


BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
BART:用于自然语言生成、翻译和理解的seq2seq去噪预训练器
作者:Mike Lewis等,来自Facebook AI 2019年
论文地址:https://aclanthology.org/2020.acl-main.703.pdf
参考博客:https://zhuanlan.zhihu.com/p/173858031
一、BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
作者:Jacob Devlin 来自google 2019年
BERT的全称是Bidirectional Encoder Representation from Transformers,即基于 Transformer 的双向编码表示器,其中「双向」表示模型在处理某一个词时,它能同时利用前面的词和后面的词两部分信息。这种「双向」的来源在于 BERT 与传统语言模型不同,它不是在给定所有前面词的条件下预测最可能的当前词,而是随机遮掩一些词,并利用所有没被遮掩的词进行预测。
1 BERT的训练任务有两个
Task1:Next Sentence Prediction (NSP),在数据集中抽取两个句子A和B,B有50%的概率是A的下一句,这样通过判断B是否是A的下一句来判断BERT模型。(网上普遍认为关于这种任务BERT完成的并不是很出色,李宏毅老师认为这是因为训练任务太简单,从而学到的东西比较少)。
Task2:Masked LM ,Mask语言模型,传统语言模型是给定所有前面词来预测最可能的当前词,而BERT模型则是随机的使用「mask」来掩盖一些词,并利用所有没有被掩盖的词对这些词进行预测。论文中是随机mask掉15%的词,并且在确定需要mask的词后,80%的情况会使用「mask」来掩盖,10%的情况会使用随机词来替换,10%的情况会保留原词,例如:
原句:xx xx xx xx hello
80%:xx xx xx xx 「mask」
10%:xx xx xx xx world
10%:xx xx xx xx hello
如图1,模型内部用的是transformer机制,也就是当预测w2时,w2的输出综合了1、2、3、4所有的信息,因为w2被mask掉了所以模型必须通过学习才能得到正确的w2,以此方式达到学习的目的。
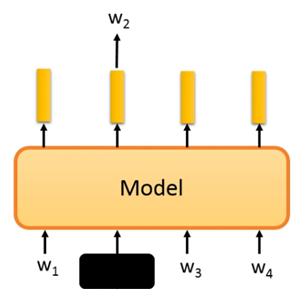
图1 Mask语言模型
2 但是,BERT 不善言辞
具体是指在generate的任务中:
我们暂时认为产生一个文章,产生一个句子的方法应该是从左往右,而BERT的训练方式不是按照文本从左往右的方式生成文本,而是根据上下文,因此根据现在产生一个句子的方法,根据上文写下下一个字,两者是不同的,虽然可以以如下图右侧的方式生成下一个,但是因为与训练的方式不同,因此效果不太理想,因此在这一方面的应用,我们会说BERT是不善言词的。但是此处讨论仅仅针对Auto-regressive的model。
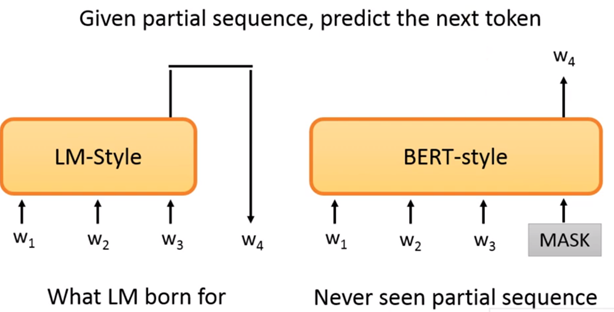
图2
这里再引入两个概念:
Auto-encoding: 把input encoder到一个hidden state再通过试图重构input的方式去学习如何得到一个更优的hidden state。典型的auto-encoding模型像BERT(对应任务是masked language modeling),auto-encoder等等都是。主要用于natural language understanding任务。
Auto-regressive: 仅根据过去的预测信息来预测未来的信息就叫auto-regressive。典型的model像GPT-2。通常用于做natural language generation。而BERT并不擅长。
BERT使用的是transformer的编码部分,因为缺乏generation的能力,所以她可能不太适合用来做seq2seq的预训练模型,假设你是seq2seq的model,那BERT可能只能当作Encoder。那有没有办法使用这种自监督模型对seq2seq进行预训练呢?
二、GPT
GPT:Improving Language Understanding by Generative Pre-Training
论文地址:https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
作者:Alec Radford 来自openAI 2018年
而后还有GPT-2、GPT-3。GPT-3的效果是最惊艳的,最终实现不用微调就可以完成对应领域的任务,我认为这是GPT给人类最大的可能性。
GPT主要是大力出奇迹,在模型设计上没有做什么努力,主要的工作集中在不断加大模型对模型进行训练。简而言之,GPT使用的是transformer的解码部分,顺序生成结果,因此她是seq2seq的,适合文本生成任务,模型局限性是不能双向获取信息,但是大力出奇迹的方式还是让人类看到了更多的可能性。
三、BART
因此,Mike Lewis等人提出了 BART,一种用于预训练seq2seq模型的去噪自动编码器。
BART的全称是Bidirectional and Auto-Regressive Transformers,顾名思义,就是兼具上下文语境信息和自回归特性的Transformer。
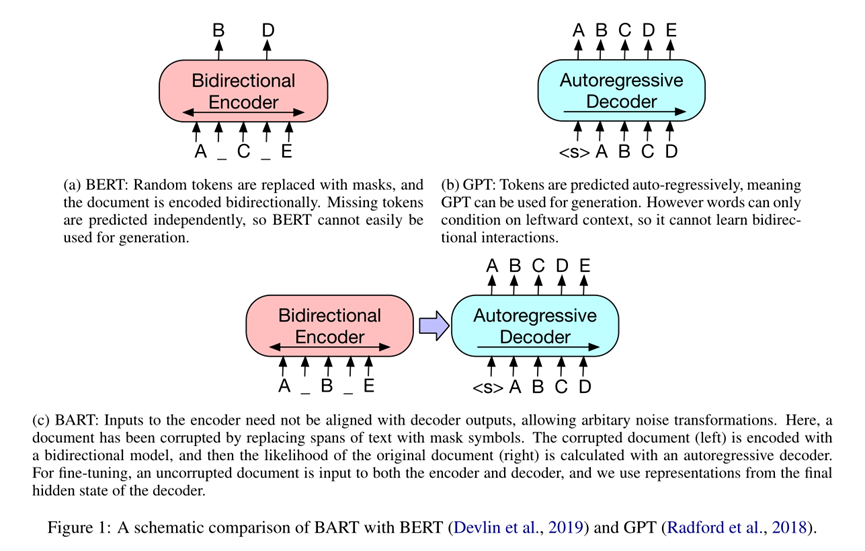
BART 通过以下方式进行训练:(1) 使用任意噪声函数破坏文本。(2) 学习seq2seq模型来重建原始文本。 它使用标准的基于 Transformer 的机器翻译架构,尽管它很简单,但可以看作是对 BERT(双向编码器)、GPT(从左到右解码器)和其他预训练方案的泛化。文章评估了许多噪声方法,通过随机打乱句子的顺序、使用新颖的填充、多个连续文本被单个掩码标记替换等多种方式来找到最佳性能。BART 在针对文本生成进行微调时特别有效,但也适用于理解任务。它与 RoBERTa 在 GLUE 和 SQuAD 上的性能相匹配,并在一系列抽象对话、问答和摘要任务上取得了SOTA。
1 BART结构
GPT是一种Auto-Regressive(自回归)的语言模型。它也可以看作是Transformer model的Decoder部分,它的优化目标就是标准的语言模型目标:序列中所有token的联合概率。GPT采用的是自然序列中的从左到右(或者从右到左)的因式分解。
BERT是一种Auto-Encoding(自编码)的语言模型。它也可以看作是Transformer model的Encoder部分,在输入端随机使用一种特殊的[MASK]token来替换序列中的token,这也可以看作是一种noise,所以BERT也叫Masked Language Model。
BART吸收了BERT的bidirectional encoder和GPT的left-to-right decoder各自的特点,建立在标准的seq2seq Transformer model的基础之上,这使得它比BERT更适合文本生成的场景;相比GPT,也多了双向上下文语境信息。在生成任务上获得进步的同时,它也可以在一些文本理解类任务上取得SOTA。
BART是一个encoder-decoder的结构,其encoder端的输入是加了噪音的序列,decoder端的输入是right-shifted(右移)的序列,decoder端的目标是原序列。模型设计的目的很明确,就是在利用encoder端的双向建模能力的同时,保留自回归的特性,以适用于生成任务。
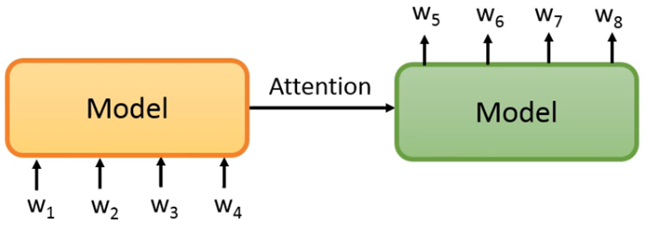
对于自监督方式(自监督学习从数据本身获得监督信号)预训练seq2seq模型而言,假设模型如下图所示,那么重新构造的w5、w6、w7、w8应该是与输入w1、w2、w3、w4一致的,那对模型而言直接一一对应复制过来就好了,这样的话模型无法得到学习,因此,最简单的方法就是对输入w1、w2、w3、w4进行破坏,破坏的方法有很多种,比如此处BART提到的五种。
2 BART预训练
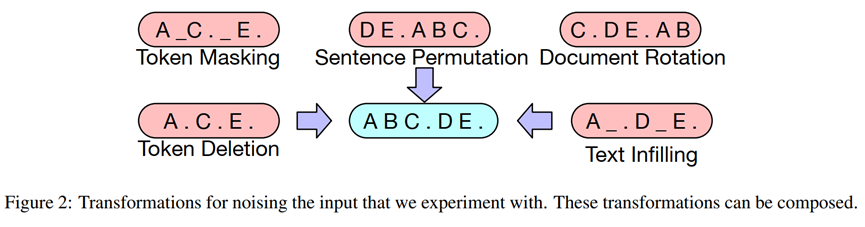
BART是通过破坏文档,然后优化重建损失(解码器输出和原始文档之间的交叉熵)来训练的。与现有的去噪自动编码器不同,BART允许应用任何类型的文件损坏。在极端情况下,所有关于源的信息都会丢失。如下Figure 2。
l Token Masking:使用[MASK]随机替代tokens
l Token Deletion:随机删除tokens,模型通过找到删除的位置进行学习
l Text Infilling:对多个spans进行抽样,每个span的长度符合λ=3的泊松分布,每个span即0-n长度的tokens被替换为[MASK]。
l Sentence Permutation:调换句子顺序,让模型学习句子顺序
l Document Rotation:在末尾随机选取1-n个token,作为一个整体放到开始位置,让模型学习识别文本开头。
3 BART微调
BART生成的表示可以使用以下几种方式用于下游应用程序。
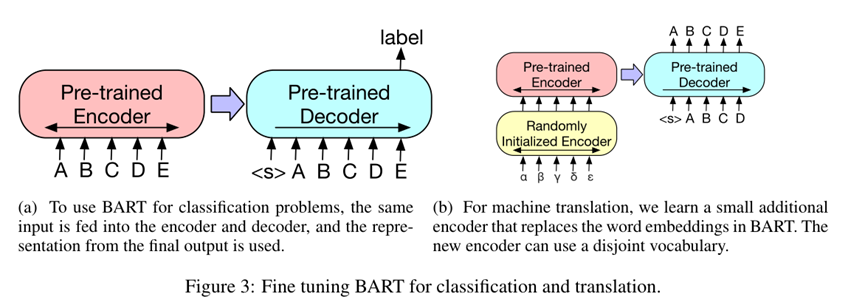
1) 序列分类任务
将该序列同时输入给encoder端和decoder端,然后取decoder最后一个token对应的final hidden state作为label,输入给一个线性多分类器。注意在序列的最后要加一个token,保证seq2seq模型输出的label包含序列中每一个token的信息(因为decoder的输入是right-shifted的,不这样做的话label将不包含最后一个token的信息) (Figure 3a)。
2) Token分类任务
将完整的文档输入编码器和解码器,并使用解码器的顶部隐藏状态作为每个单词的表示。这种表示方式用于对token进行分类。
3) 序列生成任务
因为BART有一个自回归解码器,它可以直接微调序列生成任务,如抽象问题回答和总结。在这两种任务中,信息都是从输入中复制但进行了操作,这与去噪训练前的目标密切相关。这里,编码器输入是输入序列,解码器自回归生成输出。
4) 机器翻译
将BART的encoder端的embedding层替换成randomly initialized encoder,新的encoder也可以用不同的vocabulary。通过新加的Encoder,我们可以将新的语言映射到BART能解码到English(假设BART是在English的语料上进行的预训练)的空间。具体的finetune过程分两阶段:
第一步只更新randomly initialized encoder + BART positional embedding + BART的encoder第一层的self-attention 输入映射矩阵。
第二步更新全部参数,但是只训练很少的几轮。
4 与不同预训练模型比较
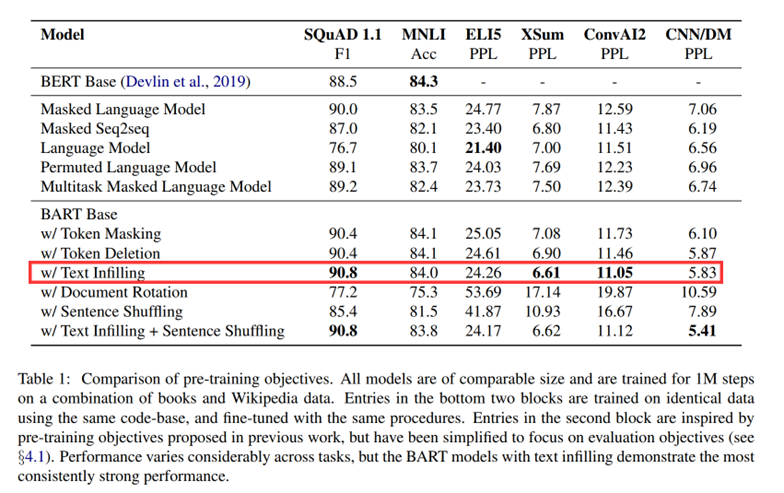
如table 1。
比较的预训练模型有:
1) GPT: (Auto-Regressive) Language model
2) XLNET: Permuted Language Model
3) BERT: Masked Language Model
4) UniLM: Multitask Masked Language Model
5) MASS: Masked Seq-to-Seq
涉及的下游任务有:
1) SQuAD: 将context和question连在一起输入Encoder和Decoder,输出的是context中的span。
2) MNLI: 将2个句子连在一起输入Encoder和Decoder(中间加上[EOS]表示隔开),模型输出的是两个句子之间的关系,是典型的序列分类问题。
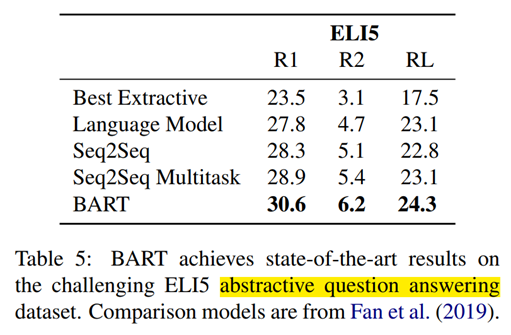
3) ELI5: 抽象的问答,将context和question连在一起输入,模型输出抽象摘要文本。
4) XSum: 新闻摘要生成任务
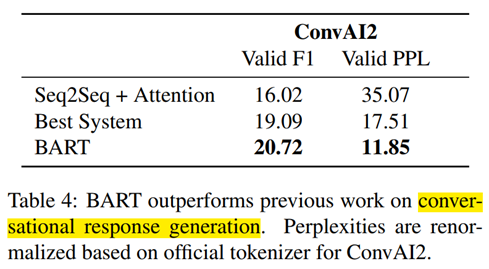
5) ConvAI2: 对话生成任务
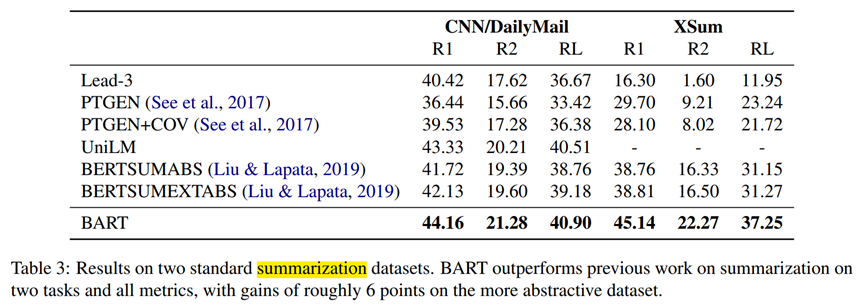
6) CNN/DM:摘要生成任务
结论:
不同预训练方法表现差异显著,预训练方法是否有效高度依赖于下游任务。例如,一个简单的GPT可以获得最好的ELI5性能,但是得到最差的SQUAD结果。
Token的MASK机制很重要,调换句子顺序或者循环位移单独作用时表现很差,成功的方法要么使用了token删除或MASK,要么使用了自注意MASK,删除token的方式似乎在生成任务上优于MASK。
对于SQuAD任务而言双向编码很重要,单向解码器在SQuAD上表现不佳,因为基于上下文的预测对于分类决策问题很关键,然而,BART只需要一半的双向层数量就可以实现类似的性能。
纯语言模型在ELI5上表现最好,ELI5数据集是一个异常值,其复杂程度远远高于其他任务,也是唯一一个其他模型优于BART的生成任务。这表明当输出仅受输入的松散约束时,BART的效率较低。
BART实现了最强大的性能。除了ELI5之外,使用文本填充的BART模型在所有任务中都表现良好。
5 大规模预训练实验
当预训练和语料库规模大时,下游任务性能可以显著提高。为了测试BART在这种模式下的表现,并为下游任务创建一个有用的模型,我们使用与RoBERTa模型相同的规模来训练BART。
1)实验参数设置
编码器和解码器均为12层,隐藏层大小为1024,batch size为8000,epoch为500000。
2)判别任务实验
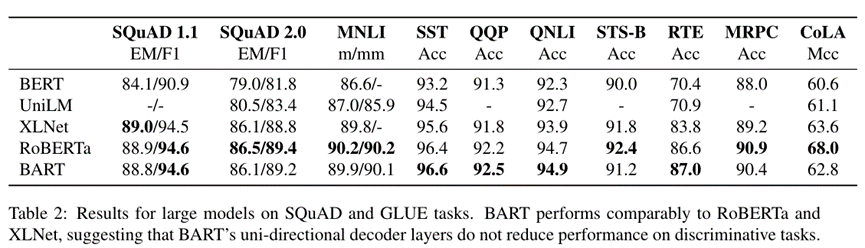
Table 2比较了BART和其他最新几种模型在SQuAD和自然语言理解(NLU)任务上的表现。
结果表明在NLU任务上与较基线RoBERTa模型比较效果持平。这表明BART在生成任务上的改进并不是以牺牲分类性能为代价的。
3)生成任务实验
摘要
对话生成
摘要式问答
4)翻译任务实验


