在线社交网络文本内容对抗技术
来源:[1]刘晓明,张兆晗,杨晨阳,张宇辰,沈超,周亚东,管晓宏.在线社交网络文本内容对抗技术[J].计算机学报,2022,45(08):1571-1597.
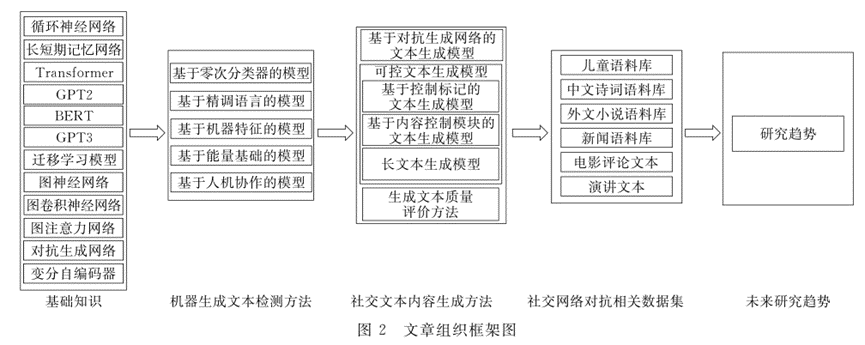
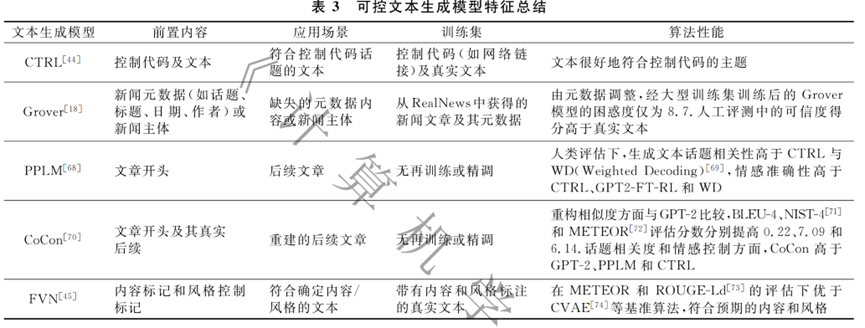
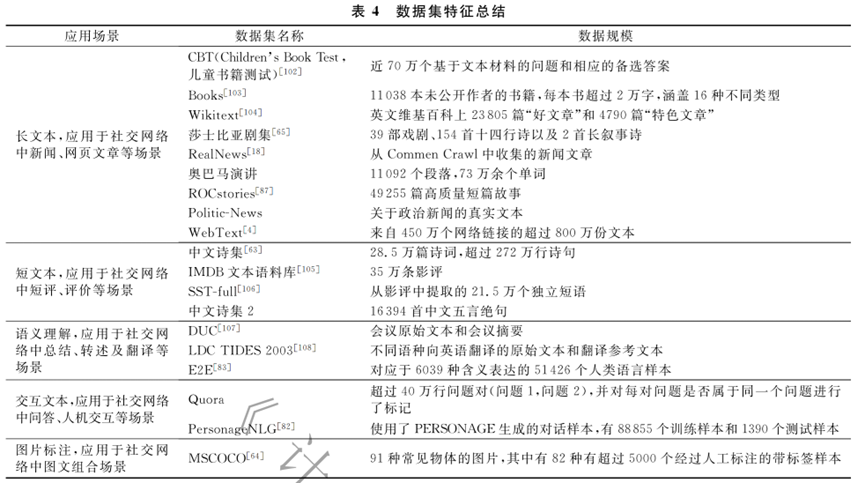
从文本内容生成与检测两方面对在线社交网络对抗进行阐述。针对社交网络文本内容检测方法,从基于零次分类器的模型、基于机器特征的模型、基于预训练语言模型的方法、基于人机协作的模型、基于能量基础的模型5个角度进行详细介绍。针对社交网络文本生成方法,对基于对抗生成网络的文本生成模型、可控文本生成模型、长文本生成、文本质量评价4方面进行了综述。还介绍了几个数据集。最下面几个图总结的很有条理。
未来研究方向:
1 增强检测与生成方法的泛化能
现有的文本检测与生成方法对模型的设定与训练数据集有非常强的依赖。说人话就是现在的研究出来的东西适应范围有限,没有以一顶百的效果,很多模型换个场景就不好用了,可以理解为人工智能其实还不够智能。
2 增强检测与生成方法的可解释
机器学习能打败围棋冠军、电竞冠军,在图形识别语音识别也做的很好,人类在这件事情上想要探究为什么这些机器学习模型能做的如此好,而不是经常用“玄学”来搪塞,这样我们才能预知机器什么时候是正常的什么时候又会出现错误。中国有句古话“知己知彼,百战百胜”,如果人类想要绝对地将人工智能纳入囊中,就必须要充分了解她,这样我们才能绝对信任这些智能化产物,这样就不会有“人工智能统治地球”这种恐慌了,而且有了解释你才能知道对于自动驾驶什么情况下会出现问题,你才会大胆放心的解放双手。(记得经历过的一次公务员面试,题目大概是“谈谈对人工智能会统治地球的看法”,旁边确实好几个答的“会”,但是就我目前的观点,人工智能还远不够智能,可能是我知道的太少……)
3 基于外部知识图谱的事实核查机制
说实话,这条不理解,我继续努力……
4 增强检测与生成方法的鲁棒性
5 增强语言模型的易用性
后面两条就感觉,,,嗯,就这样吧……
个人感觉前两条比较有参考价值