

【LLMOps】vllm加速机制及推理不一致根因剖析
介绍
当前大模型主流推理方式包括:vllm、tgi、原生transformer
回顾
目前主流大模型都是由transformer演变过来,transformer核心是attention,参考《Attention is All You Need》 ,attention核心则是3个矩阵:Query、Key、Value。
一句话解释attention:Query是当前单词查询矩阵,Key是被查询单词的索引矩阵,Value是被查询单词的结果矩阵。
参考:https://zhuanlan.zhihu.com/p/624531147?utm_id=0 、https://zhuanlan.zhihu.com/p/104393915
vllm加速原理
参考文章:https://blog.vllm.ai/2023/06/20/vllm.html
在vllm中有个观念:大模型的推理性能瓶颈是内存(In vLLM, we identify that the performance of LLM serving is bottlenecked by memory),因此vllm致力于优化内存,内存优化的越好,其支持的并发度越高。
核心技术:PageAttention
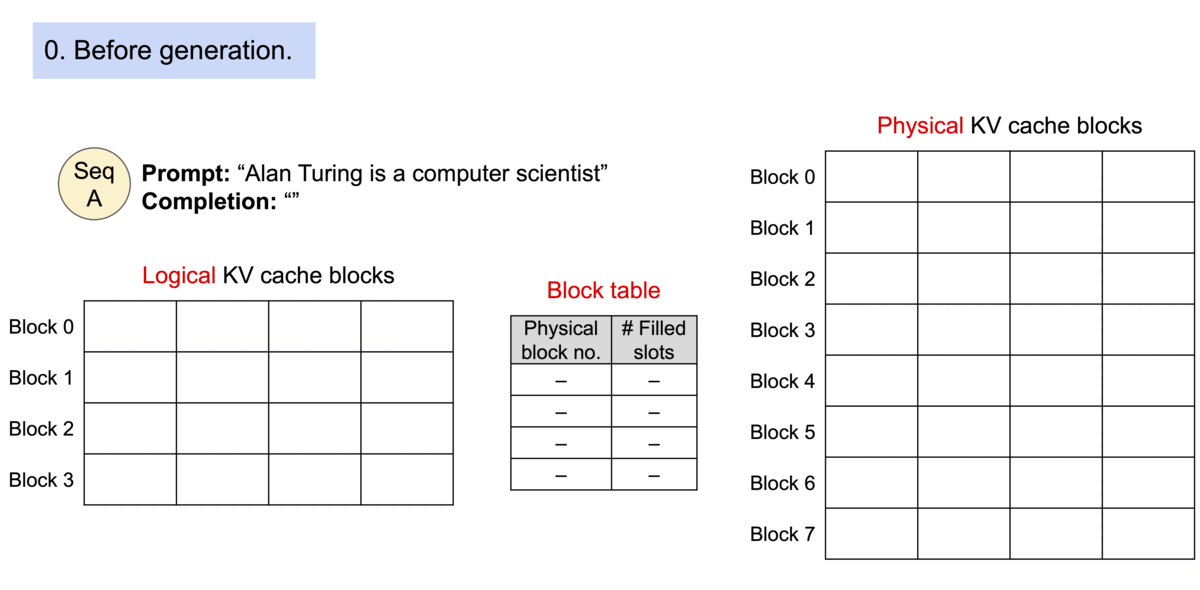
在PageAttention使用之前,大模型的推理内存是连续的,这就导致碎片化的内存是无法利用的。
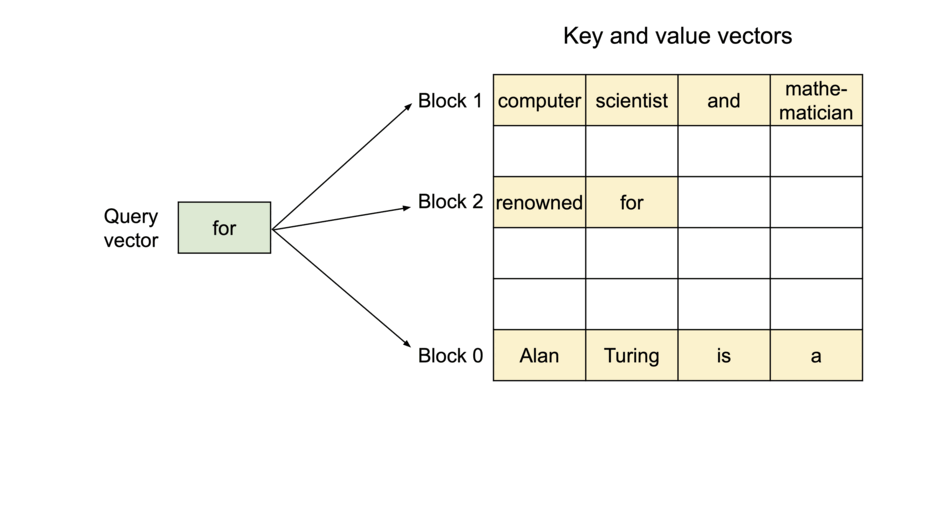
PageAttention理念来源于操作系统的虚拟内存,核心手段是对显存进行分块+索引;
另外,该方式提高显存的复用性。例如相同的prompt可以存放到单独的内存块中,不需要再重复生成。
模型并行
vllm支持模型并行,参考Megatron-LM’s tensor parallel algorithm
其核心思路是同时将模型分层,每个层分配到不同的显卡(竖切);再将一个Tensor划分成多个分配到不同的显卡(横切)
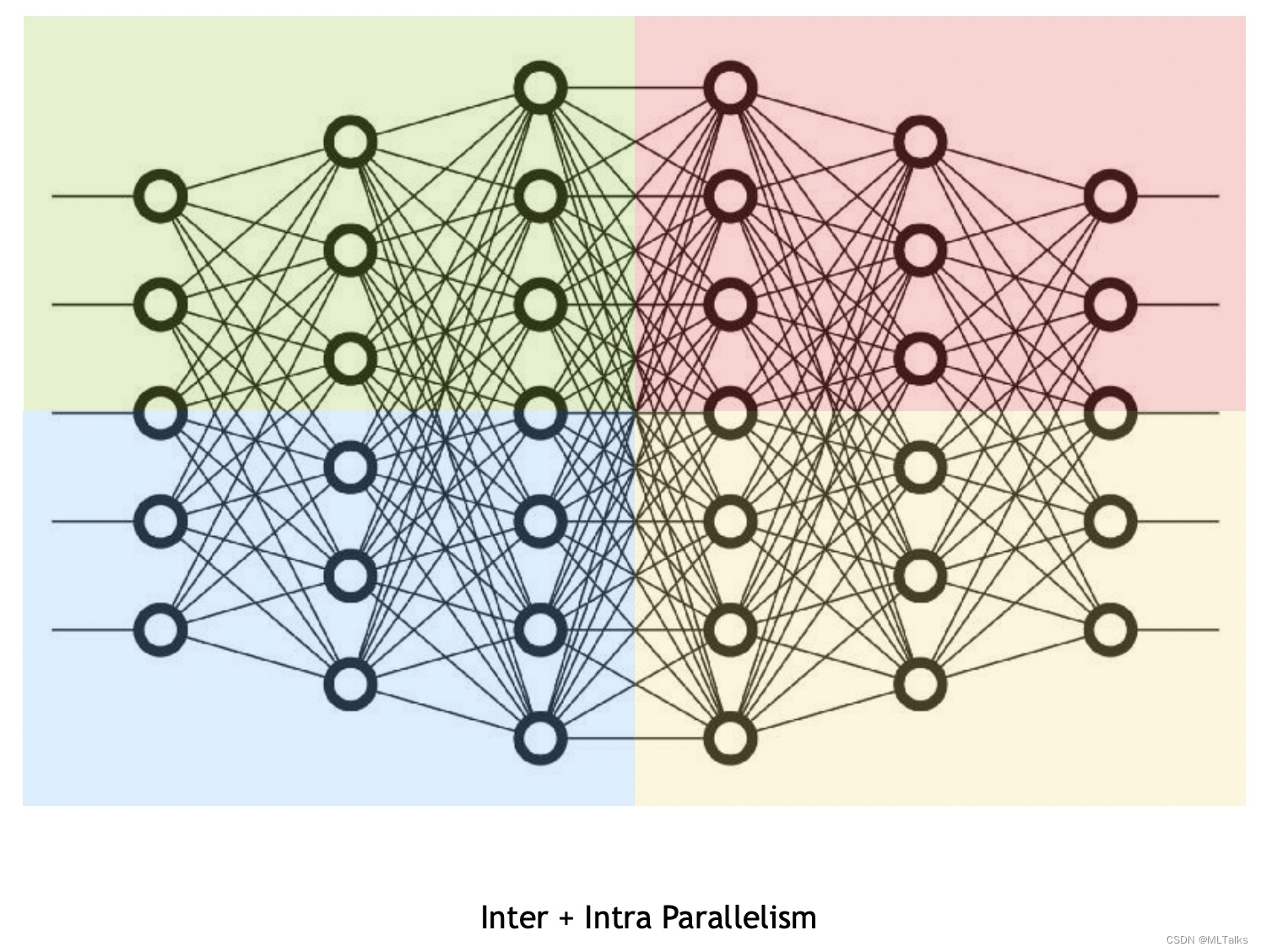
最终实现多卡之间并行推理。
参考文章:https://blog.csdn.net/qinduohao333/article/details/131617757、https://zhuanlan.zhihu.com/p/622212228?utm_id=0
推理不一致
未完待续


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律