


第2章 大数据处理架构Hadoop(二)
2.4 分布式文件系统HDFS及其命令
2.4.1 分布式文件系统与HDFS(Distributed File System)
数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
分布式文件系统是一种允许文件通过网络在多台主机上分享的文件系统,可让多台机器上的多用户分享文件和存储空间。
特性:
- 通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
- 容错。即使系统中有某些节点脱机,整体来说系统仍然可以持续运作而不会有数据损失。
分布式文件管理系统很多,hdfs只是其中一种。适用于一次写入多次查询的情况,不支持并发写情况,小文件不合适。
2.4.2 HDFS体系结构
HDFS为了做到可靠性(reliability)创建了多份数据块(data blocks)的复制(replicas),并将它们放置在服务器群的计算节点中(compute nodes),MapReduce就可以在它们所在的节点上处理这些数据了。

(1)文件写入。首先Client向NameNode发起文件写入的请求,NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
(2)文件读取。Client向NameNode发起文件读取的请求,NameNode返回文件存储的DataNode的信息。Client根据返回的信息读取DataNode上的文件信息。
(3)文件Block复制。NameNode发现部分文件的Block不符合最小复制数或者部分DataNode失效,通知DataNode相互复制Block。DataNode收到通知后开始直接相互复制。

1、NameNode
- 主节点,系统状态监控与调度
- 负载均衡
- 副本迁移
- 元数据管理
- Block与datanode映射
- 文件系统镜像文件
- 操作日志文件
- checkpoint
2、DataNode
- 从节点,数据存储
- 向client提供数据读写服务
- 执行数据块创建、拷贝或删除命令
- 定期向NameNode汇报
- 心跳包
- 状态
2.4.3 HDFS相关概念
——保障可靠性的措施
- 一个名字节点和多个数据节点
- 数据复制(冗余机制)
- 存放的位置(机架感知策略)
- 故障检测
- 数据节点
心跳包(检测是否宕机)
块报告(安全模式下检测)
数据完整性检测(校验和比较)
2.名字节点(日志文件,镜像文件)
- 空间回收机制
- 块
- HDFS使用了块的概念,默认大小设为128M字节
- HDFS将一个文件分为一个或数个块来存储
- 与传统文件系统不同的是,如果实际数据没有达到块大小,则并不实际占用磁盘空间
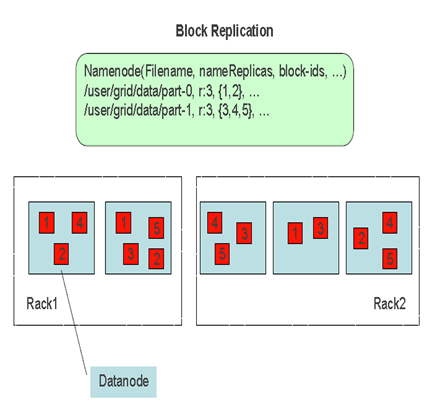
——写文件流程
- 客户端缓存
- 流水线复制
- 并发写控制
- 流程:
1) 客户端把数据缓存到本地临时文件夹
2) 临时文件夹数据超过128M,客户端联系NameNode, NameNode分配DataNode,DataNode依照客户端的位置被排列成一个有着最近物理距离和最小的序列
3) 与序列的第一个数据服务器建立Socket连接,发送请求头,然后等待回应,依次下传,客户端得到回包,流水线建立成功
4) 正式发送数据
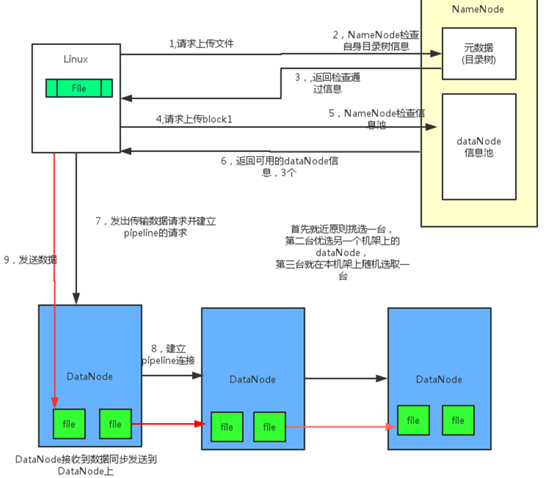
——读文件流程
1) 客户端联系NameNode,得到所有数据块信息,以及数据块对应的所有数据服务器的位置信息
2) 尝试从某个数据块对应的一组数据服务器中选出一个,进行连接(选取算法未加入相对位置的考虑)
3) 数据被一个包一个包发送回客户端,等到整个数据块的数据都被读取完了,就会断开此链接,尝试连接下一个数据块对应的数据服务器,整个流程,依次如此反复,直到所有想读的都读取完了为止

——元数据
- 元数据包括
文件系统目录树信息,文件名,目录名
文件和目录的从属关系
文件和目录的大小,创建及最后访问时间, 权限
- 文件和块的对应关系
文件由哪些块组成
- 块的存放位置
机器名,块ID
HDFS对元数据和实际数据采取分别存储的方法
– 元数据存储在一台指定的服务器上(NameNode)
– 实际数据储存在集群的其他机器的本地文件系统中(DataNode)机制
NameNode里使用两个非常重要的本地文件来保存元数据信息:
- fsimage
fsimage里保存了文件系统目录树信息
fsimage里保存了文件和块的对应关系
- edits
edits保存文件系统的更改记录(journal)
当客户端对文件进行写操作(包括新建或移动)的时候,操作首先记入edits,成功后才会 更改内存中的数据
并不会立刻更改硬盘上的fsimage
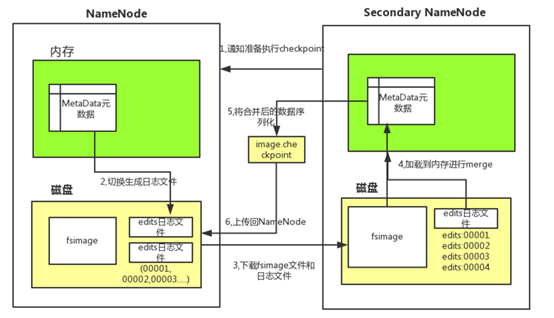
——Secondary NameNode的运行过程
1) Secondary NameNode根据配置好的策略决定多久做一次合并( fs.checkpoint.period 和 fs.checkpoint.size )
2) 通知NameNode现在需要回滚edits日志,此时NameNode的新操作将写入新的edits文件
3) Secondary NameNode通过HTTP从NameNode取得fsimage和edits
4) Secondary NameNode将fsimage载入内存,执行所有edits中的操作,新建新的完整的fsimage
5) Secondary NameNode将新的fsimage传回NameNode
6) NameNode替换为新的fsimage并且记录此checkpoint的时间
2.4.4 HDFS的shell操作
- 调用文件系统(FS)Shell命令应使用 hadoop fs 的形式 hdfs dfs
所有的FS shell命令使用URI路径作为参数。
URI格式是scheme://authority/path。HDFS的scheme是hdfs,对本地文件系统,scheme是file。其中scheme和authority参数都是可选的,如果未加指定,就会使用配置中指定的默认scheme。
例如:/parent/child可以表示成hdfs://namenode:namenodePort/parent/child,或者更简单的/parent/child(假设配置文件是namenode:namenodePort)
- 大多数FS Shell命令的行为和对应的Unix Shell命令类似
- hdfs命令以hadoop fs或者hdfs dfs开头
- HDFS的shell命令在线帮助
1. hadoop fs
使用此命令可以查看HDFS的所有常用命令语法
2.hadoop fs help
使用此命令可以查看HDFS的所有常用命令语法
3. hadoop fs –help 命令
查看某个命令的具体功能
HDFS的fs命令
-help [cmd] //显示命令的帮助信息 -ls(r) <path> //显示当前目录下所有文件 -du(s) <path> //显示目录中所有文件大小 -count[-q] <path> //显示目录中文件数量 -mv <src> <dst> //移动多个文件到目标目录 -cp <src> <dst> //复制多个文件到目标目录 -rm -r //删除文件(夹) -put <localsrc> <dst> //本地文件复制到hdfs -copyFromLocal //同put -moveFromLocal //从本地文件移动到hdfs -get [-ignoreCrc] <src> <localdst> //复制文件到本地,可以忽略crc校验 -getmerge <src> <localdst> //将源目录中的所有文件排序合并到一个文件中 -cat <src> //在终端显示文件内容 -text <src> //在终端显示文件内容 -copyToLocal [-ignoreCrc] <src> <localdst> //复制到本地 -moveToLocal <src> <localdst> -mkdir <path> //创建文件夹 -touchz <path> //创建一个空文件
HDFS的Shell命令练习
- 查看HDFS根目录
#hadoop fs -ls /
- 在根目录创建一个目录test和test1
#hadoop fs -mkdir /test #hadoop fs -mkdir /test1
- 本地输出字符串到文件test.txt
#echo -e 'hadoop second lesson' >test.txt
-e :对于特殊字符不会将它当成一般文字输出
- 将创建的文件上传到hdfs
#hadoop fs -put ./test.txt /test
或#hadoop fs -copyFromLocal ./test.txt /test
- 复制文件到本地
#cd .. #hadoop fs -get /test/test.txt . 或#hadoop fs -getToLocal /test/test.txt .
- 复制源文件到目标文件
#hadoop fs -cp /test/test.txt /test1
- 移除文件
#hadoop fs -rm /test1/test.txt
- 移动文件
#hadoop fs -mv /test/test.txt /test1
- 移除文件夹
#hadoop fs -rm -r /test1
练习:
方法:上传小于128MB的文件,观察块大小
验证:使用 http://01node:50070 观察
2.5 MapReduce介绍及WordCount案例
2.5.1 MapReduce介绍
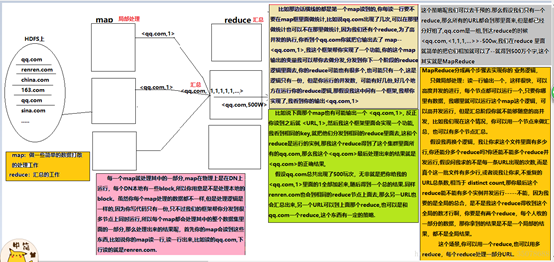
场景:比如有海量的文本文件,如订单,页面点击事件的记录,量特别大,单机版很难搞定。
怎样解决海量数据的计算?
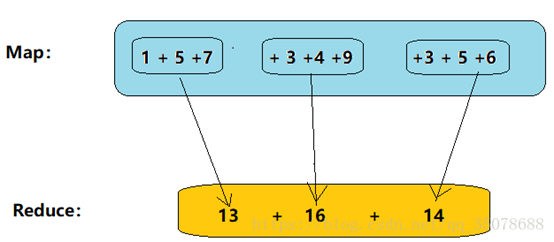
求和: 1 + 5 +7 + 3 +4 +9 +3 + 5 +6
在这里插入图片描述
MapReduce产生背景
如果让你统计日志里面的出现的某个URL的总次数,让你自己去写个单机版的程序,写个逻辑:无非就是读这个文件一行,然后把那个地方截取出来,截取出来之后,然后可以把它放到一个HashMap里面,用Map去重,看到一条新的URL ,就把它put进去,然后+1,如果下次看到再有就直接+1,没有就put进去,单机版的话逻辑是很好实现,但是数据量一大,你觉得单机版本还能搞定吗?
首先2T的文件,你放在单机上可能存不下来,如果再他多一点呢?比如几千个文件,几十个T,单机存都存不下,那么存在哪里-------hdfs上。
因为放在HDFS上可以放很多很多,比如说HDFS上有100个节点,每个节点上能耐挂载8T的硬盘,那就有800T,800T,你每个文件存3个副本的话,你至少也能存100多个T文件,耗费了大概6个T的空间,但是你一旦放到HDFS上就有一个问题:你的文件就会被切散了,被切三到很多的机器上,这个时候,你再对它们进行统计,这个时候,按照原来的逻辑,会不会出现问题?
你的任何一个节点上存的是某个文件的某些块,假设你是在那台机器上去做统计的话,你统计到的永远是局部的数据,那你专门写一个客户端,我的程序运行在这个客户端上,我去读数据,读一点统计一点,到把整个文件都读完了,统计结果也就出来了,问题是那样的话,你的程序又变成了一个单机版的,那你的内存也就不够,因为你要读一点进来统计一点,是不是要保存一些中间数据,那你可能内存也不够了,而且你因为是一个单机版的程序,所以你的速度是不是也很慢,而且你还要不断的从网络里面去拿那些数据,也会很慢,所以这个时候呢?你专门写一个客户端去做统计,肯定是不合适。
那你是不是应该把你的程序分发到集群的每一台DN上去做统计,也就是把运算往数据去移动,而不是把数据移动到运算,把我的运算逻辑移动到数据那端去,数据在哪里,我就在哪里运算,但是这也有一个问题,因为运算也变成了一个分布式的了,你的每一份运算结果都只是局部的结果,那么这个时候也存在问题:
1.你的代码怎么实现分发到很多机器上去运行,这件事情谁帮你做,如果是要你自己写程序的话,你是不是得有个U盘拷你的jar包,一个计算一个计算的去拷,拷完之后再启动,每个机器都启动jar,等你启动最后一台的时候,前面那台已经运行完了,最后一台才刚开始启动,这个工作你用手动去做是不是不合适啊?所以当你把一个简单的逻辑,变成这种分布式运行的时候,你发现很多问题就来了:
1)我的代码怎么分发,怎么配置启动环境,怎么启动起来,这个是不是得有一个庞大的系统去做,也就是说你应该额外开发这么一个叫做资源分发和Java启动程序这么一个配置 的系统,这个系统你会吗?写得出来吗?你要是写的话,是不是还得花很多时间,你还要写很多东西,因为你现在的Java不一定是擅长那个领域的 ,那这个耗费的代价就很大了
2)那个数据,比如刚才那个日志数据,是放到HDFS上面去了,但是不代表HDFS上的每一台DN上面都有这一部分数据里面的内容,因为我们这个集群很大,你这个文件存进去的时候可能只占了其中的30台节点,其中某30台节点上有你这些文件,其他节点上根本就没有你这些文件,那我们的代码,运行逻辑,最好是放到那30台上面去做统计,你放到其他的那些机器上,它可以运行,但是它的数据必须来源于网络,是不是效率会比较低,也就是说你的代码究竟分发到哪些机器上去运行,是不是也要一个策略的问题,那么这个策略是不是也有一定的算法,那么这个时候,你为了实现你那个简单的逻辑,就再去开发这样一个系统出来是不是也是很大的开发量,再考虑一个问题,假如刚才那两个工作你都做完了,你的代码真的成功的在那30台机器上跑起来了,跑起来之后,其中假设有一台机器宕机了,那么你统计的那一部分局部数据是不是也就没有了,那个局部结果也就没有了,那个局部结果没有,假设你有个汇总的结果还正确吗?没有意义了,也就是说你还得解决一个问题,就是你时时刻刻得去监控着你的程序运行情况,那个节点正常,哪个节点不正常,这个问题也是很复杂的,假设这个问题 你也解决了,还有一个问题:
刚才你的逻辑只是统计出中间结果,这个时候是不是还得汇总啊,汇总就是意味着,你要在那30台节点之间结果里面才能汇总,要么把它们全部调到一台机器上就能进行汇总,但是你调到一台机器上汇总的话,你那一台机器的负载是不是会很高,对吧?假设我调到多态机器汇总,逻辑就变得复杂了,比如说,只要是你们那30台机器上统计,每台机器上的那个URL有多少条,你又把那个所有那个URL的数据全部汇总到某个汇总节点,假如有两个URL,哪个URL分发到那个节点上进行汇总,这个策略是不是也会变得很复杂了,那你还得去做个中间数据的调度系统,那也很麻烦。
那这样的话,我们就发现,哪怕是一个很简单的东西,你也要把它变成一个分布式运行的程序,是不是面临很多很多其他的问题,跟我们逻辑无关的问题,往往这些问题要比解决那个逻辑要复杂得多,那么这些问题解决不是我们擅长的,我们大量的普通程序员还没达到那些程度,这么复杂的问题要写出来是不是很麻烦呢?你不能要求每个程序员都能达到那个功力把,我们不过就是写个简单的逻辑统计这个文本里面哪个URL出现的总次数,很简单的东西,所以呢,MapReduce才是我们这些普通程序员的福音。
就是说当我们面临海量数据处理的时候,那个逻辑也许很简单,但是面临海量数据处理,要我们这个 逻辑代码变成分布式运行,就会变得很复杂,而那些很复杂的事情又不是我们关心的,我关心的只是那个逻辑,那这个时候,就有人把你不擅长的而且又必须解决的,而且跟你的逻辑关系又不大的那些东西全部给封装起来,那么这个时候,我们是不是就直接写逻辑了,比如MapReduce和Yarn,这两个是不是做运算的,由这两个框架把我们刚才讲的那些东西全部封装起来,这个就是MapReduce产生的背景,就是这个问题。
总结
把我们很简单的运算逻辑很方便的扩展到海量数据的场景下分布式运算,所以MapReduce程序对我们程序员来说很简单,因为它把那些东西都给封装起来了,你只要写业务逻辑,写业务逻辑还不擅长吗?业务逻辑大部分就是处理文本,处理字符串,我们学的大部分逻辑里面,大部分都是在处理这个问题:处理文本、处理字符串、查询数据库是不是得到一些东西啊。查询一下数据库,处理一下字符串,输出结果,而这个逻辑本身 不用你太多的分布式细节 ,你只要把逻辑写出来就可以了,但是你写MapReduce的时候,必须要符合人家编程的规范,你不能你的写法写,他按他的写法写,每个人的写法都不一样,那MapReduce也没法给你去分发和运行,所以你也要符合他的规范,怎样才算符合规范呢?
就说你的代码,你的任意一个逻辑实现都要分成这么两个步骤:
1)Map
2)Reduce
比如说我们统计日志文件里面,相同URL出现的总次数
如下图:
在这里插入图片描述
例子:
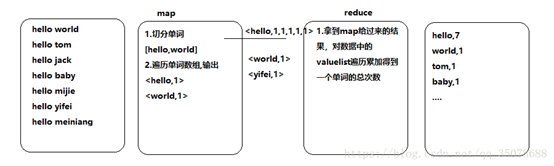
具体怎么实现呢?
2.5.2 WordCount案例
1、配置本地JDK
https://www.runoob.com/java/java-environment-setup.html
2、配置本地hadoop环境
安装包地址链接: https://pan.baidu.com/s/1YrrZFVIGv91etTMgUDa0ig 提取码: yxpc
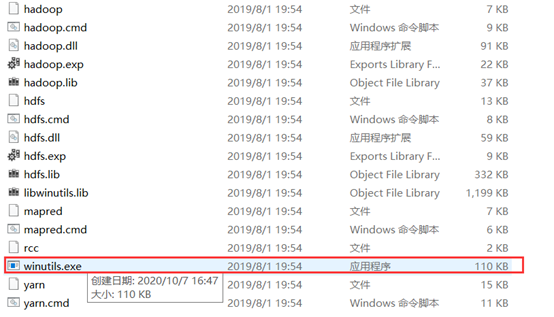
解压hadoop-2.8.4.tar.gz文件和winutils-master.zip文件


这是我的解压地址

在解压出来的winutils-master文件中找到符合自己版本,如:我用的hadoop-2.8.4,我就打开hadoop-2.8.3文件夹,将里面的winutils.exe放到第一步解压(hadoop-2.8.4.tar.gz)的hadoop-2.8.4/bin目录中
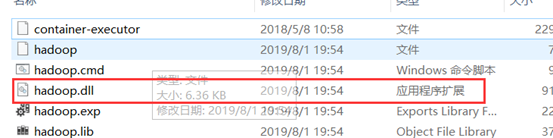
并将hadoop.dll文件放到C:\Windows\System32下

配置HADOOP_HOME环境变量(自己第一步解压的hadoop目录)
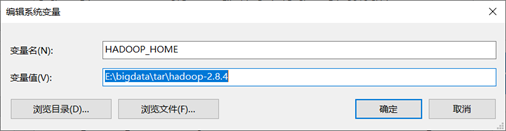
在path环境变量后追加 %HADOOP_HOME%\bin

打开hadoop-2.8.4\etc\hadoop目录(自己第一步解压的hadoop目录下的hadoop-2.8.4\etc\hadoop)
这是我的解压地址

用文本编辑器打开hadoop-env.cmd,红色部分改成自己的jdk地址(忘记的可以在环境变量的JAVA_HOME查到)

重启软件或者电脑后即可
2、创建java项目
引入maven
添加hadoop依赖:
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.8.4</version> </dependency> </dependencies>
2、编写mapper
package com.inspur; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * Created by silvan on 2020/9/22. * * Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> * 它的这个Mapper让你去定义四个泛型,为什么mapper里面需要四个泛型 * 其实读文本文件的操作不用你来实现,框架已经帮你实现了,框架可以读这个文件 * 然后每读一行,就会发给你这个map,让你去运行一次 * * 那他传给map的时候,这个数据就意味着类型的一个协议,我以什么类型的数据给你,我是不是得事先定好啊 * map接收的数据类型得和框架给他的数据类型一致,不然的话就会出现类型转换异常 * 所以map里面得定数据类型,前面两个是map拿数据的类型 * * 另外两个泛型是map的输出数据类型,即reduce也得有4个泛型,前面两个是reduce拿数据的泛型得和map输出的泛型类型一致 * 剩下两个是reduce再输出的结果时的两个数据类型 */ /* * 4个泛型,前两个是指定mapper端输入数据的类型,为什么呢,mapper和reducer都一样 * 拿数据,输出数据都是以<key,value>的形式进行的--那么key,value都分别有一个数据类型 * KEYIN:输入的key的类型 * VALUEIN:输入的value的类型 * KEYOUT:输出的key的数据类型 * VALUEOUT:输出的value的数据类型 * map reduce的数据输入输出都是以key,value对封装的 * 至于输入的key,value形式我们是不能控制的,是框架传给我们的, * 框架传给我们是什么类型,我们这里就写什么数据类型 * * 默认情况下框架传给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量, * 因为我们的框架是读一行就调用一次我们的偏移量 * 那么就把一行的起始偏移量作为key,这一行的内容作为value * * 那么输出端的数据类型是什么,由于我们输出的数<hello,1> * 那么它们的数据类型就显而易见了 * 初步定义为: * Mapper<Long, String, String, int> * 但是不管是Long还是String,在MapReduce里面运行的时候,这个数据读到网络里面进行传递 * 即各个节点之间会进行传递,那么要在网络里面传输,那么就意味着这个数据得序列化 * Long、String对象,内存对象走网络都得序列化,Long、String,int序列化 * 如果自己实现Serializable接口,那么附加的信息太多了 * hadoop实现了自己的一套序列化机制 * 所以就不要用Java里面的数据类型了,而是用它自己的封装一套数据类型 * 这样就有助于提高效率,实现了自己的序列化接口 * 在序列化传输的时候走的就是自己的序列化方法来传递,少了很多负载信息,传递数据精简, * Long---LongWritable * String也有自己的封装-Text * int--IntWritable */ public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> { //MapReduce框架每读一次数据,就会调用一次该方法 @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法参数中 //key--这一行数据的起始偏移量 value--这一行数据的文本内容 //1.先把单词拿出来,拿到一行 String line = value.toString(); //2.切分单词,这个是按照特定的分隔符 进行切分 String [] words = line.split(" "); //3.把里面的单词发送出去 /* * 怎么发出去呢?我都不知道reduce在哪里运行 * 其实呢,这个不用我们关心 * 你只要把你的东西给那个工具就可以了 * 剩下的就给那个框架去做 * 那个工具在哪-----context * 它把那个工具放到那个context里面去了,即输出的工具 * 所以你只要输出到context里面就行了 * 剩下的具体往哪里走,是context的事情 */ //遍历单词数组,输出为<K,V>形式 key是单词,value是1 for (String word : words) { //记得把key和value继续封装起来,即下面 context.write(new Text(word), new IntWritable(1)); } /* * map方法的执行频率:每读一行就调一次 * 最后到reduce 的时候,应该是把某个单词里面所有的1都得到,才能处理 * 而且中间有一个缓存的过程,因为每个map的处理速度都不会完全一致 * 等那个单词所有的1都到齐了才传给reduce */ //每一组key,value都全了,才会去调用一次reduce,reduce直接去处理valuelist //接着就是写Reduce逻辑了 } }
3、编写reducer
package com.inspur; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Created by silvan on 2020/9/22. */ public class WCReducer extends Reducer <Text, IntWritable, Text, Text> { //map处理之后,value传过来的是一个value的集合 //框架在map处理完成之后,将所有的KV对保存起来,进行分组,然后传递一个组,调用一次reduce //相同的key在一个组 @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //遍历valuelist,进行了累加 int count = 0; for (IntWritable value : values) { //get()方法就能拿到里面的值 count += value.get(); } //输出一组(一个单词)的统计结果 //默认输出到HDFS的一个文件上面去,放在HDFS的某个目录下 context.write(key, new Text(count + "")); //但是还差一个描述类:用来描述整个逻辑 /* * Map,Reducce都是个分散的,那集群运行的时候不知道运行哪些MapReduce * * 处理业务逻辑的一个整体,叫做job * 我们就可以通过job告诉集群,我们此次运行的是哪个job, * job里面用的哪个作为Mapper,哪个业务作为Reducer,我们得指定 * * 所以还得写一个类用来描述处理业务逻辑 * 把一个特定的业务处理逻辑叫做一个job(作业),我们就可以把这个job告诉那个集群, * */ } }
4、编写job
package com.inspur; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * Created by silvan on 2020/9/22. * * 该作业使用哪个类作为逻辑处理的map * 哪个作为reduce * 还可以指定该作业要处理的数据所在的路径 * 还可以指定该作业输出的结果放到哪个路径 */ public class WCRunner { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //首先要描述一个作业,这些信息是挺多的,哪个是map,哪个是reduce,输入输出路径在哪 //一般来说这么多信息,就可以把它封装在一个对象里面,那么这个对象呢就是 ----Job对象 Job job = Job.getInstance(new Configuration()); //job用哪个类作为Mapper 指定输入输出数据类型是什么 job.setMapperClass(WCMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //job用哪个类作为Reducer 指定数据输入输出类型是什么 job.setReducerClass(WCReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //指定原始数据存放在哪里 //参数1:里面是对哪个参数进行指定 //参数2:文件在哪个路径下,这个路径下的所有文件都会去读的 //D:\mr FileInputFormat.addInputPath(job,new Path(args[0])); //指定处理结果的数据存放路径 FileOutputFormat.setOutputPath(job, new Path(args[1])); //提交job boolean b = job.waitForCompletion(true); if (!b){ System.out.println("word count failed!"); } } }
5、运行
添加输入参数:
在D盘建立文件夹mr,在mr文件夹内创建文件data.txt并输入内容,如:
hello hadoop
will learn hadoop WordCount
but the hadoop is not easy
添加main函数运行参数:
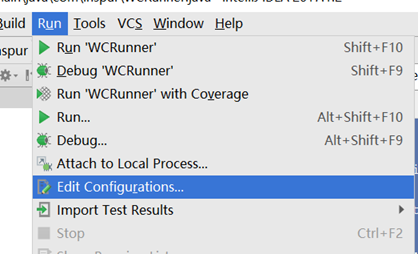
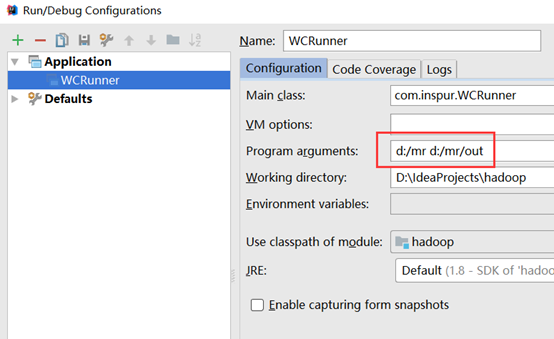
运行main函数,得到结果:

报错:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z

解决方法:

- 点击蓝色框里的会弹出这个文件

2. 将这个文件内的所有代码复制(这代码只可以读,不可修改)
然后新建一个org.apache.hadoop.io.nativeio.NativeIO
将复制的代码全部copy到这个新建的文件里(这个新建的文件里不要有内容)
找到大约296行进行修改
修改前:

修改后:

运行即可。
6、将项目导出jar包
1 点击maven project
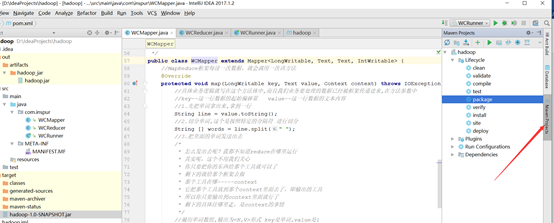
2 右击package选择Run hadoop
3 将会生成target目录,下面包含hadoop任务的jar包
第7步开始前先修改配置文件,否则会造成访问不到yarn框架,将主机名称01node换成主节点的IP地址,如下:

7、hadoop集群方式运行jar
1将hadoop-1.0-SNAPSHOT.jar上传至01node中/usr/local/hadoop/share/hadoop/mapreduce
注:一定要放置该目录下,否则会不识别主类
2新建文件夹input存放测试数据如:
在本地创建数据文件/usr/local/test.txt,测试数据可自定
hdfs dfs -mkdir /input
hadoop fs -put /usr/local/test.txt /input
3执行wordcount jar
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-1.0-SNAPSHOT.jar com/inspur/WCRunner /input /output
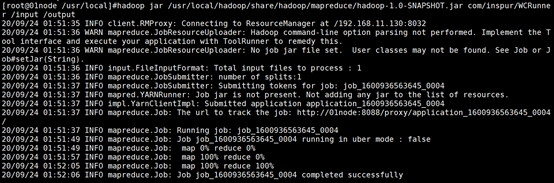
4执行完成后验证
hadoop fs -cat /output/part-r-00000


2.5.3 运行自带程序计算圆周率
在hadoop安装包的hadoop/share/hadoop/mapreduce下有官方自带的mapreduce程序。我们可以使用如下的命令进行运行测试。
示例程序jar:
hadoop-mapreduce-examples-2.8.4.jar
计算圆周率:
# hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.4.jar pi 20 50
关于圆周率的估算,感兴趣的可以查询资料MonteCarlo方法来计算Pi值。
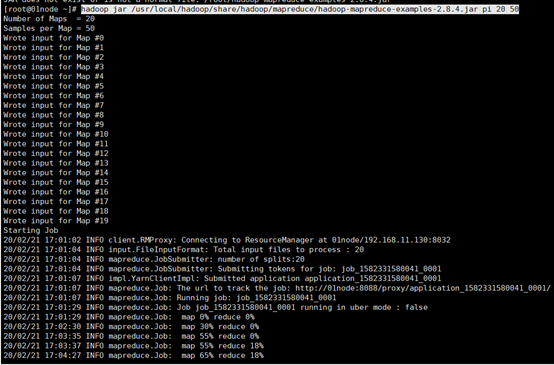

在MapReduce计算的过程中,可以通过Web-ui查看到Yarn集群在进行资源调度。

2.6 集群节点的添加与删除
在Hadoop集群环境正常运行过程中,如果出现了计算能力不足或有了新的资源需要对原集群环境进行扩展的情况时,可以在原集群环境正常运行的状态下动态的添加(删除)节点。
2.6.1 集群中动态添加节点
在正在运行的Hadoop集群环境中动态添加节点的步骤如下。
(1)准备一台新节点服务器,此服务器的配置要与其他已运行的节点机器保持一致。此新节点服务器的环境配置包括JDK环境的安装及环境变量的配置、静态IP地址的设置、防火墙的关闭、设置主机名、Hadoop环境的安装及环境变量的配置、Hadoop各核心配置文件的配置等。本文中新节点规划的静态IP地址为:192.168.11.133,主机名为:04node。此处04node节点的安装与配置过程略,具体安装配置信息可参看分布式节点的安装与配置。
【注意】如果新节点采取克隆的方式创建,则需要对之前集群的数据进行删除(即配置文件中配置的存放数据的目录),并且重新创建文件夹(创建文件夹的时候注意权限问题)。
具体过程:
1、网络
将04node设置手动ip地址为192.168.11.133
2、更改主机名
#vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=04node
如果还不行可以试试:
#vim /etc/hostname
(2)修改每个节点机器的hosts文件(其实主节点修改就可以),将04node节点添加进去,修改后的文件内容见下图所示。
#vi /etc/hosts

(3)修改每个机器节点的从文件(其实主节点修改就可以),将04node节点添加进去,修改后的文件内容见下图所示。
# vi /usr/local/hadoop/etc/hadoop/slaves
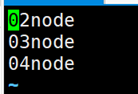
(4)配置SSH,使得NameNode登录新节点的时候不需要输入密码。
(5)配置主节点01node的hdfs-site.xml(新增节点可不配置),添加允许和拒绝加入集群的节点列表(如果允许的列表为空默认都允许连接,拒绝的列表为空则代表没有节点拒绝连接集群。拒绝列表的优先级大于允许的优先级)。修改的文件内容如下代码段2-6所示。
#vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
代码段2-6 hdfs-site.xml文件新增内容
<!--配置允许加入集群的节点列表--> <property> <name>dfs.hosts</name> <value>/usr/local/hadoop/etc/datanode-allow.list</value> <description>允许加入集群的节点列表</description> </property> <!--配置拒绝加入集群的节点列表--> <property> <name>dfs.hosts.exclude</name> <value>/usr/local/hadoop/etc/datanode-deny.list</value> <description>拒绝加入集群的节点列表</description> </property>
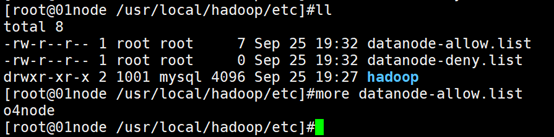
其中,允许加入集群的节点列表配置文件hadoop/etc/datanode-allow.list和拒绝加入集群的节点列表配置文件hadoop/etc/datanode-deny.list需自己手工创建。创建成功后,为新创建的文件添加允许或拒绝加入集群的节点,例如datanode-allow.list文件编辑后的内容如图所示(datanode-deny.list文件内容类似datanode-allow.list,只需将拒绝加入集群的节点机器名称列出即可)。
(6)单独启动该节点上的DataNode进程和NodeManager进程。
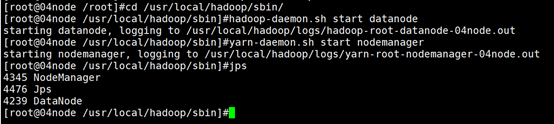
在新节点机器Hadoop的安装目录:/usr/local/hadoop/sbin下,直接运行命令“hadoop-daemon.sh start datanode”和“yarn-daemon.sh start nodemanager”即可启动新节点的dataNode和nodeManager进程,然后使用命令“jps”查看进程信息,结果如图所示。
(7)在主节点进行刷新
在主节点机器上执行命令“hdfs dfsadmin -refreshNodes”,此命令可以动态刷新dfs.hosts和dfs.hosts.exclude配置,无需重启NameNode。刷新成功如图所示。

(8)查看节点状态
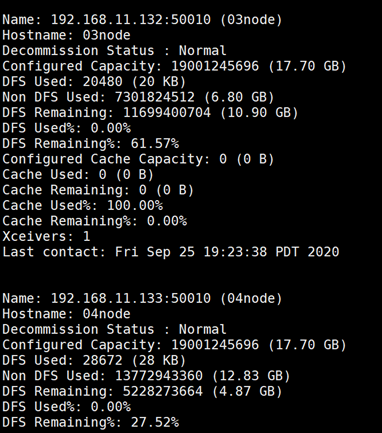
在主节点机器上执行命令“hdfs dfsadmin -report”可以查看集群中文件系统的基本信息和统计信息,如图所示。如果不成功可以等待一下或者多刷新几次。

2.6.2 集群节点的动态删除(下线)
在已启动的集群环境中删除或下线某个节点非常简单,首先需要在主节点的配置文件datanode-deny.list(此文件在此子章节的前面部分已说明)中添加拒绝连接的节点列表即可,文件内容见图所示。
#vim datanode-deny.list

然后在主节点机器执行命令“hdfs dfsadmin -refreshNodes”上刷新节点信息,查看节点状态。
# hdfs dfsadmin -report
或者web界面查看该datanode状态转为Decommission In Progress。
当datanode完成数据迁移时,姿态会变为Decommissioned

