CTR预估系列模型漫谈
FM
FM的主要内容
了解fm模型之前,需要先说一下lr带入一下场景。lr作为早期ctr预估里面的模型,其速度上有着无可比拟的优势,而偏偏ctr场景下伴随着有大量的离散特征,高维稀疏特征,这个很适合lr的场景。
lr整个模型可以被描述为一个公式:
lr的特点就是简单高效速度快可解释性强,但是他有什么问题呢?lr需要依赖大量的人工特征,所以后面伴随lr适合离散特征的特点,facebook出了一版模型就是通过gbdt+lr的策略,数据过一遍gbdt拿到叶子节点的index作为特征丢到lr里面,这是题外话了。我们做特征的时候,做一些特征组合往往是有效的,比如说点击量和购买量,把这两个特征相除得到一个转化率的特征往往能够提升模型预测购买与否的精度,那么能否将特征组合的能力体现在模型层面呢?于是就出现了lr模型的改进:加入组合特征
将任意两个特征进行组合,可以将这个组合出的特征看作一个新特征,融入线性模型中。而组合特征的权重可以用来表示,和一阶特征权重一样,这个组合特征权重在训练阶段学习获得。其实这种二阶特征组合的使用方式,和多项式核SVM是等价的。虽然这个模型看上去貌似解决了二阶特征组合问题了,但是它有个潜在的问题:它对组合特征建模,泛化能力比较弱,尤其是在大规模稀疏特征存在的场景下,这个毛病尤其突出,因为当我被组合的两个特征不同时存在,意思就是大家都是0的时候,那么这样组合导致的该组合项的权重就是0,这样是没有意义的,而恰好,ctr场景下,大规模稀疏特征带来的这种问题很多。这时候,fm就上场了,为了解决刚刚说到的这个问题,fm为每个特征引入了辅助向量:
其中\(k\)是一个超参数,自己指定,代表这个隐向量的维度。FM对于每个特征,学习一个大小为\(k\)的一维向量,于是,两个特征 \(x_i\)和 \(x_j\)的特征组合的权重值,通过特征对应的向量 \(v_i\) 和 \(v_j\)的内积 \(<v_i,v_j>\)来表示

所以最后我们的fm模型可以表示为上图的形式,其主要贡献就是引入了辅助向量的概念。
这本质上是在对特征进行embedding化表征,和目前非常常见的各种实体embedding本质思想是一脉相承的,但是很明显在FM这么做的年代(2010年),还没有现在能看到的各种眼花缭乱的embedding的形式与概念。所以FM作为特征embedding,可以看作当前深度学习里各种embedding方法的老前辈。
具体的这个辅助向量的样子如下
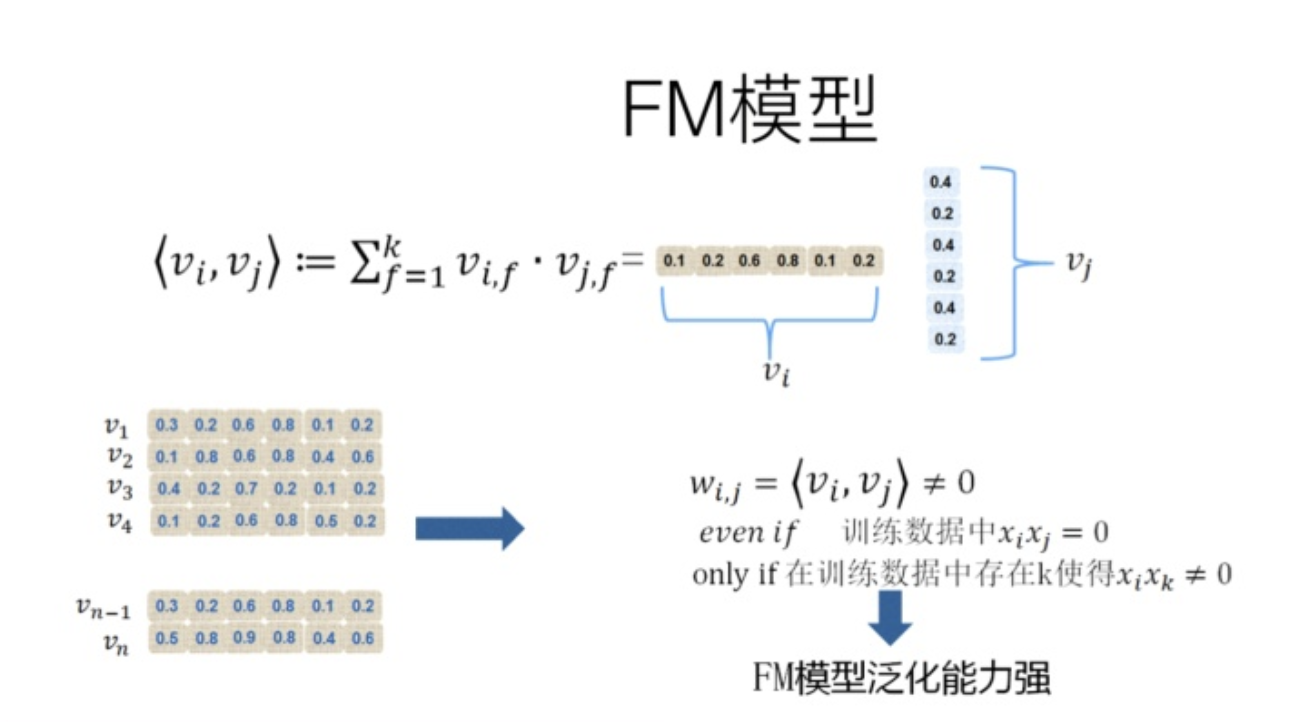
FM的这种特征embedding模式,在大规模稀疏特征应用环境下比较好用?为什么说它的泛化能力强呢?因为即使在训练数据里两个特征并未同时在训练实例里见到过,意味着 一起出现的次数为0,如果换做SVM的模式,是无法学会这个特征组合的权重的。但是因为FM是学习单个特征的embedding,并不依赖某个特定的特征组合是否出现过,所以只要某个特征和其它任意特征组合出现过,那么就可以学习自己对应的embedding向量。于是,尽管 这个特征组合没有看到过,但是在预测的时候,如果看到这个新的特征组合,因为被组合的两个特征都能学会自己对应的embedding,所以可以通过内积算出这个新特征组合的权重。这是为何说FM模型泛化能力强的根本原因。
其实本质上,这也是目前很多花样的embedding的最核心特点,就是从0/1这种二值硬核匹配,切换为向量软匹配,使得原先匹配不上的,现在能在一定程度上算密切程度了,具备很好的泛化性能。
化简的FM
如果按上述做法训练模型的话,其时间复杂度是很高的,大概是到\(O(kn^2)\)的一个程度,主要时间都消耗在做fm的过程上,那么化简一下:
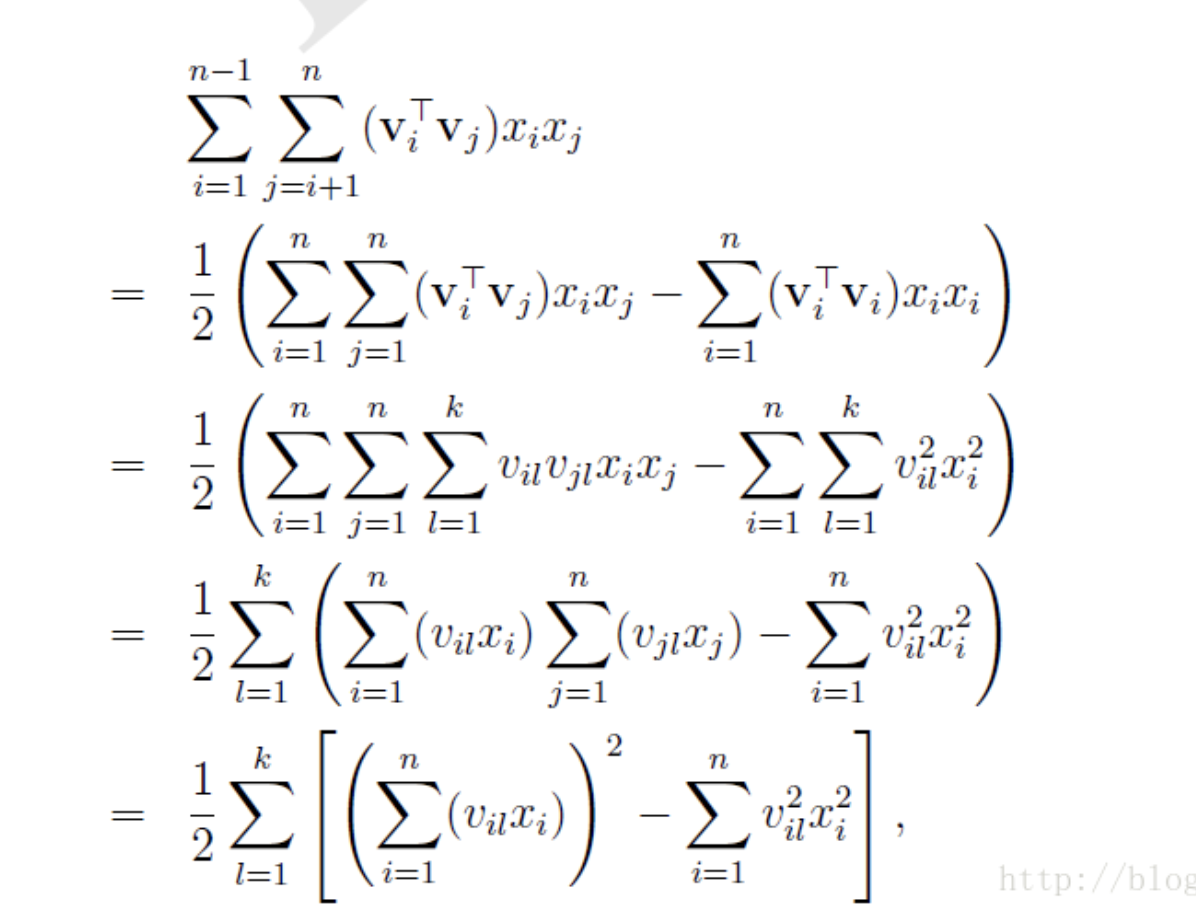
对于倒数第二步,其实\(i\)和\(j\)都是一样的,带入就会发现啊可以合并成一个平方项
就可以将这部分转化为 和的平方-平方的和 的形式
在DeepFM实现的过程中,一般都不显示写出隐向量\(V\),就是这里的\(v_{i,l}\),我们之间用embedding后的值来表示它们,毕竟通常的embedding本质上也是一个单层的MLP,其输入\(x\)和权重\(w\)就可以表示
FM中的\(v*x\).
DeepFM
说到deepfm,其核心就是将deep和fm相融合。DeepFM模型包含FM和DNN两部分,FM模型可以抽取low-order特征,DNN可以抽取high-order特征
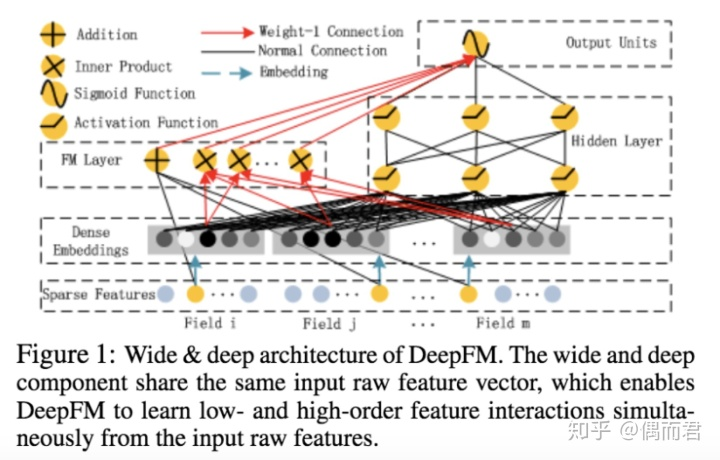
为了同时利用low-order和high-order特征,DeepFM包含FM和DNN两部分,两部分共享输入特征。对于特征i,标量wi是其1阶特征的权重,该特征和其他特征的交互影响用隐向量Vi来表示。Vi输入到FM模型获得特征的2阶表示,输入到DNN模型得到high-order高阶特征。模型联合训练,结果可表示为:
的形式,deep就是一个dnn,而fm部分就是上面说到的fm模型。相比于原始的fm,deepfm会把离散的特征embedding到低维度,再分别输入fm和dnn拿到各自的输出,结合后得到最终的输出。embedding的时候,其实特征会被分成多个fileds。比如说类别特征,我们可以把他做one-hot出来得到更多的维度,这个特征包含的这些维度就是一个filed,比如说性别[0,1], 年龄段one-hot等

