其他原始数据(文章、来源等),因此我们必须自己抓取。
A.1 数据收集
对于每个源,我们尝试使用公共图书馆(Newspaper3K、Scrapy和 news-please)来抓取新闻文章。在源新闻文章的网页被删除的情况下,我们使用了 Wayback Machine。我们试图为每个源抓取多达 300 篇文章,但这并不总是可能的。总的来说,我们的来源平均有 109 篇文章,标准差STD为 36。
对于 Twitter 用户,我们使用 Twitter API为我们能找到的每个 Twitter 帐户抓取 5000 个关注者(72.5% 的源,与(Baly 等人,2020b)相同)。此外,我们使用 Twitter 搜索 API 搜索关于Twitter在文章发布后的 3 个月内找到任何提及文章标题或 URL 的推文。然后我们也下载了发布这些推文的用户,并将他们添加到图中,将他们链接到他们发布推文的相应文章。最后,为了增加图表的连通性并准确捕捉用户之间的互动,我们还抓取了每个 Twitter 用户的关注者。然后我们过滤用户,仅将与多个源(通过源或文章连接) 或另一个用户,这样每个节点都将相互连接。我们没有抓取 Y ouTube 帐户,而是使用与已发布的帐户相同的帐户(Baly 等人,2020b)。他们为 49% 的源找到了 YouTube 频道,并发布了这些信息。
A.2 实验设置
A.2.1 初始化嵌入
我们使用SBERT RoBERTa初始化源和用户的嵌入为一个 773 维向量:表示源是否经过验证的二进制数、源关注的用户数量和关注它的用户数量、它发布的推文数量以及它的推文获得的收藏/已收到的点赞数量。对于 YouTube,我们使用的嵌入是源发布的每个视频的平均观看次数、不喜欢次数和评论次数。对于文章,我们使用 SBERT RoBERTa 模型为每篇文章生成一个768 维向量嵌入,最多前 512 个标记。
A.2.2 模型设置
我们的模型建立在 Python 中的 PyTorch(Paszke 等人,2019 年)和 DGL(深度图库)(Wang 等人,2019 年)之上。我们使用的 R-GCN 由 5 层、128 个隐藏单元组成,学习率为 0.001,节点分类的批量大小为 128。我们的初始源和文章嵌入的隐藏维度为 768,而用户嵌入的维度为 773。最终使用全连接层进行分类,分类大小为3(Baly et al, 2020b)。
对于我们的联合推理和表示学习框架,我们使用开发集(20% 的训练源)为训练数据拆分选择参数,然后在训练最终模型时将它们统一应用于所有拆分。我们最终在所有推理算子收敛之前运行了 2 次迭代(users-sources、articles-articles 和 users-articles 除外)(我们使用开发集确定收敛性),我们假设选择连接边的准确性更高将使我们能够更长时间地运行此过程。表 1 中显示的边数也是根据开发集选择的。
应用推理算子时,我们确保至少 50% 的连接节点连接到不在训练集中的源。例如,要被视为链接到非训练集节点,如果我们连接两个用户,则这些用户中至少有一个需要直接链接到非训练集节点(通过遵循非训练集来源或与来自非训练集来源的文章进行交互)。当部署模型并且推理算子将新文章/源连接到现有节点时,此设置不仅模拟了真实场景,而且还确保该图连接学习到更好的节点。
我们的模型在 12GB TITAN XP GPU 卡上进行训练,为节点分类训练每个数据拆分大约需要 4 小时。添加 20,000 条边的用户-用户推理算子阶段耗时 997.8724 秒,或大约 16 分钟。
A.2.3 先前工作的复制
为了复制 (Baly et al, 2020b) (M4),我们将他们发布的代码与我们的功能结合使用。具体来说,我们使用了我们的文章、Twitter 个人资料、Twitter 关注者和 Y ouTube 嵌入。此设置包含我们图表中的所有数据,并且还提供了 (Baly et al, 2020b) 中的最佳性能。
A.2.4 100%准确率方法的解释
在第 5.1 节中,我们提到了使用 100%准确率运行方法的结果。并表示这是我们方法的潜力。在这里,我们将更详细地解释该设置。
为了获得 100% 准确的边缘,我们需要为用户、文章和来源添加标签。我们使用所有数据(训练、开发和测试集)计算了那些,这是作弊。文章的标签是根据他们直接连接的源计算的(即使它是测试集源),用户的标签是根据他们与之交互的源或他们关注的文章计算的(同样,即使这是一个测试集)。这就是为什么我们认为这是我们方法的一个潜力,因为在实践中我们无法访问测试集标签,因此无法以 100% 的准确度执行此推理过程。
A.2.5 新闻影响者的解释
在第 3.3.2 节中,我们提到了一个推理算子为新闻影响者。在这里做出解释是如何选择新闻影响者:为了选择有影响力的人,我们首先查看图中的每个用户并确定它有多少粉丝;然后,仅使用训练集,确定每个用户的标签(基于他们连接的文章/来源,以及最常见的标签是什么)。我们认为有影响力的人是大多数拥有同样追随者标签的用户。例如,具有主要低真实性用户关注他们的用户很可能是低真实性信息的影响者。
因此,既然我们有了用户标签并且我们知道谁关注了每个用户,我们就可以确定每个潜在影响者的分布。如果最常见的标签(在所有关注他们的人中)和下一个最常见的标签之间的差距大于阈值(我们实验性地将高/混合事实设置为 3000,低为 100,因为它们较少) ,那么我们将用户视为有影响力的人。我们一开始添加了 500 个影响者,然后通过表 3 中的推理算子,又添加了 1000 个。当用户连接到影响者时,它是通过 R-GCN 中的特殊边缘类型完成的。
附录B 假新闻检测分析
在本节中,我们在第 5 节的基础上提供额外的分析实验并进一步详细说明已经讨论过的实验。
B.1 额外分析:图嵌入
在本小节中,我们提出了一个新的分析,试图回答我们的模型嵌入的意义。为此,我们分析了模型训练之前 (a) 和之后 (b) 的文章嵌入,并将它们绘制在图 4 中(红色 = 高真实性,蓝色低,绿色混合)。嵌入表明,我们的推理算子使真实性能够传播到文章的表示中,因为在对图形进行训练后,文章的聚类更加清晰。

B.2 额外分析:推理算子边计数实验
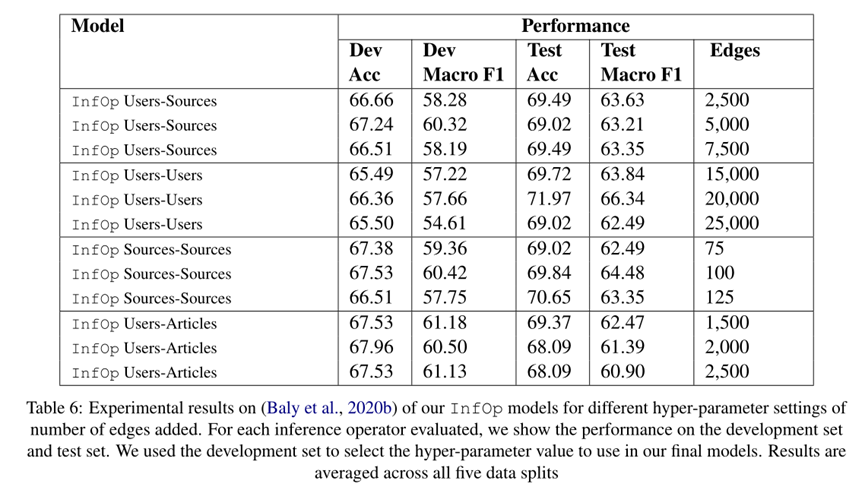
我们详细介绍了每个推理算子的性能如何根据每个推理算子添加的边数而变化。添加边的数量是一个超参数,因为我们可以决定何时停止添加边(我们根据前 k 个相似度分数添加边,k 是超参数)。结果显示在表 6 中。对于每个推理运算符,我们评估三个不同数量的添加边超参数设置,显示测试和开发集(训练集中 20% 的源)的结果。
B.3 额外分析:推理算子运行花费多少时间?
现在,我们评估推理运算符运行多长时间,以表明程序的有效性。我们添加 20,000 个边对用户-用户推理算子进行计,这是任何单一推理运算符中边数最多的。因此,这是计算量最大的推理运算符,除了 articles-articles表现不佳。
在单个 GPU GeForce GTX 1080 Ti GPU 上对其计时,6 个英特尔酷睿 i5-8400 CPU @ 2.80 GHz 处理器超过 5 次运行(所有数据拆分均取平均值)。推理运算符用了 997.8724 秒(刚好超过 16 分钟)。
因此,我们相信我们的程序不涉及巨大的计算和内存成本。这部分是因为我们使用 FAISS (Johnson et al, 2017) 有效地进行嵌入相似性搜索,正如我们在第 3.3 节中提到的那样。其他推理运算符和需要建立较少边缘连接的情况将花费更少的时间,尤其是在更强大的机器上。这也是未来工作的一个有趣方向,我们可以在应添加的边数之间找到适当的平衡,同时考虑它们对性能的影响。
B.4 续分析:推理算子具体实例分析
通过分析所建立的特定边连接来分析推理算子,继续第 5.4 节的分析讨论。看到该模型在连接可能属于同一信息社区的节点时做出了明智的选择。
(1) 一篇讨论民主党人为“危险的开放边界狂热分子”的低真实性文章与生物“BuildtheWall ... DEMONRA TS”的用户有关。
(2) 一位用户的个人简介包含“被环保运动扣为人质”,该用户与主要是低真实性的来源有关,该用户与一篇谈论民主党想要通过“绿色运动”破坏乐趣的文章有关。
(3) 一位用户的个人简介包含“让我们拯救我们的共和国”,该用户与一篇文章有关,该文章提到一位名人在推特上发布了一张著名民主党领袖杀害总统的照片。
(4) 一个生物“为大众制作模因”的用户被连接到另一个生物“在这里玩得开心”的用户。
(5) 两篇关于总统上任第一周的文章被连在一起了。
总的来说,这些例子表明我们的模型可以根据社交媒体上可能存在的信息社区做出决策,因为它连接了谈论相似内容的用户/文章,这正是我们试图捕获的内容。
B.5 续分析:学习信息社区
在这里,我们在第 5.3 节中提供了分析背后的技术细节。在对用户进行聚类时,我们根据用户标签评估纯度。标签是根据每个用户在初始图中直接连接到的源的最常见标签计算的(例如:遵循 3 个高真实性来源的用户被分配了一个高真实性标签)。
我们还使用来自 (Baly et al, 2020b) 的偏差标签评估了用户如何根据偏差标签(表格前两行每个单元格中的第二个数字)进行聚类。
B.6 续分析:合并新闻上下文
在第 5.5 节的分析中,我们想看看我们的模型如何很好地整合以前从未见过的新闻内容。为此,从流行的事实核查网站 PolitiFact 中收集了 1500 条经过事实核查的陈述。每个陈述都由专家按照真实性水平的增加按 1-5 的等级进行标记,我们将其转换为高(前两个)、低(后两个)和混合(其他 - #3),以匹配我们的源标签。然后,我们通过计算每个语句的 RoBERTa 嵌入与所有图文章 RoBERTa 嵌入的相似性,将语句合并到我们的图中。
将每个 PolitiFact 语句连接到它的前 5 个相似图文章,为每个语句生成图嵌入,然后在表 5 D2 中对其进行聚类。然后,应用用户文章推理算子,其中每篇文章现在都是一个 PolitiFact 声明,并在 D3 中再次将它们聚类。这样做时,我们发现所有 k 值的聚类得到改进,表明推理运算符使我们能够更好地捕捉 PolitiFact 陈述的真实性。此外,推理运算符的推理准确率为 51.45%(从与 PolitiFact 语句标签匹配的用户源连接推断出的用户标签),表明该图在选择连接内容时能够做出正确的决策。
附录C 补充材料:假新闻文章检测
对于假新闻文章检测,我们使用了 (Nguyen et al, 2020) 公开发布的数据集。但是,在初始节点嵌入的图形设置中,我们使用 RoBERTa文章嵌入和 Twitter 简介文件嵌入。因此,我们从 (Nguyen et al, 2020) 发布的链接下载了文章文本,并使用 RoBERTa 对其进行了编码,文章的第一行是所使用的声明文本 (Nguyen et al, 2020),如果可用的话.和以前一样,我们对前 512 个标记进行编码。此外,我们下载了 Twitter 个人资料,但我们图表中的用户与 (Nguyen et al, 2020) 相同。在本节的后面,我们还将评估模型的另一个版本,在该版本中我们使用与 (Nguyen et al, 2020) 相同的初始表示,而不是 RoBERTa SBERT 的。
除了初始嵌入之外,我们还抓取了每个使用的社交媒体用户的关注者 (Nguyen et al, 2020),以及图中至少有一个关注另一个的关联用户。如第 3.1 节所述,此过程使我们能够捕获支持虚假新闻传播的社交媒体景观,并有助于我们通过推理运算符建立信息社区。(Nguyen et al, 2020) 还将时间信息纳入了他们的图表,而我们没有这样做。我们假设在我们的设置中添加时间信息将导致进一步的改进,并将其留给未来的工作。
除了这些差异之外,我们的工作与 (Nguyen et al, 2020) (FANG) 相同,只是我们使用推理算子。我们的图表与上面附录中描述的相同(尽管数据不同),来源、用户和文章具有相同的节点/边缘类型。我们使用相同的推理运算符连接过程,使用相同的参数训练相同的 RGCN。
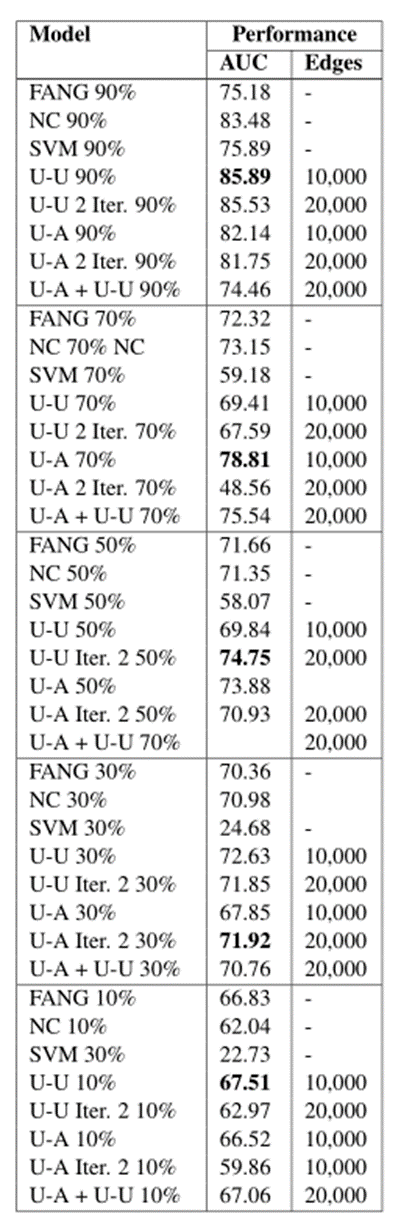
我们下面的扩展实验结果(表 7)显示了不同的推理运算符(将用户连接到用户 -> U-U 并将用户连接到文章 -> U-A,在多次迭代中进行 -> Iter 2,同时进行 -> U-A + UU) 即使在假新闻文章分类上也能提高性能。和以前一样,我们使用开发集来判断收敛性。为了进行完整的评估,我们还包括在不添加推理算子的情况下训练的模型的结果(仅在假新闻文章节点分类 (NC) 上),以及我们在 SVM 中使用我们的文章和社交媒体功能(我们使用网格训练 SVM-搜索参数优化,其中每篇文章的特征是我们在图中使用的 RoBERTa 嵌入加上文章在最终图中连接到的所有用户配置文件的平均值)。 SVM 使我们能够评估与(Nguyen 等人,2020 年)FANG 相比,我们从 Twitter/文章嵌入/其他数据中获得了多少性能改进,可以看到嵌入不会带来强劲的性能。因此,从结果可以看出,与 (Nguyen et al, 2020) (FANG) 相比,我们的图设置以及应用推理算子会带来性能改进,这表明我们的设置对假新闻和文章检测很有用。此外,在初始设置 (NC)应用推理算子,也会得到进一步的性能改进,从而在此任务上取得最佳结果。这显示了使用基于推理算子框架进行假新闻文章检测的好处。结果见表 7。

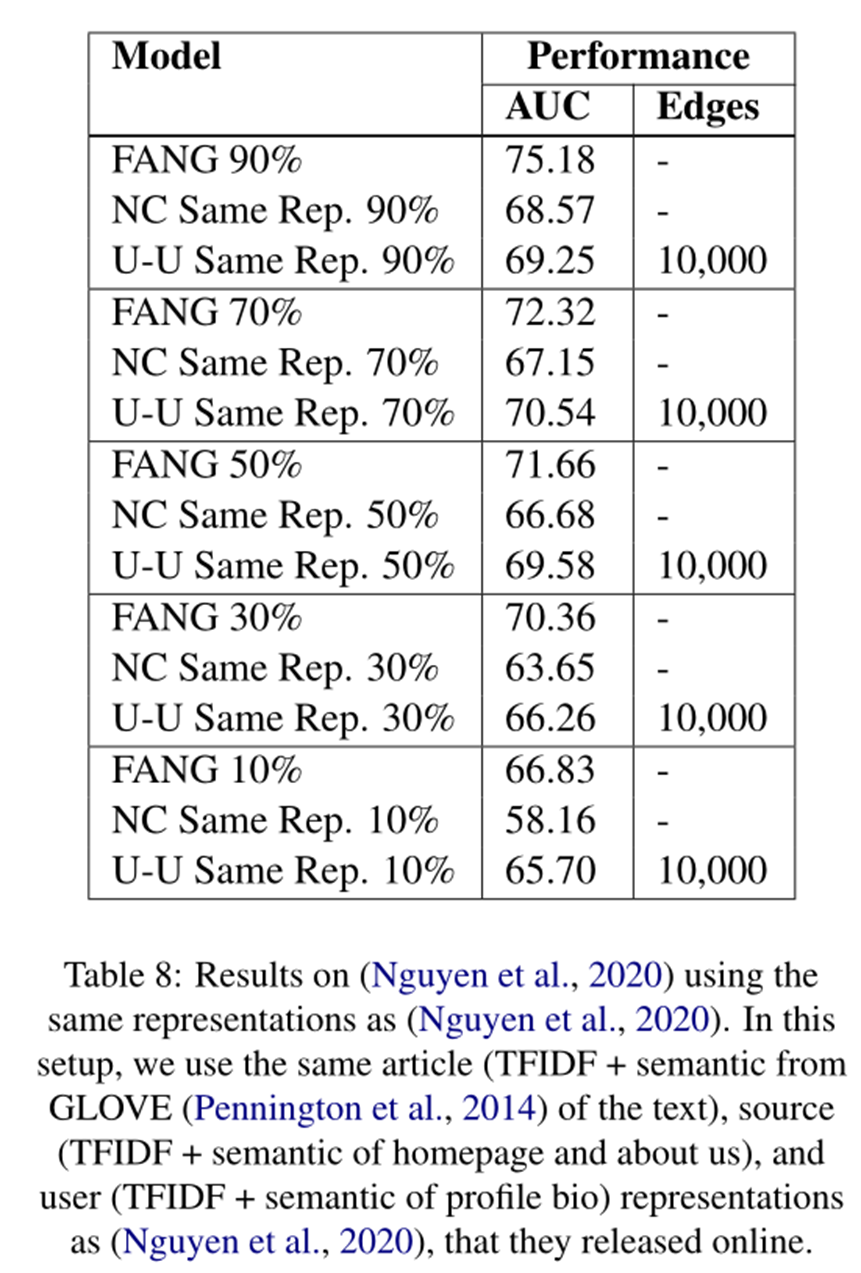
为了进一步分析初始表示,在表 8 中,对文章、来源和用户使用与 (Nguyen et al, 2020) 相同的节点表示时,使用和不使用推理算子评估模型性能。 Nguyen 等人在他们的论文中公开了这些表示,每个表示都是 100 维的(文章是来自 GLOVE 的 TFIDF + 语义,来源是主页和关于我们的 TFIDF + GLOVE 语义,用户是个人资料的 TFIDF + GLOVE 语义)。我们图框架中的其他所有内容都保持不变。因此,与 (Nguyen et al, 2020) 相比,我们的设置现在更弱,因为我们仍然不包括他们使用的时间信息,并且我们没有捕捉 Twitter 用户对文章的立场。即使在这种情况下,我们也看到与节点分类图基线相比,推理运算符可以提高性能,这表明即使初始节点表示较弱,推理算子也可以帮助模型。此外,推理算子模型与 Nguyen 等人的最佳结果竞争。我们假设当推理算子与额外信息结合时,使用(姿态预测/时间数据),整体性能会更高并超过 Nguyen 等人,即使使用与它们相同的嵌入,并将其留给未来的工作。
附录D 补充材料:改进推理
D.1 推理过程
在第 5.1 节中,我们讨论了基于用户-用户推理运算符的方法的潜在扩展,我们不是仅基于嵌入相似性搜索来添加前 k 个边,而是使用全局概率推理方法。在这里,我们将更详细地解释该过程。
在第 3 节的当前方法中,我们考虑了每个推理运算符的所有节点对之间的相似性分数,并选择了前 k 个进行连接,其中 k 是从开发集中确定的。虽然成功,但此过程可能并不总是连接最佳边集。例如,考虑三个用户的情况:A、B、C。假设推理算子决定用边连接 A 和 B,同样地,B 和 C。在这种情况下,很明显 A 和 C 很可能在同一个信息社区中,因为它们都连接到 B(通过传递性属性)。然而,在目前的方法中,如果 A 和 C 的图嵌入不够相似,我们可能不会连接它们。同时,如果 A 和 C 非常不同,或者它们的真实性水平非常不同(由训练集确定),那么我们可能不想将它们连接起来(尽管它们都与 B 连接)。因此,拥有一个允许所有这些决策共同做出的设置将是有益的。
出于这个原因,我们探索如何利用全局关系学习来确定要连接的边。在这项工作中,我们使用了一个名为 DRaiL 的框架(Pacheco 和 Goldwasser,2021)。 DRaiL 是一种概率学习框架,用于使用加权逻辑规则学习关系模型。我们在第 5.1 节的图 3 中将设置描述为因子图。在因子图中,我们定义了两种决策变量类型,F 与用户的真实性预测相关,E 与用户对的推理运算符结果相关。每个都与一个评分函数相关联,ψ1 对用户的真实性分配进行评分,而 ψ2 基于嵌入相似性对用户对进行评分(相似性来自 FAISS,如前所述)。使用两组约束连接分配:C,确保通过预测边连接的用户的事实标签一致性,以及 T,确保跨边对的传递性,共享节点(如上所述)。DRaiL 然后使用 MAP 推理来识别解决方案边集。表中的结果。与局部推理 (71.97) 相比显示出适度的改进 (72.17),使用明显更少的边缘获得(6.7K 与 30K 相比)。每个评分函数 (ψ1, ψ2) 在 MAP 推理问题中被赋予一个权重。对我们来说,由于真实性很重要,我们将 ψ1(用户真实性)加权为 5000,将 ψ2(用户-用户相似性得分)加权为 1.0。每个约束 (C, T) 的权重相等。我们使用开发集通过实验确定了所有权重。
图中每个用户的真实性得分是概率性的,跨越三个值——高、低和混合。我们使用训练集确定用户的真实性标签,其中跟随训练集来源或与训练集文章互动的用户被分配相应来源的标签(如果有多个,则这确定概率 - 例如用户关注 5来源,其中 3 个在训练集中具有高真实性标签,将有 0.6 的概率是高真实性)。对于不与训练集文章进行交互的用户,我们会查看他们在图中最多两跳的所有间接连接(直接连接的节点是一跳)并以这种方式分配标签(例如,一个用户与另一个与文章交互的用户交互将被赋予该文章的标签)。未为此过程分配标签的用户将被忽略,但由于我们的图表连接良好,因此在 69K 中只有 21 个。将来,如果添加了不在训练集中的新来源,并且我们想用它们来计算用户标签(例如,如果他们的用户没有连接到训练集中的任何东西),那么我们也可以使用模型源预测来近似它们的标签。
在从基于 FAISS 的模型中接收到前 k 个相似度分数后,我们称之为候选者(在 users-users 的情况下为 30,000 个候选者),DRaiL 解决了约束 MAP 问题,即根据提供的加权分数和约束来决定添加哪些边(以及上面讨论过)。通过实验测试,我们决定至少添加 5000 个候选边,然后 DRAIL 可以根据哪些解决优化问题进一步添加边。总的来说,在 (Baly et al, 2020b) 和用户-用户推理运算符的数据拆分中,我们平均添加了 6,732 条边。
D.2 推理的好处
使用像 DRaiL 这样的系统进行全局推理有几个好处,我们在这里讨论了其中的一些。
理论上,通过加权评分函数和约束,DRaiL 允许更多的知识被纳入节点连接决策过程,最终可以提高假新闻检测性能。在这里,我们开始探索用户-用户案例,其中我们考虑了模型相似性得分、用户真实性标签和传递性约束。但是,将来还可以添加更多的评分功能和约束,例如增加连接谈论相同事件的用户的可能性。在这种情况下,可以使用语义模型来确定两个用户谈论同一事件的可能性,并且可以将其作为附加评分函数传递给像 DRaiL 这样的系统。同样,也可能有额外的限制。从实验的角度来看,通过使用 DRaiL,我们看到了通过使用明显更少的边(DRaiL 为 6,732 vs 我们的相似性评分方法为 30,000)与我们的初始方法相似的性能改进(在表 3 中略好)。添加较少的边有几个好处,例如引入较少的噪声、速度更快(这也有助于及早发现假新闻),并且不会使图形太大。
未来,随着更多评分函数和约束的添加,以及通过像 DRaiL 这样的优化系统探索更多推理运算符类型,我们可能会看到假新闻检测的性能进一步提高。进一步探索这一点是我们未来工作的一个非常有趣的方向。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix