
CUDA版Grabcut的实现
在上次用 CUDA实现导向滤波 后,想着导向滤波能以很小的mask还原高分辨率下的边缘,能不能搞点事情出来,当时正好在研究Darknet框架,然后又看到grabcut算法,用opencv试了下,感觉效果有点意思,后面想了下,这几个可以连在一起,先读取高分辨率的图像,然后用降低分辨率先通过yolov3算出人物框(非常稳定,不跳,几乎不会出现有人而找不到的情况),再用grabcut算出低mask,然后用这个mask结合原图用导向滤波得到高分辨率下清晰边缘的分割图,最后再把CUDA算出的结果直接丢给UE4/Unity3D的对应DX11中。
先放出cuda版grabcut的效果图。

当然opencv本身提供的grabcut是用cpu算的,416*416差不多有个几桢左右,肯定不满足要求,所以在这个前提下,用Cuda来实现整个grabcut整个流程。
因要集成到UE4/Untiy3D对应软件中,在window本台下,我们首先需要如下。
1 拿到darknet源码,C风格代码,说实话,没想过能看到这种短小精湛的深度学习模型框架,带cuda与cudnn,直接在VS下建一个动态链接库,把相应代码放进来,不多,改动几个Linux下的函数,包含编译符GPU与CUDNN,然后修改darknet.h这个函数,dllexport这个文件下函数,后期还可以改下,这个文件下的编译符移到别的位置,pthread头文件的引用这些,以及可以直接传入GPU数据这几点。opencv4虽然已经有yolo3的实现,但是我们要GPU的,后续的操作几乎全在GPU上。
2 我们主要是参照opencv里的grabcut实现,为了更好的参数一些数据,我们最好编译自己的opencv版本,我是用的opencv-4.0.0-alpha,比较老的一个版本,需要带opencv_contrib,包含opencv_cuda相关的模块,主要是后期我们实现cuda 版grabcut如果不好确认我们是否正常实现就可以调试进去看数据值,看源码,以及用GpuMat/PtrStepSz,这个简单封装真的很适合处理图像数据。
如上二点完成后,我们可以简单分析下grabcut算法主要由那种算法构成,如何完成一个流程,一次大迭代主要如下,主要是先定框,框内为可能前景区,框外为背景区,二个区域分别为Kmeans分类,然后二个分类的数据分别GMM建立模型,最后用GMM算出最大流算法需要的每点的source/sink,建立graph,用GPU友好的maxflow算法push-relabel得到最小切,也就是mask,然后把mask给GMM重新建立模型然后重复这个过程。
如上所说,我们主要实现三种算法,分别是kmeans,gmm,push-relabel。下面如无别的说明,本机给的是在1070下416*416分辨率下的时间。
首先讲下kmeans的优化,kmeans的实现比较简单,就是一个不断重新分配中心点至到稳定的过程,其中有个过程是把数据根据前后景分别归类(我们假设聚合为5块),最直观最简单的方法就是用原子操作。


__global__ void updateClusterAtomic(PtrStepSz<uchar4> source, PtrStepSz<uchar> clusterIndex, kmeansI& meansbg, kmeansI& meansfg) { const int idx = blockDim.x * blockIdx.x + threadIdx.x; const int idy = blockDim.y * blockIdx.y + threadIdx.y; if (idx < source.cols && idy < source.rows) { float4 color = rgbauchar42float4(source(idy, idx)); //背景块,使用kcentersbg,否则使用kcentersfg kmeansI& kmeans = (!inRect(idx, idy)) ? meansbg : meansfg; int index = clusterIndex(idy, idx); atomicAdd(&kmeans.kcenters[index].x, color.x); atomicAdd(&kmeans.kcenters[index].y, color.y); atomicAdd(&kmeans.kcenters[index].z, color.z); atomicAdd(&kmeans.kcenters[index].w, color.w); } }
用Nsight看了下时间,花费超过1ms了,我是想到所有线程最后归类时都只操作10块地方,原子操作在这有点把多线程变成有限的几个能同时做事了。
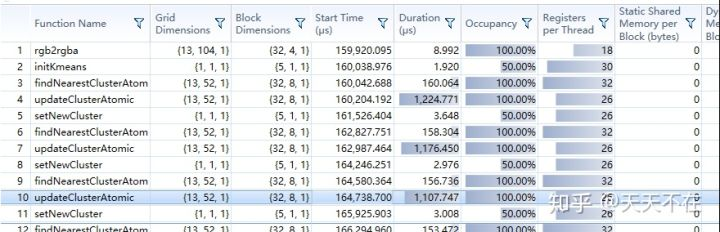
因此需要换种想法,很简单,不用原子操作,用一部分线程如32*8,遍历最个纹理数据,然后在一个线程里32*8个数据再整合,使用这步后,时间降低0.5ms左右,利用的还不是很完全,毕竟一次kmeans稳定需要遍历十几次左右,这个过程就要了5ms后面就不用搞了,在这基础上,结合共享显存,每个点一个线程先用共享显存处理后放入对应grid块大小的显存中,然后数据除32*8的grid块执行上面的操作,这个操作包含后面统计等加起0.12ms,这样十几次迭代也就不到2ms,不过我没想到的是,从cudaMemcpyDeviceToHost一个int32的四字节Nsight给的时间很低0.001ms,但是从上面的简隔来看,应该有0.1ms了,应该还有一些别的花费,所以很多操作,后续的统计计算我就是用GPU里一个核心来算,也不先download给CPU算然后再upload上来,但是这个操作还没想到办法避免,毕竟需要在CPU上判定是否已经稳定后关闭循环。
//把source所有收集到一块gridDim.x*gridDim.y块数据上。 template<int blockx, int blocky> __global__ void updateCluster(PtrStepSz<uchar4> source, PtrStepSz<uchar> clusterIndex, PtrStepSz<uchar> mask, float4* kencter, int* kindexs) { __shared__ float3 centers[blockx*blocky][CUDA_GRABCUT_K2]; __shared__ int indexs[blockx*blocky][CUDA_GRABCUT_K2]; const int idx = blockDim.x * blockIdx.x + threadIdx.x; const int idy = blockDim.y * blockIdx.y + threadIdx.y; const int threadId = threadIdx.x + threadIdx.y * blockDim.x; #pragma unroll CUDA_GRABCUT_K2 for (int i = 0; i < CUDA_GRABCUT_K2; i++) { centers[threadId][i] = make_float3(0.f); indexs[threadId][i] = 0; } __syncthreads(); if (idx < source.cols && idy < source.rows) { //所有值都放入共享centers int index = clusterIndex(idy, idx); bool bFg = checkFg(mask(idy, idx)); int kindex = bFg ? index : (index + CUDA_GRABCUT_K); float4 color = rgbauchar42float4(source(idy, idx)); centers[threadId][kindex] = make_float3(color); indexs[threadId][kindex] = 1; __syncthreads(); //每个线程块进行二分聚合,每次操作都保存到前一半数组里,直到最后保存在线程块里第一个线程上(这块比较费时,0.1ms) for (uint stride = blockDim.x*blockDim.y / 2; stride > 0; stride >>= 1) { //int tid = (threadId&(stride - 1)); if (threadId < stride)//stride 2^n { #pragma unroll CUDA_GRABCUT_K2 for (int i = 0; i < CUDA_GRABCUT_K2; i++) { centers[threadId][i] += centers[threadId + stride][i]; indexs[threadId][i] += indexs[threadId + stride][i]; } } //if (stride > 32) __syncthreads(); } //每块的第一个线程集合,把共享centers存入临时显存块上kencter if (threadIdx.x == 0 && threadIdx.y == 0) { int blockId = blockIdx.x + blockIdx.y * gridDim.x; #pragma unroll CUDA_GRABCUT_K2 for (int i = 0; i < CUDA_GRABCUT_K2; i++) { int id = blockId * 2 * CUDA_GRABCUT_K + i; kencter[id] = make_float4(centers[0][i], 0.f); kindexs[id] = indexs[0][i]; } } } } //block 1*1,threads(暂时选32*4),对如上gridDim.x*gridDim.y的数据用blockx*blocky个线程来处理 template<int blockx, int blocky> __global__ void updateCluster(float4* kencter, int* kindexs, kmeansI& meansbg, kmeansI& meansfg, int& delta, int gridcount) { __shared__ float3 centers[blockx*blocky][CUDA_GRABCUT_K2]; __shared__ int indexs[blockx*blocky][CUDA_GRABCUT_K2]; const int threadId = threadIdx.x + threadIdx.y * blockDim.x; #pragma unroll CUDA_GRABCUT_K2 for (int i = 0; i < CUDA_GRABCUT_K2; i++) { centers[threadId][i] = make_float3(0.f); indexs[threadId][i] = 0; } __syncthreads(); //int gridcount = gridDim.x*gridDim.y; int blockcount = blockDim.x*blockDim.y; int count = gridcount / blockcount + 1; //每块共享变量,每个线程操纵自己对应那块地址,不需要同步,用线程块操作一个大内存 for (int i = 0; i < count; i++) { int id = i*blockcount + threadId; if (id < gridcount) { #pragma unroll CUDA_GRABCUT_K2 for (int j = 0; j < CUDA_GRABCUT_K2; j++) { int iid = id * CUDA_GRABCUT_K2 + j; centers[threadId][j] += make_float3(kencter[iid]); indexs[threadId][j] += kindexs[iid]; } } } __syncthreads(); for (uint stride = blockDim.x*blockDim.y / 2; stride > 0; stride >>= 1) { if (threadId < stride) { #pragma unroll CUDA_GRABCUT_K2 for (int i = 0; i < CUDA_GRABCUT_K2; i++) { centers[threadId][i] += centers[threadId + stride][i]; indexs[threadId][i] += indexs[threadId + stride][i]; } } //if (stride > 32) __syncthreads(); } if (threadIdx.x == 0 && threadIdx.y == 0) { int count = 0; //收集所有信息,并重新更新cluster,记录变更的大小 for (int i = 0; i < CUDA_GRABCUT_K; i++) { meansfg.kcenters[i] = make_float4(centers[0][i], 0.f); if (indexs[0][i] != 0) meansfg.cluster[i] = meansfg.kcenters[i] / indexs[0][i]; count += abs(indexs[0][i] - meansfg.length[i]); meansfg.length[i] = indexs[0][i]; } for (int i = CUDA_GRABCUT_K; i < CUDA_GRABCUT_K2; i++) { meansbg.kcenters[i - CUDA_GRABCUT_K] = make_float4(centers[0][i], 0.f); if (indexs[0][i] != 0) meansbg.cluster[i - CUDA_GRABCUT_K] = meansbg.kcenters[i - CUDA_GRABCUT_K] / indexs[0][i]; count += abs(indexs[0][i] - meansbg.length[i - CUDA_GRABCUT_K]); meansbg.length[i - CUDA_GRABCUT_K] = indexs[0][i]; } delta = count; } } void updateCluster_gpu(PtrStepSz<uchar4> source, PtrStepSz<uchar> clusterIndex, PtrStepSz<uchar> mask, float4* kencter, int* kindexs, kmeansI& meansbg, kmeansI& meansfg, int& delta, cudaStream_t stream = nullptr) { dim3 grid(cv::divUp(source.cols, block.x), cv::divUp(source.rows, block.y)); updateCluster<BLOCK_X, BLOCK_Y> << <grid, block, 0, stream >> > (source, clusterIndex, mask, kencter, kindexs); updateCluster<BLOCK_X, BLOCK_Y> << <1, block, 0, stream >> > (kencter, kindexs, meansbg, meansfg, delta, grid.x*grid.y); } void KmeansCuda::compute(GpuMat source, GpuMat clusterIndex, GpuMat mask, int threshold) { int delta = threshold + 1; initKmeans_gpu(*bg, *fg); while (delta > threshold) { findNearestCluster_gpu(source, clusterIndex, mask, *bg, *fg); updateCluster_gpu(source, clusterIndex, mask, dcenters, dlenght, *bg, *fg, *d_delta); //可以每隔五次调用一次这个 cudaMemcpy(&delta, d_delta, sizeof(int), cudaMemcpyDeviceToHost); } }

这里肯定有点反直觉,十多行代码扩展到百多行,效率还增加了十倍,但是GPU运算就是这样,每步能多利用核心就行,还有,cudaMemcpy花费真的大,这里有个失败的尝试,因为在这基础上,都是用更多的计算核心带来的好处,就想把这个算法再扩展了下,前景与背景二个各分五类,一共十类,故当前准备用block的z为10,当做每块的索引,和我想象不同,这个要的时间在0.4ms左右,时间关系,没有继续测试,后续针对这块再仔细分析比对下。
如下显示的效果图。
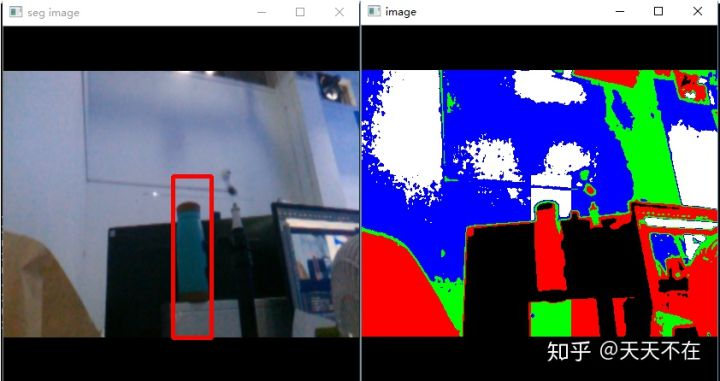
然后就是GMM的实现,这个实现和k-means过程比较相似,代码就不贴了,当时效果完成后,我的主要疑问在如果确认我的实现是对的,但是下面这张图出来后,我就知道应该是对了。GMM对k-means每块求的结果,然后用这结果来得到颜色的分类,这二者效果应该差不多是一样,但是肯定又有点区别(image是k-means的结果,seg image是GMM一次learning然后再分配的结果),当然最后确认还是我比较opencv里GMM里各个分类与我实现GMM的值的比较,一般来说,各个分类的平均值与个数相差不大,各个分类在所有点的比例类似,当然二者的结果不会完全一样,opencv中k-means中用k-means++随机选择五个差异比较大的中心,就算用opencv自己重复算同一张图,每次结果都会有细小区别。

最后是maxflow的实现,这个过程我参照了https://web.iiit.ac.in/~vibhavvinet/Software/ 的实现,要说这份代码稍稍改下还是能运行的,就是数据来源全在一个文件上,包含formsource,tosink,edge的信息,主要查看push与relabel与bfs的实现,可以去掉一些很多无关紧要的代码,并且与opencv对接,所有显存全用gpumat代码,差不多只有200行左右的代码。记的用这里的数据如person/sponge大约50多次迭代push-relabel后就能得到很好的结果(50次640*480类似的图只需要5-8ms,如果是416*416会更低,大约0.07ms就能一次迭代),在这给了我信心能继续做下去,当然后续结果另说。
后续就是一个组合过程,组合过程参照opencv的实现。
void GrabCutCude::renderFrame(GpuMat x3source, cv::Rect rect) { cudaDeviceSynchronize(); rgb2rgba_gpu(x3source, source); setMask_gpu(mask, rect); kmeans->compute(source, clusterIndex, mask, 0); //testShow(showSource, clusterIndex, "image"); gmm->learning(source, clusterIndex, mask); //testShow(showSource, clusterIndex, "seg image"); int index = 0; while (index++ < iterCount) { gmm->assign(source, clusterIndex, mask); gmm->learning(source, clusterIndex, mask); graph->addTermWeights(source, mask, *(gmm->bg), *(gmm->fg), lambda); graph->addEdges(source, gamma); graph->maxFlow(mask, maxCount); } }

其中有几处要求聚合运算,分别是求maxflow边的权重时,整张图的beta值,k-means更新聚合,gmm的训练,其中求beta只费了0.02ms,而k-means在0.12ms,而gmm的训练在1.2ms左右,beta只是把所有数据相加,每个像素对应4byte的共享存储,而k-means把数据取成十个类别,每个像素对应对应4byte*(3+1)*10个字节,时间花费0.02/0.12应该是一个正常范围,而gmm与k-means运算差不多完全一样,只是共享显存占用4byte*(3+3*3+1)*10个字节,时间花费比k-means多了十倍。这个比较很有意思,共享显存用越多,可以看到,GPU利用率会变低,求beta时,occupancy可以到达100%,而在k-meansk中只有25%,updateGMM只有6.25%。从前面k-means的代码看,每个聚合分成二部分,经调整GMM的前后部分发现,上部分降低线程块block可以降低时间,而下部分升高线程块block可以降低时间,其实这么算的话GMM的计算可以考虑分开算,让k-means的花费来看,最多0.3ms左右,1.2ms肯定还有很多优化空间。
如下结合我们自己编译的darknet动态链接库组合的代码。
void testYoloGrabCutCuda() { cv::VideoCapture cap; cv::VideoWriter video; cv::Mat frame; cv::Mat result, reframe; cap.open(0); char* modelConfiguration = "yolov3.cfg"; char* modelWeights = "yolov3.weights"; network *net = load_network(modelConfiguration, modelWeights, 0); layer l = net->layers[net->n - 1]; set_batch_network(net, 1); cv::Mat netFrame(net->h, net->w, CV_32FC3); const char* window_name = "yolo3"; //namedWindow(window_name); cv::namedWindow("image"); cv::namedWindow("seg image"); createUI("1 image"); int height = net->w; int width = net->h; GrabCutCude grabCut; grabCut.init(width, height); GpuMat gpuFrame; while (cv::waitKey(1) < 1) { updateUI("1 image", grabCut); cap >> frame; cv::resize(frame, reframe, cv::Size(net->w, net->h)); //reframe.convertTo(netFrame, CV_32FC3, 1 / 255.0); image im = mat_to_image(reframe); float *predictions = network_predict(net, im.data); int nboxes = 0; float thresh = 0.7f; detection curdet = {}; float maxprob = thresh; bool bFind = false; detection *dets = get_network_boxes(net, im.w, im.h, thresh, 0, 0, 0, &nboxes); for (int i = 0; i < nboxes; i++) { auto det = dets[i]; //0 person 39 bottle if (det.prob[39] > maxprob) { maxprob = det.prob[39]; curdet = det; bFind = true; } } if (!bFind) continue; int width = curdet.bbox.w + 20; int height = curdet.bbox.h + 20; cv::Rect rectangle(curdet.bbox.x - width / 2.f, curdet.bbox.y - height / 2.f, width, height); if (bCpu) { cv::Mat bgModel, fgModel; cv::grabCut(reframe, result, rectangle, bgModel, fgModel, iterCount, cv::GC_INIT_WITH_RECT); } else { grabCut.setParams(iterCount, gamma, lambda, maxCount); cudaDeviceSynchronize(); gpuFrame.upload(reframe); grabCut.renderFrame(gpuFrame, rectangle); grabCut.mask.download(result); } cv::compare(result, cv::GC_PR_FGD, result, cv::CMP_EQ); cv::Mat foreground(reframe.size(), CV_8UC3, cv::Scalar(0, 0, 0)); reframe.copyTo(foreground, result); cv::imshow("image", foreground); cv::rectangle(reframe, rectangle, cv::Scalar(0, 0, 255), 3); cv::imshow("seg image", reframe); } }
这段代码就是前面显示的结果,但是最后我发现,效果并不好,至少相对我参考那段maxflow效果来说,迭代五十次只需要5ms,再稍微优化下,k-means加上GMM可以控制在3ms内,这样加上yolo3也可以控制在30桢左右,但是,就前面那个杯子来说,需要迭代超过300次才能有个比较好的效果,如果是人,需要迭代上千次才能达到opencv的效果,那就没啥意义了,后续准备的优化与整合进引擎也暂停。
至于为啥会这样,我分析了下,原参考push-relabel里数据是用种子生成的方式来生成formsource,tosink,这样formsource与tosink本来就接近结果了。

而按照opencv里的流程,出来的formsource与tosink图如下。
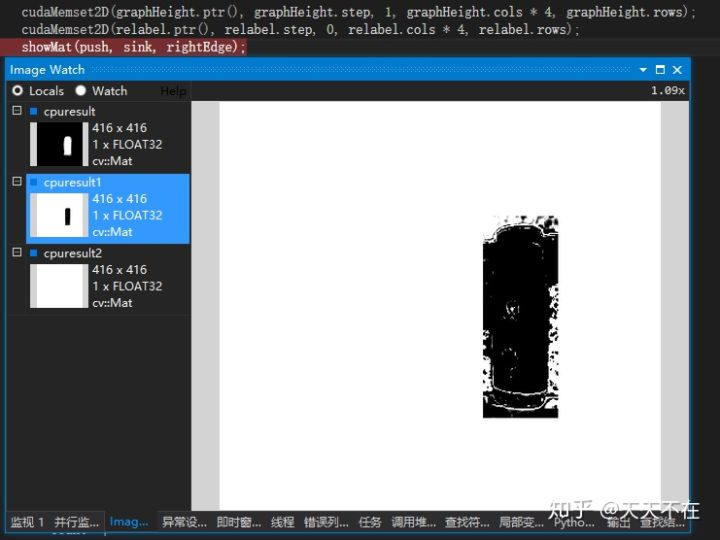
这样就需要迭代更多次的push_relabel来完成,主要因为这二次方式生成的GMM有很大区别,种子点生成的GMM各个分类与占比本来就好,我试验了下,扩大生成的边框,马上push_relabel的迭代次数加个百次,这是因为前景中混成来的背景越多,背景分类与占比越大,不确定区颜色通过GMM生成的formsource与tosink差值越小,虽然push-relabel每个点可以独立计算,很适合GPU算,但是他的push与relabel方式导致他每次可能就少数点在流动,大多点根本不满足要求。
那么要考虑在100次迭代内得到比较好的效果,需要种子点方式,加上一些特定需求,比如背景与人变动不大,只是人在背景中的位置在不断变化,可以先用几桢算mask-rcnn得到mask,用mask得到相对准确的GMM模型,再把这个GMM模型算对应graph的点权重,然后用maxflow算的比较清晰的边,最后用导向滤波还原大图,这模式对现在的流程有些改动,故此记录下现在流程,如果后续有比较好的效果再来继续说。
2019/3/20号更新:
为了验证我的想法以及评论区有同学提出formsource与tosink用同一例子比较,深以为然。下面是先用几桢效果的图算出GMM,然后用这个GMM值直接算formsource与tosink,如下是对应的formsource与tosink图。

void GrabCutCude::renderFrame(GpuMat x3source) { rgb2rgba_gpu(x3source, source); graph->addEdges(source, gamma); int index = 0; while (index++ < iterCount) { graph->addTermWeights(source, *(gmm->bg), *(gmm->fg), lambda); graph->maxFlow(mask, maxCount); } }
相对于原先方框里算k-means,GMM模型,这个是在已经得到GMM模型的情况下,用GMM直接算formsource与tosink,可以看到,相对于原来来说,结果已经很干净了,这种情况下,50次push-relabel就能得到比较准确的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号