20172308 《程序设计与数据结构》第九周学习总结
教材学习内容总结
第 十五 章 图
树的定义是,除根结点之外,树的每个结点都恰好有一个父结点。
而如果违背了这一个前提,即允许树的每个结点连通多个其它结点,不再有父亲、孩子之说,即得到孩子的概念
一、无向图
- 图与树类似,也由结点和这些结点之间的连接构成(这些结点就是图的顶点,而结点之间的连接就是图的边)
- 无向图是一种边为无序结点对的图
- 如果图中的两个顶点之间有一条连通边,则称这两个顶点是邻接的(也互称邻居)
- 连通一个顶点及其自身的边称为自循环或环
- 如果无向图拥有最大数目的连通顶点的边,则认为这个无向图是完全的
- 对有n个顶点的无向图,要使该图为完全的,要求有n(n-1)/2条边(这里假设其中没有边是自循环的)
- 路径是图中的一系列边,每条边连通两个顶点(无向图中的路径是双向的)
- 如果无向图中的任意两个顶点之间都存在一条路径,则认为这个无向图是连通的
- 环路是一种首顶点和末顶点相同且没有重边的路径
- 没有环路的图称为无环的
- 无向树是一种连通的无环无向图,其中一个元素被指定为树根
二、有向图
- 有向图(双向图),它是一种边为有序顶点对的图
- 有向图的路径是图中连通两个顶点的有向边序列(有向图中的路径不是双向的)
- 如果有向图中没有环路,且有一条从A到B的边,则可以把顶点A安排在顶点B之前。这种排列得到的顶点次序称为拓扑序
- 为什么说树也是图?需要满足的条件?
三、网络(加权图)
- 网络:一种每条边都带有权重的或代价的图
- 根据需要,网络可以是无向的,也可以是有向的
- 对于网络,可以用一个三元组来表示每条边(包括起始顶点、终止顶点、权重)
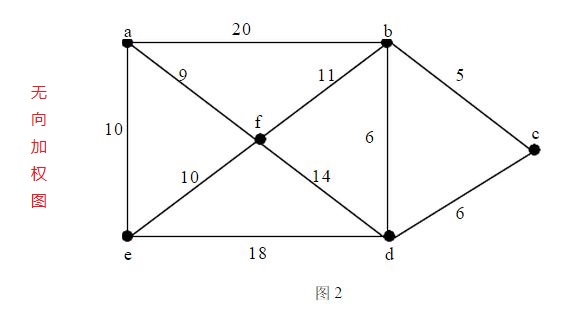
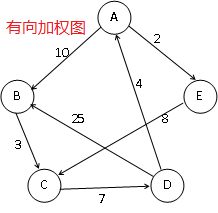
四、常用的图算法
1。 比如:各种遍历算法、寻找最短路径算法、寻找网络中最低代价路径的算法,回答一些简单图相关问题(如图是否连通,两个顶点间最短路径)
2。 遍历:
-
广度优先遍历:类似于树的层次遍历
-
深度优先遍历:类似于树的前序遍历
但是要注意的是:图中不存在根结点,因此图的遍历可以从其中的任一顶点开始 -
广度优先遍历的算法:用一个队列和一个无序列表来构造(使用队列管理遍历,使用无序列表构造出结果)
第一步,起始点进入队列traveralQueue,同时标记该顶点为已访问的( visited)
然后开始循环,该循直持续到 traveralQueue为空时停止,在这个循环中,从 traveralQueue中取出这个首顶点,并将它添加到 resultList的末端
接着,让所有与当前顶点邻接且尚未被标记为 visited的各个顶点依次进入队列 traversalQuet,同时把它们逐个标记为 visited
然后再重复上述循环
对每个已访问的顶点都重复这一过程,直到 traversalQucue为空时结束,这时意味着无法再找到任何新的顶点
现在resultList即以广度优先次序(从给定的起始顶点开始)存放着各个顶点 -
深度优先遍历的算法:其构造使用了与广度优先遍历同样的逻辑,不过在深度优先遍历中用 traversalstack代替了 traversalQueue
算法中还有另一处不同:在顶点尚未添加到 resultList之前,并不想标记该顶点为visited -
图的深度优先遍历与广度优先遍历唯一的不同是:前者使用的是栈而不是队列来管理遍历
3。 测试连通性
- 不论哪个为起始顶点,当且仅当广度优先遍历中的顶点数目等于图中的顶点数目时,该图才是连通的
- 关于连通性的解释
4。 最小生成树
- 生成树是一棵含有图中所有顶点和部分边(但可能不是所有边)的树
- 最小生成树:其边的权重总和小于或等于同一个图中其它任一棵生成树的权重总和
- 最小生成树的算法:
5。 判定最短路径:判定图的“最短”路径有两种情况
-
第一种:是判定起始顶与目标顶点之间的字面意义上的最短路径,也就是两个顶点之间的最小边数。
将广度优先遍历算法转变成寻找最短路径的算法,只需在遍历期间再对每个顶点存另两个信息即可:从起始顶点到本顶点的路径长度,以及路径中作为本顶点前驱的那个顶点
接着修改循环,使得当抵达目标顶点时循环将终止,最短路径的路径长度就是从起始顶点到目标顶点前驱的路径长度再加1;
如果要输出这条最短路径上的顶点,只需沿前驱链回溯即可 -
第二种:寻找加权图的最便宜路径。这里不使用顶点队列(这要求我们必须根据顶点的遭遇次数来探究图),而是用一个 minheap或优先队列来存储顶点,
基于总权重(从起地顶点到本顶点的权重和)来衡量顶点对,这样我们总是能优先沿着最便宜的路径来游历
对每个顶点都必须存储该顶点的标签,(迄今为止)从起始顶点到本顶点的最便宜路径的权重,路径上本顶点的前驱
在 minheap中将存储顶点、对每条已经遇到但尚未游历的候选路径来权衡顶点对,
从 minheap取出顶点的时候,会权衡取自 minheap的顶点对;
如遇到一个顶点的权重小于目前本顶点中已存储的权重,则会更新路径的代价
五、图的实现策略
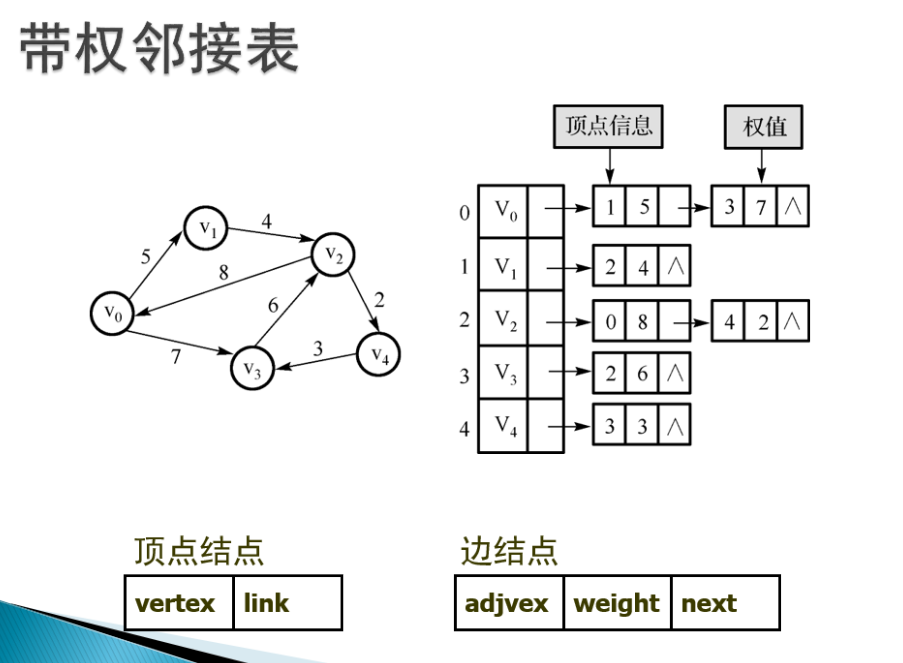
1。邻接列表:
对于图节点来说,每个节点可以有多达n-1条边与其它结点相连,因此用一种类似于链表的动态节点来存储每个节点带有的边,这种链表称为邻接列表
2.。邻接矩阵:
-
每个单元都表示了图中两个顶点交接情况的二维数组(这些交接情况由一个表明两个顶点是否连通的布尔值表示)
-
无向图的矩阵是对称的,所以对于无向图来说,没必要表示整个矩阵,只需给出矩阵对角线的一侧即可
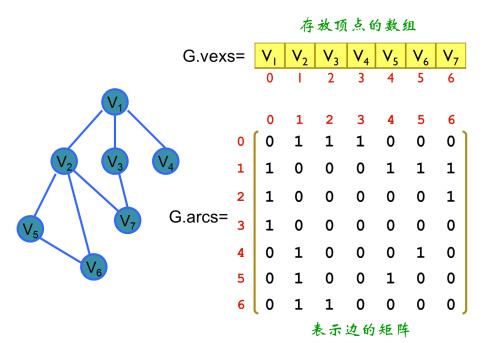
-
对于有向图来说,所有边都是定向的,故而矩阵不对称
教材学习中的问题和解决过程
问题1:什么是“拓扑序”?在哪里应用?
问题1解析:
百度的解释:
拓扑序:在图中从顶点A到顶点B有一条有向路径,则顶点A一定排在顶点B之前。满足这样的条件的顶点序列称为一个拓扑序。
what ???
这就是拓扑序的定义?(手动笑哭)
这么高大上的名字,就是这个意思?A到B有多条路径,每一个路径,A都是起点,B是终点(自己瞎造的理解。。。)
那么这么 “ 简单 ” 的定义有什么用吗?还专门定义了一个名词?
那就是——拓扑排序:获得一个拓扑序列的过程
说实话,我也没觉得这个排序有多么厉害。。。
但是,看了相关参考,才知道专门定义一个这样的名词是很有必要的
举个栗子:
比如大学的课程安排:
例如:
如果你想学习离散数学,前提你必须要预修高等数学这门课。
如果你想学习数据结构这门课,那么你要先学了程序设计这门课,等等等等
所以大学都会根据课程之间的联系来安排学生学习课程的先后次序
所以这个先后顺序,就用到了有向图来表示:
比如下面的这张有向图:
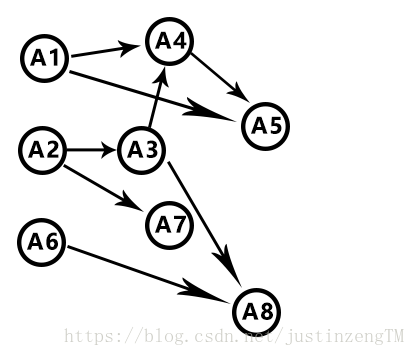
图中的每一个顶点对应每一门课,如果两门课之间是有预修关系的,即如果前一门课是后一门课的预修课程,那么表示这两门课的两个顶点间就有一条有向边
这样的图符合上面所说的拓扑序,即两个顶点之间的边表示的是两个之间的前后关系
选择不同的课程都会按照一定的路径从A开始到B结束,这样多个课程混杂也就形成了如上的有向图
问题2:为什么深度优先遍历在顶点尚未添加到 resultList之前,并不想标记该顶点为visited?
问题2解析:
要明白这个问题,得先知道深度优先遍历是如何遍历的
课本说它与广度优先遍历的逻辑一致
百度的解释为:从图的某个顶点v出发,访问此顶点,然后从v的未被访问过的邻接点出发深度优先遍历图,直至图中的所有和v有路径相通的顶点都被访问到(对于连通图来讲)
广度优先遍历中,顶点进入队列然后标记为已访问,然后开始循环,该循直持续到队列为空时停止,在这个循环中,从队列中取出这个首顶点,并将它添加到 resultList的末端
而深度优先遍历不同的就在这里:在顶点尚未添加到 resultList之前,并不想标记该顶点为visited
这有什么区别吗?
我觉得区别可能在于,深度遍历是用栈来实现的,不同于队列实现的广度优先遍历,
队列可以按照先进先出的规则,将邻接的节点按照一定顺序直接设定为已访问存进去,取出来的时候即按照存进去的顺序取出来
而栈是后进先出的,所以在添加进栈的时候,不把他们标记为已访问,而当将他们取出来,放进resultList里的时候才将他们标记为已访问,
这样可以保证一条路走到黑?
结合百度的资料,总结一下二者的区别:
- 1) 二叉树的深度优先遍历的非递归的通用做法是采用栈,广度优先遍历的非递归的通用做法是采用队列。
- 2) 深度优先遍历:对每一个可能的分支路径深入到不能再深入为止,而且每个结点只能访问一次。
广度优先遍历:又叫层次遍历,从上往下对每一层依次访问,在每一层中,从左往右(也可以从右往左)访问结点,访问完一层就进入下一层,直到没有结点可以访问为止。 - 3)深度优先搜素算法:不全部保留结点,占用空间少;有回溯操作(即有入栈、出栈操作),运行速度慢。
广度优先搜索算法:保留全部结点,占用空间大; 无回溯操作(即无入栈、出栈操作),运行速度快。 - 通常 深度优先搜索法不全部保留结点,扩展完的结点从数据库中弹出删去,这样,一般在数据库中存储的结点数就是深度值,因此它占用空间较少。
所以,当搜索树的结点较多,用其它方法易产生内存溢出时,深度优先搜索不失为一种有效的求解方法。
广度优先搜索算法,一般需存储产生的所有结点,占用的存储空间要比深度优先搜索大得多,因此,程序设计中,必须考虑溢出和节省内存空间的问题。
但广度优先搜索法一般无回溯操作,即入栈和出栈的操作,所以运行速度比深度优先搜索要快些
【参考资料】
图的深度优先遍历和广度优先遍历理解
总结深度优先与广度优先的区别
十二、图的遍历--(2)深度优先搜索算法
图的深度优先遍历
代码运行中的问题及解决过程
问题1:PP15.1,利用邻接列表实现无向图,如何实现?
问题1解决过程:
对比着课本上给出的邻接矩阵的实现代码、其它网上博客,并参考了侯泽洋同学的代码实现了邻接列表的代码实现,并记录下了如下分析:
1。 邻接矩阵是通过一个二维数组实现了对一个点与其它点是否连通的记录
而如果用邻接列表的话,则不需要用二维数组记录连接情况:直接将与某点邻接的点链在此点的后面即可
如图:

将节点存在列表当中,在每个节点后面链上其它与其邻接的节点(形成链表)
对比代码(上方为邻接矩阵,下方为邻接列表):
protected int numVertices; // 当前顶点个数
protected boolean[][] adjMatrix; // 邻接矩阵
protected T[] vertices; // 顶点的值
protected int modCount;// 修改标记数
/* ****************************************************************************** */
protected int numVertices; // 当前顶点个数
protected List<List<Integer>> adjMatrix; // 邻接的节点链成的链表
protected List<T> vertices; //存放节点的列表
protected int modCount;
2。 添加节点addvertices操作
- 邻接矩阵需要将添加的节点与其它节点之间设置为false存储在二维数组里,在添加节点前还得判断数组是否满以及执行扩展数组操作
- 邻接列表不需要上述操作,无序判断数组是否满,直接添加即可,但是要记录存储添加节点的索引值
对比代码(上方为邻接矩阵,下方为邻接列表):
public void addVertex(T vertex) {
// 如果顶点满了
if ((numVertices + 1) == adjMatrix.length)
expandCapacity();
vertices[numVertices] = vertex;// 添加结点
// 添加的这个顶点和每一个顶点的连边默认的设置
for (int i = 0; i < numVertices; i++) {
adjMatrix[numVertices][i] = false;
adjMatrix[i][numVertices] = false;
}
numVertices++;
modCount++;
}
/* ******************************************************************************** */
public void addVertex(T vertex) {
vertices.add(vertex);//直接添加到列表中
List list = new ArrayList();
list.add(numVertices);
adjMatrix.add(list);//存储添加节点的索引值
numVertices++;
modCount++;
}
3。 删除节点removeVertex操作
-
邻接矩阵的节点删除操作,是直接通过覆盖完成的:
首先先判断删除的节点索引值是否存在
然后先将节点所在的二维数组中的值行列用下一行、右一列依次向上,向左进行覆盖
最后将节点数组中的要删除的节点处的下一位依次向上移,即完成删除操作
第二步是相当于完成了删除边的操作 -
邻接列表不用上述操作,直接执行列表具有的删除节点操作,接下来就是删除与节点邻接的边的操作(具体操作在下面删除边的代码中分析)
对比代码(上方为邻接矩阵,下方为邻接列表):
public void removeVertex(int index){
if (indexIsValid(index)) {
for (int a = 0; a < vertices.length; a++) {//相当于完成了删除边的操作
adjMatrix[a][index] = adjMatrix[a][index + 1];
adjMatrix[index][a] = adjMatrix[index + 1][a];
}
for (int i = index; i < numVertices; i++) {//删除节点
vertices[index] = vertices[index + 1];
}
}
}
@Override
public void removeVertex(T vertex) {
if (isEmpty()) {
throw new EmptyCollectionException("Graph");
}
removeVertex(getIndex(vertex));
}
/* ********************************************************************* */
public void removeVertex(T vertex) {
int index = getIndex(vertex);
if (indexIsValid(index))
vertices.remove(index);//删除节点
for (int i = 0;i < adjMatrix.get(index).size()-1;i++)//找到与节点相邻接的所有节点并删除边
{
int x = adjMatrix.get(index).get(i+1);
removeEdge(x,index);
}
adjMatrix.remove(index);//删除记录的节点的索引值
numVertices--;
modCount++;
}
4。 添加边addEdge操作
- 邻接矩阵直接找到索引处的两个节点,将两个索引处对应的二位数组设置成true即可(无向的)
- 邻接列表先找到第一个索引处的节点,然后将下一个索引处的节点添加到其后即可(无向的,索引反过来在执行一遍即可)
这里有两种实现方式,在两个索引处加边,或在两个节点间加边
对比代码(上方为邻接矩阵,下方为邻接列表):
@Override
public void addEdge(T v1, T v2) {
addEdge(getIndex(v1), getIndex(v2));
}
private void addEdge(int index1, int index2) {
if (indexIsValid(index1) && indexIsValid(index2)) {//两个索引都存在
adjMatrix[index1][index2] = true;
adjMatrix[index2][index1] = true;
modCount++;
}
}
/* ********************************************************************* */
public void addEdge(int index1,int index2)
{
if (indexIsValid(index1)&&indexIsValid(index2))
{
(adjMatrix.get(index1)).add(index2);
(adjMatrix.get(index2)).add(index1);
modCount++;
}
}
public void addEdge(T vertex1,T vertex2)
{
int index1 = getIndex(vertex1);
int index2 = getIndex(vertex2);
if (indexIsValid(index1)&&indexIsValid(index2))
{
(adjMatrix.get(index1)).add(index2);
(adjMatrix.get(index2)).add(index1);
modCount++;
}
}
5。 删除边removeEdge操作
- 邻接矩阵:与添加边正好相反,把两个索引处对应的二位数组设置成false即可
- 邻接列表:与添加边正好相反,先找到第一个索引处的节点,但这里需要判断,下一索引处的节点是否与其邻接
如果邻接,则将下一个索引处的节点删除即可(无向的,索引反过来在执行一遍即可)
这里也有两种实现方式,在两个索引处删边,或在两个节点间删边
对比代码(上方为邻接矩阵,下方为邻接列表):
@Override
public void removeEdge(T v1, T v2) {
removeEdge(getIndex(v1), getIndex(v2));
}
private void removeEdge(int index1, int index2) {
if (indexIsValid(index1) && indexIsValid(index2)) {
adjMatrix[index1][index2] = false;
adjMatrix[index2][index1] = false;
modCount++;
}
}
/* ********************************************************************* */
@Override
public void removeEdge(T vertex1, T vertex2) {
int index1 = getIndex(vertex1);
int index2 = getIndex(vertex2);
if (indexIsValid(index1)&&indexIsValid(index2))
{
if (adjMatrix.get(index1).contains(index2))
{
(adjMatrix.get(index1)).remove(adjMatrix.get(index1).indexOf(index2));
(adjMatrix.get(index2)).remove(adjMatrix.get(index2).indexOf(index1));
modCount++;
}
}
}
public void removeEdge(int index1, int index2) {
if (indexIsValid(index1)&&indexIsValid(index2))
{
if ((adjMatrix.get(index1)).contains(index2))
{
(adjMatrix.get(index1)).remove(adjMatrix.get(index1).indexOf(index2));
(adjMatrix.get(index2)).remove(adjMatrix.get(index2).indexOf(index1));
modCount++;
}
}
}
【参考资料】
Java实现无向图邻接表
java:邻接表无向图的链表实现法
邻接表无向图(三)之 Java详解
用邻接表实现无向图
用邻接表表示图【java实现】
无向图的实现(邻接表) 图的遍历
问题2:PP15.7,即实现一个无向网络
问题2解决过程:
无向网络只要在无向图的基础上,在边的相关方法里加上权重参数即可
在书上的邻接矩阵实现的代码基础上,把二维数组的true或false改成相关权重值即可,删除边,只要将其赋成无穷大POSITIVE_INFINITY或其他的什么
运行结果截图:
本周错题
本周无错题
代码托管

结对及互评
-
博客中值得学习的或问题:
- 侯泽洋同学的博客排版工整,界面很美观,并且本周还对博客排版、字体做了调整,很用心
- 问题总结做得很全面:对课本上不懂的代码会做透彻的分析,即便可以直接拿过来用而不用管他的含义
- 对教材中的细小问题都能够关注,并且主动去百度学习
- 代码中值得学习的或问题:
- 对于编程的编写总能找到角度去解决
-
本周结对学习情况
- 20172302
- 结对学习内容
- 第十五 章内容:图
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 4/4 | |
| 第二周 | 560/560 | 1/2 | 6/10 | |
| 第三周 | 415/975 | 1/3 | 6/16 | |
| 第四周 | 1055/2030 | 1/4 | 14/30 | |
| 第五周 | 1051/3083 | 1/5 | 8/38 | |
| 第六周 | 785/3868 | 1/6 | 16/54 | |
| 第七周 | 733/4601 | 1/7 | 20/74 | |
| 第八周 | 2108/6709 | 1/8 | 20/74 | |
| 第九周 | 1425/8134 | 1/9 | 20/94 |
作者:静默虚空
欢迎任何形式的转载,但请务必注明出处。
限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 用 C# 插值字符串处理器写一个 sscanf
· Java 中堆内存和栈内存上的数据分布和特点
· 开发中对象命名的一点思考
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· DeepSeek 解答了困扰我五年的技术问题。时代确实变了!
· 本地部署DeepSeek后,没有好看的交互界面怎么行!
· 趁着过年的时候手搓了一个低代码框架
· 推荐一个DeepSeek 大模型的免费 API 项目!兼容OpenAI接口!