企业生产环境-麒麟V10(ARM架构)操作系统部署Zookeeper单节点&集群版
前言:ZooKeeper是一个分布式协调服务,它为分布式应用提供一致性服务,是Apache Hadoop的子项目。它被设计为易于编程,同时具有高性能和高可靠性。ZooKeeper提供了一个简单的接口和一些基本的文件系统操作,使得开发者能够快速地构建分布式应用。
以下是ZooKeeper的一些关键特性和概念:
-
一致性:ZooKeeper保证了分布式环境中数据的一致性。它使用原子操作来确保在分布式系统中数据的一致性。
-
可靠性:ZooKeeper通过数据复制和容错机制来保证服务的可靠性。即使部分服务器出现故障,ZooKeeper也能继续提供服务。
-
有序性:ZooKeeper能够保证操作的顺序性,即使在分布式环境中,也能确保操作按照特定的顺序执行。
-
实时性:ZooKeeper提供了实时的数据更新和监控机制,客户端可以实时获取到数据的变化。
-
层次命名空间:ZooKeeper使用层次化的命名空间(类似于文件系统的路径),这使得数据的组织和管理更加直观和方便。
-
数据模型:ZooKeeper的数据模型类似于文件系统,但它的数据节点(ZNodes)可以存储少量的数据(默认不超过1MB)。
-
会话管理:客户端与ZooKeeper服务器之间建立的会话可以保持一段时间,期间客户端可以执行各种操作。
-
ACL(访问控制列表):ZooKeeper支持细粒度的权限控制,可以对不同的ZNode设置不同的访问权限。
-
分布式同步:ZooKeeper提供了分布式锁、队列等同步原语,帮助分布式系统中的节点协调操作。
-
Watcher机制:ZooKeeper允许客户端注册Watcher来监听ZNode的变化,当ZNode发生变化时,ZooKeeper会通知客户端。
ZooKeeper的应用场景非常广泛,包括但不限于:
- 配置管理:在分布式系统中动态地管理配置信息。
- 命名服务:为分布式系统中的服务提供命名和发现机制。
- 分布式锁:在分布式系统中实现锁的功能,以避免多个节点同时执行相同的操作。
- 集群管理:管理集群中的节点状态,如选举主节点等。
- 队列管理:实现分布式队列,用于任务分发和负载均衡。
ZooKeeper通常作为大型分布式系统的基础设施之一,为系统提供必要的协调和同步服务。
部署zk3.9.2单机:
安装zk,需要jdk环境,参考博客xc安装jdk篇
第一步:上传apache-zookeeper-3.9.2-bin.tar.gz包
使用ssh终端工具登录到Zookeeper服务器上。本例中安装在/mpjava目录下
第二步:配置zookeeper
1、根据zookeeper服务器在zookeeper集群的顺序,建立zookeeper实例目录。(zookeeper集群必须是奇数台)
例如:zookeeper集群有三台服务器,本服务器是第1台服务器,则在/mpjava目录下创建目录zookeeper-3.9.2,依次类推。
命令:mkdir /mpjava/zookeeper-3.9.2
2、在zookeeper-3.9.2实例目录下创建data、dataLog
命令:mkdir data dataLog
3、在data目录下创建myid文件,填入服务实例的顺序
例如本服务器是第1台服务器,则在myid中填入1,依次类推。
4、将zookeeper-3.9.2-bin.tar.gz解压到zookeeper-3.9.2目录下面
命令:tar -zxvf zookeeper-3.9.2-bin.tar.gz
5、将/mpjava/zookeeper-3.9.2/apache-zookeeper-3.9.2-bin/conf/zoo_sample.cfg文件复制为zoo.cfg文件
命令:cd /mpjava/zookeeper-3.9.2/apache-zookeeper-3.9.2-bin/conf/ && cp zoo_sample.cfg zoo.cfg
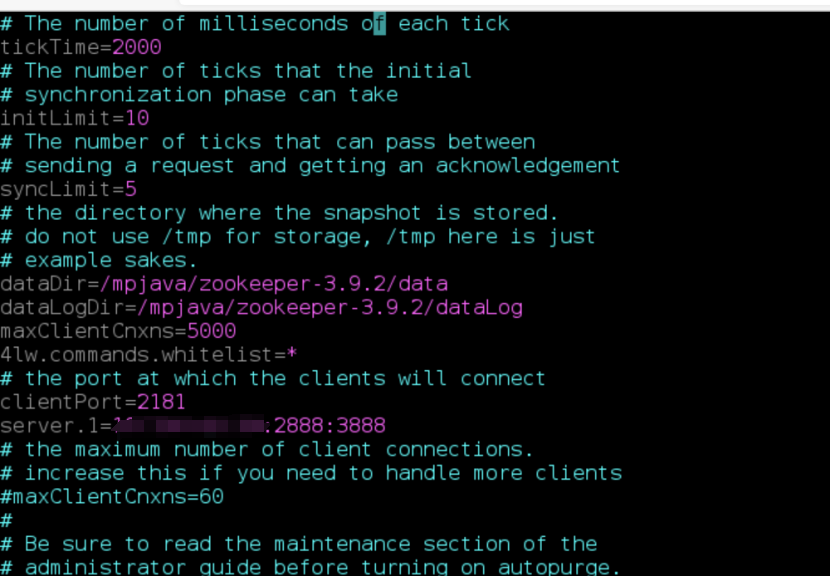
6、按照下面的说明,编辑zoo.cfg文件,并保存
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/mpjava/zookeeper-3.9.2/data
dataLogDir=/mpjava/zookeeper-3.9.2/dataLog
maxClientCnxns=5000
4lw.commands.whitelist=*
# the port at which the clients will connect
clientPort=2181 (建议默认端口)
server.1=10.0.0.8:2888:3888
注释:
dataDir目录为本zookeeper实例的data目录
dataLogDir目录为本zookeeper实例的dataLogDir目录
clientPort为客户端连接端口,保持为2181不改变。
server.1中的1为实例顺序,根据zookeeper实例序号,ip、port保持为127.0.0.1:2888:3888。
第三步:输入下面命令,执行zookeeper目录bin/zkServer.sh,启动zookeeper
命令:./zkServer.sh start
命令:jps

启动成功!
参考命令:
停止 ZooKeeper: ./zkServer.sh stop
查看 ZooKeeper状态: ./zkServer.sh status
查看 ZooKeeper 服务器的日志: tail -f $ZOOKEEPER_HOME/logs/zookeeper.log
配置单节点开机自启:
命令:vim /etc/rc.d/rc.local
添加:
export JAVA_HOME=/usr/java/jdk1.8.0_421
export PATH=$JAVA_HOME/bin:$PATH
touch /var/lock/subsys/local
/mpjava/zookeeper-3.9.2/apache-zookeeper-3.9.2-bin/bin/./zkServer.sh start
启动 rc-local:
命令:systemctl restart rc-local
命令:systemctl status rc-local
测试:export JAVA_HOME=""
命令:/etc/rc.d/rc.local start
然后reboot
部署zk3.9.2集群:
安装zk,需要jdk环境,参考博客xc安装jdk篇
部署准备工作:
第一步:修改 /etc/hosts文件
三节点:vim /etc/hosts
添加:
10.0.0.1 GH-PROD-MP-1
10.0.0.2 GH-PROD-MP-3
10.0.0.3 GH-PROD-MP-2
第二步:安装ntpdate并配置时钟同步
sudo yum update
sudo yum install ntpdate
时钟同步命令:ntpdate pool.ntp.org
第三步:关闭防火墙
修改vim /etc/sysconfig/selinux
原文件:SELINUX=permissive
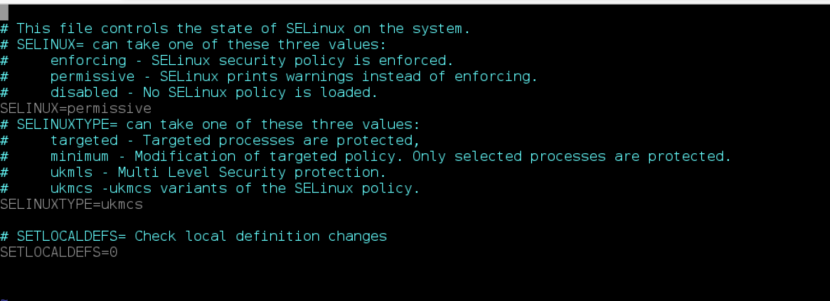
修改设置 SELINUX=disabled
命令:systemctl disable firewalld
命令:systemctl stop firewalld
第四步:将部署组件解压缩分发到各个节点
命令: mkdir /usr/lib/hadoop
命令: tar -zxvf apache-zookeeper-3.9.2-bin.tar.gz
命令: mv apache-zookeeper-3.9.2-bin zookeeper-3.9.2
第六步:修改环境变量(即在文件~/.bash_profile尾部追加下面的声明语句)
命令:vim ~/.bash_profile
export ZOOKEEPER_HOME=/usr/lib/hadoop/zookeeper-3.9.2
export PATH=$PATH:$ZOOKEEPER_HOME/bin
export ZOO_LOG_DIR=/var/hadoop/zk/logs
第六步:重启服务器
命令:reboot
部署zookeeper 集群 :
第一步:创建目录
1、创建临时目录/var/hadoop/zk/tmp(每个节点都需要配置)
2、创建日志目录/var/hadoop/zk/logs(每个节点都需要配置)
3、创建数据节点目录/var/hadoop/zk/data (每个节点都需要配置)
命令:mkdir -p /var/hadoop/zk/tmp /var/hadoop/zk/logs /var/hadoop/zk/data
第二步:修改$ZOOKEEPER_HOME/conf/zoo.cfg(在 GH-PROD-MP-1)
从模板zook_sample.cfg 复制一份配置文件zoo.cfg
命令:cp $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfg
修改配置文件:
tickTime=6000
dataDir=/var/hadoop/zk/data #数据存储路径
dataLogDir=/var/hadoop/zk/logs #日志路径
autopurge.purgeInterval=1 #快照自动清理频率,单位:小时
autopurge.snapRetainCount=3 #保存快照数量
server.0=GH-PROD-MP-1:2888:3888
server.1=GH-PROD-MP-2:2888:3888
server.2=GH-PROD-MP-3:2888:3888
第三步:编辑myid
GH-PROD-MP-1执行:echo 0 > /var/hadoop/zk/data/myid
GH-PROD-MP-2执行:echo 1 > /var/hadoop/zk/data/myid
GH-PROD-MP-3执行:echo 2 > /var/hadoop/zk/data/myid
第五步:同步配置文件到集群到其他节点(在 GH-PROD-MP-1)
命令:tar -czf conf.tar.gz conf/
命令:scp -r $ZOOKEEPER_HOME/conf.tar.gz GH-PROD-MP-2:$ZOOKEEPER_HOME/
命令:scp -r $ZOOKEEPER_HOME/conf.tar.gz GH-PROD-MP-3:$ZOOKEEPER_HOME/
第六步:启动zookeeper集群
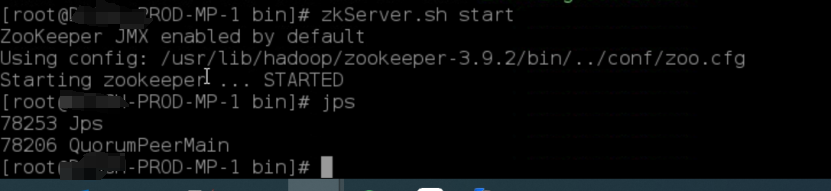
1、在GH-PROD-MP-1,GH-PROD-MP-2,GH-PROD-MP-3分别执行启动命令:zkServer.sh start
2、验证集群启动成功,分别输入:jps
GH-PROD-MP-1
GH-PROD-MP-2
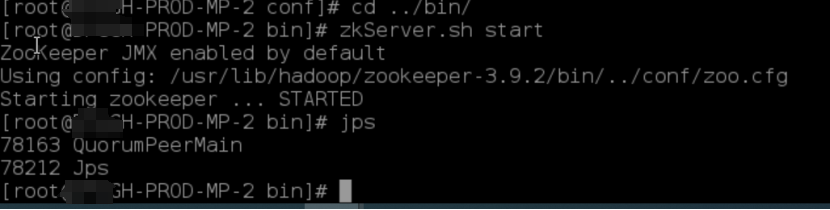
GH-PROD-MP-3
配置开机自动:
这里推荐几种不同方法(这里一和二不写具体配置了,优先推荐方法二,便于运维管理),如果无法生效就用方法三:
方法一:crontab -e
方法二:/etc/systemd/system/zookeeper.service
方法三:
命令:vim /etc/rc.d/rc.local
添加:
export JAVA_HOME=/usr/java/jdk1.8.0_421
export PATH=$JAVA_HOME/bin:$PATH
touch /var/lock/subsys/local
#!/bin/sh -e
if ! pgrep -x "zkServer.sh" > /dev/null
then
/usr/lib/hadoop/zookeeper-3.9.2/bin/zkServer.sh start
fi
exit 0
加执行权限: chmod +x /etc/rc.d/rc.local
参考命令,启动rc-local:systemctl restart rc-local
查看 rc-local状态:systemctl status rc-local
然后reboot验证

 浙公网安备 33010602011771号
浙公网安备 33010602011771号