循环神经网络笔记
RNN
RNN背后的思想是利用顺序信息。在传统的神经网络中,我们假设所有的输入(包括输出)之间是相互独立的。对于很多任务来说,这是一个非常糟糕的假设。如果你想预测一个序列中的下一个词,你最好能知道哪些词在它前面。RNN之所以循环的,是因为它针对系列中的每一个元素都执行相同的操作,每一个操作都依赖于之前的计算结果。换一种方式思考,可以认为RNN记忆了到当前为止已经计算过的信息。
先放一张rnn的结构图
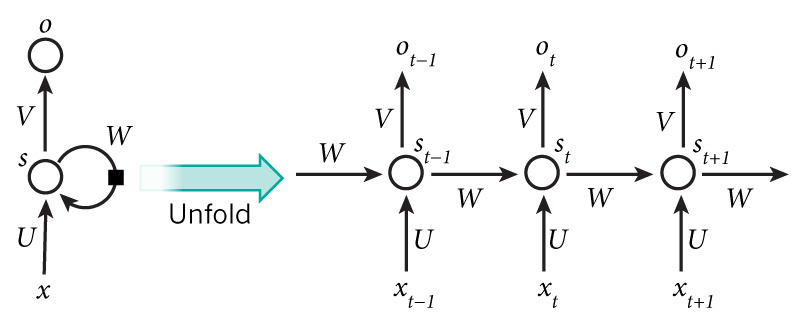
上面的图中展示了RNN被展开成一个全网络后的结构。这里展开的意思是把针对整个序列的网络结构表示出来,实际上,每个节点,也就是每个step,其实都是一个具有n和hiden units的mlp,就像下面这样
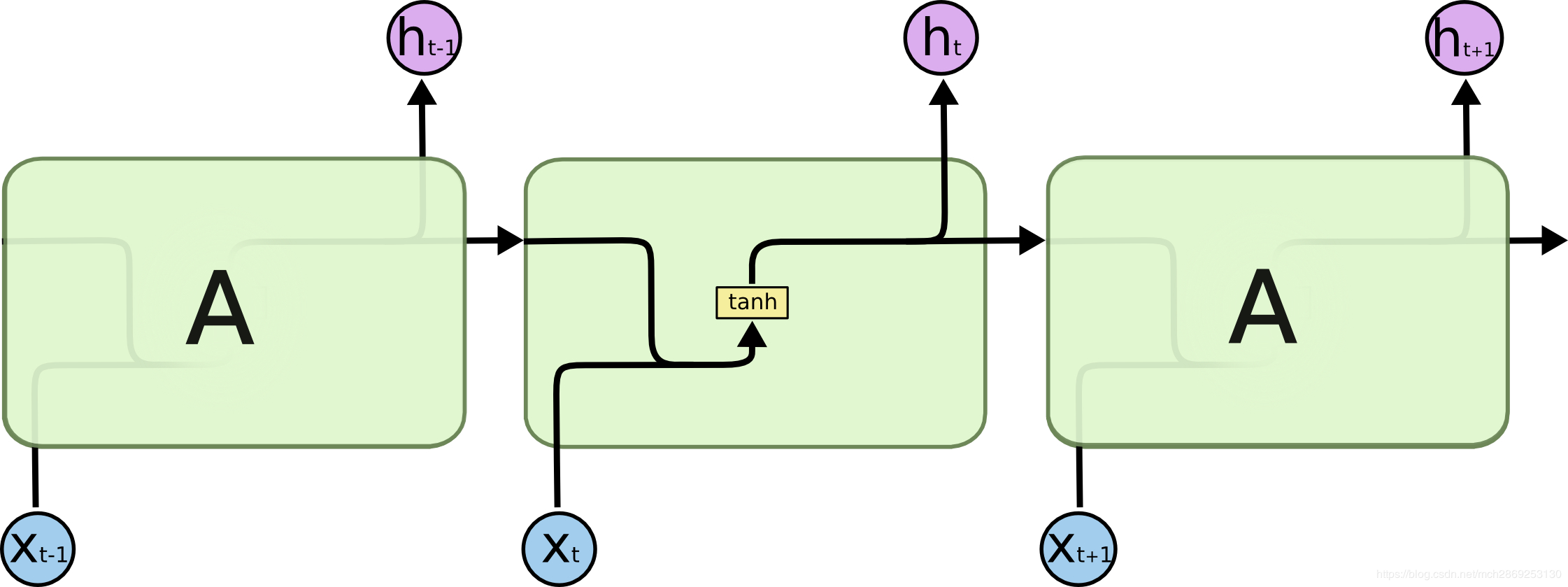
下图更好理解RNN的每个cell
LSTM
lstm解决了rnn不能捕获长期依赖所导致的梯度消失问题,其主要改动,就是cell内部多了几个gate和1个state
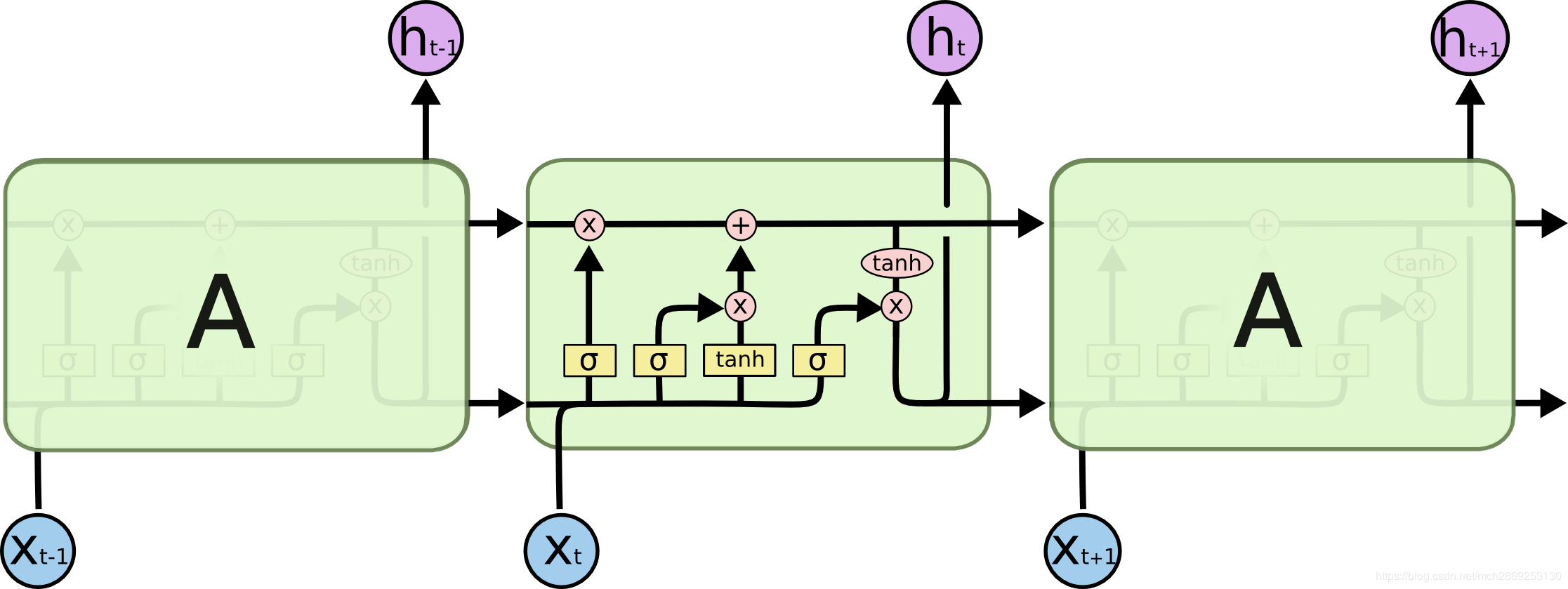
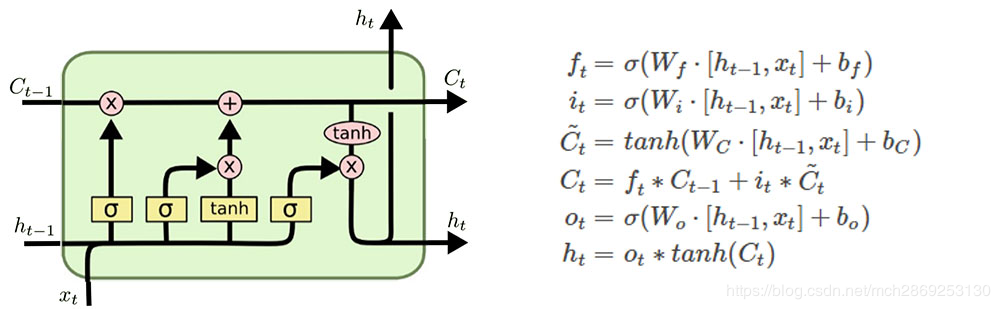
上一个cell的输出\(h_{t-1}\)和state\(C_{t-1}\)贯穿当前cell的所有门,作为他们的输入
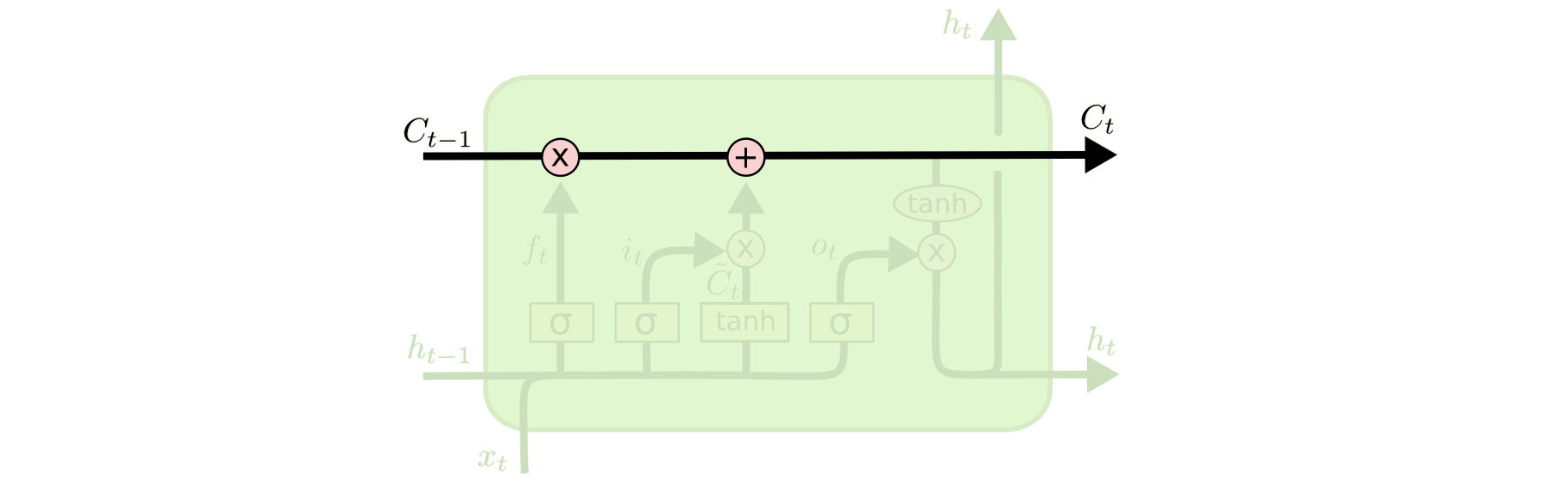
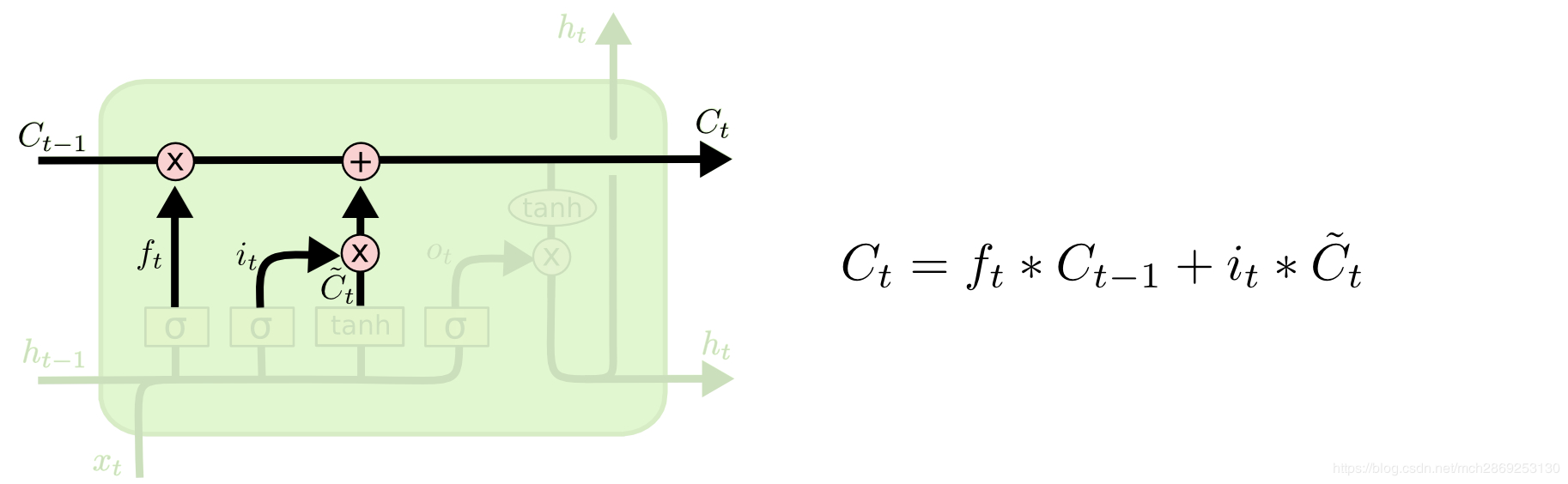
cell state 状态
这一条贯通所有cell的线,或者说是状态传送带就是多出来的state,也是lstm能catch产期依赖的原因之一,线上的state如何更新将有cell里面的几个gate共同决定
forget gate遗忘门
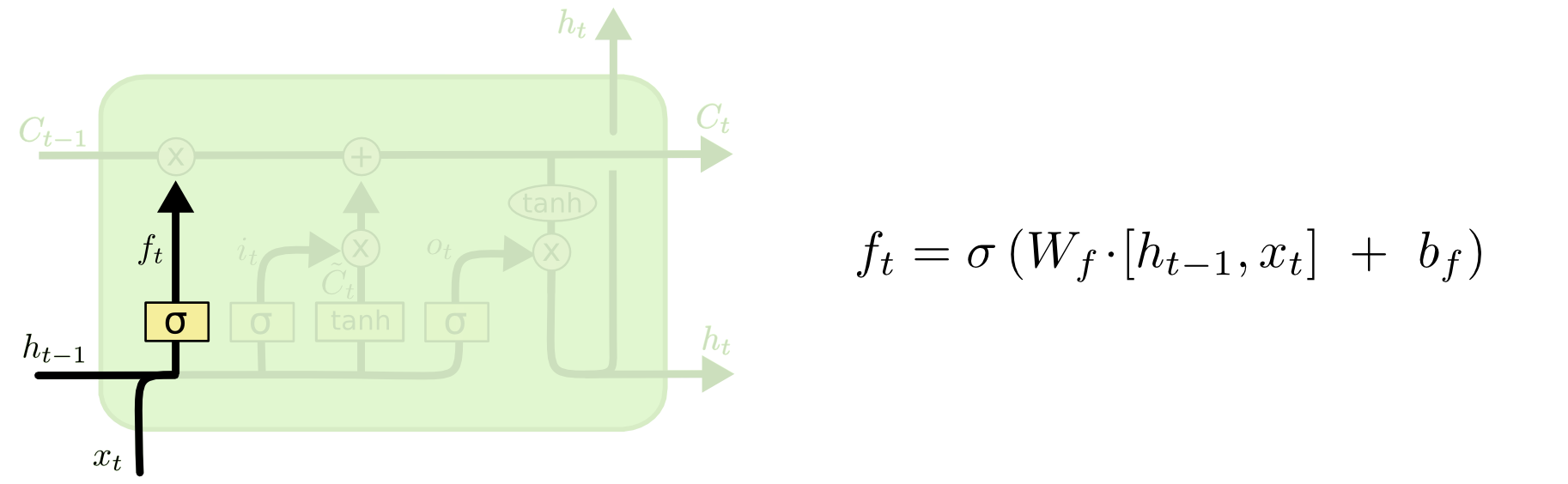
forget gate 的输入包含: 当前时间步的输入向量,上一个时间步中 ouput gate 的输出向量。通过一次 把这两个向量拼接起来,丢到sigmoid 变换映射到[0,1], \(f_t\),其将会与上一个cell的 state 进行逐元素相乘。也就是:\(f_t\odot C_{t-1}\) 哈达马积,受sigmoid激活的影响,乘上上一个元素的状态将表示这次有多少状态得到保留,又有多少将被舍弃
input gate 输入门
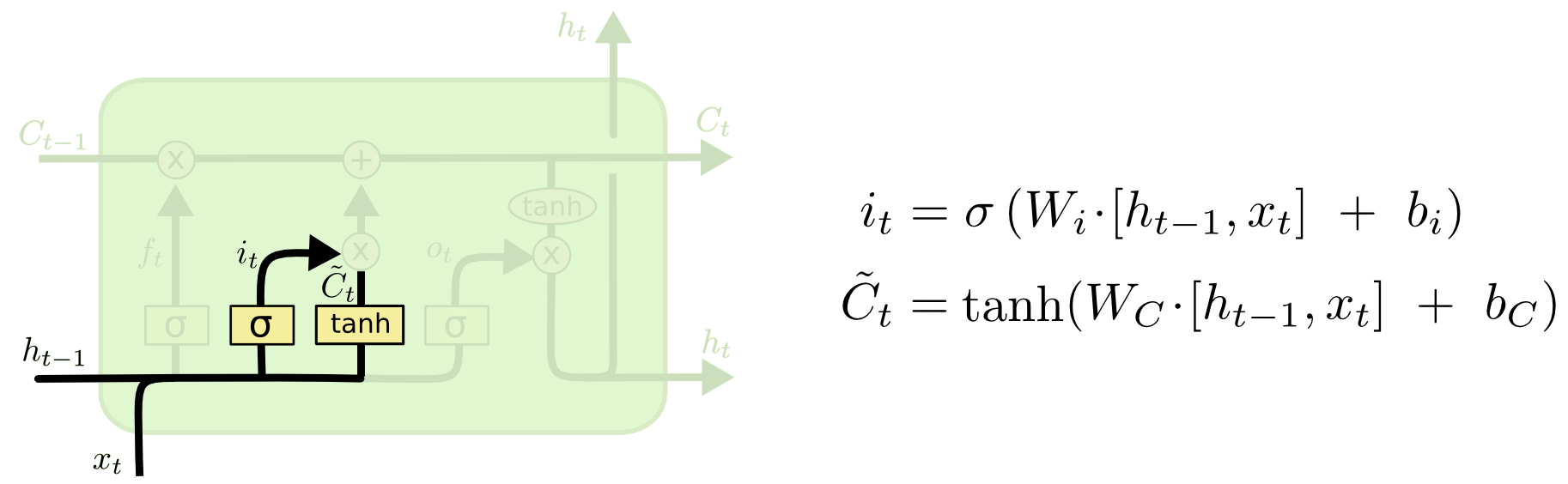
这个步骤中 LSTM 做的是把新的信息加入 临时的cell state 中(\(\tilde C_{t}\)),这项工作包含两部分: input gate layer 和 tanh layer. Input gate 层将决定 \(\tilde C_{t}\) 中的哪些值需要被更新,而tanh 层负责生成一组候选值 \(\tilde C_{t}\) 。最后再与 上一个cell state 相加。input gate 的输出向量也是只有 0 和 1,逐元素相乘后只有为 1 的那些状态量会被更新,所以 \(i_t\)起到的其实是一个
mask的作用。cell state更新到此为止,我们可以看到更新策略
output gate 输出门
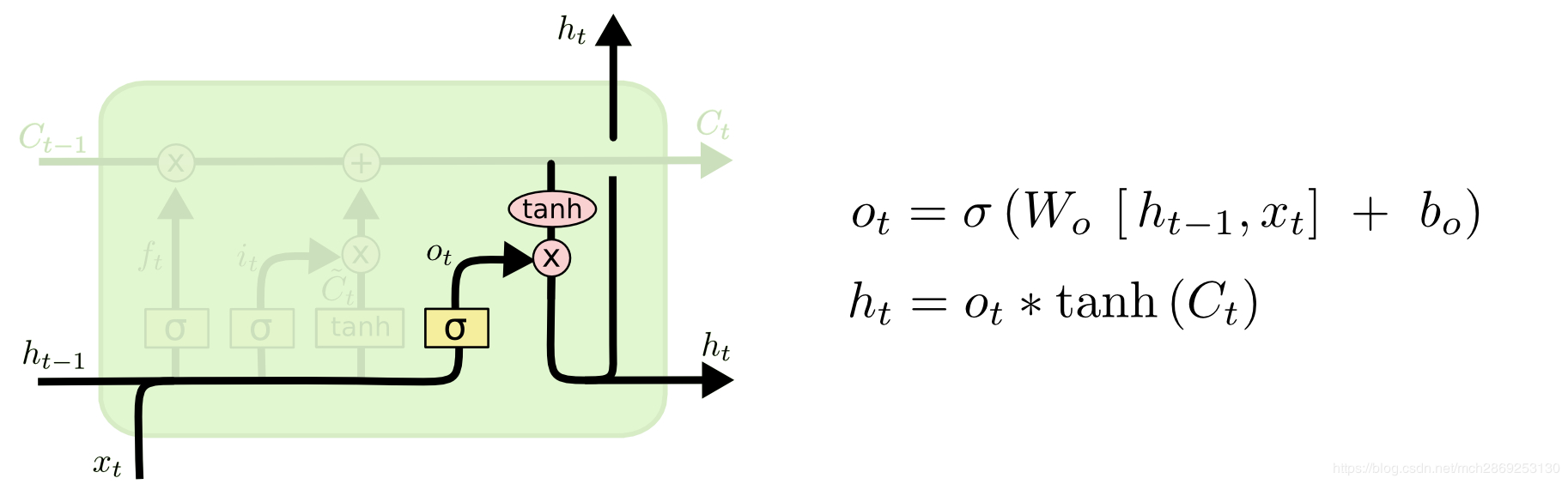
这部分同样由一个 sigmoid layer 和 tanh layer 组成,tanh 层将当前 cell state 压缩到 (−1,1) 区间内 ,然后与sigmoid输出 执行逐元素相乘,产生这个单元的输出变量,sigmoid 层决定了哪些状态信息要被输出。输出变量同时作为下一个单元的 \(h_{t-1}\)加入到循环中。
双向lstm
如果说lstm只顾低头往前看,那么bilstm则会“反思”自己。RNN和LSTM都只能依据之前时刻的时序信息来预测下一时刻的输出,但在有些问题中,当前时刻的输出不仅和之前的状态有关,还可能和未来的状态有关系。比如预测一句话中缺失的单词不仅需要根据前文来判断,还需要考虑它后面的内容,真正做到基于上下文判断。BRNN有两个RNN上下叠加在一起组成的,输出由这两个RNN的状态共同决定。
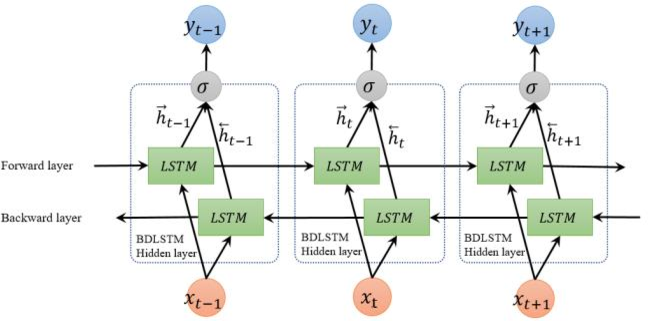
对于每个时刻t,输入会同时提供给两个方向相反的RNN,输出由这两个单向RNN共同决定。

