Batch Normalization 和 DropOut
Batch-Normalization
https://www.cnblogs.com/guoyaohua/p/8724433.html
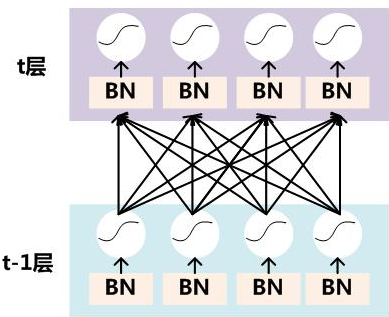

有几点需要注意:
- \(x^{(k)}\)指的是t层的输入. 也就是t-1层的输出x权重的变换
- 训练时,在做BN的时候, \(E(x)^{(k)}\)是mini-batch里面, m个样本所获得的均值,也就是说: \(E\)不是这一层, 连向这个神经元的权重的均值, 而是连向这个神经元的激活值的均值, 分母是mini-batch里面的样本数量

测试时候如何使用BN
求各层全局评均的均值方差, 作为测试时候的均值方差
测试时的输入难到不可以求均值方差?
- 测试的时候, 有可能只要一个sample, 那么这时候, 就没法求方差了
Dropout
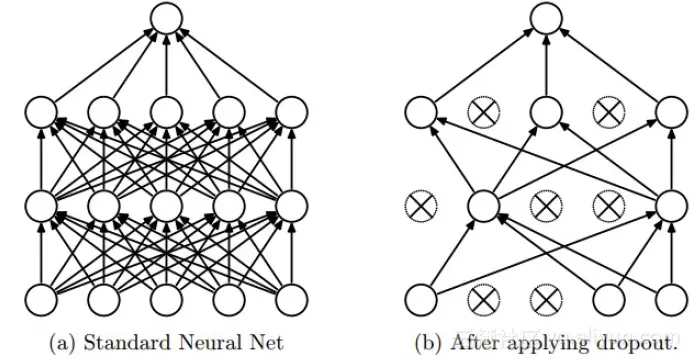
参考博客
https://blog.csdn.net/program_developer/article/details/80737724
个人细节理解
假设有100个神经元, dropout概率p取0.5
- 训练时: 一共50个神经元参与训练
- 测试时, 所有的神经元都参与, 但是, 这样的话, 和没有dropout差异不大, 所以, 在测试阶段, 所有的神经元权重都将乘以概率p
- dropout可以理解为一种集成学习的策略, 因为每次训练, drop掉的神经元不一样, 这就相当于每次都训练一个不同的神经网络
- dropout有点像正则化, 减小权重使得网络对特征的鲁棒性更高
BN和dropout一般不同时使用,如果一定要同时使用,可以将dropout放置于BN后面。
droput之后改变了数据的标准差(令标准差变大,若数据均值非0时,甚至均值也会产生改变)。
如果同时又使用了BN归一化,由于BN在训练时保存了训练集的均值与标准差。dropout影响了所保存的均值与标准差的准确性(不能适应未来预测数据的需要),那么将影响网络的准确性。

