


Compare to The Knowledge: Graph Neural Fake News Detection with External Knowledge
Compare to The Knowledge: Graph Neural Fake News Detection with External Knowledge
知识对比:基于外部知识的图神经虚假新闻检测
作者:Linmei Hu ;Chuan Shi 北京邮电大学 2021年ACL
https://aclanthology.org/2021.acl-long.62.pdf
概念铺垫:
directed heterogeneous document graph:有向异质文档图
LDA(隐含狄利克雷分布Latent Dirichlet Allocation):
是一种基于贝叶斯思想的无监督的聚类算法,广泛用于文本聚类,文本分析,文本关键词等场景。具体的,算法的输入是一个文档的集合D={d1, d2, d3, ... , dn},同时还需要主题Topic的类别数量m;然后算法会将每一篇文档di在所有Topic上的一个概率值p;这样每篇文档都会得到一个概率的集合di=(dp1,dp2,..., dpm), 表示文档di在m个topic上的概率值;同样的文档中的所有词也会求出它对应每个Topic的概率,wi =(wp1,wp2,wp3,...,wpm);这样就得到了两个矩阵,一个文档到Topic,一个词到Topic。
transE(Translating Embedding):
表示学习旨在学习一系列低维稠密向量来表征语义信息,而知识表示学习是面向知识库中实体和关系的表示学习。transE算法就是一个非常经典的知识表示学习,用分布式表示(distributed representation)来描述知识库中的三元组。
TF-IDF和词袋模型:
做文本分类等问题的时,需要从大量语料中提取特征,并将这些文本特征变换为数值特征。因为机器根本无法处理原始形式的文本数据。他们需要我们将文本分解成一种易于机器阅读的数字格式。
我将用一个流行的例子来解释本文中的Bag of Words(BoW)和TF-IDF。
我们都喜欢看电影(不同程度)。在我决定看一部电影之前,我总是先看它的影评。我知道你们很多人也这么做!所以,我在这里用这个例子。
以下是关于某部恐怖电影的评论示例:
点评一:This movie is very scary and long
点评二:This movie is not scary and is slow
点评三:This movie is spooky and good
l 从文本创建向量
你能想出一些我们可以在一开始就把一个句子向量化的技巧吗?基本要求是:
1) 它不应该导致稀疏矩阵,因为稀疏矩阵会导致高计算成本
2) 我们应该能够保留句子中的大部分语言信息
词嵌入是一种利用向量表示文本的技术。还有2种单词嵌入形式是:
1) Bow,代表词袋
2) TF-IDF,代表词频-逆文本频率
现在,让我们看看如何将上述电影评论表示为嵌入,并为机器学习模型做好准备。
l 词袋(BoW)模型
词袋(BoW)模型是数字文本表示的最简单形式。像单词本身一样,我们可以将一个句子表示为一个词向量包(一个数字串)。
让我们回顾一下我们之前看到的三种类型的电影评论:
点评一:This movie is very scary and long
点评二:This movie is not scary and is slow
点评三:This movie is spooky and good
我们将首先从以上三篇评论中所有的独特词汇中构建一个词汇表。词汇表由这11个单词组成:“This”、“movie”、“is”、“very”、“stear”、“and”、“long”、“not”、“slow”、“spooky”、“good”。
现在,我们可以将这些单词中的每一个用1和0标记在上面的三个电影评论中。这将为我们提供三个用于三个评论的向量:
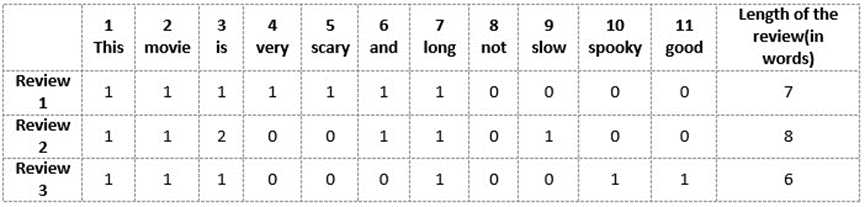
点评向量1:[1 1 1 1 1 1 0 0 0 0]
点评向量2:[1 1 2 0 0 1 0 1 0 0 0]
点评向量3:[1 1 1 0 0 0 1 0 1 1 1 1]
这就是“词袋”(BoW)模型背后的核心思想。
使用单词包(BoW)模型的缺点
在上面的例子中,我们可以得到长度为11的向量。然而,当我们遇到新的句子时,我们开始面临一些问题:
1) 如果新句子包含新词,那么我们的词汇量就会增加,因此向量的长度也会增加。
2) 此外,向量还包含许多0,从而产生稀疏矩阵(这是我们希望避免的)
3) 我们没有保留任何关于句子语法和文本中单词顺序的信息。
l 词频-逆文本频率(TF-IDF)
我们先对TF-IDF下一个正式定义。百科是这样说的:
“TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)”
术语频率(TF)
首先让我们理解术语频繁(TF)。它是衡量一个术语t在文档d中出现的频率:
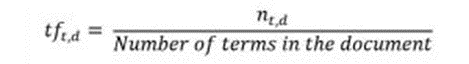
这里,在分子中,n是术语“t”出现在文档“d”中的次数。因此,每个文档和术语都有自己的TF值。
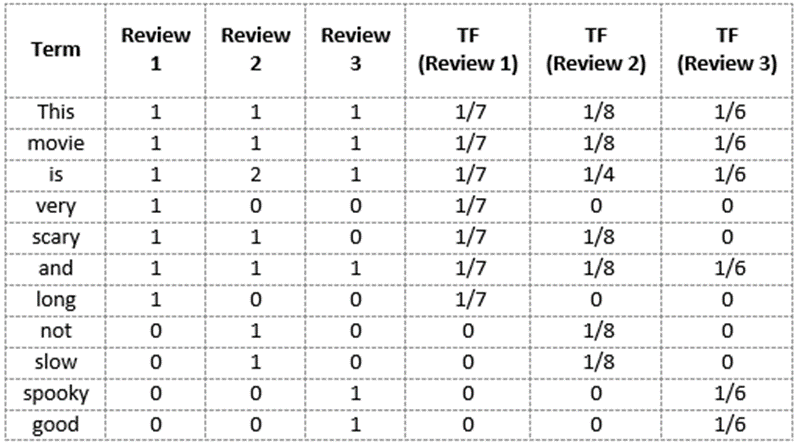
我们再次使用我们在词袋模型中构建的相同词汇表来演示如何计算电影点评2:
点评 2: This movie is not scary and is slow
这里
词汇:“This”,“movie”,“is”,“very”,“stear”,“and”,“long”,“not”,“slow”,“spooky”,“good”
点评2的单词数=8
单词“this”的TF=(点评2中出现“this”的次数)/(点评2中的单词数)=1/8
同样地
TF(‘movie’) = 1/8
TF(‘is’) = 2/8 = 1/4
TF(‘very’) = 0/8 = 0
TF(‘scary’) = 1/8
TF(‘and’) = 1/8
TF(‘long’) = 0/8 = 0
TF(‘not’) = 1/8
TF(‘slow’) = 1/8
TF( ‘spooky’) = 0/8 = 0
TF(‘good’) = 0/8 = 0
我们可以这样计算所有点评的词频:
逆文本频率(IDF)
IDF是衡量一个术语有多重要的指标。我们需要IDF值,因为仅计算TF不足以理解单词的重要性:

我们可以计算点评2中所有单词的IDF值:
IDF('this')=log(文档数/包含“this”一词的文档数)=log(3/3)=log(1)=0
同样地,
IDF(‘movie’, ) = log(3/3) = 0
IDF(‘is’) = log(3/3) = 0
IDF(‘not’) = log(3/1) = log(3) = 0.48
IDF(‘scary’) = log(3/2) = 0.18
IDF(‘and’) = log(3/3) = 0
IDF(‘slow’) = log(3/1) = 0.48
我们可以计算每个单词的IDF值。因此,整个词汇表的IDF值为:
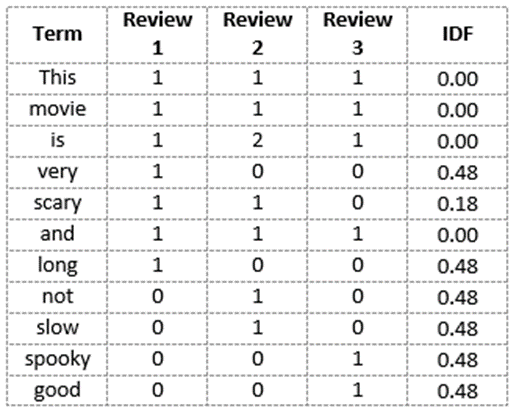
因此,我们看到“is”、“this”、“and”等词被降为0,代表重要性很小;而“scary”、“long”、“good”等词则更为重要,因而具有更高的权值。
我们现在可以计算语料库中每个单词的TF-IDF分数。分数越高的单词越重要,分数越低的单词越不重要:
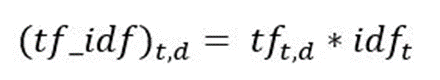
现在,我们可以计算点评2中每个单词的TF-IDF分数:
TF-IDF(‘this’, Review 2) = TF(‘this’, Review 2) * IDF(‘this’) = 1/8 * 0 = 0
同样地
TF-IDF(‘movie’, Review 2) = 1/8 * 0 = 0
TF-IDF(‘is’, Review 2) = 1/4 * 0 = 0
TF-IDF(‘not’, Review 2) = 1/8 * 0.48 = 0.06
TF-IDF(‘scary’, Review 2) = 1/8 * 0.18 = 0.023
TF-IDF(‘and’, Review 2) = 1/8 * 0 = 0
TF-IDF(‘slow’, Review 2) = 1/8 * 0.48 = 0.06
同样地,我们可以计算出对于所有评论的所有单词的TF-IDF分数:
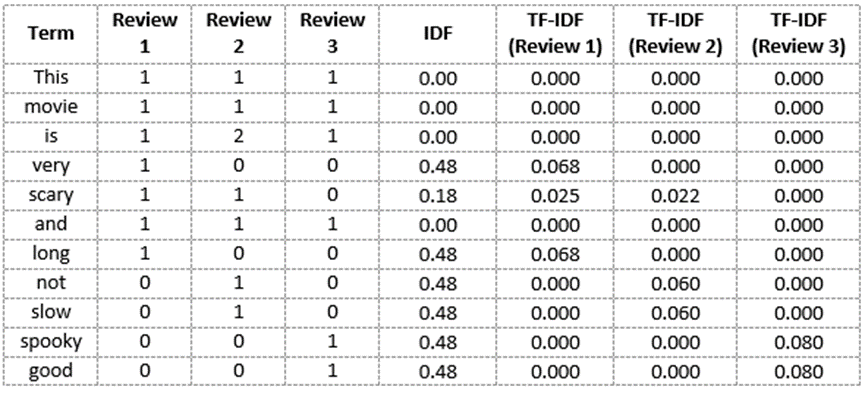
我们现在已经获得了我们词汇的TF-IDF分数。TF-IDF还为频率较低的单词提供较大的值,并且当IDF和TF值都较高时,该值较高。TF-IDF分值高代表该单词在所有文档中都很少见,但在单个文档中很常见。
结尾
词袋只创建一组向量,其中包含文档中的单词出现次数,而TF-IDF模型还包含关于更重要的单词和不重要的单词的信息。
词袋向量很容易解释。然而,在机器学习模型中,TF-IDF通常表现得更好。
虽然“词袋”和“TF-IDF”在各自方面都很受欢迎,但在理解文字背景方面仍然存在空白。检测单词“spooky”和“scary之间的相似性,或者将给定的文档翻译成另一种语言,需要更多关于文档的信息。
摘要
近年来,虚假新闻检测,旨在验证新闻文档是可信的还是伪造的,已越来越受到重视。大多数现有方法严重依赖新闻内容的语言和语义特征,未能有效利用外部知识,而外部知识很可能对确定新闻文档是否可信非常有帮助。在本文中,我们提出了一种名为 CompareNet 的新型端到端图神经模型,该模型通过实体将新闻与知识库 (KB) 进行比较以进行假新闻检测。考虑到假新闻检测与话题/主题相关,我们还整合了主题以丰富新闻的表示。具体地,我们首先为每个包含主题和实体的新闻构建一个有向异质文本图。基于该图,我们设计了一个异质图注意力网络,用于学习主题增强的新闻表示以及编码了新闻内容语义的基于上下文的实体表示。然后通过精心设计的实体对比网络(entity comparison network)将基于上下文的实体表示与相应的基于知识库的实体表示进行对比,以捕获新闻内容和知识库之间的一致性。最后,结合了实体对比特征的主题增强的新闻表示被输入到虚假新闻分类器中。两个基准数据集的实验结果表明,CompareNet 显著优于最先进的方法。
1引言
随着互联网的快速发展,假新闻的生产、传播和消费的机会越来越大。这些主观故意的假新闻很可能会误导读者。假新闻还很容易误导舆论,从而引发严重的信任危机,扰乱社会秩序。众所周知,虚假新闻在2016年美国总统选举时,就产生了不良影响。因此,基于新闻文本的文本内容信息,设计开发有效的虚假新闻检测方法,以尽早发现虚假新闻非常重要。
一些现有的虚假新闻检测方法严重依赖各种手工的语言和语义特征来区分真假新闻。为避免这样的特征工程,一些深度神经网络的方法,如采用Bi-LSTM和卷积神经网络(CNN)等,相继被提出。然而,这些方法没有考虑到文档中的句子交互。表明可信新闻和虚假新闻通常会具有不同的句子交互模式,因此他们将新闻文档建模为一个句子完全图,并提出了一个用于假新闻检测的图注意力模型。尽管这些现有方法一定程度上是有效的,但它们仍然有未能充分利用外部知识库来帮助虚假新闻检测的不足。
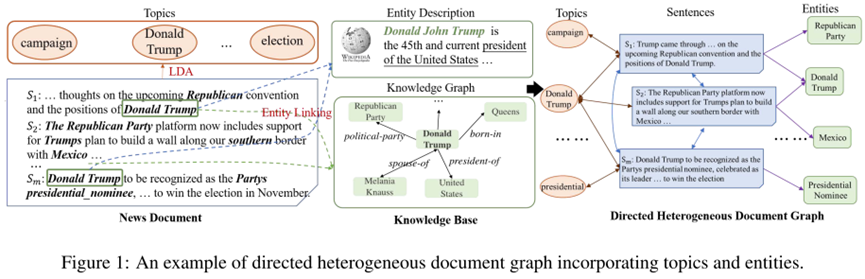
维基百科等外部知识库包含大量高质量的结构化的主谓宾三元组和非结构化的实体描述,这可以作为检测虚假新闻的证据。如图1所示,关于“X光检查不能有效检测乳腺肿瘤”的新闻文档很可能被检测为虚假新闻,因为根据维基百科中的实体描述页面,“乳房X光检查”的目标正是为了尽早发现“乳腺癌”。因此[1]提出从真新闻和假新闻构建一个知识图谱,并应用TransE学习三元组分数,从而进行虚假新闻检测。然而,该方法的性能在很大程度上会受到所构建的知识图谱的影响。在本文中,为了充分利用外部知识,我们提出了一种新颖的端到端的图神经网络模型CompareNet,它以实体为桥梁将新闻与知识库直接进行对比,从而进行虚假新闻检测。在 CompareNet 中,我们还考虑使用主题来丰富新闻文档的表示以进一步提升检测效果,这是因为虚假新闻检测和主题高度相关。例如,“健康”主题的新闻文档更容易偏向于虚假,而“经济”主题的新闻文档则更容易偏向于可信。
具体地,我们首先为每个新闻文档构建一个有向异质文本图,其中包含句子、主题和实体作为节点。句子节点之间被双向全连接。而每个句子还与其最相关的主题节点双向相连。此外如果一个句子包含某个实体,则会建立一个从该句子节点到实体节点的单向链接。单向链接的目的是为了确保我们可以正确学得对新闻语义进行了编码的基于上下文的实体表示,并与此同时避免学习新闻表示的过程中,将真实知识库的实体信息直接引入到文档表示中,从而对检测产生误导的影响。基于该有向异质文本图,我们设计了一个异质图注意力网络来学习主题增强的新闻表示和基于上下文的实体表示。然后将学习到的基于上下文的实体表示与相应的基于知识库的实体表示进行对比,并使用精心设计的实体对比网络捕获新闻内容和外部知识库之间的语义一致性。最后,将主题增强的新闻表示和实体的对比特征结合起来进行最后的虚假新闻分类。
综上所述,我们的主要贡献包括:
- 在本文中,我们提出了一种新颖的端到端的图神经模型CompareNet,它以实体作为桥梁,将新闻与外部知识直接进行对比从而进行虚假新闻检测。
- 在 CompareNet 中也考虑了非常有效的主题信息。我们构建了一个包含了主题和实体的有向异质文本图,然后设计了异质图注意力网络来学习主题增强的新闻表示,最后一个新颖的实体对比网络用于将新闻与知识库进行对比。
- 在两个基准数据集上的大量实验表明,我们的模型通过有效地结合外部知识和主题信息,在虚假新闻检测任务上明显优于最先进的模型。
[1] Content Based Fake News Detection Using Knowledge Graphs
2模型
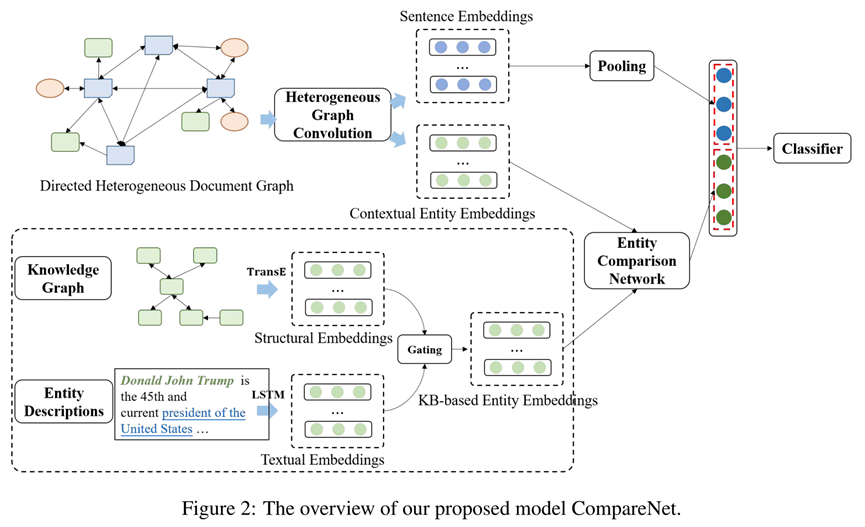
在本节中,我们将详细介绍所提出的虚假新闻检测模型 CompareNet,它直接将新闻与外部知识进行检测。如图2所示,我们还考虑了用主题丰富新闻的表示,因为虚假新闻检测通常是与主题高度相关的。具体来说,我们首先为每个包含主题和实体的新闻文档构建一个有向异质文本图。该文本图可以很好地捕捉句子、主题和实体之间的交互关系。基于该图,我们设计了一个异质图注意力网络来学习主题增强的新闻表示,以及对新闻文档语义进行编码的基于上下文的实体表示。为了充分利用外部知识库,我们将实体作为新闻文档和知识库之间的桥梁。因此我们使用一个精心设计的实体对比网络将基于上下文的实体表示与相应的基于知识库的实体表示进行对比。最后,将获得的实体对比特征与主题增强的新闻文档表示相拼接,最后用于虚假新闻检测。
2.1有向异质文本图
对于每个新闻文档 ,我们构建了一个包含主题和实体的有向异质文本图G = (V, ε),如图1所示。图中共有三种节点:句子S = {s1, s2, · · ·, sm},、主题T ={t1, t2, · · ·, tK}和实体E = {e1, e2, · · ·, en},即V = S ∪ T ∪ E,边的集合ε表示句子、主题和实体之间的关系。构建图的细节描述如下。
我们首先将新闻文档拆分为一组句子。句子在图中彼此双向连接以建模每个句子与其他句子的交互。由于主题信息对于虚假新闻检测很重要,我们使用无监督的LDA模型从我们数据集中的所有文档的所有句子中挖掘潜在主题T。具体地,每个句子都被视为一个伪文档,并被分配到概率最大的前P个相关主题。因此,每个句子也与它分配的前P个主题彼此双向连接,从而允许有用的主题信息在句子之间传播。请注意,我们还可以通过使用训练好的LDA推断新的新闻文档的主题。我们识别文档中的实体,并使用实体链接工具 TAGME 将它们映射到维基百科。若一个句子包含某个实体e,则建立一个从句子到实体的单向边,以便只允许从句子到实体的信息传播。这样,我们可以避免将真正的实体知识直接集成到新闻表示中,而这可能会误导假新闻的检测。
2.2异质图卷积
基于上述构建的有向异质文本图,我们设计了一个异质图注意力网络,用于学习新闻表示以及基于上下文的实体表示。它不仅考虑了不同类型的不同节点的权重,还考虑了异质图中的边方向。
形式化地,我们有具有不同特征空间的三种类型T = {τ1, τ2, τ3}的节点:句子、主题和实体。我们使用 LSTM 对句子进行编码,并得到它的向量表示。实体初始化为基于外部知识库学到的实体表示 (参见下节)。主题则用独热码初始化。
接下来,考虑图G = (V, ε),其中V和ε分别代表节点和边的集合。令X是一个矩阵,包含了所有节点的特征向量xv ∈ RM (其中每行xv是节点v的向量特征)。记A和D分别是邻接矩阵和度矩阵。则异质卷积层通过聚合相邻节点的特征来更新具有不同类型的节点的表示:
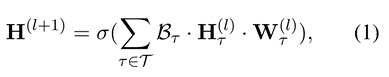
其中σ(·)表示激活函数。不同类型的节点τ有不同的变换矩阵W(l)τ。变换矩阵考虑到了不同的特征空间并将它们投影到相同的隐式特征空间中。Bτ ∈ R|V|×|Vτ |是注意力矩阵,每一行代表一个节点,列代表该节点类型为τ的相邻节点。它的第v行第v’列中的元素βvv’的计算如下:
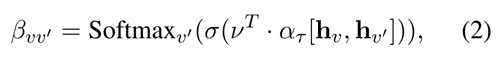
其中v是注意力向量,ατ是类型级别的注意力权重。hv和 hv’分别是当前节点v及其相邻节点v’的表示。Softmax函数用于在节点v的相邻节点之中进行归一化。
我们根据当前节点嵌入hv和类型嵌入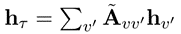 来计算类型级注意力权重 (其中类型嵌入为相邻的类型节点嵌入的加权和,加权矩阵˜A = D-1/2 (A+I)D-1/2是添加了自连接的归一化邻接矩阵),形式化如下所示:
来计算类型级注意力权重 (其中类型嵌入为相邻的类型节点嵌入的加权和,加权矩阵˜A = D-1/2 (A+I)D-1/2是添加了自连接的归一化邻接矩阵),形式化如下所示:
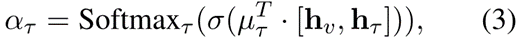
其中µτ是τ类型的注意力向量。Softmax 函数将用于归一化。
经过L层异质图卷积,我们最终可以得到所有节点(包括句子和实体)的聚合了邻域语义的表示。我们对句子节点Hs ∈ RN的表示使用最大池化以获得最终的主题增强的新闻文档嵌入表示Hd ∈ RN。学得的对文档上下文语义进行了编码的实体表示将作为基于上下文的实体表示ec ∈ RN。
2.3 实体对比网络
本小节将详细介绍提出的实体对比网络,该网络将学习到的基于上下文的实体嵌入ec与相应的基于知识库的实体嵌入eKB进行对比。基于下述假设我们认为这样的实体对比特征将可以提升虚假新闻检测的效果,即从可信的新闻文档中学到的基于上下文的实体表示ec可以更好地与相应的基于知识库的实体表示eKB对齐;而对于虚假新闻,则相反。
2.3.1 基于知识库的实体表示
我们将首先介绍如何充分利用知识库(即维基百科)中的结构化的主谓宾三元组和非结构化的实体的文本描述,以学习基于知识库的实体表示eKB。
结构表示。我们可以应用广泛使用的知识图谱嵌入方法来获得结构化的实体嵌入表示。由于TransE 的简单性,这里我们采用 TransE从三元组中学习基于结构的实体表示es ∈ RM。即,给定三元组(h, r, t),TransE将关系r视为从头实体h到尾实体t的翻译向量r,即h+r=t。
文本表示。对于每个实体,我们将相应维基百科页面的第一段作为该实体的文本描述。然后我们使用LSTM 来学习对实体描述进行编码的基于文本的实体表示ed ∈ RM。
基于门控的整合。由于结构三元组和文本描述都为实体提供了有价值的信息,我们需要将这些信息整合到一个联合的表示中。特别地,由于我们有结构嵌入es和文本嵌入ed,我们采用可学习的门控函数来整合这两个不同来源的实体嵌入。形式化地:
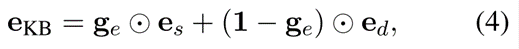
其中ge ∈ RM是一个门控向量(对应于实体),用于对两个来源的信息之间做权衡,其元素的取值范围是[0, 1]。 点乘表示对应元素乘法。门控向量ge意味着,对于es和ed的每个维度,都将通过不同的权重进行相加。为了满足取值范围的约束,我们使用 Sigmoid 函数来计算门控向量 :

其中˜ge ∈ RM是一个实值向量并在训练过程中进行学习。
在将两种类型的嵌入经过门控函数进行了融合后,我们获得了最终的基于知识库的实体嵌入,它对三元组的结构信息和知识库中实体描述的文本信息进行了编码。
实体对比。然后我们在新闻文档和知识库之间,进行实体之间的对比,从而捕获新闻内容和知识库之间的语义一致性。我们计算每个基于上下文的实体表示ec与其对应的基于知识库的实体嵌入ekb之间的对比向量。
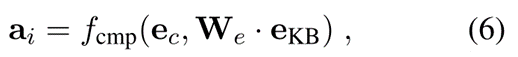
其中f表示对比函数,We是一个变换矩阵。为了衡量嵌入之间的接近程度和相关程度,我们将此对比函数设计为:
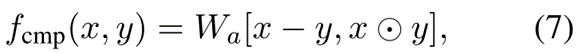
其中Wa是变换矩阵,点乘是 hadamard积,即对应元素的乘积。最终输出的对比特征向量A = [a1, a2, ..., an] 是通过在新闻文档中的所有实体E = {e1, e2, ..., en}的对比向量上使用最大池化获得的。
2.3.2 模型训练
在获得对比向量C ∈ RN和最终的新闻文档表示向量Hd ∈ RN后,我们将它们拼接起来并输入到 Softmax分类层中。如下:

其中W0和b0是线性变换的参数矩阵和偏置向量。在模型训练中,我们使用参数的 L2正则以及训练数据上的交叉熵损失:
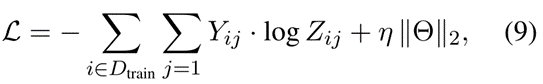
其中Dtrain是新闻文档的训练集,Y是对应的标签指标矩阵,Θ是模型参数,η是正则化因子。我们采用梯度下降算法优化模型。
3实验
3.1主实验
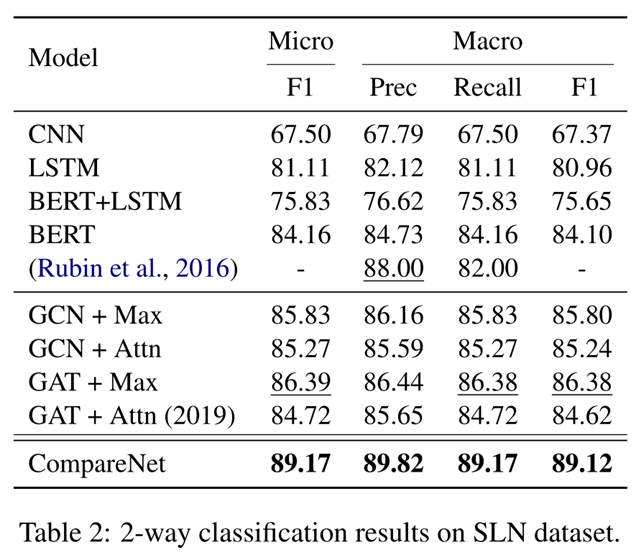
表2 报告了二路分类的实验效果。由于 micro=Precision=Recall=F1,这里我们只报告了 micro F1。正如我们所看到的,我们提出的模型 CompareNet 在所有指标上都明显优于所有最先进的基线方法。与最佳基线模型相比,CompareNet将 micro F1 和 macro F1 提高了近 3%。我们还发现,基于图神经网络的模型 GCN 和 GAT 都比包括 CNN、LSTM 和 BERT在内的序列深度神经模型表现得更好。原因是这些序列深度神经模型不能考虑句子之间的交互,而这对于虚假新闻检测非常重要,因为在真假新闻中观察到的交互模式是不同的。我们的模型CompareNet通过有效利用主题以及外部知识库进一步提升了虚假新闻检测。这些主题丰富了新闻表示,而外部知识库为虚假新闻检测提供了证据。
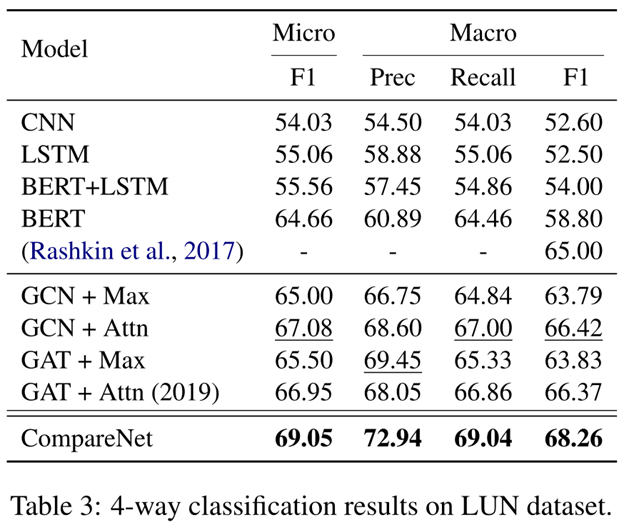
表3展示了四路分类的结果。一致地,可以捕获句子交互的图神经模型都优于深度神经模型。而我们的模型CompareNet 在所有指标上都实现了最佳性能。我们相信这是由于我们的模型CompareNet 受益于主题和外部知识。
3.2消融实验
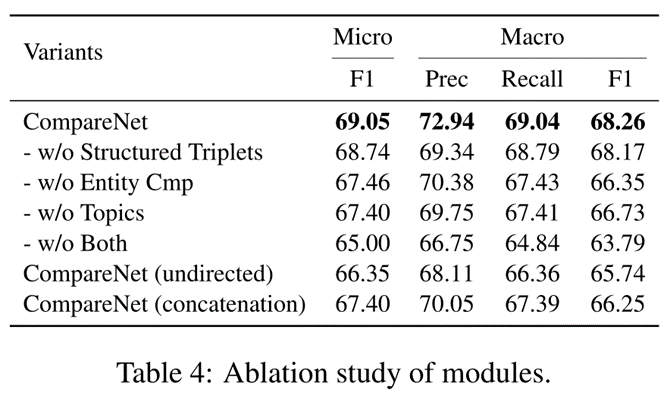
在本小节中,我们实验研究 CompareNet 中每个模块以及我们整合外部知识的方式的有效性。我们在LUN-test上运行5次并报告平均性能。如表4所示,我们测试了CompareNet在去除了结构化三元组、去除了整个外部知识、去除了主题以及同时去除主题和外部知识时的性能。在最后两行中,我们进一步测试了所构建的有向异质文本图和设计的实体对比函数。变体 CompareNet(无向)不考虑有向异质文本图中边的方向。变体模型 CompareNet(concatenate) 使用简单的拼接代替了实体对比函数。正如我们从表 4 中看到的那样,移除了结构化实体知识(即w/o Structured Triplets)会导致轻微的性能下降。但如果我们移除了整个外部知识(即,w/o Entity Cmp),则在 micro F1 和 macro F1 上的性能分别下降约 1.3% 和1.8%。移除主题(即w/o topics)会比较影响性能,这表明主题信息与外部知识一样重要。删除主题和外部知识(即 w/o Both)将导致性能大幅下降(4.0-5.0%)。这展示了主题和外部知识的重要性。变体模型CompareNet(undirected)虽然结合了主题和外部知识,但其性能低于 CompareNet w/o Entity Cmp 和 CompareNet w/o Topics。原因可能是 CompareNet(undirected) 直接将真正的实体知识聚合到图卷积中的新闻表示中了,因为它并没有考虑到边的方向,从而误导了分类器区分真假新闻。这验证了我们构建的有向异质文本图的必要性。最后一个变体 CompareNet(concatenate)的性能也低于 CompareNet w/o Entity Cmp,进一步表明直接拼接真正的实体知识并不是引入实体知识的好方法。与CompareNet相比,它的性能下降了大约 2.0%。这些证明了在 CompareNet 中精心设计的实体对比网络的有效性。

