
HiveQL:数据查询
实验目的
- 基本的select操作
- 基于分区的查询
- Join查询
- 硬件环境要求
实验环境
PC机至少4G内存,硬盘至少预留50G空间。
- 软件要求
已安装并启动Hadoop
已安装并启动Hive
实验要求
- 应用基本的Select 操作
- 应用基于分区的查询
- 应用Join进行查询
实验步骤
第7章 HiveQL:数据查询
1 基本的Select 操作
l 基本查询
查询employee表中数据:
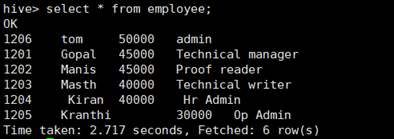
所使用命令:
# select * from employee;
或者 # select t.id,t.name,t.salary,t.position from employee t;
l limit
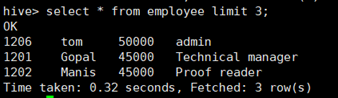
所使用命令:
# select * from employee limit 3;
l 区间查询between and
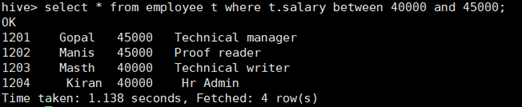
所使用命令:
# select * from employee t where t.salary between 40000 and 45000;
l 空查询is null

所使用命令:
# select t.id no,t.name,t.salary from employee t where t.id is null;
l 不空查询is not null
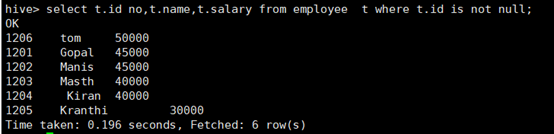
所使用命令:
# select t.id no,t.name,t.salary from employee t where t.id is not null;
l 集合查询in

所使用命令:
# select t.id no,t.name,t.salary from employee t where t.name in (‘tom’,’Gopal’);
l 不在集合范围内not in

所使用命令:
# select t.id no,t.name,t.salary from employee t where t.name not in (‘tom’,’Gopal’);
l 函数查询
最高工资max
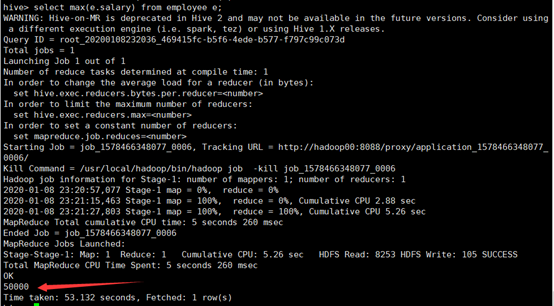
所使用命令:
# select max(e.salary) from employee e;
最低工资min

所使用命令:
# select min(salary) from employee e;
总人数count
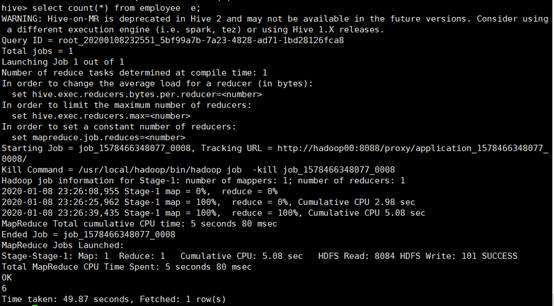
所使用命令:
# select count(*) from employee e;
公司月总支出sum
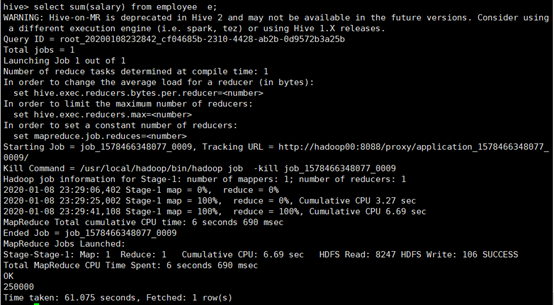
所使用命令:
# select sum(salary) from employee e;
平均工资avg
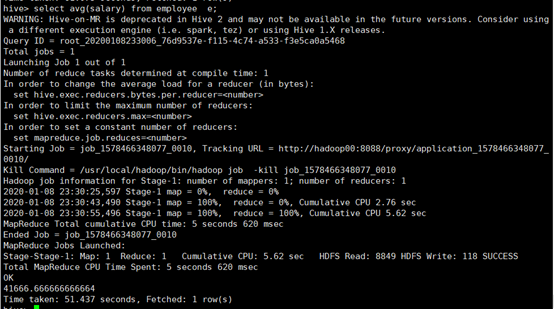
所使用命令:
# select avg(salary) from employee e;
l ORDER BY与SORT BY
ORDER BY的使用:
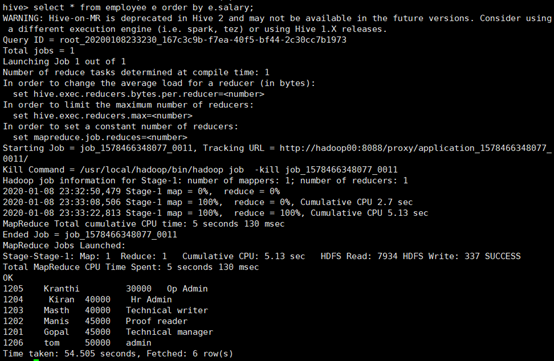
所使用的命令:
# select * from employee e order by e.salary;
SORT BY的使用:

# select * from employee e sort by e.salary;
2 基于分区的查询
加载数据到表分区,以第五章创建的表t为例。
2.1 加载数据到分区
在/usr/local/data/文件夹下创建customer.txt文件,其内容为:

加载数据到分区:

所使用命令:
# load data local inpath ‘/usr/local/data/customer.txt' into table t partition(year=2014,month=11);
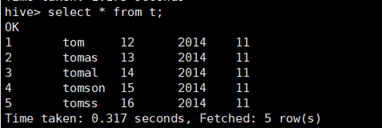
查询结果:
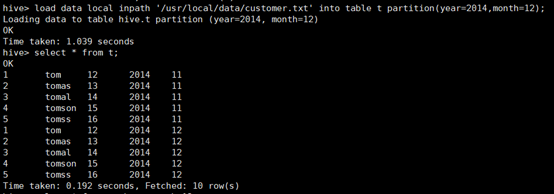
加载数据到分区(year=2014,month=12)和查询结果:
2.2 基于分区的查询
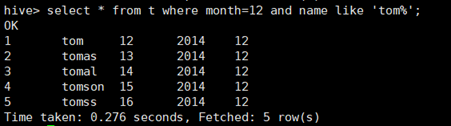
所使用命令:
# select * from t where month=12 and name like ‘tom%’;
3 基于Join的查询
两个表进行连接,例如有两个表m n ,m表中的一条记录和n表中的一条记录组成一条记录。
3.1 实验准备:
/usr/local/data目录下创建两个数据文件:
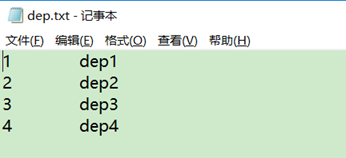
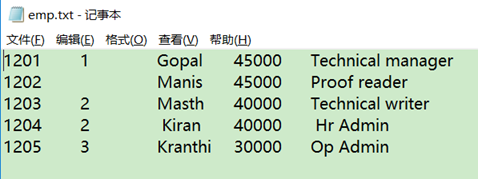
创建员工表和部门表:

所使用命令如下:
# create table emp (id int,depno int,name string,salary int,position string) row format delimited fields terminated by '\t' ;
# create table dep (id int,name string) row format delimited fields terminated by '\t' ;
导入数据:
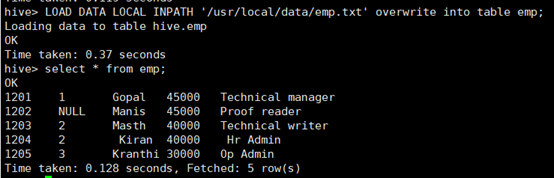
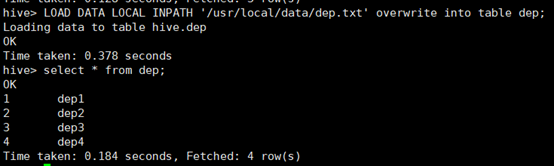
所使用命令如下:
# LOAD DATA LOCAL INPATH '/usr/local/data/emp.txt' overwrite into table emp;
# LOAD DATA LOCAL INPATH '/usr/local/data/dep.txt' overwrite into table dep;
3.2 join on :等值连接
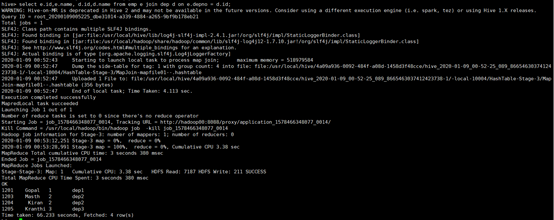
所使用命令:
# select e.id,e.name, d.id,d.name from emp e join dep d on e.depno = d.id;
3.3 left join:左连接
左连接表示以join左边数据为主,若join右边的数据不存在则补空。
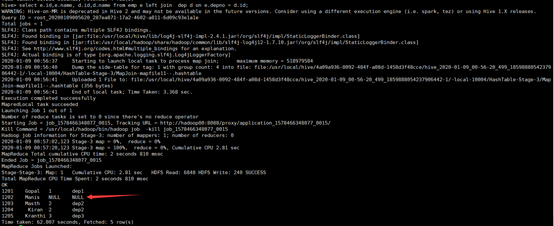
所使用命令:
# select e.id,e.name, d.id,d.name from emp e left join dep d on e.depno = d.id;
3.4 right join:右连接
右连接表示以join右边数据为主,若join左边的数据不存在则补空。
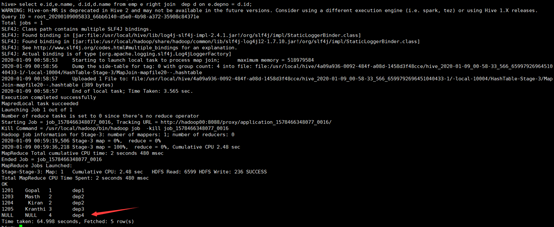
所使用命令:
# select e.id,e.name, d.id,d.name from emp e right join dep d on e.depno = d.id;
总结与提高
- 提高学生的动手操作能力,使用HiveQL中select语句进行数据查询,应用分区查询,应用join进行数据查询。
