第2章 大数据处理架构Hadoop (一)
第2章 大数据处理架构Hadoop
In pioneer days they used oxen for heavy pulling, and when one ox couldn’t budge a log,they didn’t try to grow a larger ox. We shouldn’t be trying for bigger computers, but for more systems of computers.
—Grace Hopper
2.1 Hadoop简介
2.1.1 Hadoop是什么
Hadoop这个名字不是一个缩写,它是一个虚构的名字。该项目的创建者,Doug Cutting解释Hadoop的得名 :“这个名字是我孩子给一个棕黄色的大象玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义,并且不会被用于别处。小孩子恰恰是这方面的高手”。Hadoop的logo如下。

Hadoop的源头是Apache Nutch搜索引擎项目。Doug Cutting等人受到Google的GFS和Map/Reduce学术论文启发,实现MapReduce计算框架并和HDFS(Nutch Distributed File Ssytem)结合,用以支持Nutch引擎的主要算法。2006年2月,Apache Hadoop项目正式启动以支持MapReduce和HDFS的从Nutch中独立出来发展。
目前,Hadoop是Apache软件基金会旗下的一个开源分布式存储与计算平台。用户利用Hadoop可以轻松的组织计算机资源,搭建自己的分布式计算平台,充分利用集群的计算和存储能力,完成海量数据的处理。该平台使用Java实现,具有良好的可移植性。Hadoop的核心包含两个部分:
- l HDFS(Hadoop Distribute File System),Hadoop分布式文件系统
- l MapReduce计算框架(Google MapReduce的开源实现)
HDFS的高容错性、高伸缩性等优点允许用户将Hadoop部署在低廉的硬件上,形成分布式系统。MapReduce分布式编程模型允许用户在不了解分布式系统底层细节的情况下开发并行应用程序。简单的说,Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,那它具有哪些特性呢?
- l 高可靠性:采用荣誉数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对外提供服务。
- l 高效性:作为并行分布式计算平台,Hadoop采用分布式存储和分布式处理两大核心技术,能够高效地处理PB级数据。
- l 高可扩展性:Hadoop的设计目标是可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点上。123 1
- l 高容错性:采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务进行重新分配。
- l 成本低:Hadoop采用廉价的计算机集群,成本较低,普通用户也很容易用自己的PC搭建Hadoop运行环境。
- l 运行在Linux平台上:Hadoop是基于Java语言开发的,可以较好地运行在Linux平台上。
- l 支持多种编程语言:Hadoop上的应用程序也可以使用其他语言编写,如C++。
2.1.2 Hadoop生态圈
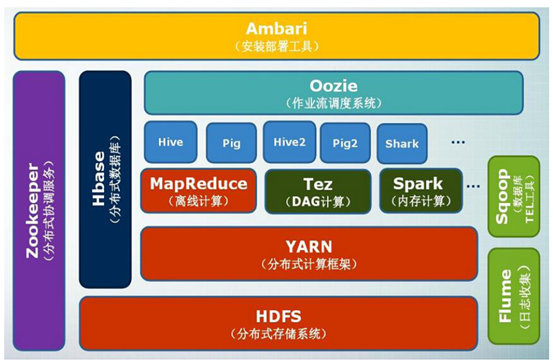
Hadoop除了其核心的MapReduce和HDFS之外,还包含了很多不可或缺的周边项目。具体介绍如下:
|
组件 |
功能 |
|
HDFS |
分布式文件系统 |
|
MapReduce |
分布式并行编程模型 |
|
YARN |
资源管理和调度器 |
|
Tez |
运行在YARN之上的下一代Hadoop查询处理框架 |
|
Hive |
Hadoop上的数据仓库 |
|
HBase |
Hadoop上的非关系型的分布式数据库 |
|
Pig |
一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin |
|
Sqoop |
用于在Hadoop与传统数据库之间进行数据传递 |
|
Oozie |
Hadoop上的工作流管理系统 |
|
Zookeeper |
提供分布式协调一致性服务 |
|
Storm |
流计算框架 |
|
Flume |
一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 |
|
Ambari |
Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
|
Kafka |
一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据 |
|
Spark |
类似于Hadoop MapReduce的通用并行框架 |
2.1.3 Hadoop体系架构
从前面的内容我们了解到Hadoop是使用计算机集群进行分布式大数据处理的框架,那么这些众多的计算机应该要怎么管理呢?Hadoop使用主从结构,来了解两个概念:
NameNode,主节点,只有一个,负责:
1) 接收用户操作请求
2) 维护文件系统的目录结构
3) 管理文件与块之间关系,block与datanode之间关系
DataNodes,从节点,有很多个,负责:
1) 存储文件
2) 文件被分成block存储在磁盘上
3) 为保证数据安全,文件会有多个副本
下面将分别介绍两个核心项目MapReduce和HDFS的体系架构。
1. HDFS架构
在Hadoop中,一个文件会被划分成大小固定的多个文件块,分布的存储在集群中的节点中,比如文件a.txt大小600G要存入到HDFS,当前HDFS具有一个NameNode和多个DataNodes,如下图所示。
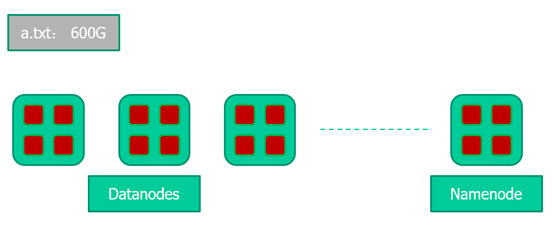
同一个文件块在不同的节点中有多个副本。
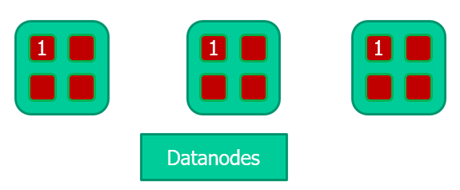
而此时我们需要一个集中的地方保存文件的分块信息,这个地方就是NameNode。如下。
/home/hdfs/a.txt.part1,3,(dn1,dn2,dn3)
/home/hdfs/a.txt.part2,3,(dn2,dn3,dn4)
/home/hdfs/a.txt.part3,3,(dn6,dn11,dn28)
…
2. MapReduce架构 第一行表示a.txt文件总共分为3块,其中第一块分别存储在从节点1、从节点2和从节点3。
MapReduce是一种编程模型,用于大规模数据集的并行计算,同样也分为主节点和从节点。
JobTracker,主节点,只有一个,负责:
1) 接收客户提交的计算任务
2) 把计算任务分给TaskTrackers执行
3) 监控TaskTracker的执行情况
TaskTrackers,从节点,只有一个,负责:
1) 执行JobTracker分配的计算任务
示例:
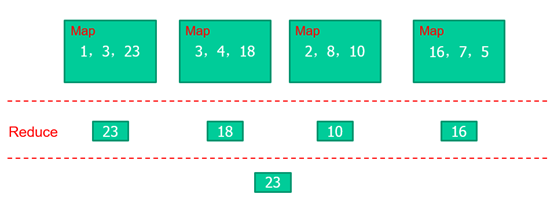
求出以下数组当中最大的数
1,3,23,3,4,18,2,8,10,16,7,5 int Max(int a[], n) { int m=0; for(int i=0; i<n; i++) if(m<a[i]) m=a[i]; return m; }
如果使用MapReduce进行上述计算:将数组分为四个小数组,每个数组里面包含三个数,分别对这四个数组进行比较计算,求取每个数组的最大值,对得到的最大值再次进行比较计算,最终得出原来数组的最大值。
2.2 安装Hadoop前准备
2.2.1 集群简介
Hadoop集群具体来说包含两个集群:HDFS集群和Yarn集群,两者逻辑上分离,但物理上常在一起。
HDFS集群负责海量数据的存储,集群中的角色主要有:
NameNode、DataNode、SecondaryNameNode
Yarn集群负责海量数据运算时的资源调度,集群中的角色主要有:
ResourceManager、NodoManager
那MapReduce是什么呢?它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,然后打包运行在HDFS集群上,并且受到Yarn集群的资源调度管理。
Hadoop部署方式分三种:
(1)单机模式:仅一个机器运行一个Java进程,主要用于调试。
(2)伪分布式:主节点和从节点都运行在同一台机器上,主要用于调试
(3)完全分布式:也称集群模式,主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
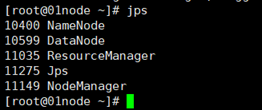
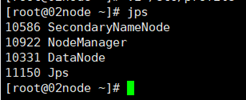
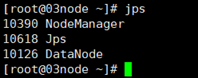
在本案例中,我们将以3节点为例进行完全分布式搭建,角色分配如下:
01node NameNode DataNode ResourceManager
02node DataNode NodeManager SecondaryNameNode
03node DataNode NodeManager
2.2.2 服务器准备
本案例使用VMware虚拟机创建虚拟服务器来搭建Hadoop集群,所用软件及版本如下:
VMware Workstation Pro 12.5.7
CentOS 7.0
1. 创建新的虚拟机并配置
1) 创建01node虚拟机,在命令窗口使用管理员用户:
#su root
2) 手动设置IP地址
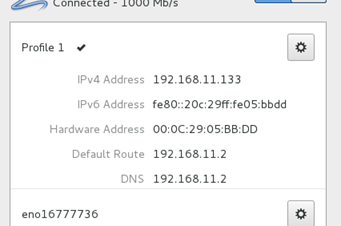
由于部署的过程中IP的变动会导致部署过程变得很麻烦,所以在这里我们进行IP地址的手动设置。
设置里面网络连接更改为vmnet8
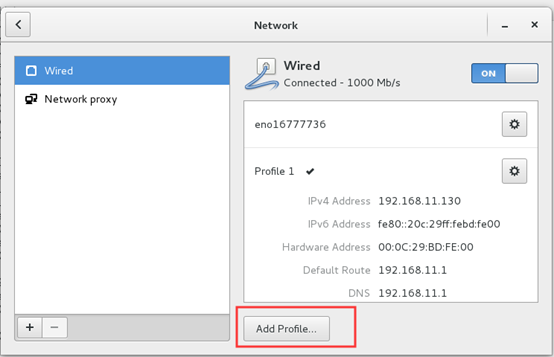
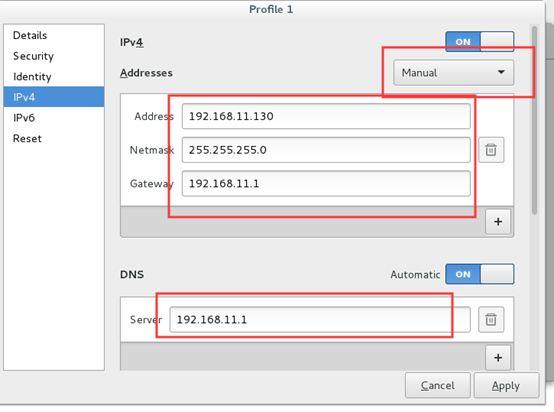
Centos7 命令行固定ip配置
准备: 查看本电脑虚拟机的网关
打开VMware软件,编辑->虚拟网络编辑器
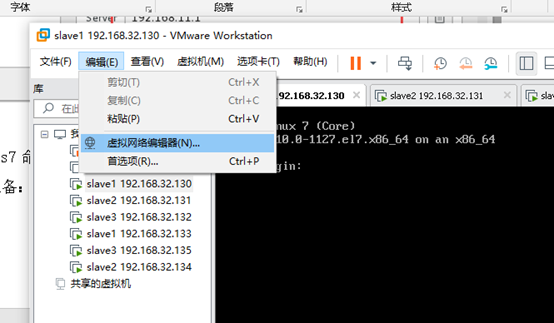
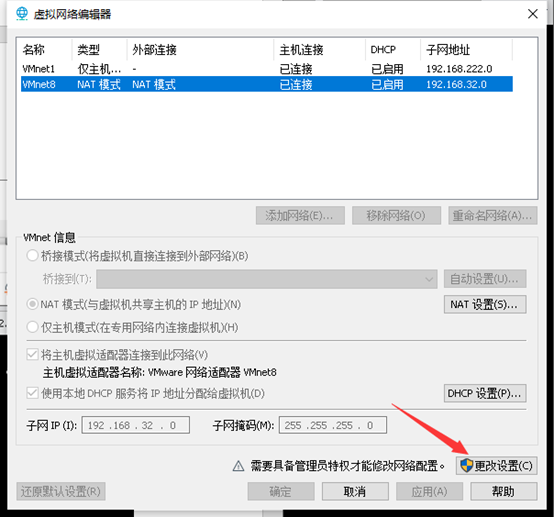
如果可以点击更改设置,一定要先点击,否则改不了。
点击完的画面:
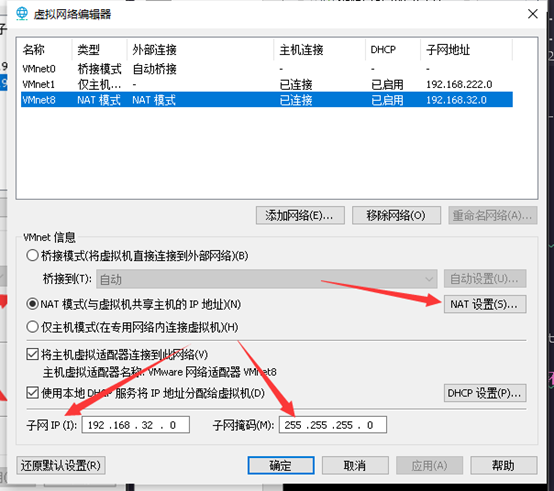
从该窗口可以获得本电脑虚拟机的子网ip段,与子网掩码。点击NAT设置,查看网关
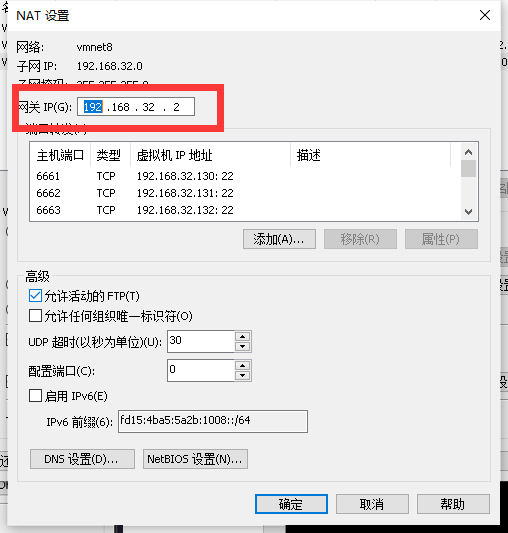
电脑网关为192.168.32.2 (通常第三组 每台电脑不同,第四组都是2)
点击取消,关闭虚拟网络编辑器。
修改网卡配置
# vi /etc/sysconfig/network-script/ificg-ens33 (这里多数电脑都是ens33,少部分电脑是ensXXXX,可以先输入ens 后按tab自动补全)

进入后 出现 配置页面
[vi 编辑器使用tips
命令模式 (在非插入模式输入:)
w 保存
q 退出
wq 保存并退出
wq! 强制保存并退出
set number 打开行号
set nonumber 关闭行号
$ 跳转至文本末尾
/xxx 查询xxx
插入模式
esc 退出插入模式进入
i 进入插入模式
o 换行输入]
- 修改配置为
bootproto=static onboot=yes //开启网卡。有同学虚拟机装好上不了网,把onboot 改为yes 有几率解决问题。
- 在最后添加 (//后的内容为注释)
IPADDR=192.168.32.132 // 本机ip地址 NETMASK=255.255.255.0 // 子网掩码 GATEWAY=192.168.32.2 // 网关,根据开始准备时看的 DNS1=119.29.29.29 //DNS1,DNS2 地址解析服务器,可以用自己的,也可以用这个。只要能解析地址成功即可。 DNS2=8.8.8.8
修改完成后 重启网络
#systemctl restart network //其他os 重启命令自查。
命令行修改固定IP完成。
3) 配置IP、主机名映射
# vi /etc/hosts
1 192.168.11.130 01node 2 192.168.11.131 02node 3 192.168.11.132 03node
4) 关闭防火墙
查看防火墙状态:
#systemctl status firewalld
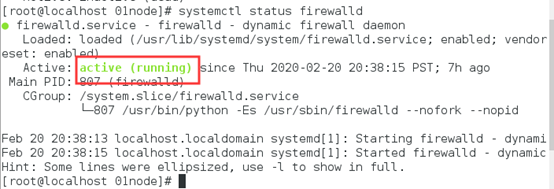
关闭防火墙:
#systemctl stop firewalld
开机禁用
#systemctl disable firewalld
5) 安装JDK
上传jdk安装包
如:jdk-8u65-linux-x64.tar.gz
解压安装包
#tar zxvf jdk-8u65-linux-x64.tar.gz -C /usr/local
更改jdk目录名,方便后续使用
#mv jdk1.8.0_65 jdk
配置环境变量:
#vi /etc/profile export JAVA_HOME=/usr/local/jdk export PATH=.:$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
刷新配置
#source /etc/profile
6) 克隆另外两台主机节点
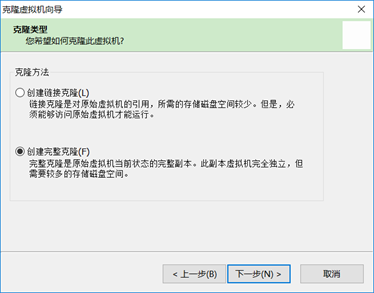
在主机关闭的情况下选择克隆,如下图。
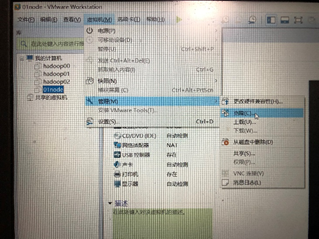
选择创建完整克隆
修改主机名
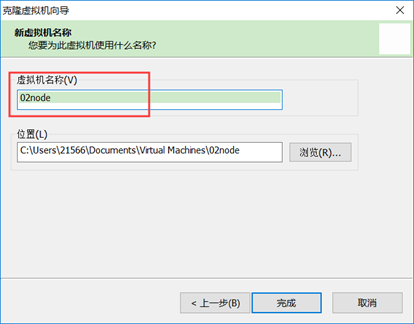
7) 设置主机名
#vi /etc/sysconfig/network
修改该文件内容为:
NETWORKING=yes
HOSTNAME=01node
另外两台主机进行同样的设置,注意修改主机名。
8) 设置SSH免密码登陆
免密登陆主要用于主节点免密访问从节点。
首先生成公私钥,在01node窗口输入:
#ssh-keygen -t rsa (四个回车)
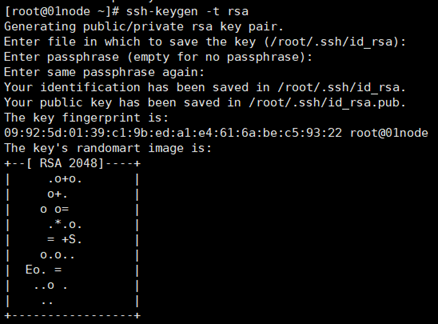
执行完这个命令后,会生成id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上,以03node为例。在01node命令窗口输入以下命令:
#ssh-copy-id 03node 执行的过程中输入yes再输入目标主机的登录密码
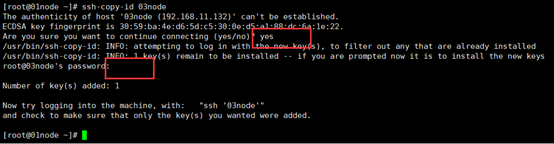
注意:要给本机拷贝一份,即要使01node能免密登录01node
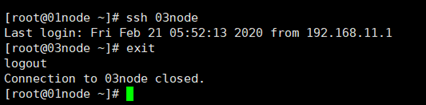
验证是否设置成功,在01node访问03node:
#ssh 03node 若无需输入密码可直接登录则设置成功
如下所示表示03node登录成功,要想退出登录输入exit即可。
2.3 安装Hadoop
2.3.1 配置Hadoop
1. 解压
#tar zxvf hadoop-2.8.4.tar.gz

修改hadoop目录名称:
#mv hadoop-2.8.4 hadoop

/usr/local/hadoop/etc/hadoop/
在$HADOOP_HOME/etc/hadoop/目录下需要配置以下文件。
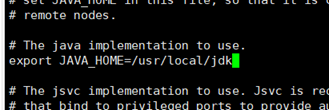
2. Hadoop-env.sh
export JAVA_HOME=具体的jdk目录
3. Core-site.xml
在configuration标签中添加以下变量和值
<!--指定HDFS的访问地址,9000是端口号--> <property> <name>fs.defaultFS</name> <value>hdfs://01node:9000</value> </property> <!--指定hadoop运行时产生的存储目录,默认/tmp/hadoop-{user.name}--> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/hadoop_tmp</value> </property>
4. Hdfs-site.xml
<!--指定hdfs副本的数量--> <property> <name>dfs.replication</name> <value>2</value> </property> <!--指定second节点,即主节点的秘书--> <property> <name>dfs.namenode.secondary.http-address</name> <value>02node:50090</value> </property>
5. Mapred-site.xml
mv mapred-site.xml.template mapred-site.xml vi mapred-site.xml
<!--指定mr运行时框架,这里指定在yarn上,默认是local--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
6. Yarn-site.xml
<!--指定yarn的老大(resourceManager)的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.11.130</value> </property> <!--nodeManager上运行的附属服务。需配置成mapreduce_shuffle 才可以运行MAPREDUCE程序默认值--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
7. Slaves
将文件内容修改为:
02node
03node
8. 添加Hadoop环境变量
#vi /etc/profile
添加内容如下:
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
刷新配置文件:
#source /etc/profile
9. 使用scp命令同步到其他节点(同步后如果修改一个配置文件,记得修改其他配置文件)
#scp -r /usr/local/hadoop/ root@02node:/usr/local/
-r:递归,表示文件夹下所有文件
#scp /etc/profile root@02node:/etc/profile
同样拷贝jdk到其他节点
刷新配置
#source /etc/profile
注:关于hadoop的配置文件
***-default.xml 这里配置了hadoop默认的配置选项
如果用户没有更改 那么这里面的选项将会生效
***-site.xml 这里面配置了用户需要自定义的选项
site中配置选项优先级>default中的,如果有配置的话就会覆盖默认的配置选项
2.3.2 启动Hadoop集群
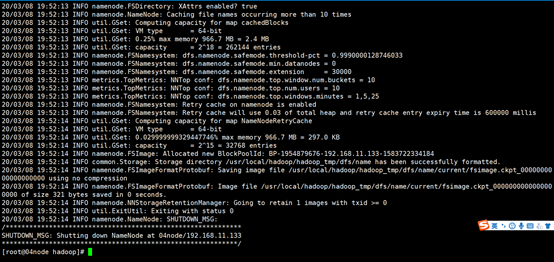
注意:首次启动hdfs时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的hdfs在物理上还是不存在的。
#hdfs namenode -format
或者
#hadoop namenode -format
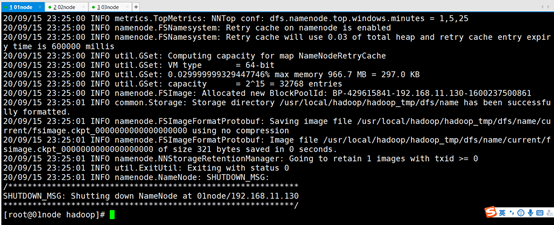
关于hdfs的格式化:
首次启动需要进行格式化
格式化本质是进行文件系统的初始化操作 创建一些自己所需要的文件
格式化之后 集群启动成功 后续再也不要进行格式化
格式化的操作在hdfs集群的主角色(NameNode)所在的机器上操作
从usr/local/hadoop/hadoop_tmp/dfs/name/current/下面的version文件中可以查看集群id,格式化时生产的,并且再次格式化会重新生产一个id,所以格式化一次就好,多次格式化会造成启动不成功。
集群启动和关闭方法:
#start-all.sh 或start-dfs.sh start-yarn.sh
和
#stop-all.sh 或stop-dfs.sh stop-yarn.sh
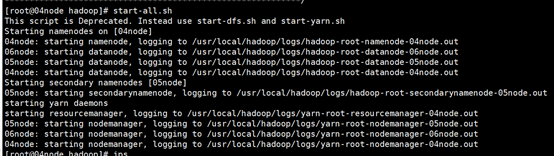
使用jps命令查看节点java进程,判断是否启动成功
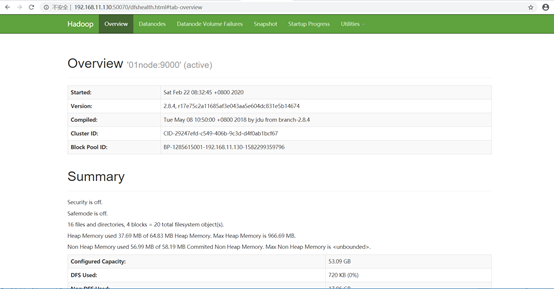
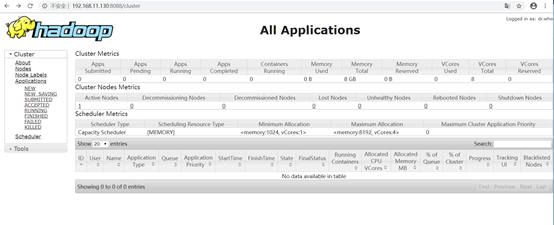
2.3.3 集群Web-ui页面
一旦hadoop集群启动并运行,可以通过web-ui进行集群查看,如下所述:
nameNode(hdfs集群) http://nn_host:50070/ 默认 50070
ResourceManager(yarn集群) http://rm_host:8088/ 默认 8088
访问不到的可以把主机名换成对应IP地址,如在本案例中是:
和