

爬虫中的正则表达式
写在前面
为了不浪费大家时间,首先声明两点:
- 在第一篇文章:简单网站爬虫的所有技能(requests+bs4)涉及到的技能,不会重复讲解
- 这篇文章不会涉及任何正则表达式基础内容,只会有新鲜的实战部分,自学正则表达式基础内容,或者看看Python-正则表达式-re模块
- 比如\d表示数字
- * 表示重复0或多次
- ......
- 对,只用了解概念就行了,所以不要太紧张
建议爬虫初学者做完简单网站爬虫的所有技能(requests+bs4)思考题。
- 如无必要,勿增实体
- 用正确的工具,做正确的事情
正则表达式是你掌握简单网站爬虫之后的进阶技能,如果requests+bs4就可以满足需求,为什么自己要平添烦恼。
为什么要用正则
因为遇到了棘手的问题,不然谁会去学这么难懂的正则表达式
今天爬取的网址是:为知笔记吧首页,爬取的内容是回复数
STOP!别点上面的文字,点击文字的时候,用简单网站爬虫的所有技能(requests+bs4)提到的检查元素工具看看文字背后的真实url,这是一个非常好的上网习惯。检查了之后,接着往下看。
(注:与为知笔记无任何利益相关)
找到回复数

(动态图只默认播放一次,嗯,我录制的时候点错了一个选项。但是解决也很简单,比如
PC:在图片上右键,点击”在新标签页中打开图片“
APP:点一下图片)
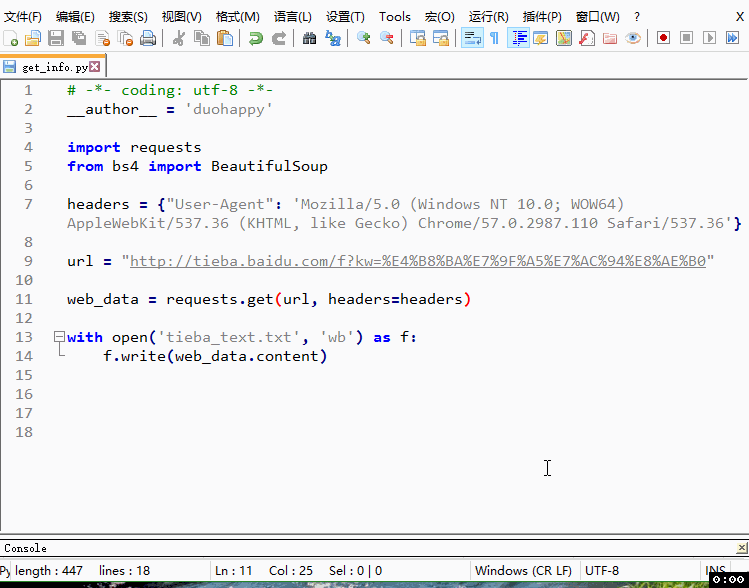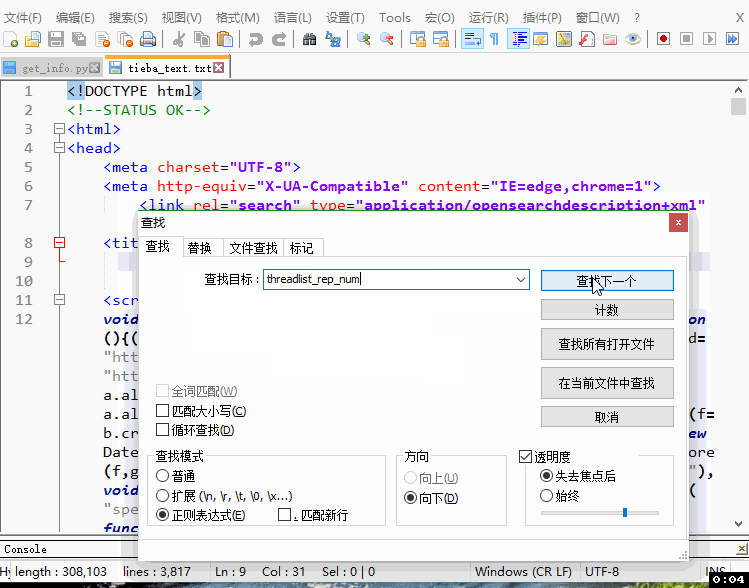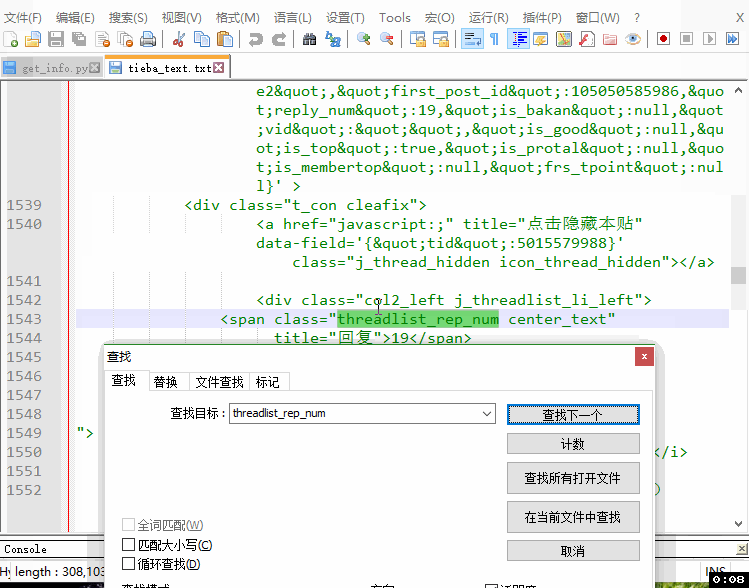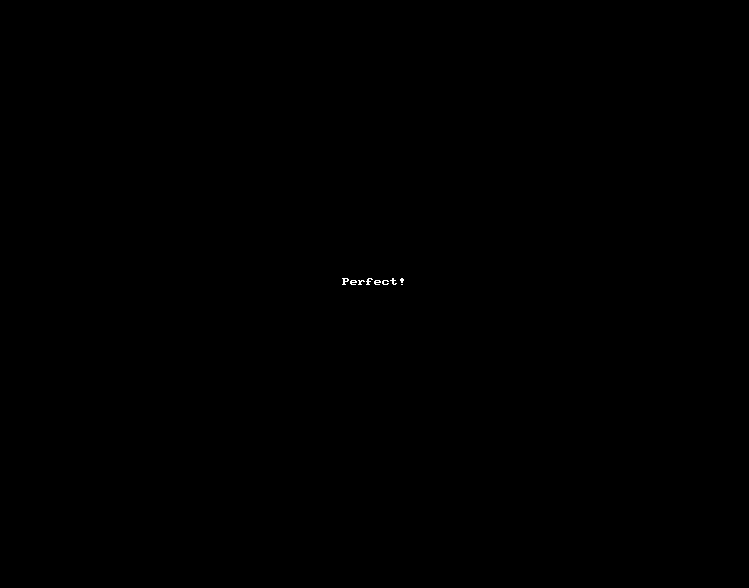
爬取网页源代码
看看网页源代码是不是真的包含了我们要的内容—回复数
# -*- coding: utf-8 -*-
__author__ = 'duohappy'
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36'}
url = "http://tieba.baidu.com/f?kw=%E4%B8%BA%E7%9F%A5%E7%AC%94%E8%AE%B0"
web_data = requests.get(url, headers=headers)
# 新知识点 web_data.content
# 以字节的方式访问web_data,所以用'wb'模式写入
with open('tieba_text.txt', 'wb') as f:
f.write(web_data.content)
搬出BeautifulSoup
网页源代码里包含了回复数,那么我们来用css selector语法把内容提取出来吧。稍等,看看soup里有没有
# -*- coding: utf-8 -*-
__author__ = 'duohappy'
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36'}
url = "http://tieba.baidu.com/f?kw=%E4%B8%BA%E7%9F%A5%E7%AC%94%E8%AE%B0"
web_data = requests.get(url, headers=headers)
web_data.encoding = 'utf-8'
web_text = web_data.text
soup = BeautifulSoup(web_text, 'lxml')
with open('soup_text.txt', 'w') as f:
f.write(str(soup)) # soup对象转成字符串

到此,我们要学正则表达式了!用正确的工具,做正确的事
收集建议
# -*- coding: utf-8 -*-
__author__ = 'duohappy'
import re
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36'}
url = "http://tieba.baidu.com/f?kw=%E4%B8%BA%E7%9F%A5%E7%AC%94%E8%AE%B0"
web_data = requests.get(url, headers=headers)
web_data.encoding = 'utf-8'
web_text = web_data.text
reply_nums = re.findall(r'(?<="回复">)[\s\S]*?(?=</span>)', web_text)
print(reply_nums)

正则表达式的心法
文章不涉及招式的讲解,需要自学正则表达式基础内容如零宽断言、懒惰模式、贪婪模式等
First Time
最容易理解的一个想法,也就是re.search()的用法: 扫描整个字符串并返回第一个成功的匹配
爬取帖子的创建时间,观察网页结构,写出匹配时间的正则
# -*- coding: utf-8 -*-
__author__ = 'duohappy'
import re
import requests
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36'}
url = "https://tieba.baidu.com/p/5054019406"
web_data = requests.get(url, headers=headers)
web_data.encoding = 'utf-8'
source_code = web_data.text
## 匹配时间的正则
time_pattern = r'\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}'
# 匹配第一个时间
create_time = re.search(time_pattern, source_code).group()
print(create_time)
Focus
反复聚焦
匹配帖子创建者的用户名,可以先想一想怎么匹配,再读源代码
如果你对网页结构敏感性越高,那么写出的正则适用性越大,通过检查元素,发现用户名存在于一段html代码中,这段代码有一个class,class="d_name",d_name有什么含义?嘿嘿嘿
<li class="d_name" data-field="{"user_id":1081331744}">
<a data-field="{"un":"suoai1335"}" alog-group="p_author" class="p_author_name j_user_card" href="/home/main?un=suoai1335&ie=utf-8&fr=pb" target="_blank">suoai1335</a>
</li>
# -*- coding: utf-8 -*-
__author__ = 'duohappy'
import re
import requests
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36'}
url = "https://tieba.baidu.com/p/5054019406"
web_data = requests.get(url, headers=headers)
web_data.encoding = 'utf-8'
source_code = web_data.text
# 匹配包含用户名正则表达式
include_username_pattern = r'(?<=<li class="d_name"\sdata)[\s\S]*?(?=</a>)'
# 匹配出来包含用户名的html代码
include_username = re.search(include_username_pattern, source_code).group()
# 匹配用户名的正则表达式
username_pattern = r'(?<=target="_blank">)[\s\S]*'
# First Time
username = re.search(username_pattern, include_username).group()
print(username)
下面用动画来演示一下,一般我们容易掉进一个误区里,认为要匹配什么,就只写匹配内容的正则表达式,可是呢?这个正则表达式又很难写,写完了又不是很通用,这个时候可以考虑换一种思路,发散一下思维,写一个正则表达式来匹配更多的内容,然后针对这一内容,再写一个正则表达式,最终取得自己想要的内容。
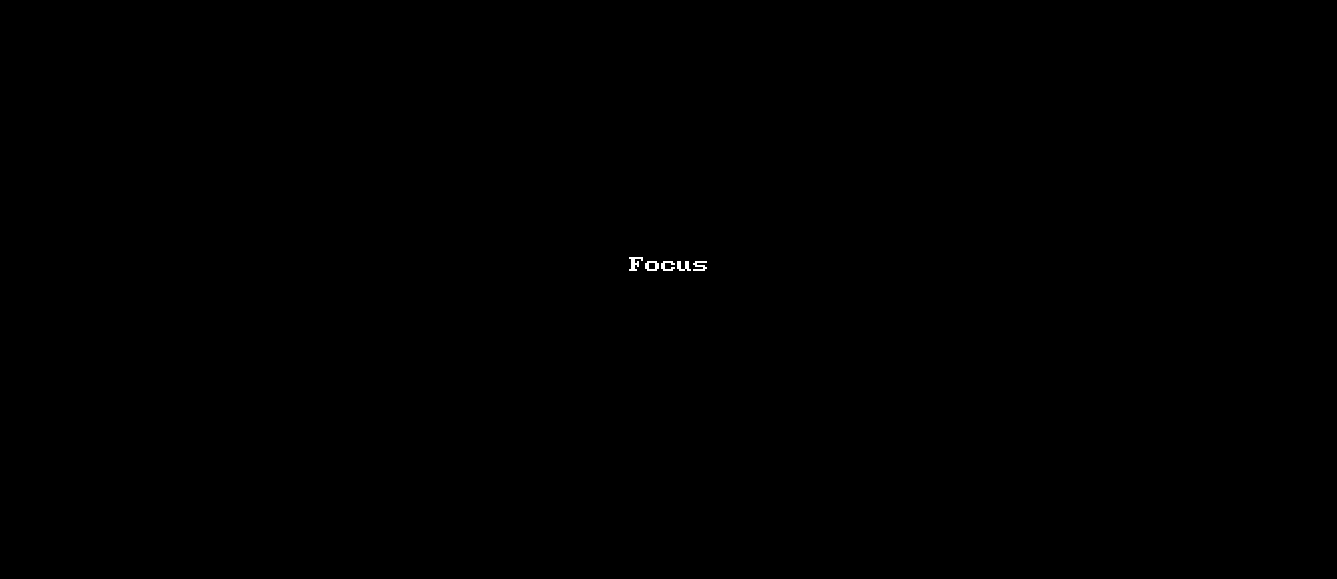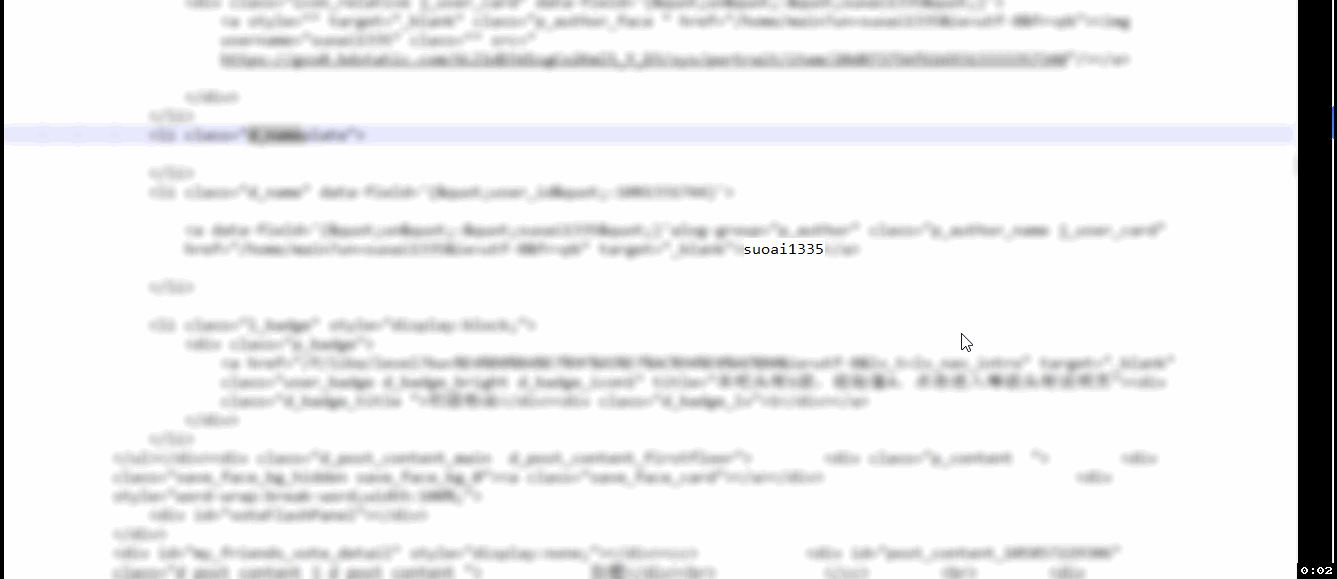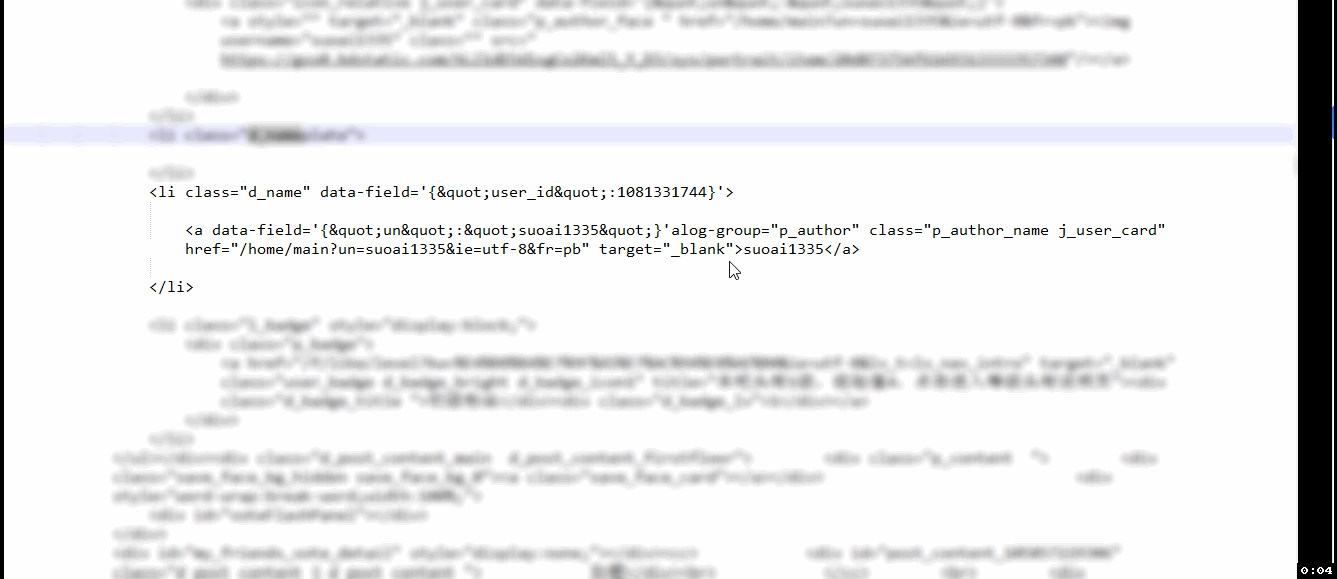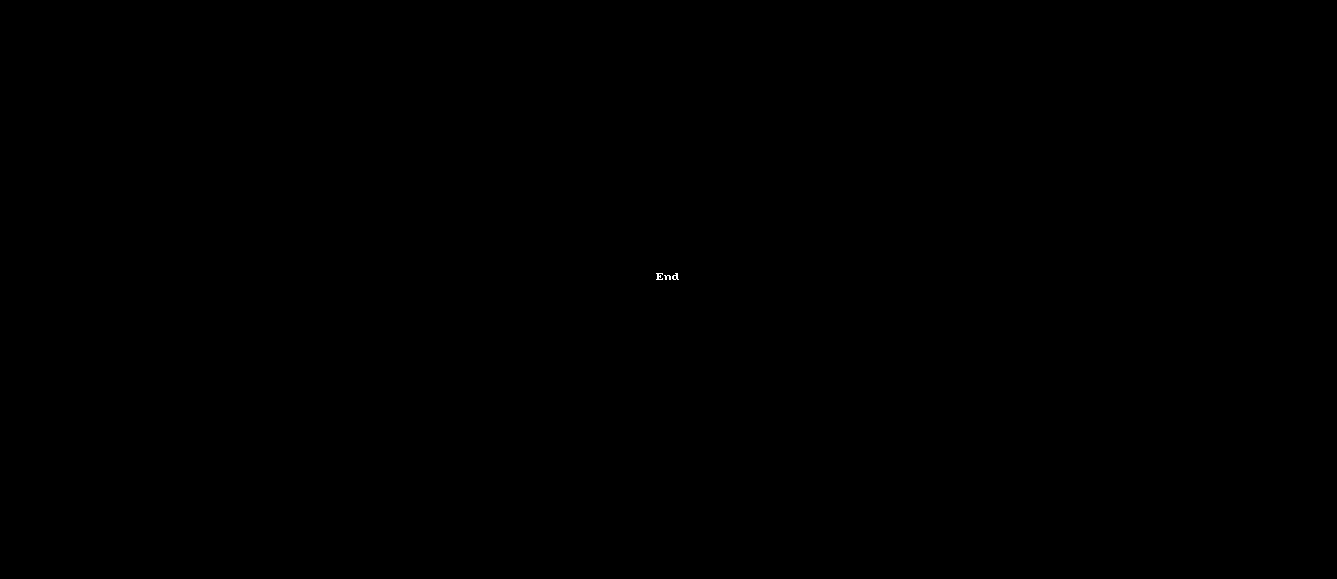
参考资料
感谢阅读,看张图片轻松一下

**
动手,你才能学会编程
分享,你才能学得透彻
**
