Spark
Spark结构
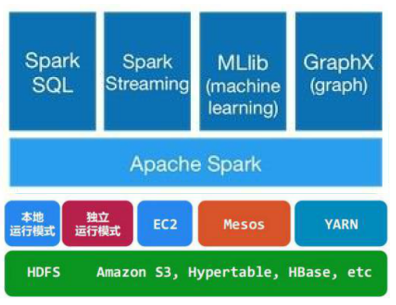
Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的
Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据
MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
Spark架构的组成图如下:
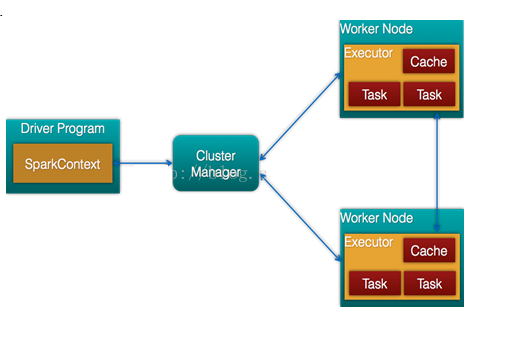
- Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器
- Worker节点:从节点,负责控制计算节点,启动Executor或者Driver。
- Driver: 运行Application 的main()函数
- Executor:执行器,是为某个Application运行在worker node上的一个进程
Spark运行基本流程
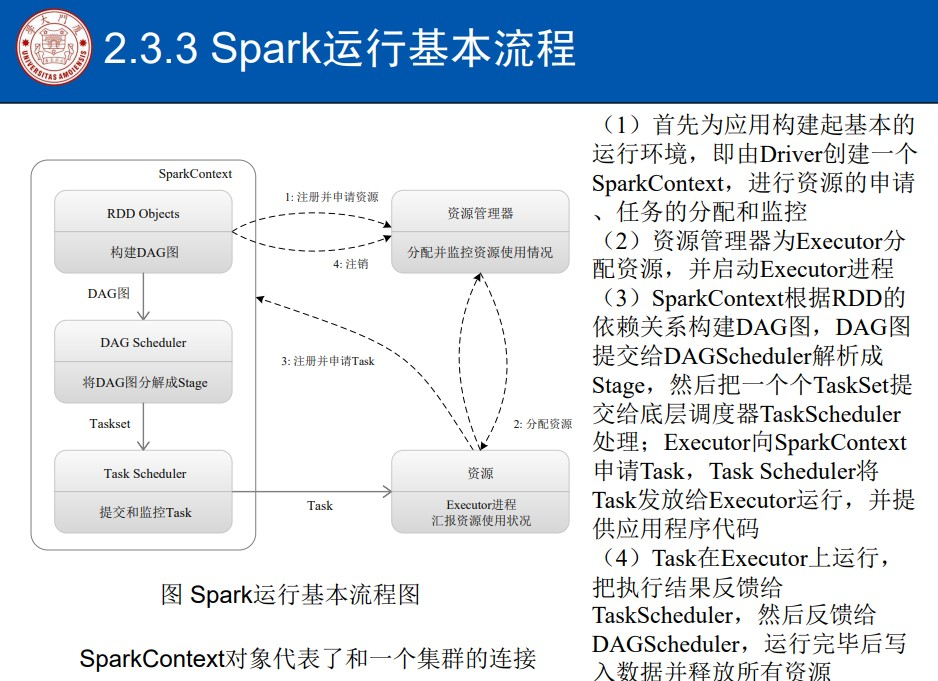
SparkContext(sc) 相当于整个应用的指挥官, 向集群资源管理器申请资源, 然后能就开始派发任务,监控任务
申请好资源之后, 资源管理器就会给每台worker分配好资源
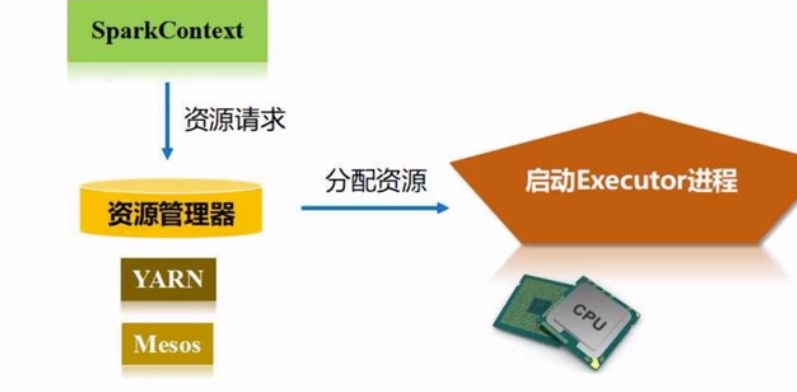
分配好资源之后呢, 就可以开始执行任务了,那任务是这样来的:
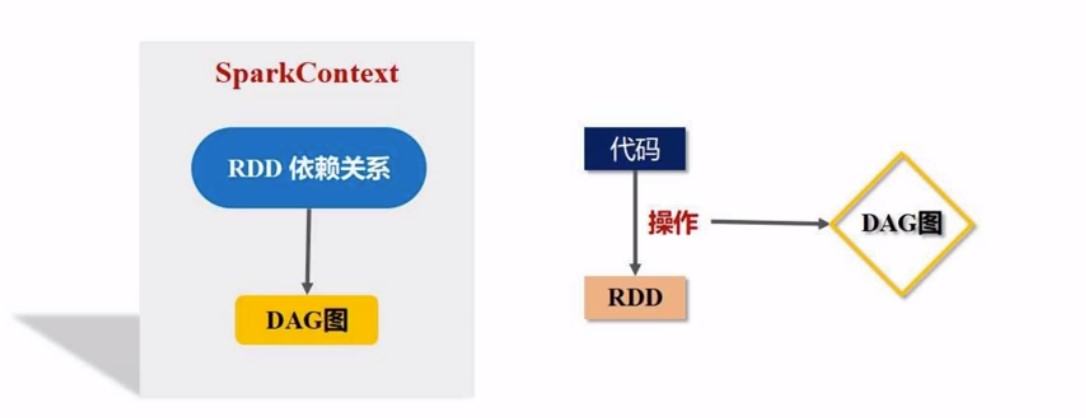
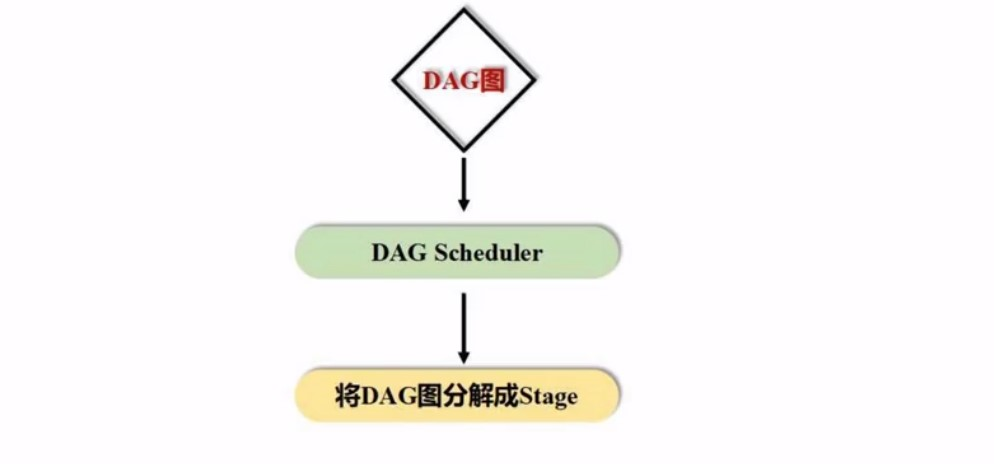
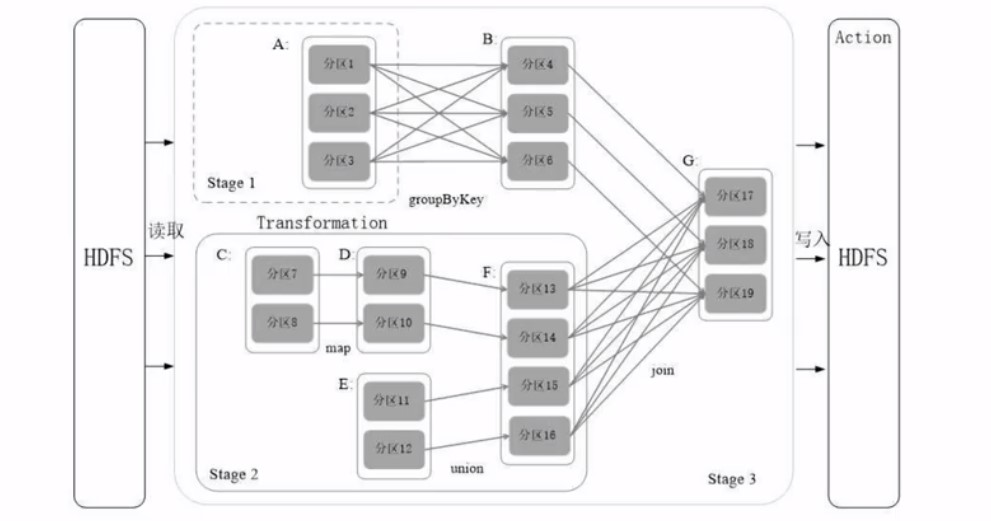
SC会根据你提交的代码去生成DAG, 我们写了代码, 代码就是对RDD的多次操作,代码经过解析之后会生成DAG,然后交给一个叫DAG schedule 的东西, 负责把DAG分解成多个stage
然后有了多个stage, 每个stage的情况是多个任务的集合:
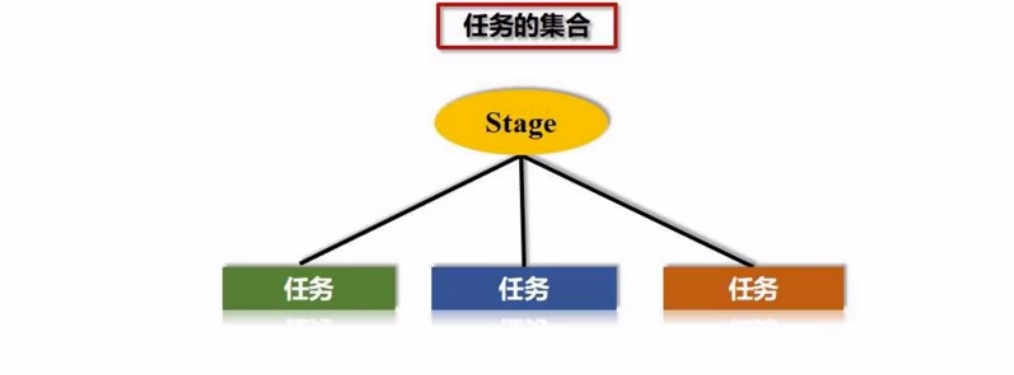
这些任务丢给那台worker处理呢?
这里就涉及到任务的分发, 每个excuter上不是有很多的线程吗? 这些线程就会和一个叫Task scheduler的组件说: 请你把任务分配给我
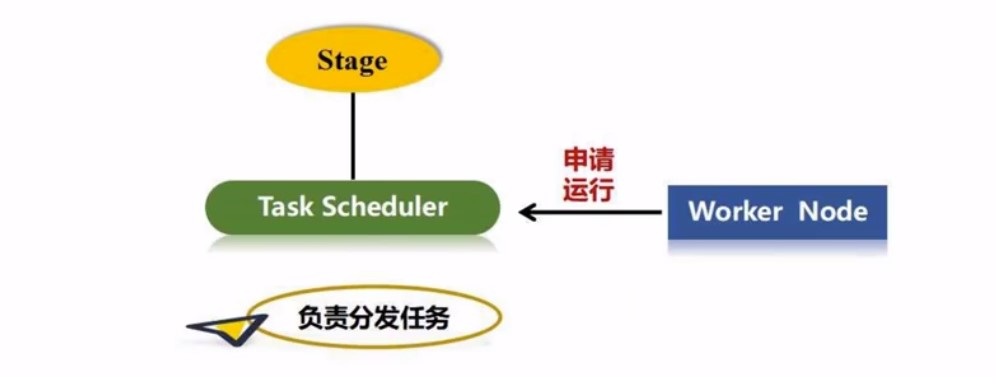
分发有一个基本原则: 计算向数据靠拢, 任务尽量分发给有对应数据的机器,数据在哪, 计算就在那, 实现数据䣌本地化处理, 减小移动数据的开销,
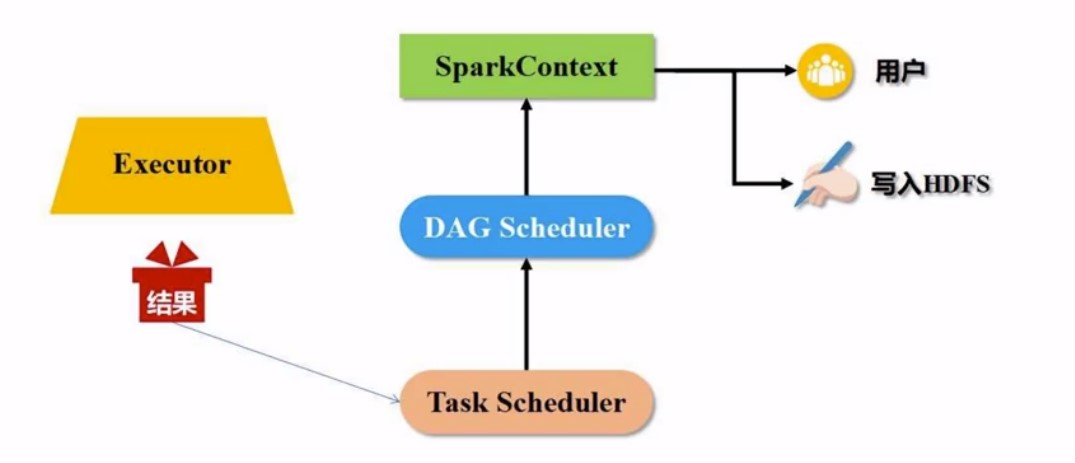
最后, 得有始有终啊: 执行完任务以后, worker把结果反馈给task schdule, task schedule再反馈给DAG schedule, 最后再去写入数据, 释放资源
RDD/DAG/EXCUTER
RDD
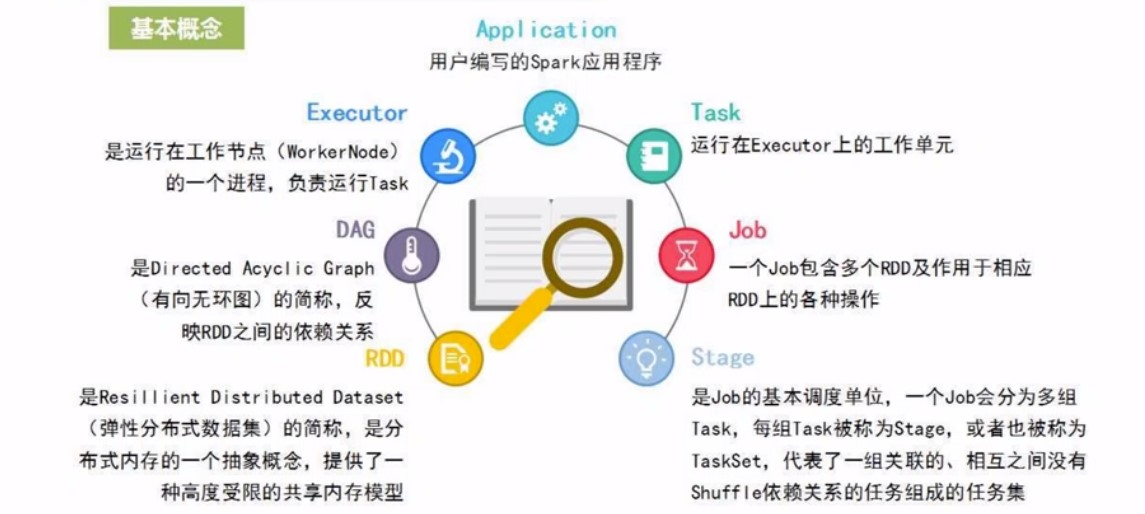
RDD, 弹性分布式数据集,是spark数据的抽象: 当数据很多的时候, 存到多台机器中去, 内存ok的话, 就存在一台上就好, 数据被分区,到多台机器
弹性体现在: 1. 数据可大可小 2. 数据可分区, 分区可修改
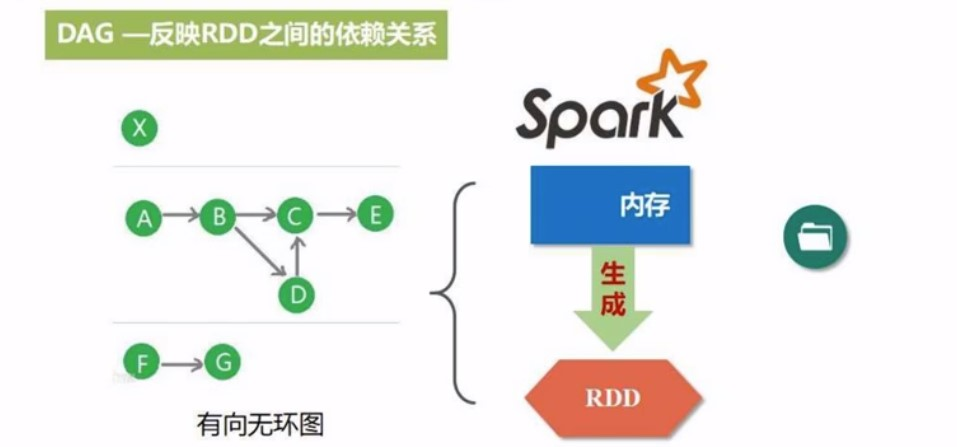
DAG
Saprk里面. 我们是对RDD进行操作, DAG则是这些RDD之间的依赖关系,. 编程的时候, 就是对RDD进行一次又一次的转换操作,或者动作类型操作,这些不同的操作之间, 会练成一张图, 就是DAG
Excuter
具体运行在worker上的进程, 具体负责执行相关任务, 一个excuter会产生多个线程
Task
运行在excuter上的各种工作单元
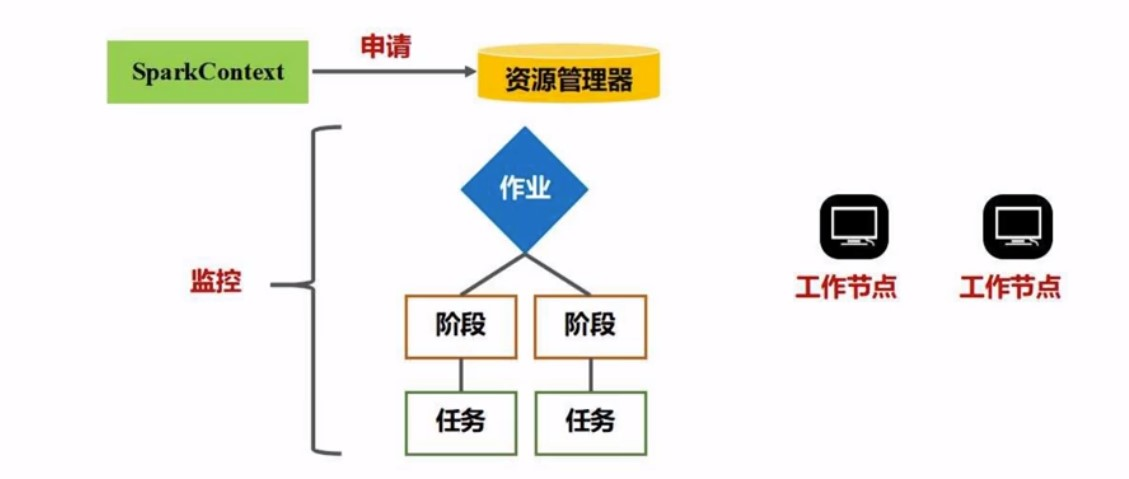
Job(作业)
其实就是对RDD的各种操作,spatk以Job的方式,完成整个任务(task)
Stage
作业的基本调度单位, 我们提交一个Spark应用,会被分为一个或者多个作业, 每一个作业, 又会被分成多组任务,每一组任务的集合, 就叫一个阶段
这些名词之间的关系:应用>作业>阶段>任务
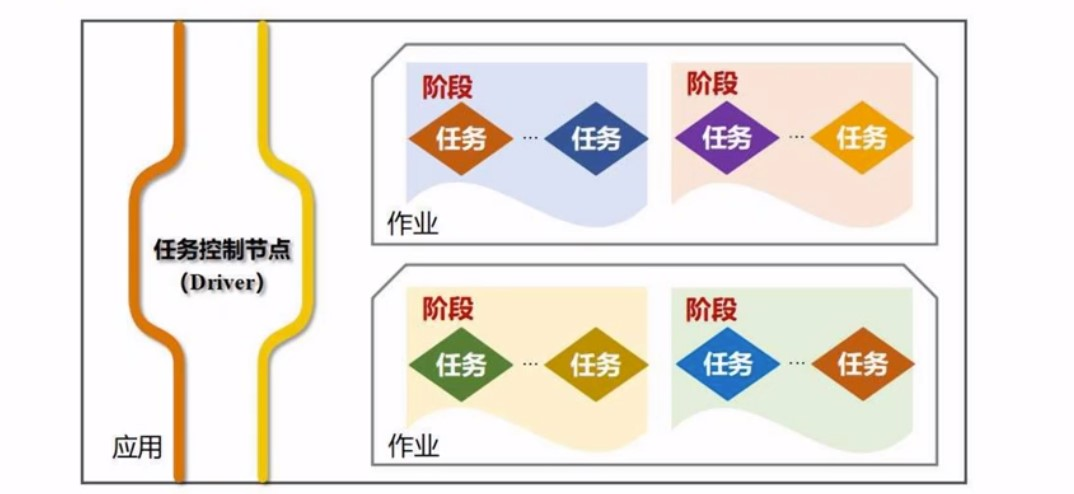
为什么要有多个阶段? 阶段设计宽窄依赖
RDD运行原理
Why RDD
hadoop里面的mr计算, 迭代开销太大,特别是中间结果的IO开销
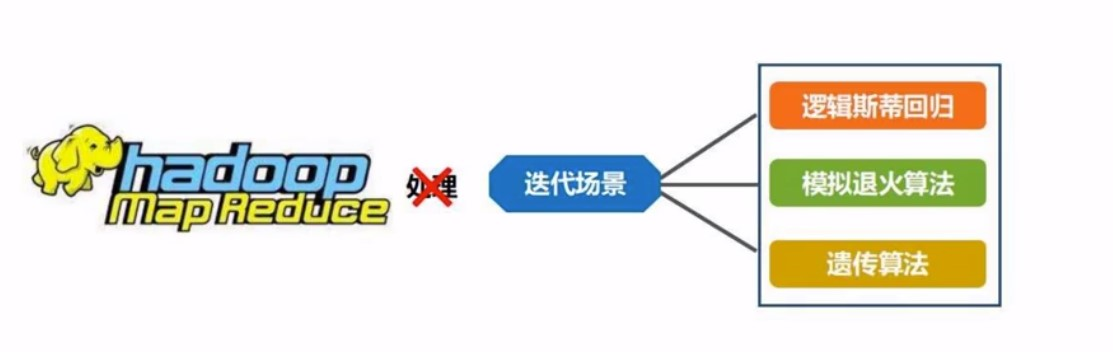

也就是说, RDD是只读的,只有在你从一个RDD转换成另一个RDD的时候, 才是可写的, 比如: 对这个数据集, 你多增加一个特征, 或者对其中的一些特征, 做一些变换. 当我们从HDFS上,或者本地读取到一个数据集之后, 就是RDD了, 不能再改了, 除非转化成一个新的RDD之后, 这个新的RDD, 又是只读了
RDD的两种操作
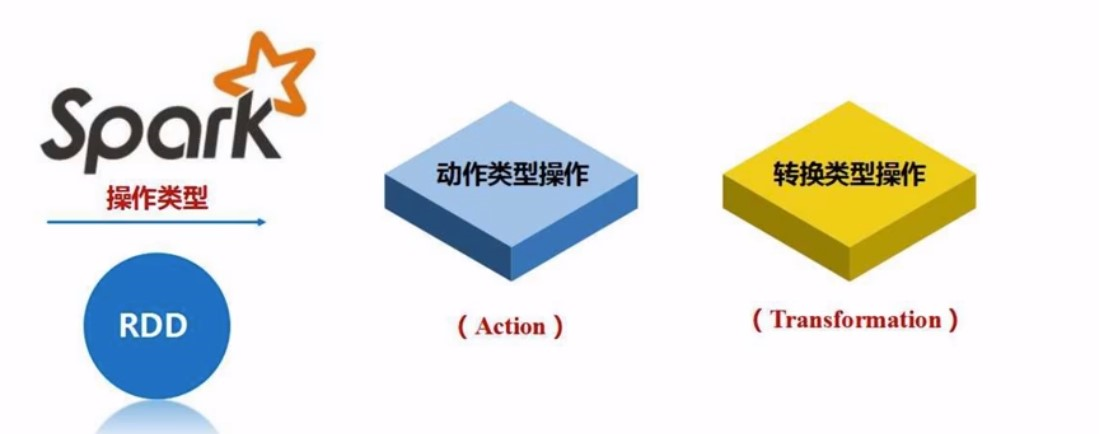
这两种操作都是粗粒度的操作, 也就是说是对整个RDD的, 而不像SQL里面, 可以针对单条数据操作. 这样也有缺点, 细粒度更新的操作不适合spark
Action: 得到结果
Transformation: 转换,RDD, 不能得到结果
RDD的执行过程
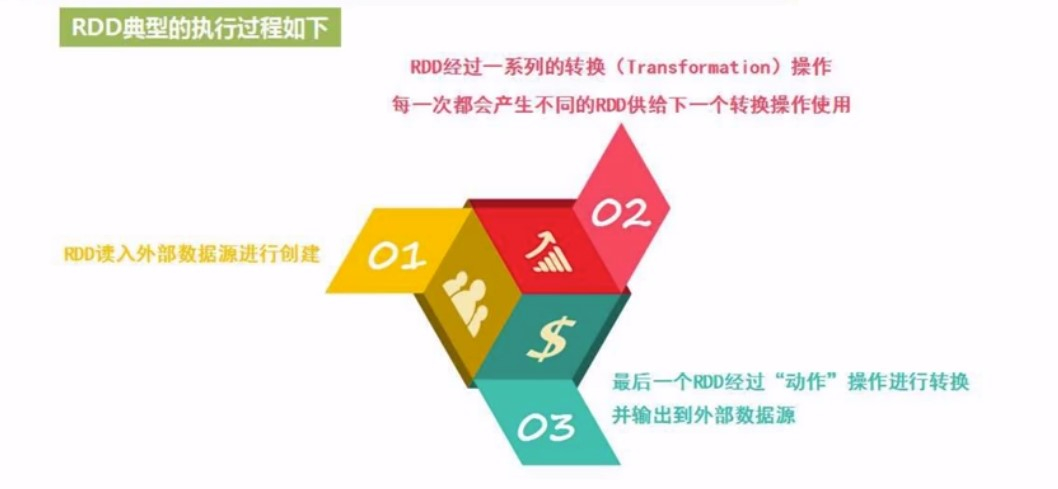
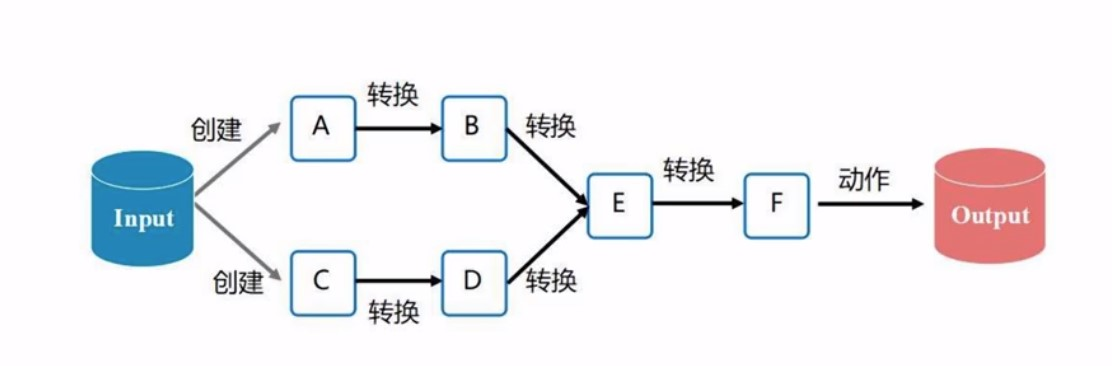
经过一系列转化后, 最终由动作操作获取结果
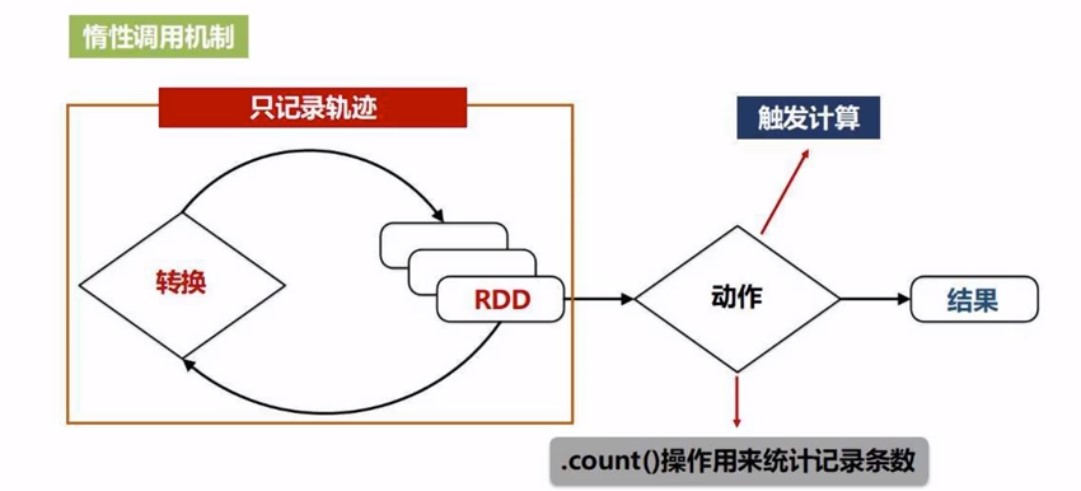
RDD的惰性机制
也就是说, 我们前面对RDD进行的一次又一次的操作, 并不会立马发生,只是记录了转化意图, 相当于只是记录了我要做这件事情, 并不会发生计算, 只有当遇到了动作类型操作的时候, 才会发生从头到尾的计算(从最初的读取数据开始)
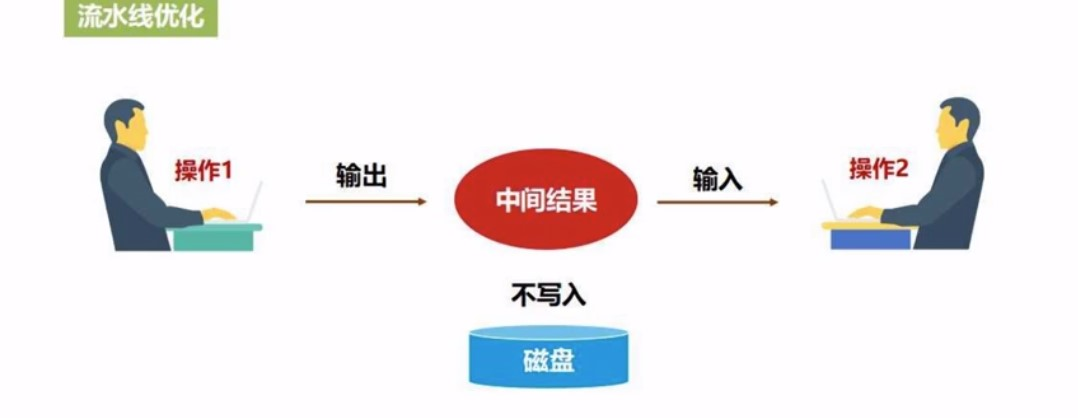
RDD 管道化
一个操作的输出, 直接扔给下一个操作作为输入, 不用经过磁盘
宽窄依赖
1. 为什么分多个stage,以什么依据分阶段?
1.1 首先我们区分宽窄依赖的依据
如果有shuffe操作, 就是宽依赖, 否则就是窄依赖. 宽窄依赖是划分阶段的依据
1.2 什么是shuffle
以mapreduce举例. map的时候, 每个worker可能都有a b c 三个word, 然后reduce的时候, 每个reduce负责的word是一样的,这样就产生了类似于全连接一样的操作,非常的有序, 变得非常的规整.
所以只要发生了shuffle, 就发生了很多来回数据的分发
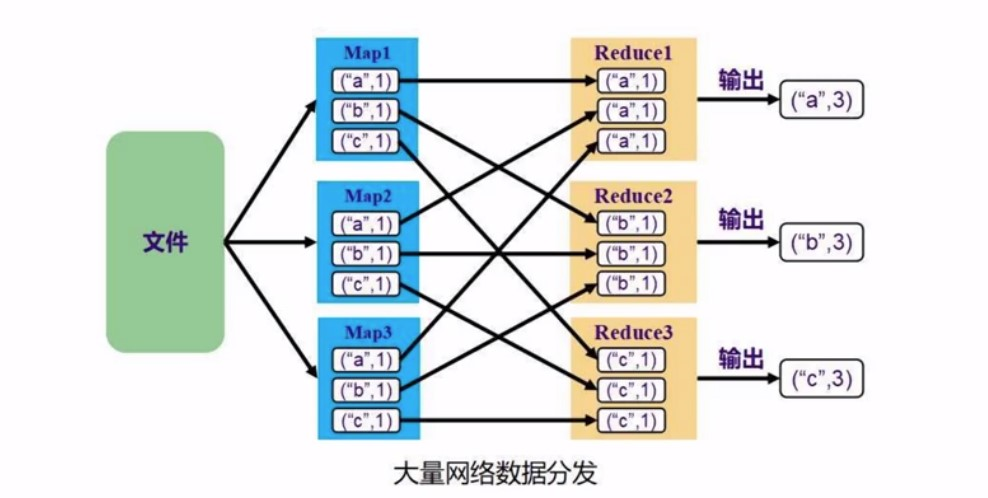
一般我们说发生了shuffle就是宽依赖, 更严格的说就是:
-
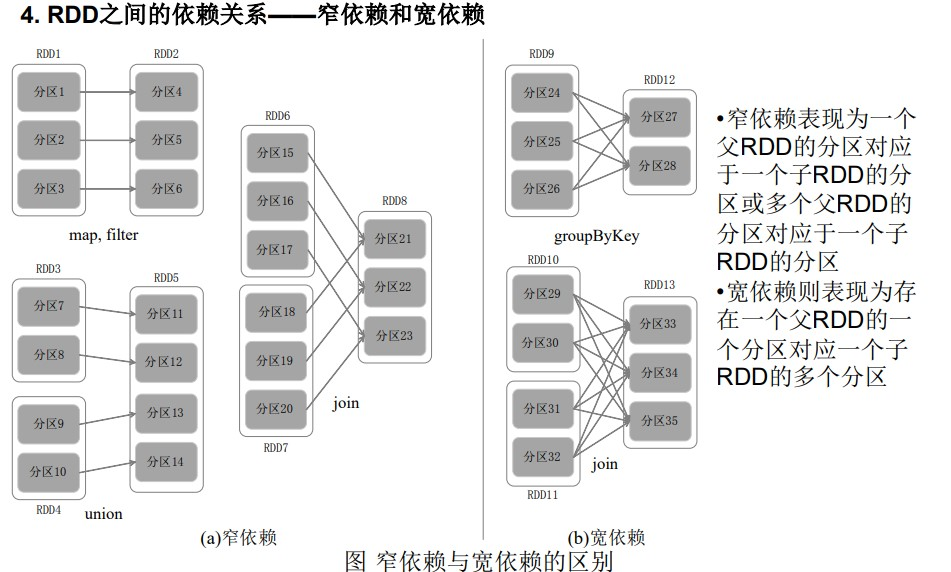
窄依赖: 一个父RDD的分区对应一个子RDD的分区, 或者多个父RDD的分区对应一个子RDD的分区

-
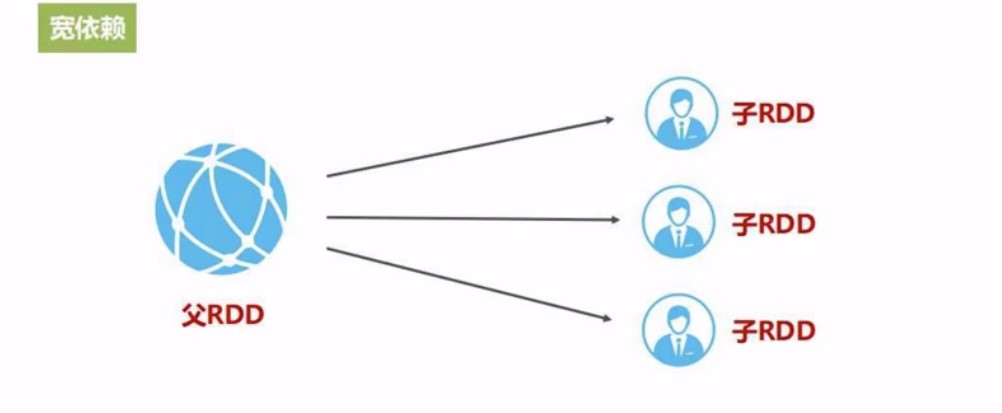
宽依赖: 一个父RDD对应多个子RDD
Stage的划分
如果是宽依赖, 就被划分为多个stage, 如果是窄依赖, 那就一直不变,为什么呢? 如下:
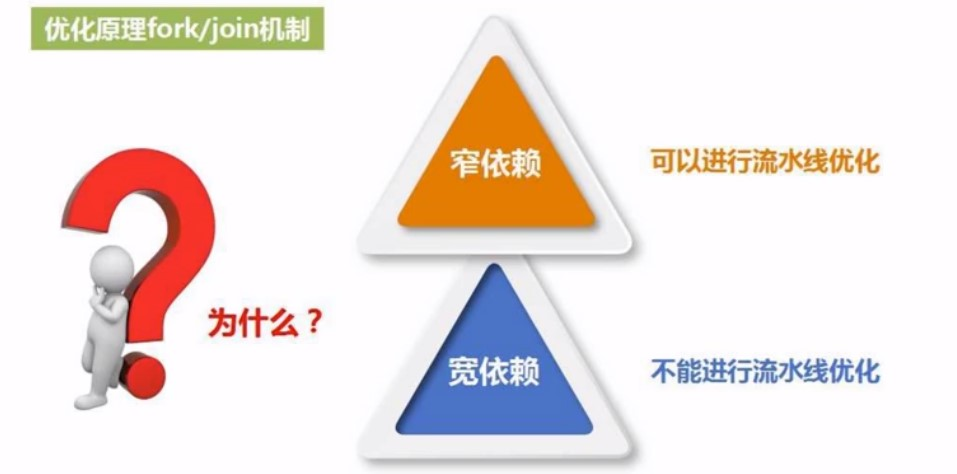
窄依赖有利于流水线作业, 容易优化, 宽依赖不适合
怎么优化?
这里涉及到分布式里面的fork/join机制
fork就是多个分区数据并行执行, join就是结果的汇总. 一个RDD到另一个RDD就是一个fork到join的过程
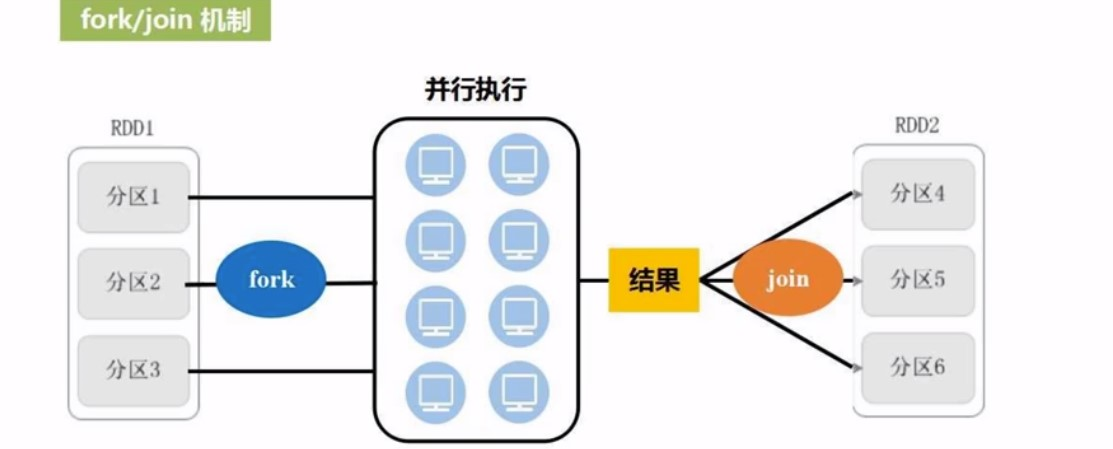
但在实际的qi情况下, 不是这么简单的一个fork-join完成的事情,可能是RDD1->RDD2->RDD3这样的转化过程,一个RDD的转换是一个fork-join, 多个RDD的转换就是多个fork-join. 很多fork-join组合如何去优化?
如何优化?从一个RDD1到RDD3, 要fork-join2次, 但是干嘛中间过程要join呢, 于是直接fork2次, 最后join就好,省掉中间的jioin, 这个join是多余的, 这个join就像中间写磁盘的过程,这样就可以管道化的处理
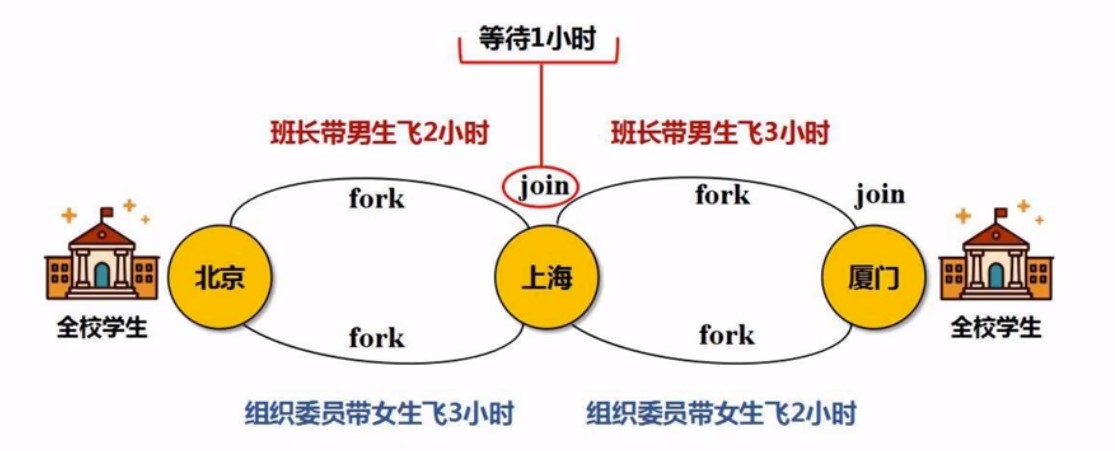
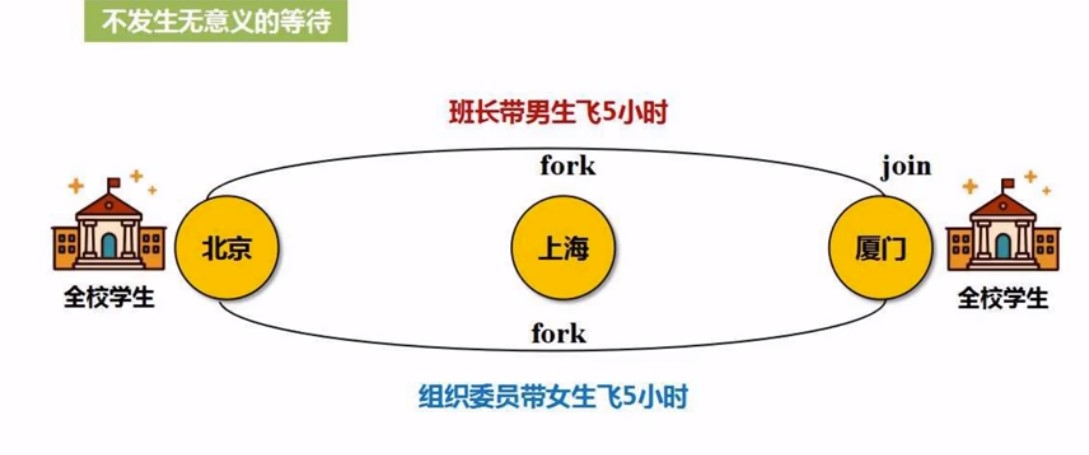
这种可以省去join的过程就叫窄依赖, 而宽依赖怎么优化?
宽依赖涉及到shulle, 只要发生shuffle就会发生磁盘读写,也就是无法流水线优化, 在宽依赖这里, 中间过程的join, 要换一下
就是规则变了, 所以必须要涉及shuffle. 发生了数据的交换, 会涉及到磁盘IO,涉及shuffle,就会发生等待
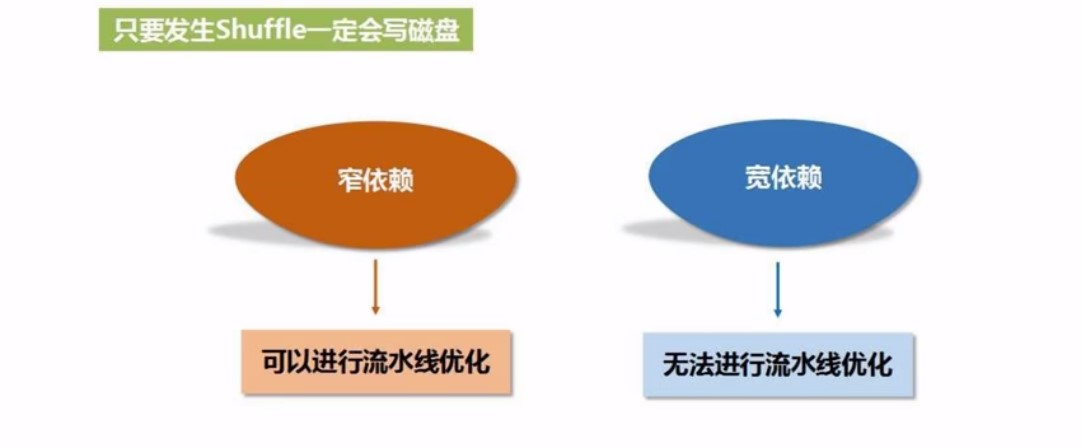
所以这时候, 就没有办法进行管道化的处理, 所以就必须把任务切开, 也就是分阶段(Statage), 也就是遇到shuffle, 就Stage
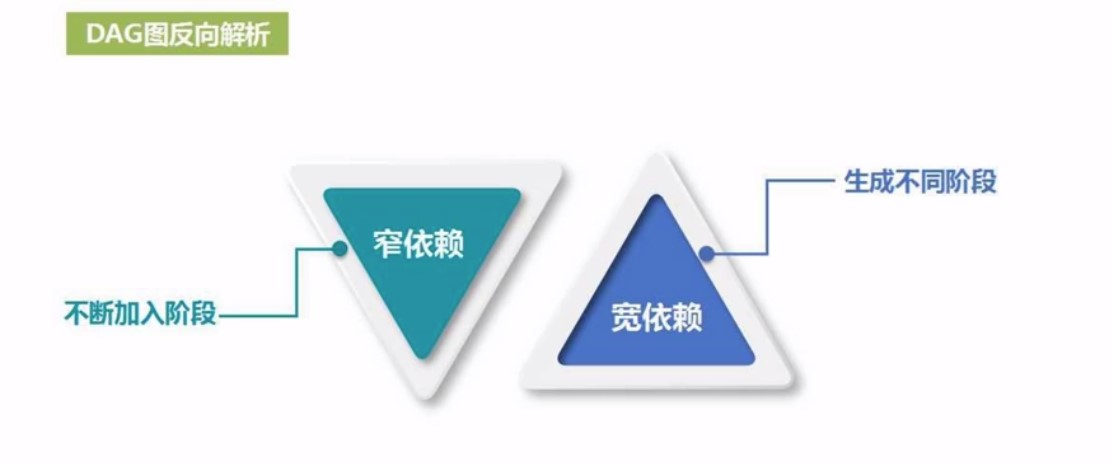
所以在DAG里面, 遇到窄依赖, 可以一路顺着走, 遇到宽依赖, 就得生成不同的阶段

 浙公网安备 33010602011771号
浙公网安备 33010602011771号