5.4.5 索引
2018-07-16 17:09 笑一笑十年少!!! 阅读(279) 评论(0) 收藏 举报5.4.5 索引
如前所述,SQL Server的表默认以堆的形式存储。要从堆中检索任何记录,SQL Server 必须执行全表扫描;换句话说,它必须检查每个记录来确定是否应返冋该记录。可以想到,
这是一种效率极其低下的检索数据的方式。堆用来存储数据很好,也能有效地处理新记录,
但要在表中寻找特定数据时就没有那么好用了。这就是索引发挥作用的地方。SQL Server 支持两种基本类型的索引:聚集索引和非聚集索引。它还支持XML索引和空间索引等其
他索引类型(本章稍后将会讨论),但这些索引和普通的关系索引大不相同,后者将用来在
数据库表中定位大多数数据。
聚集和非聚集索引之间的主要区别在于索引的叶级。在非聚集索引中,叶级包含数据
的指针。在聚集索引中,叶级包含实际数据。
1 .聚集索引
表的所有数据可存储在堆中或聚集索引中。堆和聚集索引是互相排斥的。如前所述,
堆是一个无组织的表行集合,而聚集索引是一个有组织的表行集合。
电话簿的白页是聚集索引的一个绝佳的例子。白页上所有的行都按姓和名的组合进行
聚集。当浏览白页査找一个电话号码时,浏览的是索引和数据。当找到索引值时,其余的
相关数据也找到了。
对于SQL Server聚集索引来说也是如此。可以创建聚集索引来按行的特定属性或列排 序数据。冋到图书馆的例子,图书馆通过一个基于类型和/或主题的聚集索引组织大部分的
书,然后再按作者进一步细分。聚集键在索引中必须是唯一的(这是为了支持非聚集索引,
稍后会介绍),但创建索引时不必将此列标记为唯-的。当在未标记为唯一的列上创建聚集
索引时,SQL Server会生成一个隐藏列,它保存一个名为唯一标识符(uniqueifier)的4 字节内 部值来唯一标识重复的聚集索引键。聚集索引的叶级是实际的数据行,而不是数据的指针。
2 .非聚集索引
非聚集索引更像是一本书后面的索引。当找到索引值时,并不能得到实际数据行,只
是获得指定实际数据行的位置的指针。叶级页中包括的指针类型将取决于非聚集索引是构
建在堆还是聚集索引之上。
堆上的非聚集索引
当在一个以堆形式组织的表上构建非聚集索引时,索引列根据指向数据实际位置的指
针分类。该指针由文件ID、页 ID和数据所在的页槽号组成。例如,如果数据是第一个文
件中第84 593页上的第20条记录,那么SQL将使用指针值1:84593:20。这 使 SQL Server
能够在索引找到数据之后快速访问数据。
例如,让我们回到图书馆的例子。如果收入无组织化的图书馆的每本书的物理位置都
按其在书架上的放置位置记录在索引巾,那么可以参照此索引来找到书,而不必搜索所有
书架。这种技术的不利之处就是,类似的记录(在图书馆例子中就是类似的书)可能放在完
全不同的地方。例如,搜索有关SQL Server 2008的书可能会返回好几本,而每本又位于图 书馆中的两端。如果所有SQL Server的书都放在一起,那么找到它们花费的力气就要少很 多。对于建立在一个堆表上的简单的单列索引来说,索引本身就像是一个两列的表。第一
列记录索引值,而第二列则记录从中可找到索引值的行的实际位置。
聚集索引上的非聚集索引
当在一个聚集索引上构建非聚集索引时,索引中的指针值就是数据行的聚集索引键
值。一旦定位到索引值,SQL Server就使用聚集键导航聚集索引来检索所有需要的列。 例如,在电话簿的例子中,我们知道电话簿的白页就像是SQLServer中的聚集索弓|。我住 在丙雅图东南的一个小镇上。我的电话簿在白页后面包含了一个有趣的附加索引,我把它们称
为 “灰白页”。这些“灰白页”按顺序囊括了镇卜.每一个公开的电话号码,还有号码持有人的
姓和名。这是在聚集索引上构建非聚集索引的一个非常好的例子。电话号码可以用来发现姓和
名的组合,而姓和名的组合可以用来寻找地址(如果它们在电话簿中列出来的话)。
创建聚集索引还是把记录留在堆中,这是一个通常由数据访问方式决定的设计决策。
当表中的数据主要通过一个可预测的属性或列访问时,那么把表中的行都聚集在这个特定
的列上可能十分有用。然而,如果该列基于-个人型数据类型,在其上创建聚集索引的存
储和索引维护开销将是非常昂贵的。
3 .包含列
非聚集索引的功能可以通过向索引的叶节点添加非键值得到提升。这就可使索引覆盖
更多的査询,减少为检索额外值而遍历聚集索引的次数。
将索引指派为覆盖索引(covered index)町避免重复遍历聚集索引。 通常,覆盖索引是包含满足査询所需的所有数据的索引。DBA使用的一种方法是在
LastName和 FirstName列上创建非聚集索引。这将把值放在叶节点中的LastName和
FirstName列(因为它们是索引键)以及Contactld列。如果执行一个只需要这3 列的査询, 那么不必遍历聚集索引。这一方法一般情况下都很好,只是索引大小增长过快,因为参与
索引的所有列包含在索引的所有级别中。此外,需要在两列上对索引排序,在更新中这样
做可能会导致性能问题。
包含列(includedcolumn)可以提高査询覆盖率,而不会导致复合索引键的开销。索引中 标记为included的列只出现在索引的叶节点中,在行排序中不作考虑。要在叶节点中包含
列,可使用CREATE INDEX命令的INCLUDE选项。下列命令在LastName列上创建索引, 并包含 AdventureWorks2008 中的 Person.Person 表的 FirstName 列。
CREATE NONCLUSTERED INDEX IX_Person_LastName ON Person.Person(LastName) INCLUDE(FirstName)
4 .筛选索引
筛选索引只是优化的非聚集索引。它允许在数据子集上创建索引,使得索引结构更小,
从而减少了构建索引的时间和索引维护成本。对于包含大量NULL值或包含数据范围(如美
元数)的列上的索引,筛选索引特别有用。要创建筛选索引,只需在CREATE INDEX语句
中包括WHERE子句。下列代码对所有成本大于$800的产品创建索引。
CREATE NONCLUSTERED INDEX IX_ListPrice_Product ON Production.Product(ListPrice) WHERE ListPrice > 800.00;
5 .分层索引
如第4 章所述,Hierarchyld是 SQL Server 2008中引入的一种新数据类型。为了帮助
检索分层数据,可使用两种不同的方法在此类型的列上构建索引:广度优先和深度优先。
广度优先索引
广度优先索引(breadth-first index)将同一级别的所有记录组合在一起。这 样 SQL Server
就可以非常快速地响应具有共同父节点的所有记录的查询。例如,向IT经理作汇报的所有
雇员记录会被组合在一起。下列代码在雇员表上创建一个广度优先索引。
- - Breadth-First IF EXISTS (SELECT * FROM sys.indexes WHERE Name = ,IX_Employee_OrganizationLevel一OrganizationNode’> DROP INDEX IX_Employee_OrganizationLevel_OrganizationNode ON HumanResources.Employee
CREATE NONCLUSTERED INDEX IX_Employee_OrganizationLevel_OrganizationNode ON HumanResources.Employee(
OrganizationLevel, OrganizationNode
深度优先索引
深度优先索引(depth-first index)使一条链上的所有记录组合在一起。这样SQL Server可
以非常快速地响应査找层次结构的査询。例如,假设我们需要Peter的记录和Peter各级上 司(直至CEO)的记录。
要创建深度优先索引,只需在Hierarchyld列上创建索引。
下列代码在雇员表上创建深度优先索引:
- - Depth-First
IF EXISTS (SELECT * FROM sys. indexes WHERE Name = ' IX_Employee_OrganizationNode *) DROP INDEX IX一Employee_OrganizationNode ON HumanResources.Employee
CREATE NONCLUSTERED INDEX IX_Employee_OrganizationNode
ON HumanResources.Employee
(
OrganizationNode
)
6 .空间索引
SQL Server 2008通过两种新的CLR数据类型支持空间索引:geometry和 geography<>
geometry数据类型用于平面(平面球)空间,而 geography数据类型用于地形测量(岡球)空间。
要了解这些数据类型的更多信息,可参见第4 章。
对空间数据常见的操作是找到与给定区域相交的所有记录。例如,我们需要找到以指
定位置为中心,以50米为半径的范围内的所有商店,并根据距离排序。找到相交区域是非
常昂贵的操作,对于复杂的数据区域来说更是如此。如果可排除所有与指定区域不可能相
交的区域,那么找到有效记录的幵销会大大降低。空间索引的作用就在于此。
创建空间索引需要两个阶段:分解和镶嵌。在分解阶段,SQL Server将一个有限区域
划分为一个网格结构(参考“Excel工作表”)。每个网格单元映射到另一网格结构,构成一 个更详细的级别。这一过程持续进行,直至创建4 个级别。每个级别中的网格可配置为4
X4、8X8或 16X16的单元网格。可以看到,网格数会快速增长。例如,如果在每个级别
中都有一个16X16的单元网格,最终将得到约40亿个网格。
在镶嵌阶段,表中的每个空间值都映射至每个网格级别。SQL Server计算值“接触” 的单元并将它们记录至实际空间索引中。然后,通过空间索引在空间中相对于其他也存储
在索引中的对象定位对象。
可在单个空间数据列上创建许多空间索引,每个索引覆盖一个独立的空间区域。由于
平面在任何方向都是无限延展 的 ,在 使 用 geometry(平面球)数据类型时,必须使用 BOUNDING_BOX选项指定有限空间。例如,我们可能只想对华盛顿州的商店的位置数据
进行索引。从概念上看,这非常类似于筛选索引,因为我们只索引一个数据子集,但这里
提供的是一个包围矩形,而不是提供WHERE子句来限制索引的记录。
7. XML索引
SQL Server 2008中支持的另一类索引是XML索引。SQL Server 2005引入了在表中存
储本机XML的功能,凭借这一功能可以在该XML上建立索引,帮助定位和检索XML文
本中的特定数据。XML数据在SQL Server数据库中存储为Binary Large Object(BLOB,二
进制大型对象)。要在XML文档中搜索特定的元素、属性或者值,SQL Server必须首先打 开 BLOB,然后将其内容拆解幵。SQL Server通过拆解操作创建一个自己可以导航的XML 对象的集合。它实质上是提取了 XML的数据结构,然后将其存储在临时的关系结构中。
和对应的关系索引一样,XML索引会有一些开销,但是XML索引的开销比普通索引
更大。因此,应该只对那些XML数据很少修改的列使用XML索引。
通常,比起插入和修改文档的组件,使数据库应用程序存储和检索完整的XML文档
更为有效,因为前者会导致文档散开。不过有一些业务却需要这种功能,通过创建XML
索引避免了拆解完整文档。
从本质上来说,XML索引是链接至表的主键的XML数据的预拆解部分。XML索引有4
种。第一种XML索引必须是一个主XML索弓I。在主索引上可以创建3 个辅助索引。每个附
加的索引类型会提髙特定类型的査询的XML查询性能,但同时也会影响XML数据的修改。
主 XML索引
主 XML索引实际并不是构建在XML列上,而是构建在内部表(在索引创建过程中创
建)之上的聚集索引。这个内部表称为节点表。贫点表直接链接至在其中创建XML索引的
表的聚集索引。要创建一个XML索引,具有XML列的表必须在其主键匕有一个聚集索引。
我们并不能直接访问用来支持主XML索引的节点表,但是可以使用系统视图查看与其相
关的信息。主 XML索引存储XML字段的关系表示形式,并协助査询优化器创建高效率的
查询计划,以便从XML字段中提取数据。创建主XML索引的语法的例子如下所示:
USE AdventureWorks2008 GO
CREATE PRIMARY XML INDEX XML_IX Illustration ON Production.Illustration (Diagram)
也可以在Management Studio中使用图形化方式创建主XML索引。要创建一组新的 XML索引,需要首先创建一个表。要创建包含XML列的Person.Person表的副本,可以执 行下列代码创建MyPerson表,然后在主键上创建一个聚集索引,这个索引是创建XML索 引所必需的。
USE AdventureWorks2008 GO
SELECT * INTO dbo.MyPerson FROM Person.Person
GO
ALTER TABLE dbo.MyPerson ADD CONSTRAINT PK_MyPerson BusinessEntityld PRIMARY KEY CLUSTERED (BusinessEntityld)
在创建好表之后,可在“对象资源管理器”中依次展开“AdventureWorkCOOS数据库”、
“表”以 及 “dbo.MyPerson表 ”节点。
8 .维护表
现在我们已经更深入地了解了数据在表中的组织方式和优化数据检索的方法,接下来
讨论如何维护这个环境。表的维护可分为两种基本类别:
• 索引的维护
• 索引统计信息的创建和维护
索引碎片化
査询性能不佳的一个主要原因是索引维护不善。索引在更新时会变得支离破碎,这是
因为索引是一个连续的、排序的数据集合。要维护索引的排序顺序,SQL Server必须分割 完整的数据页以容纳更多的数据。
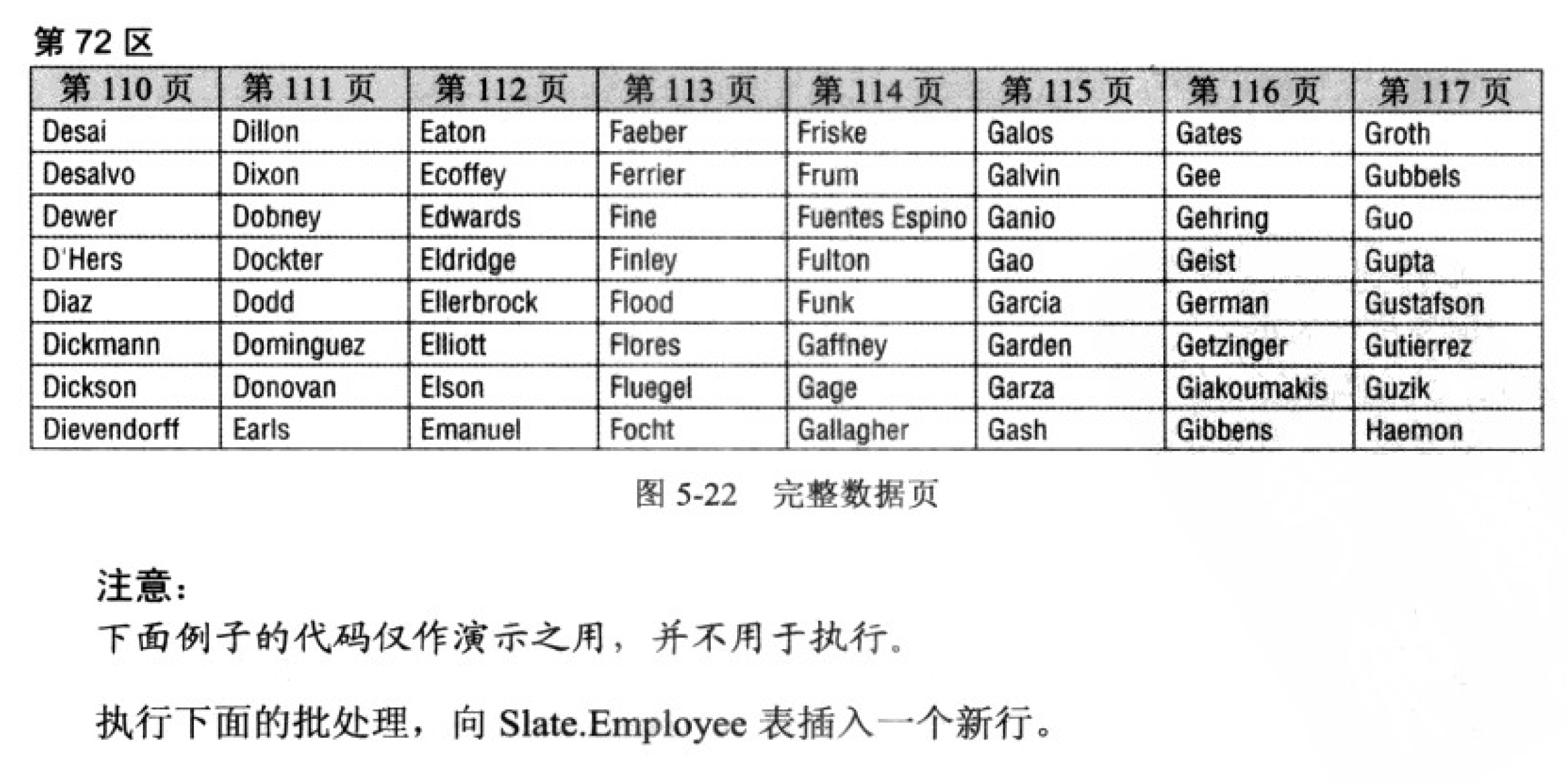
例如,第 72区(如图5-22所示)包含一个在虚构的Slate.Employee表的LastName列上
定义的聚集索引。该区中每一个数据页都是完全填满的。
例如,假定我们有一个名为Contacts的表,在其Contactld列上定义了一个聚集索引, 在 其 LastName列上定义了一个非聚集索引。非聚集索引叶节点将包含索引值和聚集键。
当使用LastName作为谓词执行一个需要Contactld、FlrstName和 LastName列的査询时,
LastName上的非聚集索引将用于定位记录,但将只包含两个需要的列,即 LastName和
Contactld。然后,SQL Server必须遍历聚集索引来为找到的每个记录检索F"irstName,值。
INSERT Slate.Employee (LastName, FirstName, Title, EmailAddress, Phone, ModifiedDate) VALUES
( ’F lin ts to n e * , ’F re d ’ , 'M r .*/ * fre d f@ sla te g ra v e l.c o m ', * 1 2 3 -4 5 6 -7 8 9 0 ', GETDATEO )
接着就会发生页拆分。这是因为数据页上已经没有空间容纳新记录。为了维护行的顺
序,SQL Server拆分了第H 3页,然后将大约50%的行移动到一个新的未分配的数据页(如 图 5-23所示)。

由于该页被拆分,当 3(51^6〜灯读取数据页以检索8以6上1!^1(^6 表的内容时,它必
须从第72区切换至第119区,然后再回到第72区以继续扫描行。添加了更多雇员之后,
就会出现更多的页拆分。这些页拆分导致产生了索引碎片。索引的碎片化将最终导致SQL
Server在检索数据时执行过量的读取,从而造成査询性能低下。 要检査表上的所有索引或一些特定索引的碎片,可以使用动态管理函数sys.dm_db_index_ physical^tats。此函数会返回表的索引的大量信息,包括每个数据页上的数据量、 引G 叶级和非叶级上的碎片量,以及索引中记录的平均大小。
当査询这个表值函数时,我最感兴趣的数据是碎片级别和每一页填充的平均百分比。
碎片级别可让我们知道需要重建哪些索引,而数据页的填充程度会告诉我们何时会发生更
多的页拆分。可以使用下列语法査询sys.dm_db_index_physical_stats动态管理视图。
SELECT {* | column l i s t } FROM s y s . d m _ d b _ in d e x _ p h y s ic a l_ s ta ts ({d a ta b a s e _ id | NULL} “ o b je c t一id | NULL} ,{ in d e x _ id | NULL} , {p a rtitio n _ n u m b e r , NULL} , {mode | NULL | DEFAULT} 如该语法所示,检索索引信息时,需要向sys.dm_db_index_physical_stats函数传递5 个
参数。表 5-2描述了这些参数。

要实际检査和维护索引,可以运行下列命令,创建将在下面几个例子中使用的
MyPersons 表:
USE AdventureWorks2 0 0 8
GO
SELECT BusinessEntityIdr LastName, FirstName, Title, ModifiedDate INTO dbo.MyPersons FROM Person.Person CREATE CLUSTERED INDEX IXMyPersonsLastName ON dbo.MyPersons(LastName)
要査询sys.dm_db_index_physical_stats视图来返回所有和MyPersons表相关的可能的数
据,可以使用如下
DECLARE @dbID smallint, QobjectlD int SET QDblD =DB__ID (1 AdventureWorks2008 ') SET QObjectlD =OBJECT_ID(*dbo.MyPersons*)
SELECT *
FROM sys.dm_db_indexjphysical_stats(@DbIDr @ObjectIDr NULL, NULL , * DETAILED*)
但是,运行此查询所返回的信息要比所需的多。因为最感兴趣的只是索引叶级的碎片
和数据页的填充百分比,所以可以限制返回的数据量。之所以不那么关注非叶级,是因为
它们通常很小。索引非叶级确实可能变得非常零碎,但这些碎片对于性能的影响远不如叶
级的影响。
要想减少sys.dm_db_index_physical_stats査询返回的信息,可以限制为仅返问感兴趣
的列和索引的叶级的信息,如下所示:
DECLARE @dbID smallint, QobjectID int SET @DbID =DB__ID (* AdventureWorks2008 ') SET @ObjectID =OBJECT_ID(1dbo-MyPersonsf )
SELECT index_idr avg_fragmentation_in_percentr avg_page_space_used_in_percent FROM sys.dm_db_index_physical__stats(@DbID, QObjectID, NULL, NULL , 'DETAILED') WHERE index_level =0 Results:
index_id avg_fragmentation_in__percent avg_page_space_used_in_percent
1 0 98.9983815171732
这个査询仅返冋碎片级别和用于索引叶级的页空间,这是最严重的碎片化(就性能而言)
会发生的地方。
作为一个度量标准,碎片化的准确定义是:下一物理页不是 下 一 逻辑页的页百分比,
如图5-24所示。

MyPersons表包含19 972行。现在在MyPersons表中插入更多记录。下列脚本插入了 3 994行额外的记录,行数由此增长了 20%:
INSERT dbo.MyPersons (BusinessEntityld, LastName, FirstName, Title, ModifiedDate) SELECT BusinessEntityld, LastName, FirstName, Title, ModifiedDate FROM Person.Person WHERE BusinessEntityld % 5 = 4
现在,査询sys.dm_db_index_physical_stats动态管理视图返回了一些很有趣的数据:
DECLARE @dbID smallint, QobjectID int SET @DbID =DB_ID(»AdventureWorks2008 ') SET QObjectlD =OBJECT_ID(•dbo.MyPersons*) SELECT index一id, avg_fragmentation_in_j>ercentr avg_page_space_used_in_percent FROM sys.dm_db_index_physical stats(QDbID, @ObjectID, NULL, NULL , •DETAILED1) WHERE index_level =0
RESULTS:
index_id avg_fragmentation_in_percent avg_page_space_used_in_percent
1 97.8571428571428 59.4185322461082
由于向MyPersons表添加了额外的行,在 SQL Server读取数据页时,下一物理页不 是下一逻辑页的情况约占97%。除了碎片之外,现在数据页只有59%的空间得到填充。
碎片化索引和部分填充的数据页使得在只需读取约40个逻辑区时,SQL Server读取274 个逻辑区。通过一个叫做DBCC SHOWCONTIG的已弃用的数据库控制台命令(DBCC,
Database Console Command)可以获得这一信息。在 SQL Server的未来版本中,DBCC
SHOWCONTIG将被删除,不过目前可以看一下它所提供的有关MyPersons表的信息:
USE AdventureWorks2008
GO
DBCC SHOWCONTIG(* dbo.MyPersons1)
RESULTS:
- Pages Scanned................................: 280 - Extents Scanned..............................: 38 - Extent Switches..............................: 274 - Avg. Pages per Extent........................: 7.4 - Scan Density [Best Count:Actual Count].......: 12.73% [35:275] - Logical Scan Fragmentation ..................: 97.86% - Extent Scan Fragmentation ...................: 13.16% - Avg. Bytes Free per Page.....................: 3284.7 - Avg. Page Density (full).....................: 59.42%
提示:
尽管在过去,DBCC表示的是Database Consistency Checker,但现在许多DBCC命令不 只是用于检查数据库一致性。因此,DBCC也作为Database Console Command的缩写。 DBCC SHOWCONTIG命令表明SQL Server扫描了 38个区来检索MyPersons表中所
有的数据,但要扫描这38个区段,SQL Server必须在它们之间切换274次。 SQL Server使用索引快速査找数据页中的行以进行读取、更新或删除。但是,如果只 是要在表中插入数据,那就不需要索引。一般来说,索引有助于提高读取性能,但是会降
低插入性能。这里有一个类比可供参考。
我在处理家装事务时是一个非常懒散混乱的人。我总是不能把用过的工具等物品归回
原位。结果就是每当我完成某个家居工程后,我用过的一切工具全都乱扔在我的工作台上。
其实把工具整理好放回原处并不会花费我很长时间。但是当我开始下一个工程时,我总是
要把大量的时间耗费在找到锤子这类事情上。有时候我甚至会绝望得打算去买一个新的工
具。家装商店相当欢迎我。其实只要我额外花一些时间把东西归回原位,我就可以节省大
量时间和金钱。
数据库也是如此。规划和构建索引需要时间和精力;建成之后维护索引也是如此。然
而,即使插入和更新操作最密集的数据库,通常每写操作1次都要读取5 次。这意味着要
把索引维持在最髙性能需要付出5 倍的代价。这一点要牢记。现在看如何减少索引碎片以
及在出现碎片时如何纠正。
使用填充因子减少碎片
为减少页拆分产生的碎片,数据库管理员可以设计或重新生成索引,使数据页不会完
全填充。为此,可以使用“填充因子' 当建立或重新生成索引时,可以指定填充因子百分
比。如果一个索引页只有90%被填充,那么只有插入更多的索引时才会导致页拆分,所以
产生碎片的时间会久一些。对于前面的例子,看一下填充数据页至90%会产生什么样的影
响(如图5-24所示)。
可以看到,数据页没有被完全填满,添加更多的联系人不会很快导致页拆分。填充因
子只有在建立或重新生成索引时才有效。执行了 •些插入之后,索引会再次被填满,页拆
分也会发生。然而,页拆分并不会立即发生,而重新生成索引之间的时间得以延长。
只是部分填充索引页仍然会有缺点。因为页未完全填充,存储索引所需的磁盘空间量
会增加。另外,由于每页的数据较少,检索数据所需的读取次数将增加。因此,如果设定
了填充因子,返回的信息肯定会有一定的减少。我个人认为,索引的填充因子最好不要低
于 90%。在更新和查询都很频繁的表上,这个比例可以低至85% ,但要记住,若填充因子
为 8 5 % ,与填充因子为100%时的情况相比,SQL Server将要多进行15%的读取来检索记 录。因此,一个10 %的碎片级别可能和一个90%的填充因子的影响相同。
去除碎片
要去除碎片,可以有3 种方法:删除并重新生成索引、原地重新生成索引或重新组织索引。
每种方法都有其优点和缺点。删除和重新生成索引选项和CREATE INDEX命令一起使用,而
重新生成和重新组织选项和ALTER INDEX命令一起使用。下面介绍如何使用这3 种方法。
使 用 DROP_EXISTING选项创建索引
删除并重新i 成索引的最主要优势在于,几乎所有有关索引的东西都是可以改变的。 例如,在其上定义索引的列可以改变、索引的FILLFACTOR可以改变,或者只要不存在聚
集索引,索引可以从非聚集索引变为聚集索引。然而,在 使 用 DROP_EXISTING选项和
CREATE INDEX命令时,必须指明一个具体索引。当使用ALTER INDEX命令的重新生成
或重新组织选项时,表上的所有索引都可以立刻指明。
使用DROP_EXISTING选项重新生成索引可以按照索引顺序重建所有的索引页,从而
去除索引碎片。它还可以压缩索引页,从而填充由页拆分生成的空间。索引的叶级和非叶
级也都可以重新生成。
下面是使用CREATE INDEX命令删除和重新生成索引的语法的例子:
CREATE UNIQUE CLUSTERED INDEX PK_Address AddressID ON Person.Address(AddressID) WITH (FILLFACTOR =90, DROP_EXISTING =ON)
重新生成索引
当使用ALTER INDEX命令重新生成索引时,SQL Server实际上和CREATE INDEX
命令一样删除并重新生成了索引。区别在于它不能改变已存在的索引的列,也无法改变索
引类型。然而,它可以修改FILLFACTOR。而且,只需在表上执行该命令一次就可以重新
生成该表的所有索引。
另一个非常有用的功能是ONLINE选项。如果打幵了 ONLINE选项,SQL Server就不 会把任何长期锁存放在被索引的表上,从而大大降低了对用户性能的影响。为此,SQL
Server利用tempdb数据库创建和维护索引。可以在tempdb数据库中创建或重新生成索引, 然后把它移动到合适的数据库中。这会减少对数据库中用户的影响,但可能导致tempdb 数据库意外增长。只有企业版和开发人员版的SQL Server中有ONLINE索引选项。
和 DROP_EXISTING选项一样,ALTER INDEX的 REBUILD选项重新生成索引的叶
级和非叶级。
下面的例子重新生成了一个单独的索引,然后重新生成了一个表中的所有索引,设置
的 FILLFACTOR为 90,并且打开了 ONLINE选项:
USE AdventureWorks2008 GO
ALTER INDEX AK_Product_ProductNumber ON Person.Product REBUILD WITH (FILLFACTOR=90,ONLINE=ON)
USE AdventureWorks2008 GO
ALTER INDEX ALL ON Person.Product REBUILD WITH (FILLFACTOR=90 r ONLINE=ON)
重新组织索引
重新组织索引消耗的系统资源最少,但不如重新生成索引来得彻底。当SQLServer重 组索引时,它重新安排并压缩数据页,使其逻辑顺序和物理顺序保持一致。索引重新组织
只影响索引的叶级,并且总是联机执行。
30%的碎片级别可以帮助确定重新组织索引还是重新生成索引。如果碎片级别小于或
等于30% ,那么重新组织花的时间和消耗的系统资源会比重新生成少。如果大于30% ,重
新组织索引花费的时间将极有可能比重新生成更长,但消耗的资源仍然是比较少的。
一般来说,如果使用合适的FILLFACTOR定期重新生成索弓I ,在此期间就没有必要进
行那么多次的重新组织索引。然而,髙事务活动的间隙可能需要介入一次重新组织,以防
止碎片超过30%而造成性能问题。
统计信息
SQL Server使用统计信息寻找从数据库表中检索数据的最有效方式,它存储了有关列 中数据的选择性以及分布情况的信息。可以手动或自动创建统计信息。第 10章详细介绍了
这方面的内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号