
【kserve】transformer使用以及predictor所包含的接口
Transformer使用
transformer是对模型推理的预处理和后处理,
class ImageTransformer(Model):
def __init__(self, name: str, predictor_host: str, protocol: str):
super().__init__(name)
self.predictor_host = predictor_host
self.protocol = protocol
self.ready = True
def preprocess(self, request: Dict) -> ModelInferRequest:
# Input follows the Tensorflow V1 HTTP API for binary values
# https://www.tensorflow.org/tfx/serving/api_rest#encoding_binary_values
input_tensors = [image_transform(instance) for instance in request["instances"]]
# Transform to KServe v1/v2 inference protocol
if self.protocol == PredictorProtocol.GRPC_V2.value:
return self.v2_request_transform(numpy.asarray(input_tensors))
else:
inputs = [{"data": input_tensor.tolist()} for input_tensor in input_tensors]
request = {"instances": inputs}
return request
def v2_request_transform(self, input_tensors):
request = ModelInferRequest()
request.model_name = self.name
input_0 = InferInput("INPUT__0", input_tensors.shape, "FP32")
input_0.set_data_from_numpy(input_tensors)
request.inputs.extend([input_0._get_tensor()])
if input_0._get_content() is not None:
request.raw_input_contents.extend([input_0._get_content()])
return request
def postprocess(self, infer_response: ModelInferResponse) -> Dict:
if self.protocol == PredictorProtocol.GRPC_V2.value:
response = InferResult(infer_response)
return {"predictions": response.as_numpy("OUTPUT__0").tolist()}
else:
return infer_response
parser = argparse.ArgumentParser(parents=[model_server.parser])
parser.add_argument(
"--predictor_host", help="The URL for the model predict function", required=True
)
parser.add_argument(
"--protocol", help="The protocol for the predictor", default="v1"
)
parser.add_argument(
"--model_name", help="The name that the model is served under."
)
args, _ = parser.parse_known_args()
if __name__ == "__main__":
model = ImageTransformer(args.model_name, predictor_host=args.predictor_host,
protocol=args.protocol)
ModelServer(workers=1).start([model])class ImageTransformer(Model):
def __init__(self, name: str, predictor_host: str, protocol: str):
super().__init__(name)
self.predictor_host = predictor_host
self.protocol = protocol
self.ready = True
def preprocess(self, request: Dict) -> ModelInferRequest:
# Input follows the Tensorflow V1 HTTP API for binary values
# https://www.tensorflow.org/tfx/serving/api_rest#encoding_binary_values
input_tensors = [image_transform(instance) for instance in request["instances"]]
# Transform to KServe v1/v2 inference protocol
if self.protocol == PredictorProtocol.GRPC_V2.value:
return self.v2_request_transform(numpy.asarray(input_tensors))
else:
inputs = [{"data": input_tensor.tolist()} for input_tensor in input_tensors]
request = {"instances": inputs}
return request
def v2_request_transform(self, input_tensors):
request = ModelInferRequest()
request.model_name = self.name
input_0 = InferInput("INPUT__0", input_tensors.shape, "FP32")
input_0.set_data_from_numpy(input_tensors)
request.inputs.extend([input_0._get_tensor()])
if input_0._get_content() is not None:
request.raw_input_contents.extend([input_0._get_content()])
return request
def postprocess(self, infer_response: ModelInferResponse) -> Dict:
if self.protocol == PredictorProtocol.GRPC_V2.value:
response = InferResult(infer_response)
return {"predictions": response.as_numpy("OUTPUT__0").tolist()}
else:
return infer_response
parser = argparse.ArgumentParser(parents=[model_server.parser])
parser.add_argument(
"--predictor_host", help="The URL for the model predict function", required=True
)
parser.add_argument(
"--protocol", help="The protocol for the predictor", default="v1"
)
parser.add_argument(
"--model_name", help="The name that the model is served under."
)
args, _ = parser.parse_known_args()
if __name__ == "__main__":
model = ImageTransformer(args.model_name, predictor_host=args.predictor_host,
protocol=args.protocol)
ModelServer(workers=1).start([model])
- 自定义java镜像
虽然kserve官方并没有支持其他语言的api,用于支撑kserve,但根据源码解读,其实现它的透传协议即可完成kserve的自定义。
源码解读地址: https://github.com/kserve/kserve/blob/master/python/kserve/kserve/model.py
流程如下:
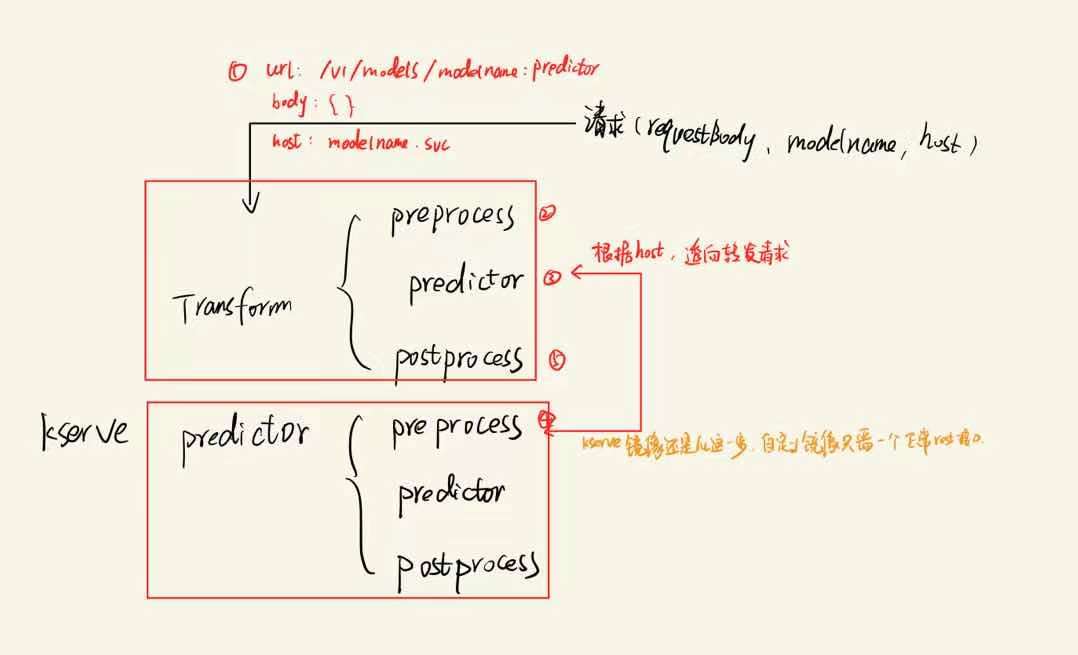
因此自定义接口完成2步即可:
1. 按照 /v1/models/([a-zA-Z0-9_-]+):predict 格式的url获取推理请求
2.根据 args获取predictor_host,在transformer完成预处理后转发给predictor_host进行推理
包含的接口
源码解析: https://github.com/kserve/kserve/blob/master/python/kserve/kserve/model_server.py
/v1/models 模型名称
/v1/models/([a-zA-Z0-9_-]+) 模型健康状态
/v1/models/([a-zA-Z0-9_-]+):predict 模型预测地址
/v1/models/([a-zA-Z0-9_-]+):explain 模型详情
/v2/health/live 健康检查
/v2/models 模型名称
/v2/models/([a-zA-Z0-9_-]+)/status 模型状态
/v2/models/([a-zA-Z0-9_-]+)/infer 模型预测地址
/v2/models/([a-zA-Z0-9_-]+)/explain 模型详情
/v2/repository/models/([a-zA-Z0-9_-]+)/load
/v2/repository/models/([a-zA-Z0-9_-]+)/unload

 浙公网安备 33010602011771号
浙公网安备 33010602011771号