利用Python进行数据分析_Pandas_数据聚合与分组运算_数据聚合
GroupBy
按发行人汇总2021年截至目前债券实际发行规模的统计
from pandas import Series,DataFrame import pandas as pd import pymysql
db = pymysql.connect(host='127.0.0.1', port =3306, user = 'root', password = 'root', database = 'jydb',charset='GBK')
sql = """SELECT MainCode,BondNature,Issuer,PlanIssueSize,ActualIssueSize FROM Bond_IssueNew where IssueDateStart>='2021-01-01"""
df = pd.read_sql(sql,db) grouped = df['ActualIssueSize'].groupby(df['Issuer'])#按Issuer进行分组,并计算ActualIssueSize的和
df1 = grouped()
df1.to_excel('2.xlsx')
执行结果:

对分组进行迭代
from pandas import Series,DataFrame import pandas as pd import pymysql
db = pymysql.connect(host='127.0.0.1', port =3306, user = 'root', password = 'root', database = 'jydb',charset='GBK')
sql = """SELECT MainCode,BondNature,Issuer,PlanIssueSize,ActualIssueSize FROM Bond_IssueNew where IssueDateStart>='2021-01-01'"""
df = pd.read_sql(sql,db) for (k1,k2),group in df.groupby(['BondNature','Issuer']): print(k1,k2) print(group)
执行结果:

数据聚合
from pandas import Series,DataFrame import pandas as pd data = pd.read_excel('F:/Jupyter/4.xlsx')#读取excel data['%'] = data['PlanIssueSize']/data['ActualIssueSize']#添加一列表示计划发行规模与实际发行规模的比值 data[:10]#取前10行数据
执行结果:

面向列的多函数应用

5.xlsx文件内容如下:
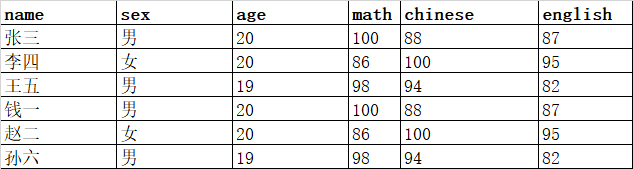
from pandas import Series,DataFrame
import pandas as pd
df = pd.read_excel('F:/Jupyter/5.xlsx')
grouped = df.groupby(['sex'])#根据性别分组
grouped_sex = grouped['math']
gp = grouped_sex .agg(['mean','sum','median'])#根据性别聚合mean\sum\median的值
gp
执行结果:
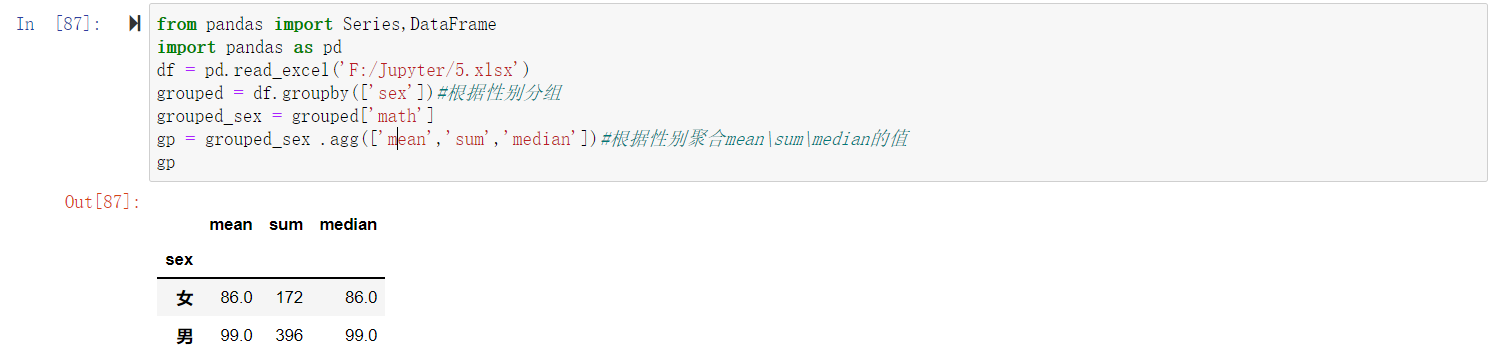
通过函数的方式,如下function函数的方式:
from pandas import Series,DataFrame import pandas as pd df = pd.read_excel('F:/Jupyter/6.xlsx') grouped = df.groupby(['sex'])#根据性别分组 function = ['mean','sum','median'] classtype = ['chinese','math','english'] gp = grouped[classtype].agg(function)#根据性别聚合不同学科的mean\sum\median的值 gp
执行结果:
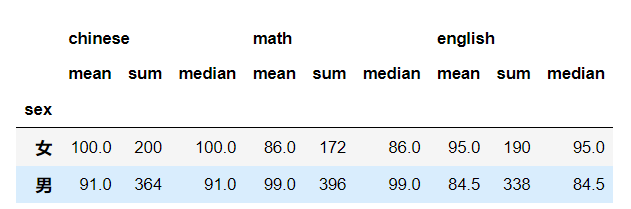
不同的列,应用不同的函数,怎么办?
向agg传入一个列名对应函数的dict(字典)
from pandas import Series,DataFrame import pandas as pd df = pd.read_excel('F:/Jupyter/6.xlsx') grouped = df.groupby(['sex'])#根据性别分组 # function = ['mean','sum','median'] function_dict = {'chinese':['mean','sum'],'math':'sum','english':'median'} classtype = ['chinese','math','english'] gp = grouped[classtype].agg(function_dict) gp
执行结果:
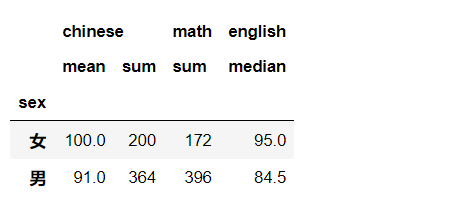
本文来自博客园,作者:ZhouSpeaks,转载请注明原文链接:https://www.cnblogs.com/zhouwp/p/15639528.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号