Spark常见的问题以及解决方案
Spark为什么比Hadoop要快?
Spark比hadoop快的原因,我认为主要是spark的DAG机制优于hadoop太多,spark的DAG机制以及RDD的设计避免了很多落盘的操作,在窄依赖的情况下可以在内存中完成end to end的计算,相比于hadoop的map reduce编程模型来说,少了很多IO的开销。其次还有几个其他方面的助攻
- shuffl机制的不同
虽然2者都会遇到shuffle的场景,但是spark的shuffle更加先进。对于MapReduce,其在Shuffle时需要花费大量时间进行排序,排序在MapReduce的Shuffle中似乎是不可避免的。而spark在shuffle的时候,不一定会用到排序,有可能会使用Hash的形式 - mr是多进程,spark则是多线程
线程相比于进程,少了很多CPU调度下的资源切换。
spark的shfflue机制
上面说到spark比mr优越的一个原因也是shffle机制的不同。具体来说,spark的shffle机制从它诞生到现在一共有这么几种。
shuffle的意思就是打乱数据顺序使得相同的key被统一到同一个分区。
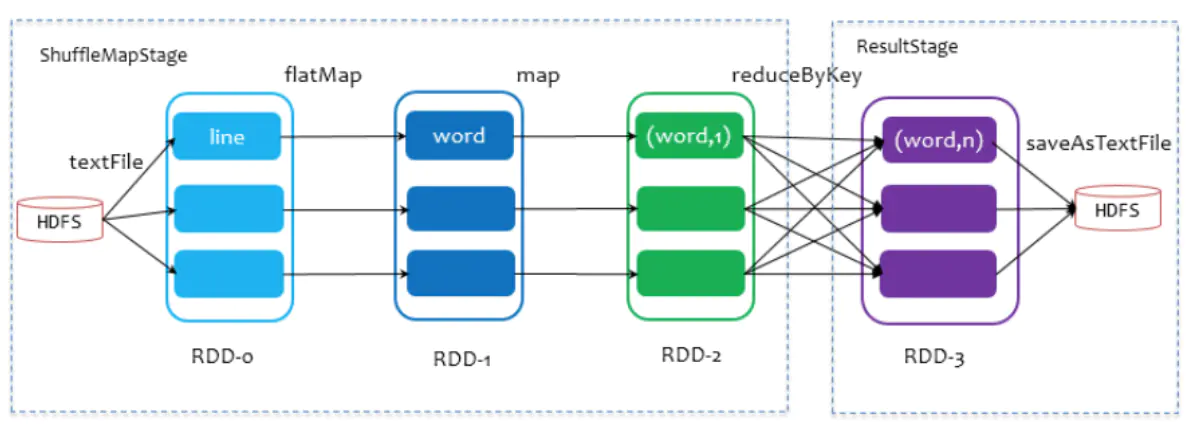
spark中只有2类stage:ShuffleMapStage和ResultStage。但其总的过程包含有map阶段(shuffle write)和reduce阶段(shuffle read),两个阶段位于不同的stage中。
ResultStage基本上对应代码中的action算子, 而ShuffleMapStage 的则伴随着 shuffle IO。spark的mr和hadoop的mapreduce不是一个东西。map端task和reduce端task不在相同的stage中,map task位于ShuffleMapStage,reduce task位于ResultStage。map task会先执行,将上一个stage得到的最后结果写出,后执行的reduce task拉取上一个stage进行合并。
对于一次shuffle,map过程和reduce过程都有若干个task来执行。对于task的个数,map端的task个数和RDD的partition个数相同,reduce 端的 stage 默认取spark.default.parallelism 这个配置项的值作为分区数,如果没有配置,则以 map 端的最后一个 RDD 的分区数作为其分区数,分区数就将决定 reduce 端的 task 的个数。
在Spark的源码中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager。
spark1.2
在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager。它的计算模式比较的简单粗暴,详细如下:
- shuffle write阶段
这个阶段将stage中每个task处理的数据根据算子进行“划分”。比如reduceByKey,就是对相同的key执行hash算法,从而将相同都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
- shuffle read阶段
stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,task给下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
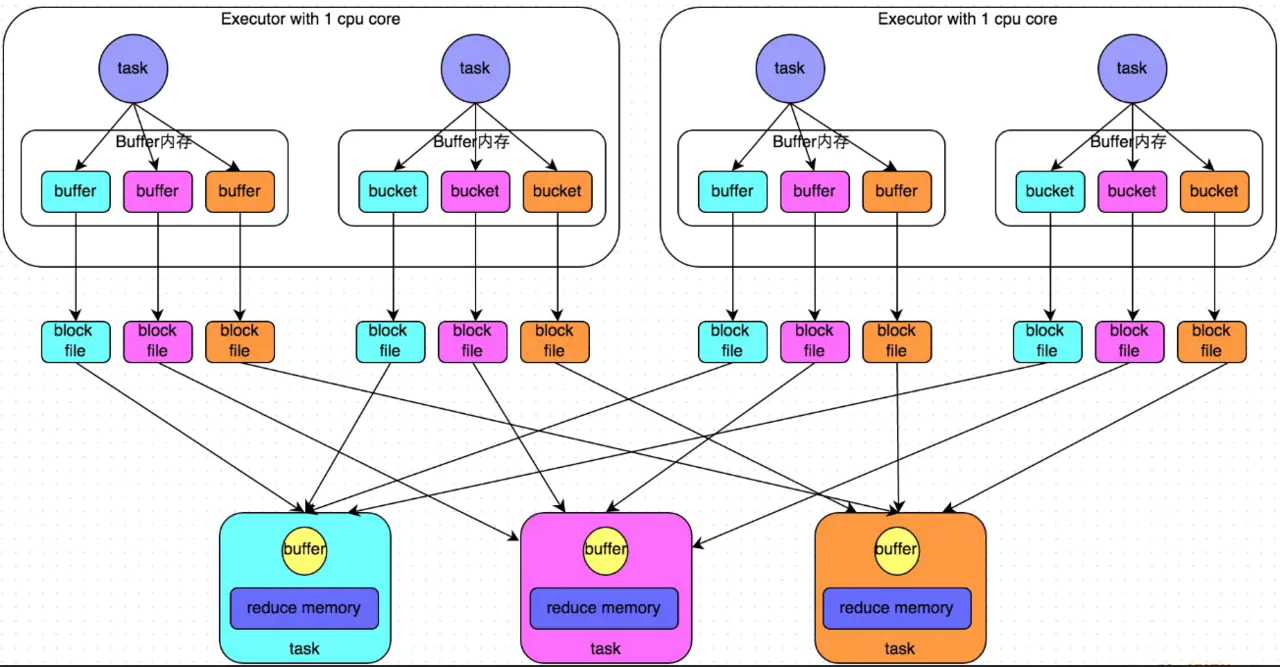
那么针对这种简单粗暴的HashShuffleManager,有着一个非常严重的弊端:会产生大量的中间磁盘文件,这样大量的磁盘IO操作会很影响性能。磁盘文件的数量由下一个stage的task数量决定,即下一个stage的task有多少个,当前stage的每个task就要创建多少份磁盘文件。比如下一个 stage 总共有 100 个 task,那么当前 stage 的每个 task 都要创建 100 份磁盘文件,如果当前stage有50个 task,那么总共会建立5000个磁盘文件。
优化之后的HashShuffleManager
由于原版的HashShuffleManager,HashShuffleManager后期进行了优化,这里说的优化是指可以设置一个参数,
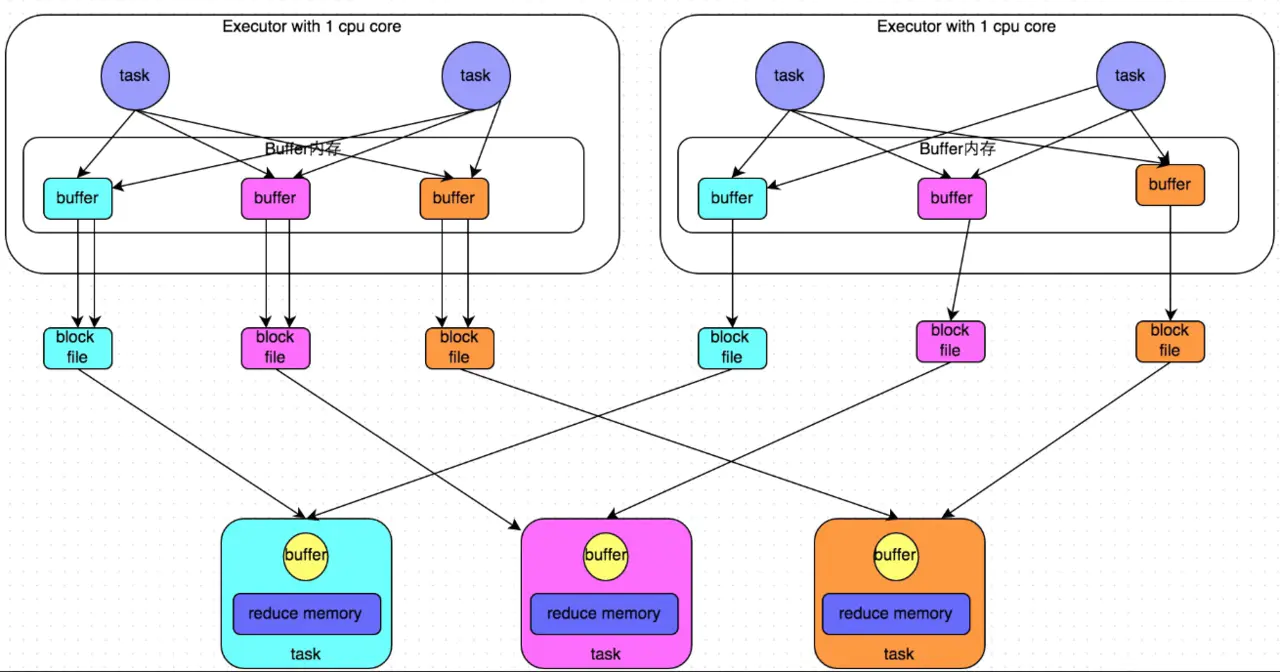
spark.shuffle.consolidateFiles=true。该参数默认值为false,通常来说如果我们使用HashShuffleManager,那么都建议开启这个选项。开启consolidate机制之后,在shuffle write过程中,task不会为下游stage的每个task创建一个磁盘文件,此时会出现shuffleFileGroup的概念,每个 shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。而此时就会根据Executor数,并行执行task。第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件内。当Executor执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup,将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。即运行在同一个Executor的task会复用之前的磁盘文件。 这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
当前spark默认使用的SortShuffleManager
在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager。SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。当shuffle read task的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),就会启用bypass机制。
普通运行模式
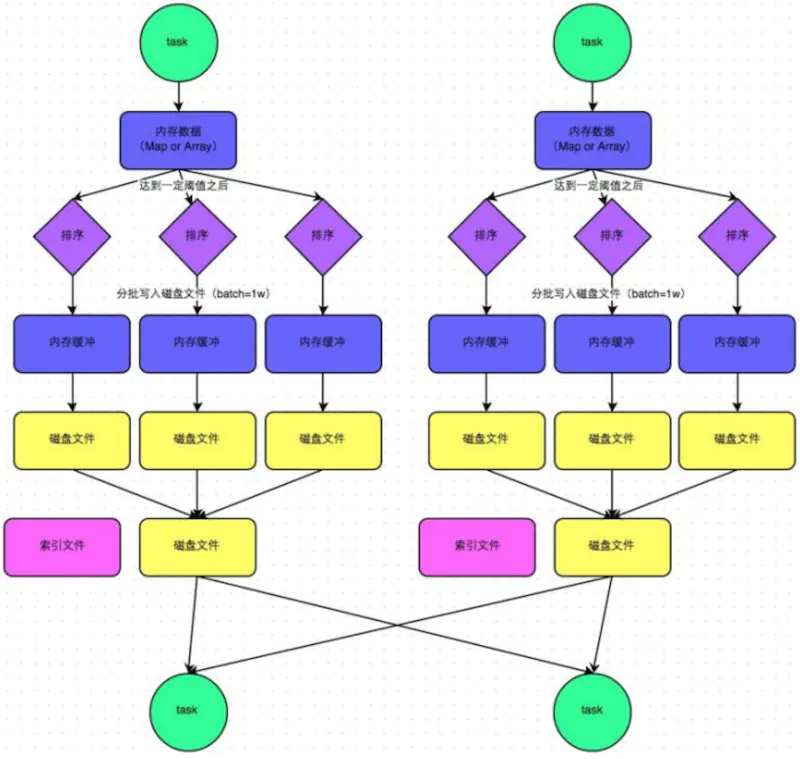
在普通模式下,数据会先写入一个内存数据结构中,此时根据不同的shuffle算子,可以选用不同的数据结构。如果是由聚合操作的shuffle算子,就是用map的数据结构(边聚合边写入内存),如果是join的算子,就使用array的数据结构(直接写入内存)。等到内存容量到了临界值就准备溢写到磁盘。在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序,排序之后,会分批将数据写入磁盘文件,每批次默认1万条数据。此时task往磁盘溢写,会产生多个临时文件,最后会将所有的临时文件都进行合并,合并成一个大文件。最终只剩下两个文件,一个是合并之后的数据文件,一个是索引文件,标识了下游各个task的数据在文件中的start offset与end offset。下游的task根据索引文件读取相应的数据文件。需要注意的是,此处所说的两个文件,是指上游一个task生成两个文件,而非所有的task最终只有两个文件。
bypass机制
触发bypass机制的条件:
- shuffle map task的数量小于spark.shuffle.sort.bypassMergeThreshold参数的值(默认200)
- 不是聚合类的shuffle算子(比如groupByKey)
排序的时间复杂度最高不能优于O(nlogn),那么如果将排序的时间复杂度省下,那么shuffle性能将会提升很多。bypass机制与普通SortShuffleManager运行机制的不同在于,bypass机制就是利用了hash的O(1)时间复杂度取代了排序的操作开销,提升了这部分的性能。
task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。如上,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
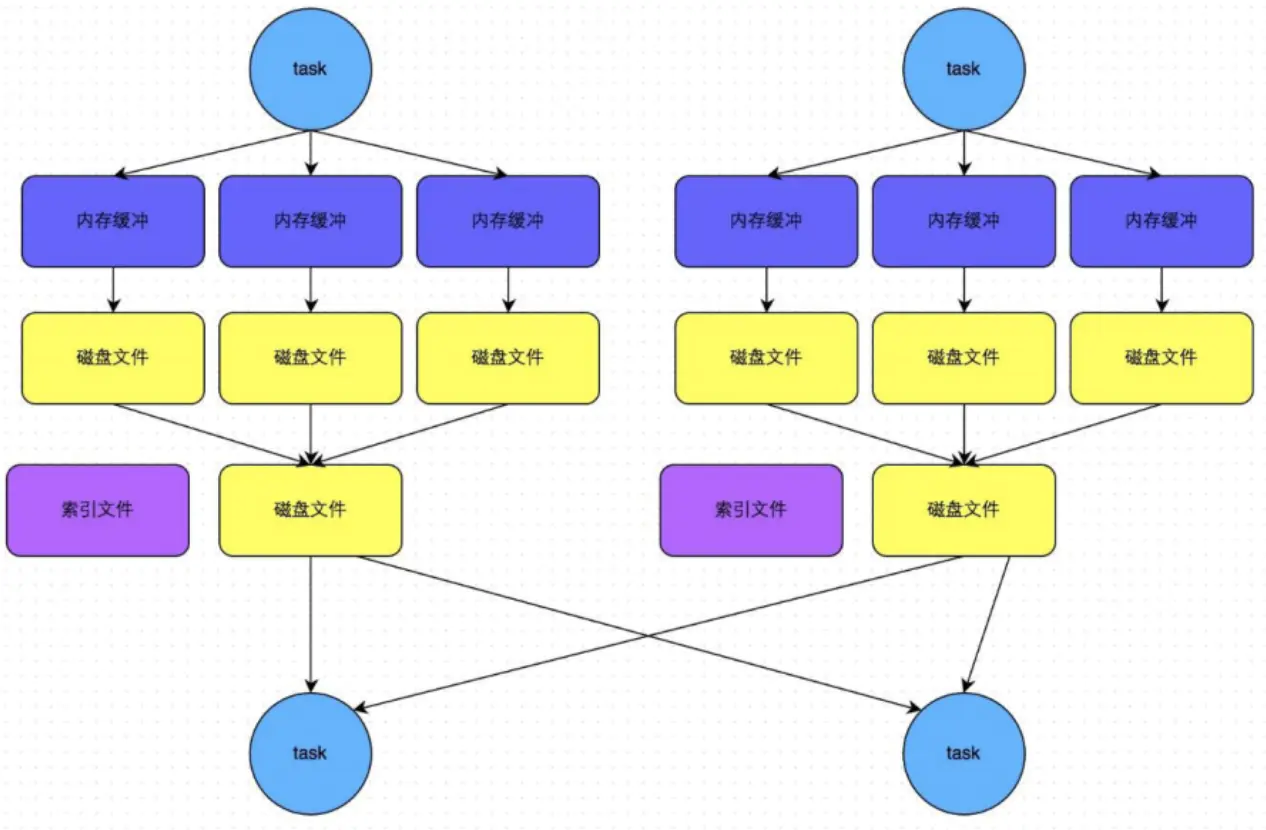
针对shuffle机制的调优策略
- spark.shuffle.file.buffer
该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小(默认是32K)。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。在实践中发现,合理调节该参数。
- spark.reducer.maxSizeInFlight:
该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。
- spark.shuffle.io.maxRetries & spark.shuffle.io.retryWait:
spark.shuffle.io.retryWait:huffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。(默认是3次)
spark.shuffle.io.retryWait:该参数代表了每次重试拉取数据的等待间隔。(默认为5s)
一般的调优都是将重试次数调高,不调整时间间隔。
- spark.shuffle.memoryFraction:
该参数代表了Executor内存中,分配给shuffle read task进行聚合操作的内存比例。
- spark.shuffle.manager
该参数用于设置shufflemanager的类型(默认为sort)。Spark1.5x以后有三个可选项:
Hash:spark1.x版本的默认值,HashShuffleManager
Sort:spark2.x版本的默认值,普通机制,当shuffle read task 的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数,自动开启bypass 机制
tungsten-sort:
复制代码spark.shuffle.sort.bypassMergeThreshold
参数说明:当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作。
调优建议:当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些
- spark.shuffle.consolidateFiles:
如果使用HashShuffleManager,该参数有效。如果设置为true,那么就会开启consolidate机制,也就是开启优化后的HashShuffleManager。
如果的确不需要SortShuffleManager的排序机制,那么除了使用bypass机制,还可以尝试将spark.shffle.manager参数手动指定为hash,使用HashShuffleManager,同时开启consolidate机制。在实践中尝试过,发现其性能比开启了bypass机制的SortShuffleManager要高出10%~30%。
Spark基石--RDD
RDD又叫弹性分布式数据集,表示一个只读的包含多个并行分区的集合。其中
- 弹性意味着:当计算过程中内存不足时可刷写到磁盘等外存上,可与外存做灵活的数据交换
- 分布式:分区使得可以在多个机器上并行计算
- 一组只读的、可分区的分布式数据集合,集合内包含了多个分区
一个最简单的rdd至少要包含以下几个东西,这些都被定义在spark core组件的rdd的抽象类中
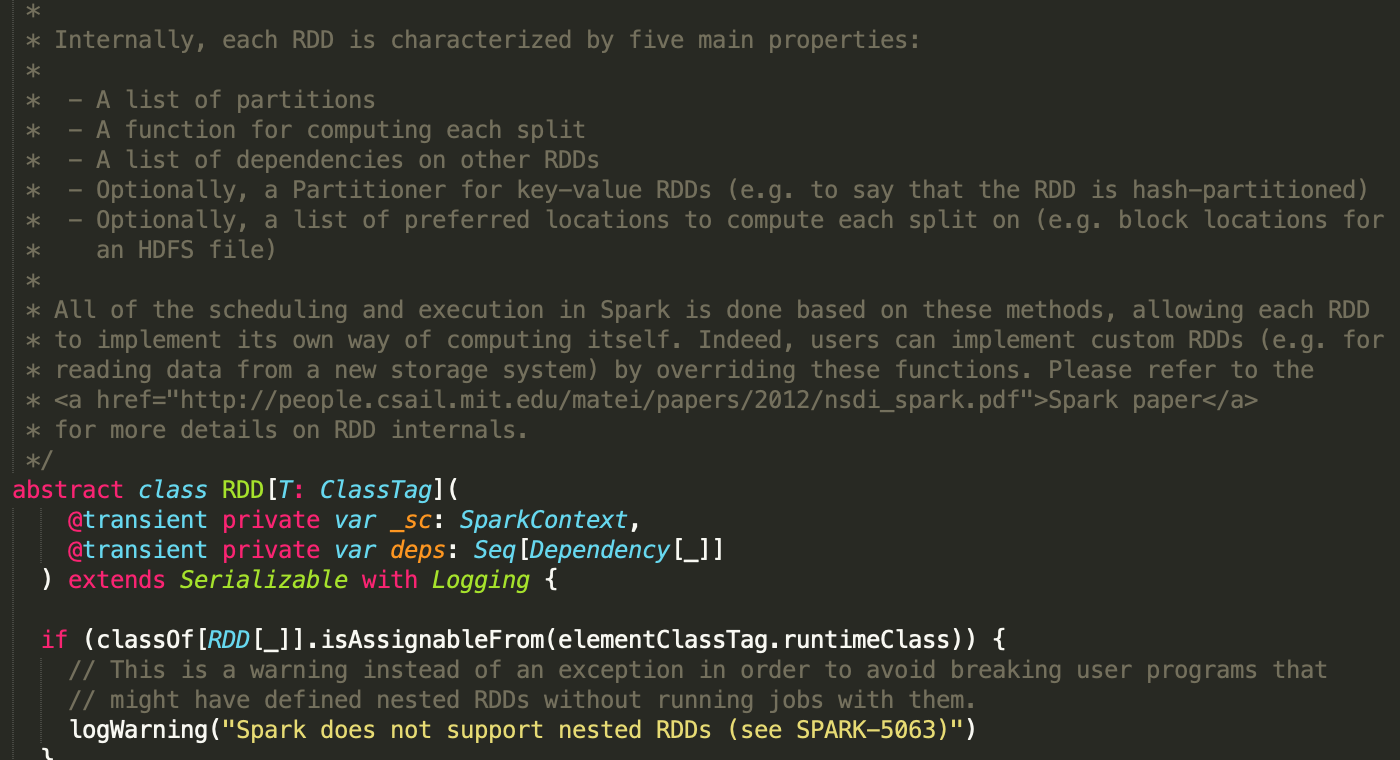
- 一组分区
- 定义在这个分区上的操作
- 当前rdd和其他rdd的依赖
可选的有 - Preferred Location
是一个列表,用于存储每个 Partition 的优先位置。对于每个 HDFS 文件来说,这个列表保存的是每个 Partition 所在的块的位置,也就是该文件的「划分点」
- 分区方式
RDD 的分区方式主要包含两种:Hash Partitioner 和 Range Partitioner,这两种分区类型都是针对 Key-Value 类型的数据,如是非 Key-Value 类型则分区函数为 None。Hash 是以 Key 作为分区条件的散列分布,分区数据不连续,极端情况也可能散列到少数几个分区上导致数据不均等;Range 按 Key 的排序平衡分布,分区内数据连续,大小也相对均等。
那么我们把rdd画出来之后它大概是这个样子
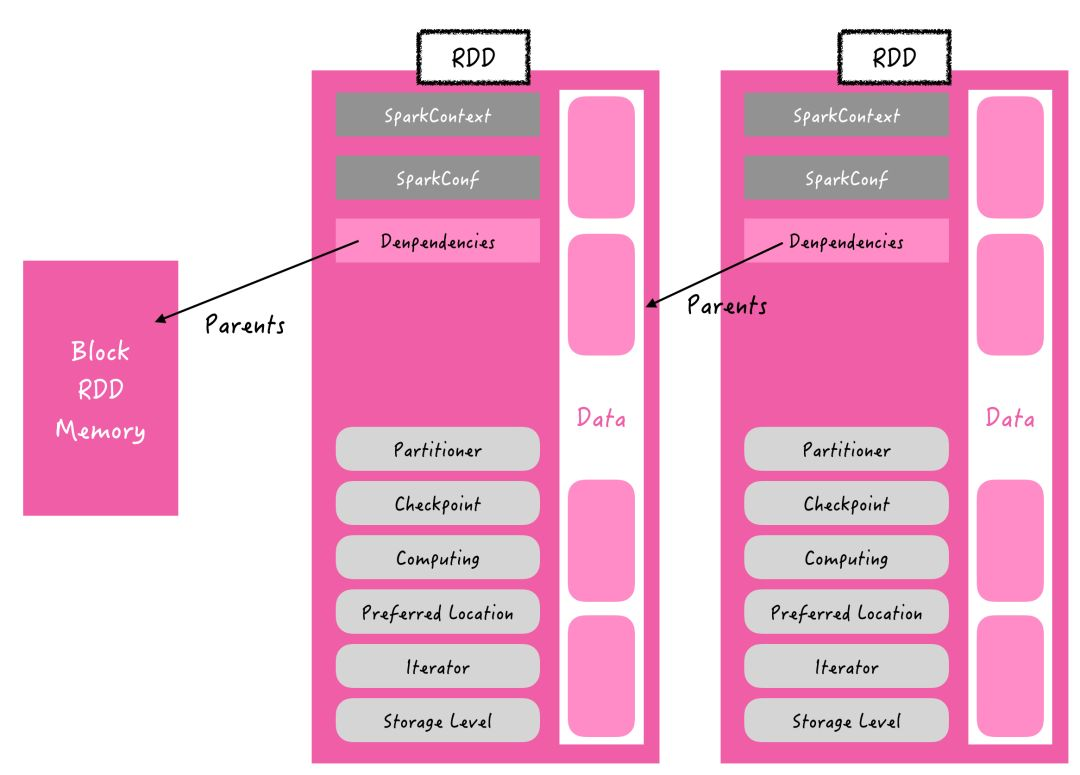
图所示是 RDD 的内部结构图,它是一个只读、有属性的数据集。它的属性用来描述当前数据集的状态。
数据集data由数据的分区(partition)组成,并由(block)映射成真实数据。
RDD 的主要属性可以分为 3 类:与上述图中代码对应,细节上来说主要有:
-
- 与其他 RDD 的关系(parents、dependencies)
-
- 数据(partitioner、checkpoint、storage level、iterator 等)
-
- RDD 自身属性(sparkcontext、sparkconf)
RDD 自身属性
从自身属性说起,自身属性包含spark上下文,以及初始化sc时候的配置信息conf
SparkContext 是 Spark job 的入口,由 Driver 创建在 client 端, 并向集群资源管理器如yarn等申请资源这些都是由sc完成
conf就是我们设置的一些job参数
数据集list
RDD 内部的数据集合在逻辑上和物理上被划分成多个小子集合,这样的每一个子集合我们将其称为分区(Partitions),分区的个数会决定并行计算的粒度,有多少分区就有多少的task,而每一个分区数值的计算都是在一个单独的任务中进行的,因此并行任务的个数也是由 RDD分区的个数决定的。但事实上 RDD 只是数据集的抽象,分区内部并不会存储具体的数据。Partition 类内包含一个 index 成员,表示该分区在 RDD 内的编号,通过 RDD 编号+分区编号可以确定该分区对应的唯一块编号,再利用底层数据存储层提供的接口就能从存储介质(如:HDFS、Memory)中提取出分区对应的数据。
RDD 的分区方式主要包含两种:Hash Partitioner 和 Range Partitioner,这两种分区类型都是针对 Key-Value 类型的数据,如是非 Key-Value 类型则分区函数为 None。Hash 是以 Key 作为分区条件的散列分布,分区数据不连续,极端情况也可能散列到少数几个分区上导致数据不均等;Range 按 Key 的排序平衡分布,分区内数据连续,大小也相对均等。
Preferred Location 是一个列表,用于存储每个 Partition 的优先位置。对于每个 HDFS 文件来说,这个列表保存的是每个 Partition 所在的块的位置,也就是该文件的「划分点」。
Storage Level 是 RDD 持久化的存储级别,RDD 持久化可以调用两种方法:cache 和 persist:persist 方法可以自由的设置存储级别,默认是持久化到内存;cache 方法是将 RDD 持久化到内存,cache 的内部实际上是调用了persist 方法,由于没有开放存储级别的参数设置,所以是直接持久化到内存。
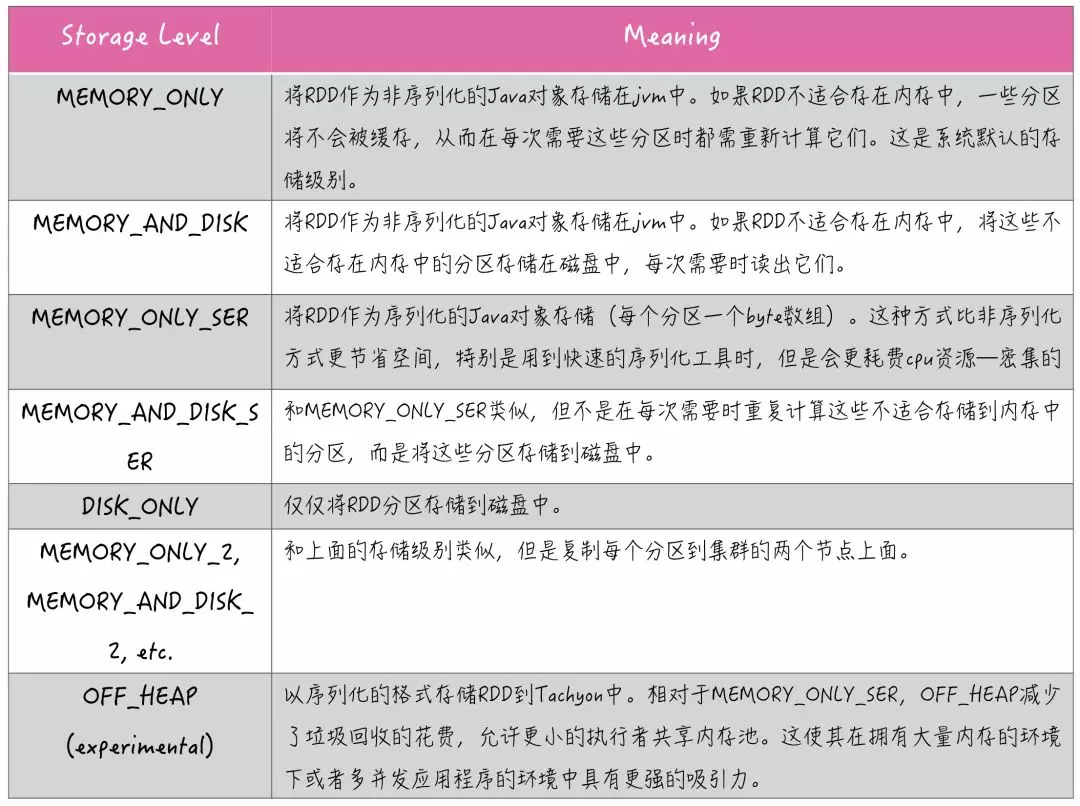
checkpoint
Checkpoint 是 Spark 提供的一种缓存机制,当需要计算依赖链非常长又想避免重新计算之前的 RDD 时,可以对 RDD 做 Checkpoint 处理,检查 RDD 是否被物化或计算,并将结果持久化到磁盘或 HDFS 内。Checkpoint 会把当前 RDD 保存到一个目录,要触发 action 操作的时候它才会执行。在 Checkpoint 应该先做持久化(persist 或者 cache)操作,否则就要重新计算一遍。若某个 RDD 成功执行 checkpoint,它前面的所有依赖链会被销毁。
与 Spark 提供的另一种缓存机制 cache 相比:cache 缓存数据由 executor 管理,若 executor 消失,它的数据将被清除,RDD 需要重新计算;而 checkpoint 将数据保存到磁盘或 HDFS 内,job 可以从 checkpoint 点继续计算。Spark 提供了 rdd.persist(StorageLevel.DISK_ONLY) 这样的方法,相当于 cache 到磁盘上,这样可以使 RDD 第一次被计算得到时就存储到磁盘上,它们之间的区别在于:persist 虽然可以将 RDD 的 partition 持久化到磁盘,但一旦作业执行结束,被 cache 到磁盘上的 RDD 会被清空;而 checkpoint 将 RDD 持久化到 HDFS 或本地文件夹,如果不被手动 remove 掉,是一直存在的。
spark血统
一个作业从开始到结束的计算过程中产生了多个 RDD,RDD 之间是彼此相互依赖的,我们把这种父子依赖的关系称之为「血统」。RDD 只支持粗颗粒变换,即只记录单个块(分区)上执行的单个操作,然后创建某个 RDD 的变换序列(血统 lineage)存储下来。
变换序列指每个 RDD 都包含了它是如何由其他 RDD 变换过来的以及如何重建某一块数据的信息。因此 RDD 的容错机制又称「血统」容错。 要实现这种「血统」容错机制,最大的难题就是如何表达父 RDD 和子 RDD 之间的依赖关系。
分区机制
RDD 的分区机制有两个关键点:一个是关键参数,即 Spark 的默认并发数 spark.default.parallelism;另一个是关键原则,RDD 分区尽可能使得分区的个数等于集群核心数目。
设置的时候可以在spark conf下设置
- spark.default.parallelism
- 或者在rdd转换的时候做repartition
RDD常用操作/算子
action算子

transform算子
spark 数据倾斜问题的处理方案
数据倾斜也是我们经常遇到的问题之一,那么通常情况下,判断spark数据倾斜的方法有2个
- client模式下,会有“进度条”,会显示当前位于那个stage,以及当前stage的task数量,当进度条突然变得很慢的时候,或者卡在某个stage不动的话,一般都是出现了数据倾斜(很少会出现资源被占)
- spark UI: 从spark ui中可以看出每个task处理的数据量和消耗的时间
数据倾斜发生的原因
数据倾斜的原理很简单:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数据,但是个别key却对应了100万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了;但是个别task可能分配到了100万数据,要运行一两个小时。因此,整个Spark作业的运行进度是由运行时间最长的那个task决定的。
因此出现数据倾斜的时候,Spark作业看起来会运行得非常缓慢,甚至可能因为某个task处理的数据量过大导致内存溢出。
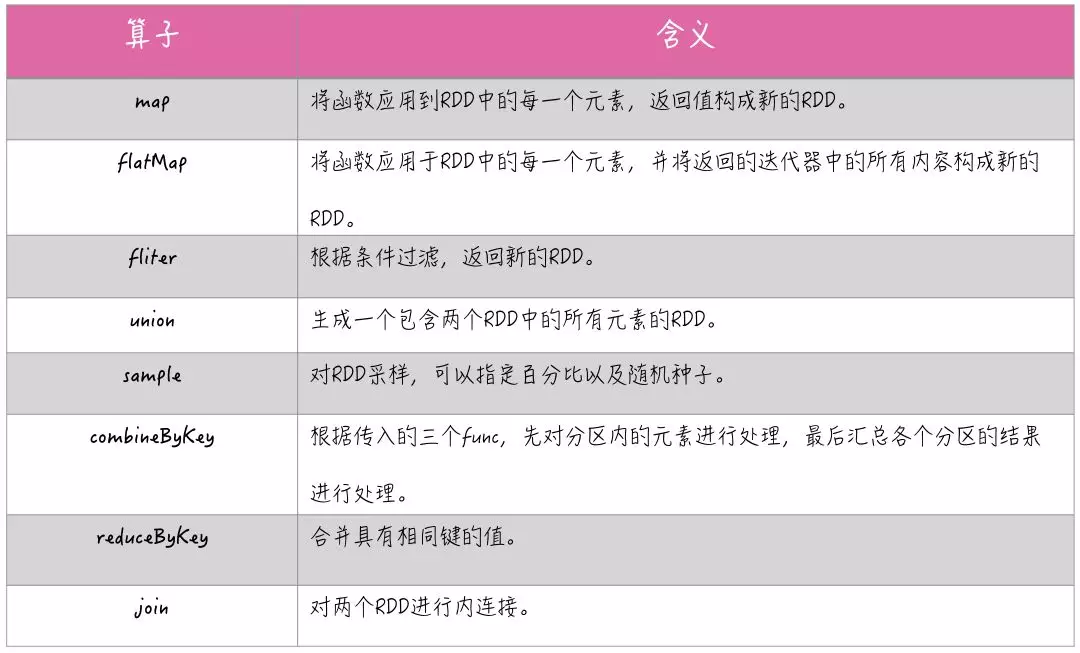
下图就是一个很清晰的例子:
hello这个key,在三个节点上对应了总共7条数据,这些数据都会被拉取到同一个task中进行处理;而world和you这两个key分别才对应1条数据,所以另外两个task只要分别处理1条数据即可。此时第一个task的运行时间可能是另外两个task的7倍,而整个stage的运行速度也由运行最慢的那个task所决定。
那么面对数据倾斜大概有如下几个方案
map侧代替join侧
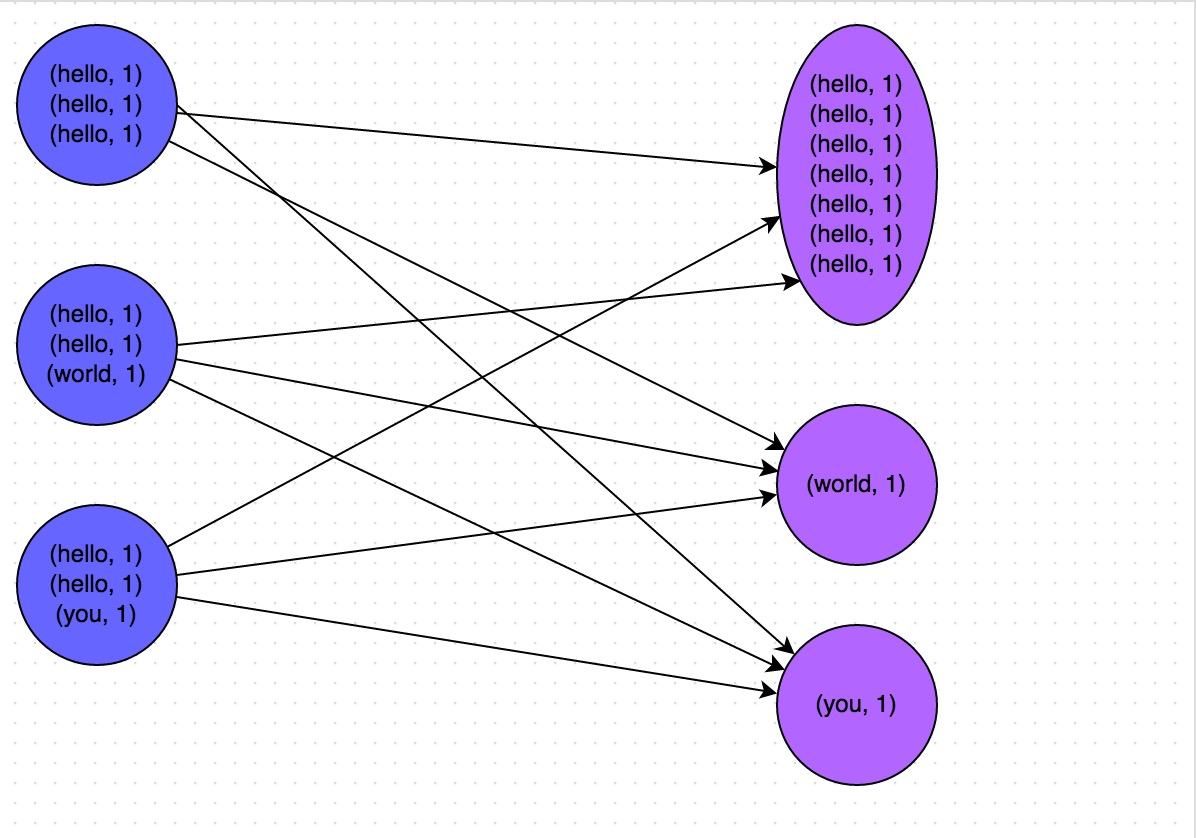
小表join大表,如果小表能够被存储在work的内存中的话,通过Spark的Broadcast机制,将Reduce侧Join转化为Map侧Join,避免Shuffle, 整个流程从宽依赖转变为窄依赖,从而完全消除Shuffle带来的数据。
随机前缀后缀key
为数据量特别大的Key增加随机前/后缀,使得原来Key相同的数据变为Key不相同的数据,从而使倾斜的数据集分散到不同的Task中,彻底解决数据倾斜问题。Join另一则的数据中,与倾斜Key对应的部分数据,与随机前缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜Key如何加前缀,都能与之正常Join。

增加task的并行度
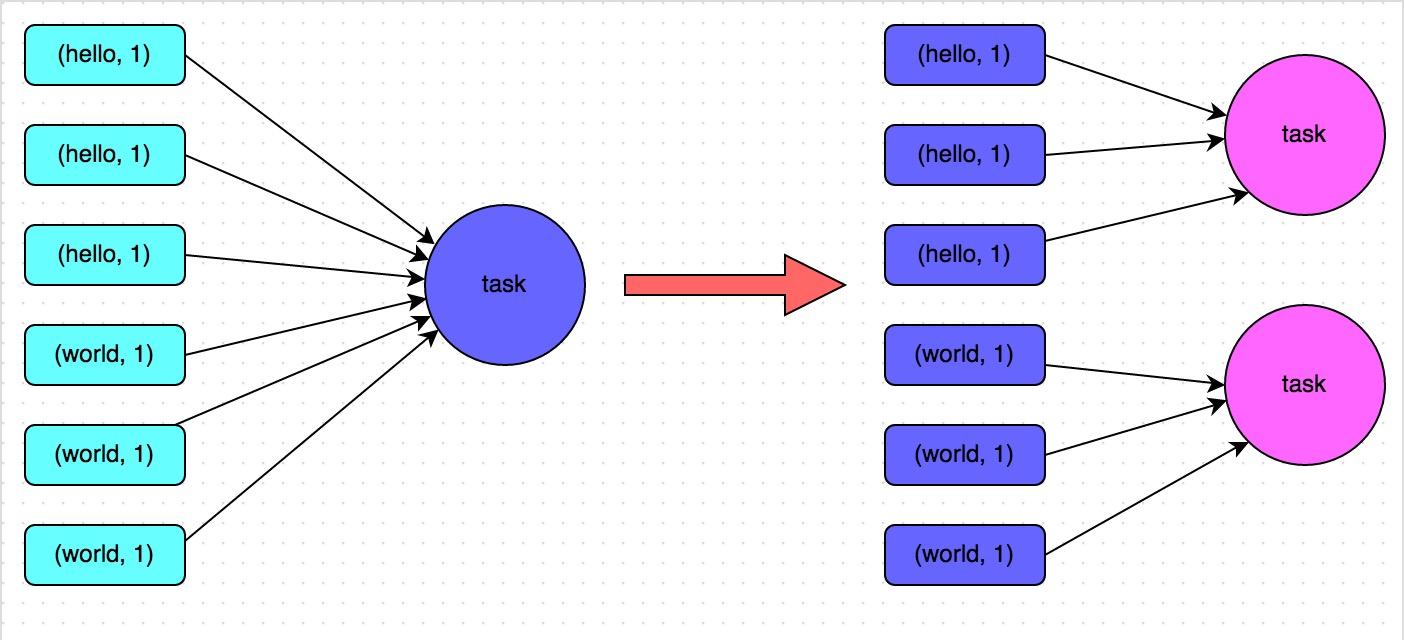
也可以被称为提高shfflue操作的并行度,在对RDD执行shuffle算子时,给shuffle算子传入一个参数,比如reduceByKey(1000),该参数就设置了这个shuffle算子执行时shuffle read task的数量。对于Spark SQL中的shuffle类语句,比如group by、join等,需要设置一个参数,即spark.sql.shuffle.partitions,该参数代表了shuffle read task的并行度,该值默认是200
增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。举例来说,如果原本有5个key,每个key对应10条数据,这5个key都是分配给一个task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个task就处理10条数据,那么自然每个task的执行时间都会变短了。具体原理如下图所示。
参考文献或转载
shfflue机制 https://juejin.im/post/6844904099872243719
spark rdd
[数据倾斜1](http://www.jasongj.com/spark/skew/, https://blog.csdn.net/u012501054/article/details/101371050)

