
【LLMOps】Accelerate & DeepSpeed使用及加速机制剖析
介绍
目前大模型微调主要方案是 LLaMA-Factory
LLaMA-Factory中,提供了两种多卡框架:Accelerate、DeepSpeed
Accelerate
依赖
accelerate==0.24.1 transformers==4.34.1 datasets==2.14.7 tiktoken==0.5.1 peft==0.6.2 trl==0.7.1
这里只列出可能冲突版本
注意
使用最新版本0.24.1,尝试使用0.21.0,发现gpu_ids不生效
其中trl需要降级到0.7.1,最新的0.7.4训练会报错。默认第一步安装是0.7.4
配置
yaml配置如下:
compute_environment: LOCAL_MACHINE distributed_type: MULTI_GPU downcast_bf16: 'no' machine_rank: 0 main_training_function: main mixed_precision: fp16 gpu_ids: 1,3 num_machines: 1 num_processes: 2 rdzv_backend: static same_network: true tpu_env: [] tpu_use_cluster: false tpu_use_sudo: false use_cpu: false
最终命令:
accelerate launch --config_file /root/default_config.yaml src/train_bash.py [llama-factory参数]
注意:
gpu_ids数量跟num_processes必须要一致
训练速度
| 模型大小 | 数据量 | 训练模式 | 资源 | 时长/epoch |
| 14B | 4500 | LoRA微调 | 单机单卡 | 52分钟 |
| 14B | 4500 | LoRA微调 | 单机2卡 | 28分钟 |
| 14B | 4500 | LoRA微调 | 单机3卡 | 19分钟 |
从结果来看,训练速度基本与显卡数量成线性关系。且显存大小几乎一样
原理剖析
基本概念
- DP:数据并行
- DDP:数据分布式并行
DP
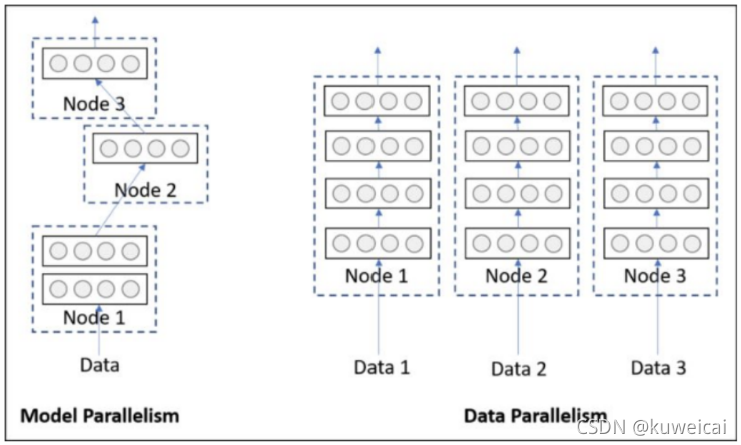
DP过程如下
- 将 inputs 从主 GPU 分发到所有 GPU 上
- 将 model 从主 GPU 分发到所有 GPU 上
- 每个 GPU 分别独立进行前向传播,得到 outputs
- 将每个 GPU 的 outputs 发回主 GPU
- 在主 GPU 上,通过 loss function 计算出 loss,对 loss function 求导,求出损失梯度
- 计算得到的梯度分发到所有 GPU 上
- 反向传播计算参数梯度
- 将所有梯度回传到主 GPU,通过梯度更新模型权重
- 不断重复上面的过程
DDP
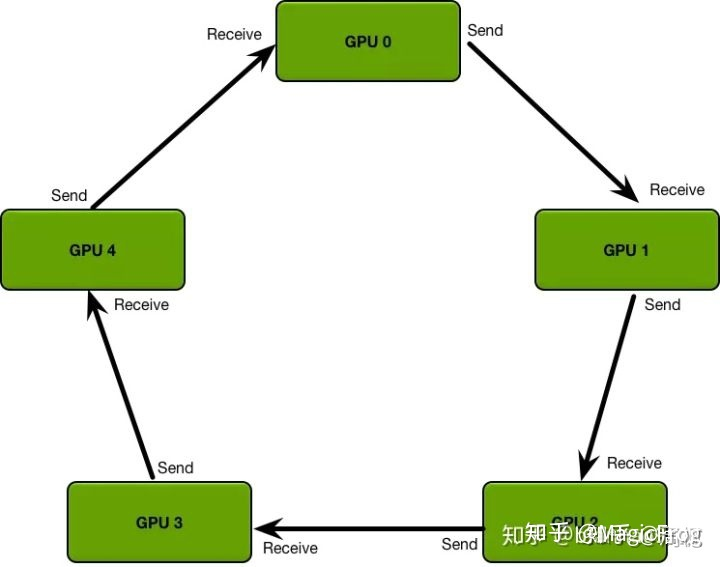
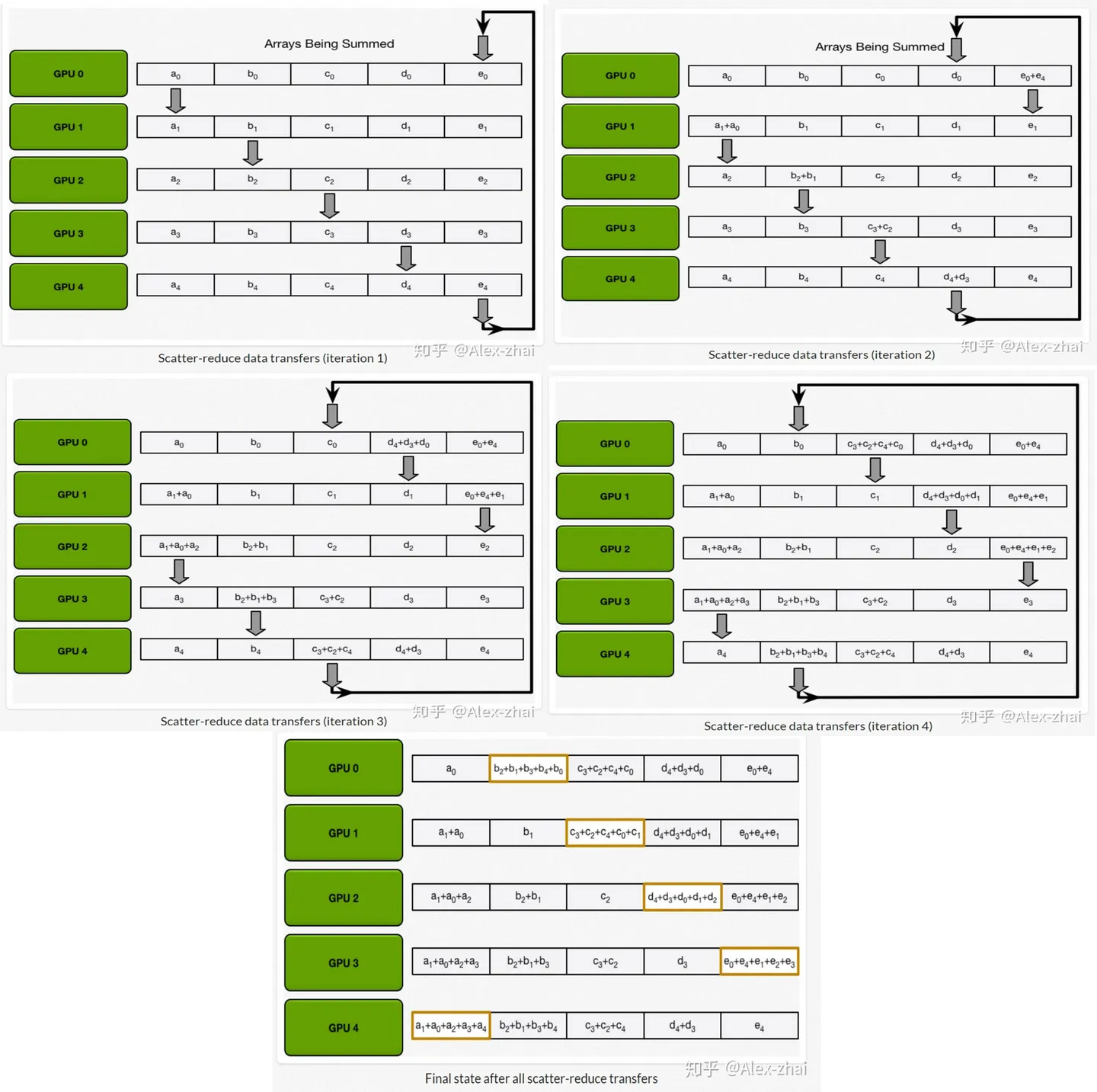
DDP相邻的卡之间通信
参考文章:https://zhuanlan.zhihu.com/p/356967195 、https://zhuanlan.zhihu.com/p/343951042
区别
DP通信量大,依赖于主节点;DDP依赖于相邻的节点
DP每个step(完整的梯度)只需要单张卡完成;DDP每个step需要遍历所有卡才能完成
Accelerate机制
accelerate使用的DDP机制,不同卡之间通过DataLoader加载均匀的数据,每张卡独自训练,并相互之间循环通信;
需要注意的是:
在accelerate中设置的batchSize是设置给每个GPU的。因此,当配置N张卡、BatchSize设置为M时,实际上每个step执行了M*N个样本;如果把这N张卡合并成一张卡。
batchSize变大了对应的learnRate也需要调大N倍。
参考文档:https://huggingface.co/docs/accelerate/v0.25.0/en/concept_guides/performance
DeepSpeed
依赖
deepspeed==0.12.3 transformers==4.34.1 datasets==2.14.7 tiktoken==0.5.1 peft==0.6.2 trl==0.7.1
配置方式1
deepspeed --include="localhost:0" src/train_bash.py [llama-factory参数] --deepspeed /root/ds_config.json
注意
单机训练不需要配置hostfile,但是需要配置localhost
配置方式2
通过accelerate,accelerate配置文件如下:
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: true
zero_stage: 2
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
最终启动命令
accelerate launch examples/nlp_example.py --mixed_precision fp16
配置方式3
accelerate配置:
command_file: null
commands: null
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: 'ds_config.json'
distributed_type: DEEPSPEED
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config: {}
gpu_ids: null
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
megatron_lm_config: {}
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_name: null
tpu_zone: null
use_cpu: false
ds_config.json配置:
{
"bf16": {
"enabled": true
},
"zero_optimization": {
"stage": 3,
"stage3_gather_16bit_weights_on_model_save": false,
"offload_optimizer": {
"device": "none"
},
"offload_param": {
"device": "none"
}
},
"gradient_clipping": 1.0,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": 10,
"steps_per_print": 2000000
}
速度
未完待续
问题
- Caught signal 7 (Bus error: nonexistent physical address)
在使用单机多卡时,使用官方镜像:registry.cn-beijing.aliyuncs.com/acs/deepspeed:v072_base,会报如下错误:
[fc3a502973d9:255 :0:690] Caught signal 7 (Bus error: nonexistent physical address) ==== backtrace (tid: 690) ==== 0 0x0000000000043090 killpg() ???:0 1 0x000000000018bb41 __nss_database_lookup() ???:0 2 0x00000000000755bd ncclGroupEnd() ???:0 3 0x000000000007a74f ncclGroupEnd() ???:0 4 0x0000000000059e67 ncclGetUniqueId() ???:0 5 0x0000000000048b3b ???() /usr/lib/x86_64-linux-gnu/libnccl.so.2:0 6 0x000000000004a5c2 ???() /usr/lib/x86_64-linux-gnu/libnccl.so.2:0 7 0x0000000000064f66 ncclRedOpDestroy() ???:0 8 0x000000000004ae0b ???() /usr/lib/x86_64-linux-gnu/libnccl.so.2:0 9 0x000000000004b068 ncclCommInitRank() ???:0 10 0x0000000000118354 horovod::common::NCCLOpContext::InitNCCLComm() /opt/horovod/horovod/common/ops/nccl_operations.cc:113 11 0x0000000000118581 horovod::common::NCCLAllreduce::Execute() /opt/horovod/horovod/common/ops/nccl_operations.cc:180 12 0x00000000000da3cd horovod::common::OperationManager::ExecuteAllreduce() /opt/horovod/horovod/common/ops/operation_manager.cc:46 13 0x00000000000da7fc horovod::common::OperationManager::ExecuteOperation() /opt/horovod/horovod/common/ops/operation_manager.cc:112 14 0x00000000000a902d horovod::common::(anonymous namespace)::BackgroundThreadLoop() /opt/horovod/horovod/common/operations.cc:297 15 0x00000000000a902d std::__shared_ptr<CUevent_st*, (__gnu_cxx::_Lock_policy)2>::operator=() /usr/include/c++/9/bits/shared_ptr_base.h:1265 16 0x00000000000a902d std::shared_ptr<CUevent_st*>::operator=() /usr/include/c++/9/bits/shared_ptr.h:335 17 0x00000000000a902d horovod::common::Event::operator=() /opt/horovod/horovod/common/common.h:185 18 0x00000000000a902d horovod::common::Status::operator=() /opt/horovod/horovod/common/common.h:197 19 0x00000000000a902d PerformOperation() /opt/horovod/horovod/common/operations.cc:297 20 0x00000000000a902d RunLoopOnce() /opt/horovod/horovod/common/operations.cc:787 21 0x00000000000a902d BackgroundThreadLoop() /opt/horovod/horovod/common/operations.cc:651 22 0x00000000000d6de4 std::error_code::default_error_condition() ???:0 23 0x0000000000008609 start_thread() ???:0 24 0x000000000011f133 clone() ???:0 =================================
使用单机单卡没有问题,该问题issue:https://github.com/microsoft/DeepSpeed/issues/2638
该issue描述的这个问题根因是因为deepspeed不支持s3协议,导致该错误发生。但是这个结论是错误的,实际根因参考:https://forums.developer.nvidia.com/t/more-than-1-gpu-not-working-using-tao-train/244506 ,根因还是nccl库安装的不对。
官方镜像v072_base版本滞后,torch还是1.12.0,导致llama-factory很多库不兼容(最低版本1.13.0)。按照deepspeed最新的Dockerfile构建,已经更新为torch==1.13.0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号