


《PyTorch深度学习实践》-刘二大人 第八讲
课堂练习:
1 import torch 2 import numpy as np 3 from torch.utils.data import Dataset 4 from torch.utils.data import DataLoader 5 6 # prepare dataset 7 class DiabetesDataset(Dataset): 8 def __init__(self, filepath): 9 xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32) 10 self.len = xy.shape[0] # shape(多少行,多少列) 11 self.x_data = torch.from_numpy(xy[:, :-1]) 12 self.y_data = torch.from_numpy(xy[:, [-1]]) 13 14 def __getitem__(self, index): 15 return self.x_data[index], self.y_data[index] 16 17 def __len__(self): 18 return self.len 19 20 dataset = DiabetesDataset('diabetes.csv') 21 train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2) # num_workers 多线程 22 23 # design model using class 24 class Model(torch.nn.Module): 25 def __init__(self): 26 super(Model, self).__init__() 27 self.linear1 = torch.nn.Linear(8, 6) 28 self.linear2 = torch.nn.Linear(6, 4) 29 self.linear3 = torch.nn.Linear(4, 1) 30 self.sigmoid = torch.nn.Sigmoid() 31 32 def forward(self, x): 33 x = self.sigmoid(self.linear1(x)) 34 x = self.sigmoid(self.linear2(x)) 35 x = self.sigmoid(self.linear3(x)) 36 return x 37 model = Model() 38 39 # construct loss and optimizer 40 criterion = torch.nn.BCELoss(reduction='mean') 41 optimizer = torch.optim.SGD(model.parameters(), lr=0.01) 42 43 # training cycle forward, backward, update 44 if __name__ == '__main__': 45 #sum1=0 46 for epoch in range(10): 47 #此处数据集大小为759条,根据设置batch_size=32,所以需要759/32=23.7即24次循环才能遍历完,因此每个epoch会执行24次内循环 48 for i, data in enumerate(train_loader, 0): # train_loader 是先shuffle后mini_batch 49 inputs, labels = data 50 y_pred = model(inputs) 51 loss = criterion(y_pred, labels) 52 #print(epoch, i, loss.item()) 53 54 optimizer.zero_grad() 55 loss.backward() 56 57 optimizer.step() 58 #sum1+= 1 59 #print(sum1)
在网上找的一个作业,怎么调参数都不收敛,我觉得是失败了,主要是电脑不太能支持,参数稍微调大一点就运行好几十分钟,然鹅我这个穷人又没有服务器……
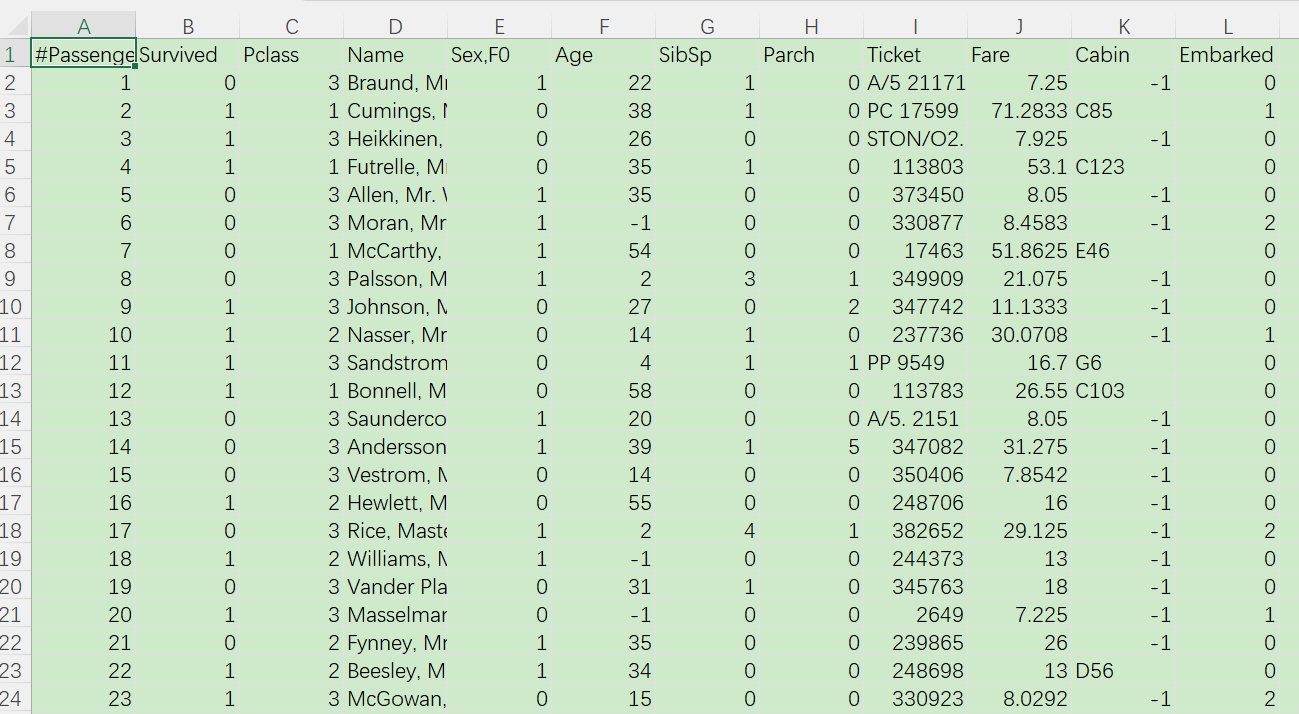
数据集从kaggle上下,第一行添加#注释掉,替换掉空格为-1,不然运行的时候会提醒有空格,同样用数字替换掉性别还有最后栏的CSQ几个值,可能还有未尽事宜,请见招拆招!
data提取百度链接:https://pan.baidu.com/s/1S67KwdF0lyezlUDWzPkwpw
提取码:5a4i
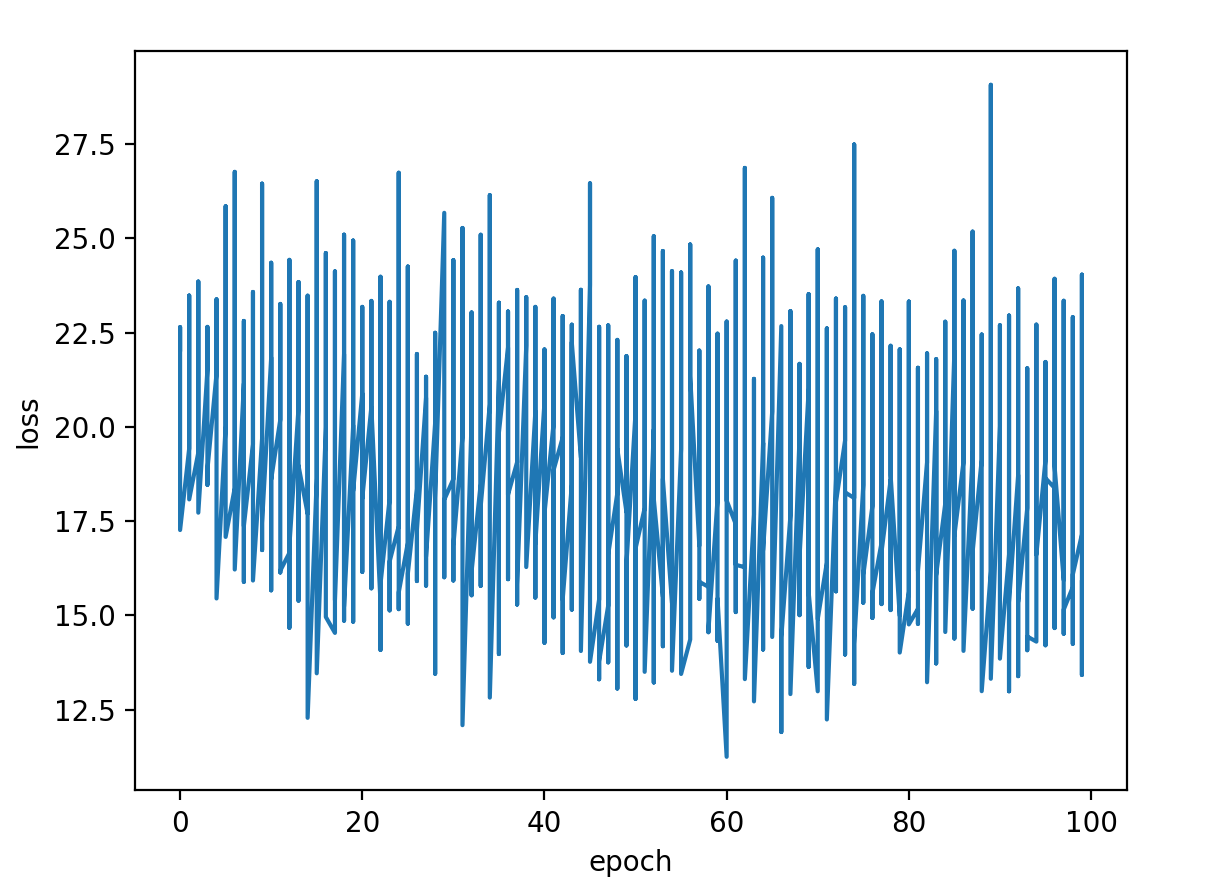
给大家看看我这失败的结果……
1 import torch 2 from torch.utils.data import Dataset 3 from torch.utils.data import DataLoader 4 import numpy as np 5 import matplotlib.pyplot as plt 6 import os 7 os.environ['KMP_DUPLICATE_LIB_OK']='True' 8 9 class titanicDataset(Dataset): 10 def __init__(self, filepath): 11 x = np.loadtxt(filepath, delimiter=',', dtype=np.float32, usecols=(2, 5, 6, 7, 8, 10, 12)) 12 # 上面只取有效特征,类似人名,票号等唯一特征对训练没用就没取。 13 y = np.loadtxt(filepath, delimiter=',', dtype=np.float32, usecols=1) 14 # 'delimiter'为分隔符 15 y = y[:, np.newaxis] 16 # 这里增加一维,不然计算loss的时候维度不同会报错 17 18 self.x_data = torch.from_numpy(x) 19 self.y_data = torch.from_numpy(y) 20 self.len = x.shape[0] 21 22 def __getitem__(self, index): 23 return self.x_data[index], self.y_data[index] 24 25 def __len__(self): 26 return self.len 27 28 29 dataset = titanicDataset('Titanic/train.csv') # 读数据集 30 # print(dataset.x_data,'\n',dataset.y_data) 31 train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2) # 将数据集分成小批量 32 33 34 # 读测试集数据 35 class test(Dataset): 36 def __init__(self, filepath): 37 x = np.loadtxt(filepath, delimiter=',', dtype=np.float32, usecols=(1, 4, 5, 6, 7, 9, 11)) 38 self.len = x.shape[0] 39 self.x = torch.from_numpy(x) 40 41 def __getitem__(self, index): 42 return self.x[index] 43 44 def __len__(self): 45 return self.len 46 47 48 testset = test('Titanic/test.csv') # 测试集 49 testset = testset.x 50 51 52 # ---设计模型 53 class Model(torch.nn.Module): 54 def __init__(self): 55 super(Model, self).__init__() 56 self.linear1 = torch.nn.Linear(7, 6) 57 self.linear2 = torch.nn.Linear(6, 3) 58 self.linear3 = torch.nn.Linear(3, 1) 59 self.sigmoid = torch.nn.Sigmoid() 60 # self.activate = torch.nn.ReLU() 61 62 def forward(self, x): 63 x = self.sigmoid(self.linear1(x)) 64 x = self.sigmoid(self.linear2(x)) 65 x = self.sigmoid(self.linear3(x)) 66 return x 67 68 69 model = Model() 70 # ---设计模型 71 72 # ---计算损失和更新 73 criterion = torch.nn.BCELoss(reduction='sum') 74 optimizer = torch.optim.SGD(model.parameters(), lr=0.01) 75 # ---计算损失和更新 76 77 # 自己写了一个保存到csv表格的函数 78 import pandas as pd 79 80 def save(num, value, filepath): 81 dataframe = pd.DataFrame({'PassengerId': num,'Survived': value}) 82 # 将DataFrame存储为csv,index表示是否显示行名,default=True 83 dataframe.to_csv(filepath, index=False, sep=',') 84 85 loss_list = [] 86 epoch_list = [] 87 # ---训练 88 if __name__ == '__main__': 89 for epoch in range(100): 90 for i, data in enumerate(train_loader, 0): 91 # 1 Prepare data 92 inputs, labels = data 93 # 2 Forward 94 y_pred = model(inputs) 95 loss = criterion(y_pred, labels) 96 #画图数据 97 epoch_list.append(epoch) 98 loss_list.append(loss.item()) 99 # 3 Backward 100 optimizer.zero_grad() 101 loss.backward() 102 # 4 Update 103 optimizer.step() # 更新权重 104 105 # ---训练 106 # print('w= ', model.linear1.weight.shape) 107 # print('b = ',model.linear1.bias.shape)#输出参数 108 109 y_pred = model(testset) 110 num = y_pred.shape[0] # 测试集个数,按个数预测结果 111 test_value = [] 112 for i in range(num): 113 if y_pred.data[i] < 0.5: 114 test_value.append(0) 115 else: 116 test_value.append(1) 117 # print('测试结果为:', test_value) 118 119 # 892-1309 120 num = [] 121 for i in range(892, 1310): 122 num.append(i) 123 save(num, test_value, 'Titanic/value.csv') 124 125 plt.plot(epoch_list, loss_list) 126 plt.ylabel('loss') 127 plt.xlabel('epoch') 128 plt.show()

