

4 .3 .4 常见高CPU利用率的原因
2018-06-30 17:16 笑一笑十年少!!! 阅读(772) 评论(0) 编辑 收藏 举报4 .3 .4 常见高CPU利用率的原因
存在髙CPU利用率的问题类型有很多种,但是我们可以关注一些常见类型,至于其他
极端类型暂时不包含。以下便是高CPU利用率的常见类型:
□缺失索引(Missing Index)
□统计信息过时
□ 非 SARG查询
□ 隐式 转 换 (Implicit conversions □ 参数嗅探(Parameter sniffing)
□非参数化Ad-hoc査询 □非必要的并行查询
下面分别介绍一下。
1 . 缺失索引
缺失索引是最常见的引起髙CPU和 I/O利用的原因之一,当没有合适的索引用于支
持查询时,一般只能通过大面积扫描来获取所需的信息。一方面,这种扫描会造成SQL
Server需要处理很多非必要的数据;另外一方面,由于需要加载很多非必要的数据到内存, 因此会引起内存压力,导致计划缓存被移除,更严重的是引起SQL Server必须重新编译、 优化查询,编译和优化也是高CPU开销操作。下面来看个例子,执行如下语句。
USE AdventureWorks2008R2 GO
SET STATISTICS TIME ON;
SET STATISTICS IO ON;
SELECT per.FirstName , per.LastName , p.Name , p .ProductNumber , OrderDate , LineTotal • soh.TotalDue FROM Sales.SalesOrderHeader AS soh INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderlD = sod.SalesOrderlD INNER JOIN Production.Product AS p ON sod.ProductlD = p.ProductID INNER JOIN Sales.Customer AS c ON soh.CustomerlD = c.CustomerlD INNER JOIN Person.Person AS per ON c.PersonlD = per.BusinessEntitylD WHERE LineTotal > 25000
SET STATISTICS IO OFF;
SET STATISTICS TIME OFF;
得 到 下 面 的 信 息 ,
SQL Server执行时间:
C P U 时间= 0 毫秒,占用时间= 0 毫秒。
SQL Server执行时间:
C P U 时间= 6 2 毫秒,占用时间= 9 7 毫秒。
SQL Server执行时间:
C P U 时间= 0 毫秒,占用时间= 0 毫秒。
可以看到,由于缺少索引,CPU需要花费很多时间去获取不必要的数据。我们可以创
建一个索引,然后再看看结果。
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_LineTotal ON Sales.SalesOrderDetail (LineTotal)
索 引 后 结 果 如 下 ,
SQL Server执行时间:
CPU时间= 0 毫秒,占用时间= 0 毫秒。
SQL Server执行时间:
CPU时间= 0 毫秒,占用时间= 1 毫秒。
SQL Server执行时间:
C P U 时间= 0 毫秒,占用时间= 0 毫秒。
有了索引,占用时间几乎为0 , 可见效果很明显。在本人的工作经历中,缺失索引是最
常见的CPU消耗原因。
2. 统计信息过时
SQL Server优化器借助统计信息来预估查询情况,如果统计信息过时、不准 确 ,会导 致优化器产生不合适的执行计划,比如表中只有几万数据,而统计信息显示有几亿,这时
候优化器可能会选择hash连接,这将加大各方面的资源开销。对于这类问题,可以在通过 执行计划来查看,如果一个查询,你明知道它返回和处理的结果集都很小,而优化器却选
择了 hash连接,那么这时就可以检查一下图形化执行计划中是否有黄色叹号,或者用文本 化执行计划看看预估和实际行数的差异是否很大。如果是,可以使用UPDATE STATISTICS
语句更新统计信息,同时检查为什么统计信息过时。
3. 非 SARG查询
SARG是 Search Argument的缩写。简单来说,如果一个谓词(特别是WHERE条件
中)能用到索引查找操作,就可以理解为符合SARG。但是如果在WHERE条件所用到的
列中使用了标量函数(YEAR、UPPER等),或者使用了 LIKE •%%’这类的查询,就称为非
SARG査询,会导致索引无效。这些非SARG的写法使得SQL Server只能进行表或者索引 扫描,结果类似于缺失索引,所以同样会引起CPU高利用。下面是典型的非SARG查询:
SELECT soh.SalesOrderlD , OrderDate , DueDate , ShipDate , Status , SubTotal ,
TaxAmt ,
Freight , TotalDue FROM Sales.SalesOrderheader AS soh INNER JOIN Sales.SalesOrderDetail AS sod ON soh.SalesOrderlD = sod.SalesOrderlD WHERE CONVERT (date, sod.ModifiedDate) = *07/01/2005'
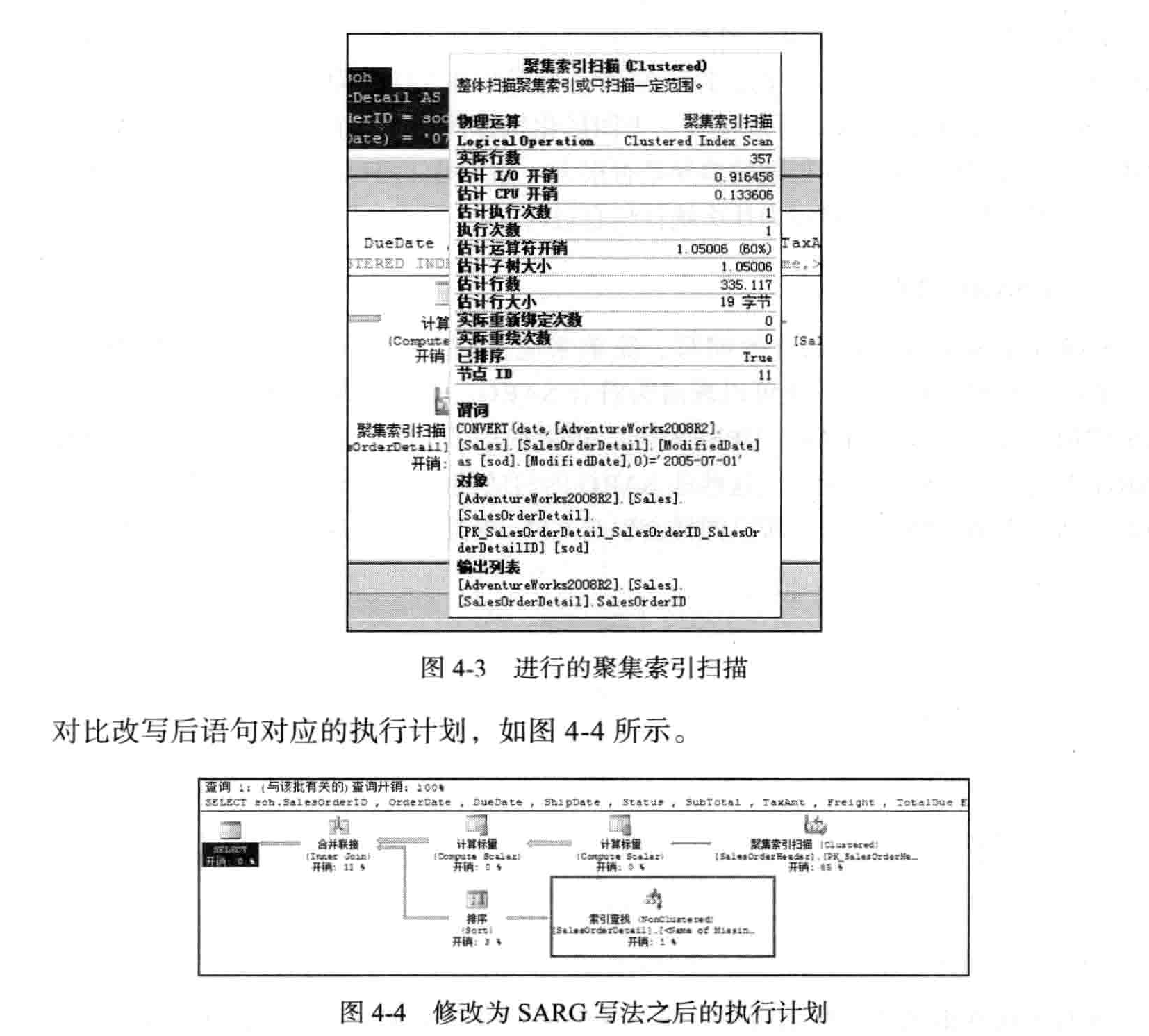
查看上面查询的执行计划可以看出,这里进行的是聚集索引扫描,如图4-3所示。但
本来是可以进行聚集索引査找的。
面对这类问题时,可以对语句进行改写。
SELECT soh.SalesOrderlD , OrderDate , DueDate , ShipDate , Status , SubTotal ,
TaxAmt ,
Freight , TotalDue FROM S a l e s . S a le s O r d e r h e a d e r AS so h INNER JOIN S a le s . S a le sO rd e rD e ta il AS sod ON so h .S alesO rd erlD = so d .S alesO rd erlD WHERE s o d . M odifiedD ate >= * 2 0 0 5 -0 7 -0 1 0 0 :0 0 :0 0 .0 0 0 * AND s o d . M odifiedD ate < * 2 0 0 5 -0 7 -0 2 0 0 :0 0 :0 0 .0 0 0 *
另外,常见的非SARG查询还包括对where条件中的列使用一些如UPPER/LTRIM/ ISNULL之类的标量函数。对于这类情况,绝大部分情况下通过改写查询都能解决。
4 . 隐式转换
隐式转换(执行计划中会出现Implicit conversions)指一个查询的FROM/WHERE子句
中,用于关联或判断的列之间数据类型不相等,导致优化器需要根据数据类型的优先级高
低进行类型转换然后再优化、执行。由于SQL Server无法匹配不同类型的数据,所以需要 先将它们转换成相同类型再进行匹配。这个步骤发生在查询执行过程中。但是如果出现这
种情况,会导致查询转变成非SARG查询,从而出现类似上面介绍的问题。比如下面这个
查询:
SELECT p .FirstName , р . LastName , с. AccountNumber FROM Sales.Customer AS c INNER JOIN Person.Person AS p ON c.PersonlD = p.BusinessEntitylD
WHERE AccountNumber = N*AW00029594'执行上面的语句,并查看实际执行计划中
的图标属性,如图4-5所示。
、
在图4-5中,加框部分就是查询需要把varchar类型隐式转换成nvarchar类型。解决这 类问题最好的方法是在设计过程中就先考虑数据类型,并且确保在where条件中变量、参 数、常量等都和数据列的类型一致。如果无法做到,可以考虑在传人where条件之前先进 行屋式数据类型转换。
5 . 参数嗅探
参数嗅探( Parameter sniffing)是 SQL Server创建针对存储过程、函数或者参数化查
询的执行计划时,根据传人的参数进行预估并生成(或重用)执行计划的一个功能。通常来
说,参数嗅探方式是比较好的功能,因为可以重用计划缓存。但是有些时候,针对一个查
询的第一次传参已经产生了一个执行计划,当后续传参时,由于存在对应参数的数据分布
等问题,导致原有的执行计划无法髙效响应请求,这时候就会出现参数嗅探问题。参数嗅
探仅出现在执行计划的编译或者重编译过程中。
来看看下面这个例子:
—创建存储过程
CREATE PROCEDURE user_GetCustomerShipDates
(
@ShipDateStart DATETIME , @ShipDateEnd DATETIME
)
AS
SELECT CustomerlD , SalesOrderNumber FROM Sales.SalesOrderHeader WHERE ShipDate BETWEEN @ShipDateStart AND @ShipDateEnd
GO
--创建非聚集索引,演示完毕后请删除
CREATE NONCLUSTERED INDEX IDX_ShipDate_ASC ON Sales.SalesOrderHeader (ShipDate)
GO
— 清空缓存
DBCC FREEPROCCACHE
EXEC user_GetCustomerShipDates * 2005/07/08 *, *2008/01/01'
EXEC user_GetCustomerShipDates * 2005/07/10', 12005/07/20 *

从 图 4-6可以看到,虽然在ShipDate上有索引,但还是进行的聚集索引扫描。这是因 为在第一个存储过程的参数中,查询条件的时间范围几乎包括了全表的所有时间,另外由
于非聚集索引没有覆盖查询(在第6 章介绍),因此使用了聚集索引扫描操作。而第二个存
储过程仍然会沿用上面的执行计划,但是实际上它只需要查询十天的数据,按理是不应该
存在扫描,可它还是进行了聚集索引扫描。现在把上面的存储过程顺序调换一下,注意先
清空计划缓存。
DBCC FREEPROCCACHE -清空计划缓存,避免原有执行计划对本例造成影响
EXEC user_GetCustomerShipDates '2005/07/10', ,2005/07/20'
EXEC user_GetCustomerShipDates '2005/07/08', '2008/01/01'
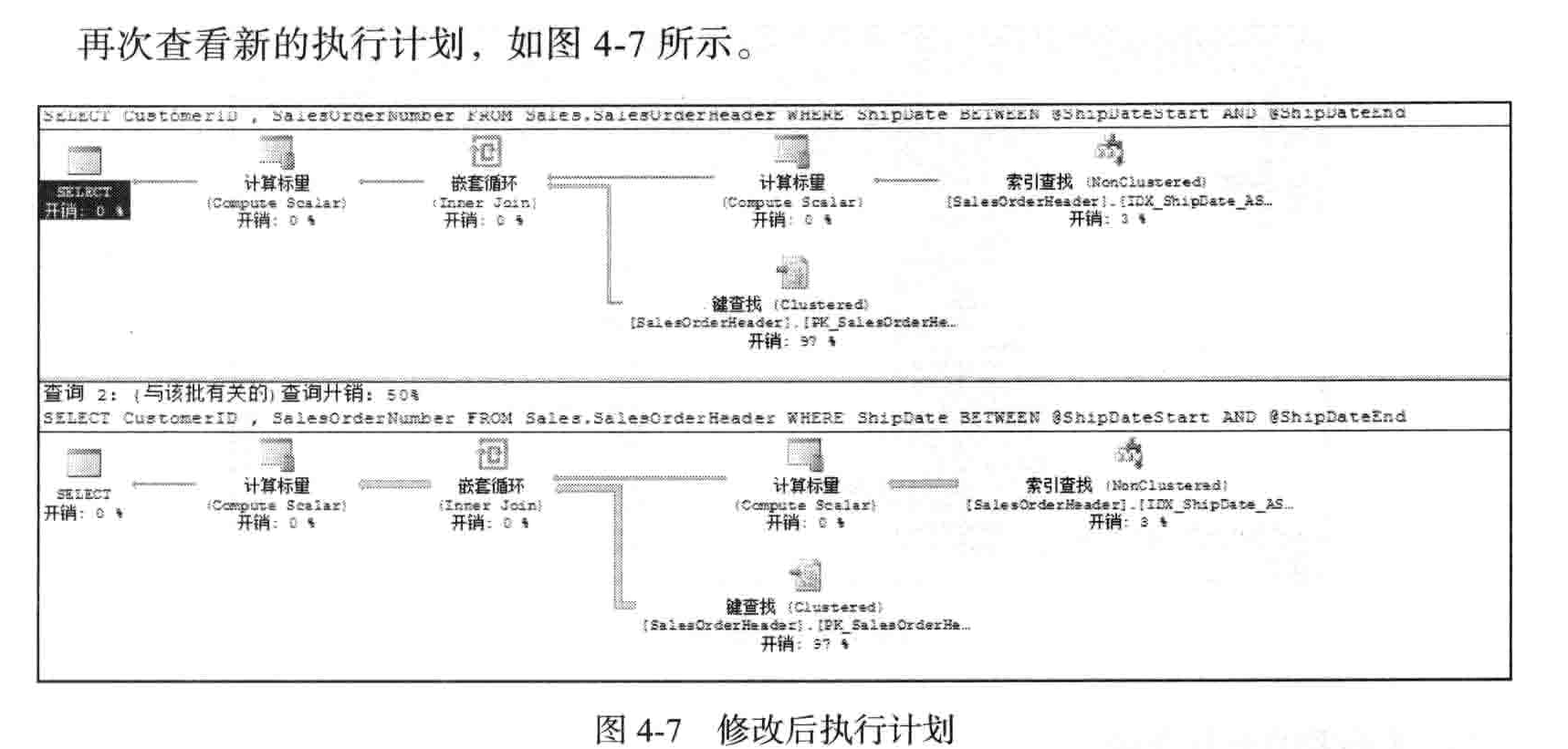
从图4-7可以看到,两个查询都使用了索引查找。如果打开SET STATISTICS IO/TIME
这两个配置,然后对比上面两次查询的CPU时间,会发现前者第一个查询的CPU时间远
大于第二个,而后者的第二个时间远大于第一个。这是因为对于范围比较大的那个参数区
间,CPU需要处理更多的数据。
对于参数嗅探问题,可以使用部分重编译、编译提示(OPTIMIZE FOR)等功能来避
免,更多的优化应该考虑数据和研究数据分布问题。
6 . 非参数化Ad-hoc查询
Ad-hoc称为即席查询,可以理解为没有使用存储过程、SP_ExeCUteSql或者其他方式强 制预定义SQL语句。这类查询会导致SQL Server每次都要检查是否有计划缓存可用于完全 匹配这些语句。在这类语句中,即使只有参数不同,都会导致CPU分别进行编译和优化。
而这将导致CPU的浪费(浪费在对本来可以重用的执行计划上),也会因为对Ad-hoc查询 分别存放执行计划(可能只会用一次)导致计划缓存空间的浪费。可以使用下面的计数器来
进行监控,看看是否存在这样的浪费。
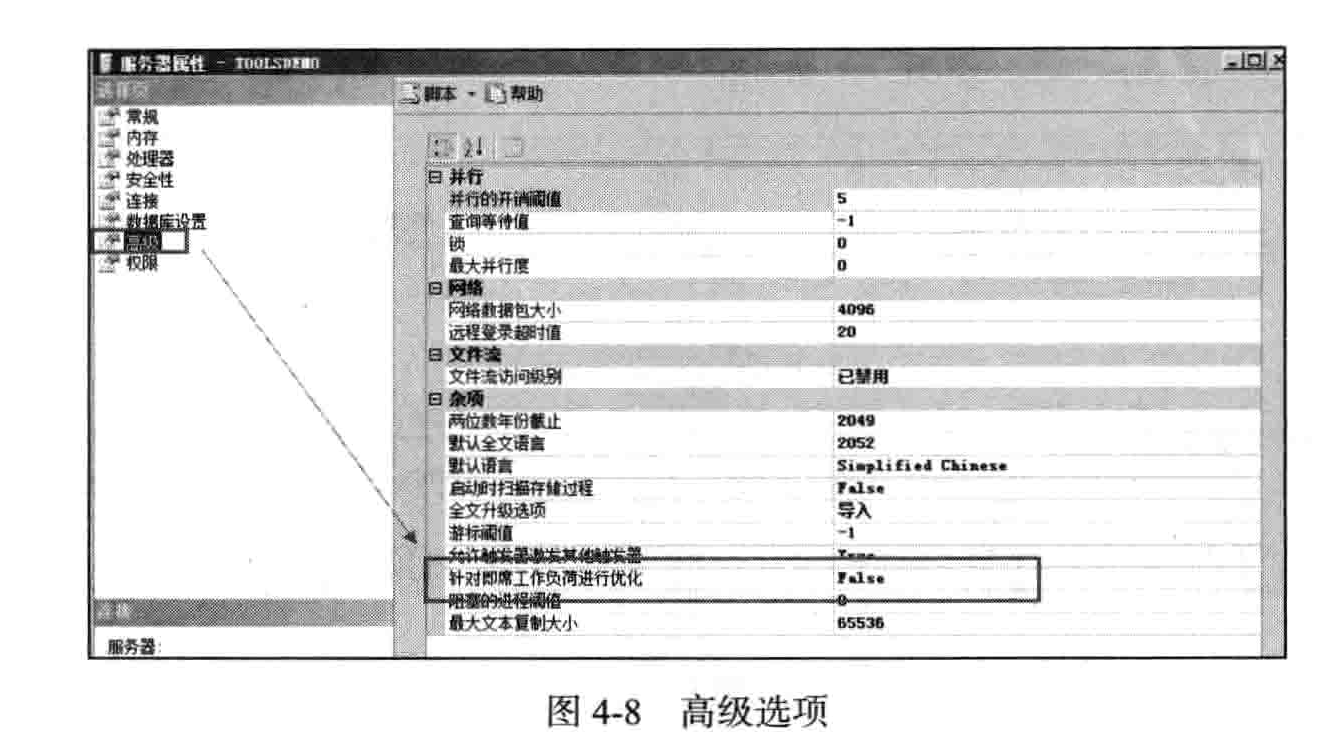
□ SQL Server: SQL Statistics: SQL Compilations/Sec □ SQL Server: SQL Statistics: Auto-Param Attempts/Sec □ SQL Server: SQL Statistics: Failed Auto-Param/Sec 如果是非参数化的A d-hoc,即不带参数的A d-hoc,比如select * from tb where id =xxx
这类查询引起了问题,在 SQL Server 2008中,可以使用图4-8所 示 的 “高级”选项来对其 进行优化。
或者在数据库层面强制参数化。
ALTER DATABASE AdventureWorks SET PARAMETERIZATION FORCED
7 . 非必要的并行查询
并行操作会把一个査询分开到多个线程中执行,然后再合并到一起返回结果。当一个
査询的开销超过cost threshold for parallelism这个阈值时(默认为5 秒),就会检查是否有可
用 的 CPU用于支持并行操作,其中,并行度取决于max degree of parallelism的值。 但是 对于OLTP系统,并行操作往往是非必需的,过多的并行执行会加重CPU的负担。可以用
下面语句来检查是否存在并行操作的执行计划。
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
WITH XMLNAMESPACES
(DEFAULT •http://schemas.microsoft.com/SQL Server/2004/07/showplan*) SELECT query_plan AS CompleteQueryPlan , n.value(•(@StatementText)[1]•, *VARCHAR(4000)*) AS StatementText , n.value(1 (QStatementOptmLevel) [1]*, ’VARCHAR(25) 1) AS StatementOptimizationLevel , n.value(*(QStatementSubTreeCost)[1]、 *VARCHAR(128)*) AS StatementSubTreeCost , n.query(•.') AS ParallelSubTreeXML , ecp.usecounts f ecp.size_in_bytes FROM sys.dm_exec_cached_plans AS ecp CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS eqp CROSS APPLY query_
plan.nodes (•/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple') AS qn ( n ) WHERE n.query(*.*).exist(*//RelOp[@PhysicalOp=M Parallelism” ]') = 1
对于存在并行操作的査询,不建议马上降低并行度,应该优化查询,使其尽可能保持
在并行开销的阈值以内。CPU髙利用的情况可能会有很多,这里只给出几个常见的类型及
对应的处理方法,在后续的章节中会陆续进行进一步的描述。

