特征工程
特征工程很重要,特征工程主要包含:特征构建和提取、特征处理、特征选择等几个方面。不同应用场景下,需要有的放矢的做一些特征工程的工作。
特征构建和提取
特征构建基本上就是从原始的数据中抽取出我们需要的特征。一方面需要结合业务知识,另一方面可以结合数据分析得到一些特征的灵感。
特征处理
经过提取的特征,如果未经过处理的话,可能会存在一下几个问题
不属于同一量纲
即特征的规格不一样,不能够放在一起比较。无量纲化可以解决这一问题,不属于同一个量刚就是说:假如某个特征的单位是比如房价是“万元”,个人收入是“元”,那么这个时候就需要对两个特征做无量纲化处理,使得不同规格的数据转换到同一规格。
无量纲化的主要应用场景就是一些线性的模型、神经网络模型,而对于一些树模型的化,它们本身对是否无量纲化并不感冒,因为不影响到结点分裂的增益,该是多少还是多少。
常见的无量纲化有2种:
区间缩放
区间缩放也有很多种,最常使用的就是 Min-Max scale,公式表示为
最大最小归一化也叫 0-1 归一化,它将原本的特征的值映射到一个0-1的区间中去。
标准化
标准化需要计算特征的均值和方差,公式表达为:
这样计算的好处是能将特征分布拉到均值为0方差为1的标准正态分布中去。像一些神经网络的模型,也是假设数据服从均值为0方差为1 的分布。
信息冗余与One-hot编码
对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。二值化可以解决这一问题。
定性特征不能直接使用:某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。最简单的方式是为每一种定性值指定一个定量值,但是这种方式过于灵活,增加了调参的工作。通常使用哑编码的方式将定性特征转换为定量特征:假设有N种定性值,则将这一个特征扩展为N种特征,当原始特征值为第i种定性值时,第i个扩展特征赋值为1,其他扩展特征赋值为0。哑编码的方式相比直接指定的方式,不用增加调参的工作,对于线性模型来说,使用哑编码后的特征可达到非线性的效果。
one-hot和二值化都是经常会遇到的一些情况,一方面one-hot后的特征可以使得原本非线性可分的样本能够变得线性可分,对于线性模型来说,这是最好不过的事情了,本身线性模型计算也快,还可以并行。但对于一些其他的比如树模型的化,one-hot后导致的高维稀疏特征有时候并不利于模型的学习。一方面,这样会增加特征数量导致计算开销比较大,其次是可能导致过拟合的概率会变大,原因是树模型与高维稀疏特征。
连续特征离散化
连续特征离散化主要的应用场景是一些以embedding为基础的模型,比如DeepFM,DCN这些深度学习的模型,以及一些线性模型也可以把连续的特征离散化。
缺失值的处理
大部分算法并不支持缺失值,如:GBDT,RandomForst(尽管理论上可以支持,但是一些常用的lib里面并没有支持),虽然XGB,LGB这些算法以及支持缺失值,但还是建议自己处理缺失值,因为基于不同的数据缺失机制的原因,可能缺失的数据导致原有的数据分布存在偏差,一个场景就是MCAR,数据是随机缺失的。
那么如果数据是随机缺失的,就可以用一些技巧把数据补全。比如基于LR的MICE,基于RF的MissForest,以及目前的一些GAN方法都有比较好的表现
特征选择
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征:
- 特征是否发散:
如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:
这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
- 特征之间是否存在共线性:
如果存在共线性的话,对于LR这种线性模型会导致解空间的不稳定
- 特征含有是否相同:
如果两个特征名字不同,但描述的是同一个东西,那么这样的特征我们只需要留一个。因为对于树模型是徒增计算量,最终只会采用某一个来分裂,剩下的特征就不会被拿去分裂,这个时候,理论上这些含有相同的特征中,重要性高的只会有一个,而剩下的都是非常低的重要性。而对于线性模型来说,也会造成解空间的不稳定。
方差选择法
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征
from sklearn.feature_selection import VarianceThreshold
VarianceThreshold(threshold=3).fit_transform(iris.data)
相关系数法
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值
1 from sklearn.feature_selection import SelectKBest
2 from scipy.stats import pearsonr
3
4 #选择K个最好的特征,返回选择特征后的数据
5 #第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量,输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值。在此定义为计算相关系数
6 #参数k为选择的特征个数
7 SelectKBest(lambda X, Y: array(map(lambda x:pearsonr(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
卡方检验
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:
\(x^2=\sum \frac{(A-E)^2}{E}\)$
这个统计量的含义简而言之就是自变量对因变量的相关性
1 from sklearn.feature_selection import SelectKBest
2 from sklearn.feature_selection import chi2
3
4 #选择K个最好的特征,返回选择特征后的数据
5 SelectKBest(chi2, k=2).fit_transform(iris.data, iris.target)
互信息法
为了处理定量数据,互信息被提出,用以评价定性自变量对定性因变量的相关性的,互信息计算公式如下:
互信息描述的是:再给定Y的条件下,变量X的不确定度的缩减量。也就是说,互信息越大,两个变量越相关。
互信息和信息增益的计算结果是一样的,互信息也叫信息增益
最大化互心信息系数(MIC)
互信息有一些缺点:1. 对连续型数据不友好
所以有最大化互信息系数
\(MIC(x;y)=\max_{a*b<B}\frac{I(x;y)}{log2 \min(a,b)}\)
1 from sklearn.feature_selection import SelectKBest
2 from minepy import MINE
3
4 #由于MINE的设计不是函数式的,定义mic方法将其为函数式的,返回一个二元组,二元组的第2项设置成固定的P值0.5
5 def mic(x, y):
6 m = MINE()
7 m.compute_score(x, y)
8 return (m.mic(), 0.5)
9
10 #选择K个最好的特征,返回特征选择后的数据
11 SelectKBest(lambda X, Y: array(map(lambda x:mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
基于树的特征选择方法
可以通过像GBDT和RF之类的模型先行拿到一波特征重要性,进而选择高增益的特征
特征降维
当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。常见的降维方法除了以上提到的基于L1惩罚项的模型以外,另外还有主成分分析法(PCA)和线性判别分析(LDA),线性判别分析本身也是一个分类模型。PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
PCA
目的:将高维的数据映射到低维, 基于方差去寻找最有价值的信息
- 其思想就是 将数据投影到新的一组基上,基相当于坐标轴
- 协方差: 变量 a 和 b直接的相关性, 协方差越大, 相关性越密切, 取值范围为(-1,1)
- 线性相关: 比如2个特征: 收入: 1元 和 令一个收入 10角 这两个很相关啊, 甚至是同一个含义的表达
将高维的数据映射到低维, 基于方差去寻找最有价值的信息,降维后, 数据物理意义就变了, 谁也不知道是什么, 其思想就是 将数据投影到新的一组基上,基相当于坐标轴, 能够使得数据到了新的维度基变换下,坐标点分散够松散,数据间各有区分.
方差
我们知道数值的分散程度,可以用数学上的方差来表述。一个变量的方差可以看做是每个元素与变量均值的差的平方和的均值,即:
为了方便处理,我们将每个变量的均值都化为 0 ,因此方差可以直接用每个元素的平方和除以元素个数表示:
比如二维的数据, 我们寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
协方差
在一维空间中我们可以用方差来表示数据的分散程度。而对于高维数据,我们用协方差进行约束,协方差可以表示两个变量的相关性。为了让两个变量尽可能表示更多的原始信息,我们希望它们之间不存在线性相关性,因为相关性意味着两个变量不是完全独立,必然存在重复表示的信息。
至此,我们得到了降维问题的优化目标:将一组 N 维向量降为 K 维,其目标是选择 K 个单位正交基,使得原始数据变换到这组基上后,各变量两两间协方差为 0,而变量方差则尽可能大(在正交的约束下,取最大的 K 个方差)。
协方差矩阵
针对我们给出的优化目标,接下来我们将从数学的角度来给出优化目标。我们看到,最终要达到的目的与变量内方差及变量间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。于是我们有:
假设我们只有 a 和 b 两个变量,那么我们将它们按行组成矩阵 X:


矩阵对角化
根据我们的优化条件,我们需要将除对角线外的其它元素化为 0,并且在对角线上将元素按大小从上到下排列(变量方差尽可能大),这样我们就达到了优化目的。
设原始数据矩阵 X 对应的协方差矩阵为 C,而 P 是一组基按行组成的矩阵,设 Y=PX,则 Y 为 X 对 P 做基变换后的数据。设 Y 的协方差矩阵为 D,我们推导一下 D 与 C 的关系:

优化目标变成了寻找一个矩阵 P,满足
\(D=PCP^{T}\) 是一个对角矩阵,并且对角元素按从大到小依次排列,那么 P 的前 K 行就是要寻找的基,用 P 的前 K 行组成的矩阵乘以 X 就使得 X 从 N 维降到了 K 维并满足上述优化条件。
协方差矩阵 C 是一个是对称矩阵,在线性代数中实对称矩阵有一系列非常好的性质:
- 实对称矩阵不同特征值对应的特征向量必然正交。
PCA 求解步骤

更多信息:
SVD与PCA, PCA通过SVD求解,速度会更快
https://www.zhihu.com/search?type=content&q=PCA
LDA(线性判别分析)
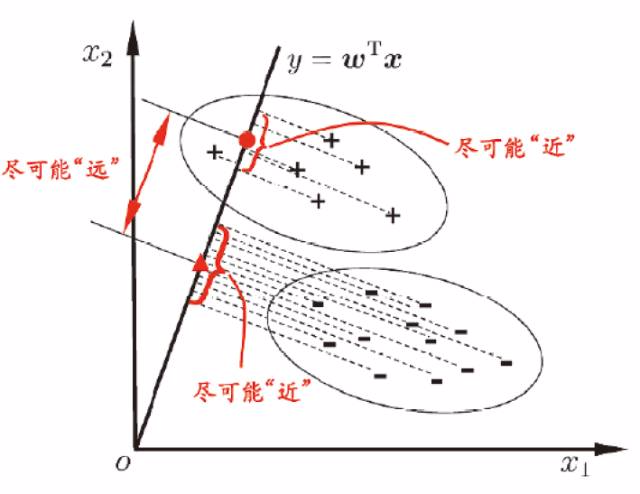
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的,这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”,如下图所示。 我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
局部线性嵌入
局部线性嵌入(Locally Linear Embedding,以下简称LLE)是非常重要的降维方法。和传统的PCA,LDA等关注样本方差的降维方法相比,LLE关注于降维时保持样本局部的线性特征(保持原有拓扑结构),由于LLE在降维时保持了样本的局部特征,它广泛的用于图像识别,高维数据可视化等领域。
https://www.jianshu.com/p/25a2a47bb60b
AutoEncoder
AutoEncoder(后面用AE简称)是一个自动编码器,它是通过重建输入的神经网络训练过程,它的隐藏成层的向量具有降维的作用。它的特点是编码器会创建一个隐藏层(或多个隐藏层)包含了输入数据含义的低维向量。然后有一个解码器,会通过隐藏层的低维向量重建输入数据。通过神经网络的训练最后AE会在隐藏层中得到一个代表输入数据的低维向量。它可以帮助数据分类、可视化、存储。AE是一个自动编码器是一个非监督的学习模式,只需要输入数据,不需要label或者输入输出对的数据。
https://www.cnblogs.com/huangyc/p/9824202.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号