


人工智能之深度学习基础——常见的激活函数
激活函数是神经网络中的关键组件,用于引入非线性特性,从而使神经网络能够学习复杂的模式和关系。以下是常见的激活函数及其特点、公式和应用场景:
1. Sigmoid(S 型函数)
公式:σ(x) = 1 + 1 / (e−x)
特点:
- 输出范围:(0,1)。
- 常用于二分类问题的概率输出。
优点:
- 平滑、连续,易于求导。
- 将输出限制在 0 到 1 之间,便于概率建模。
缺点:
- 梯度消失问题:在输入值较大或较小时,梯度接近 0。
- 输出不为零均值:导致较早层权重更新速度变慢。
应用场景:
- 输出层(特别是二分类问题)。
Sigmoid在逻辑回归里也有用到(LogicRegression)
2. Tanh 激活函数
公式:f(x) = tanh(x) = (ex−e−x) / (ex+e-x)
特点:
- 输出范围:(−1,1)。
- 相比 Sigmoid,输出值居中在 0 附近。
优点:
- 零均值:加快权重更新速度。
- 相对 Sigmoid 梯度较大。
缺点:
- 梯度消失问题:对于极大或极小的输入,梯度趋近 0。
- 比较慢的计算速度。
应用场景:
- 隐藏层激活函数(已逐渐被 ReLU 替代)。
3. ReLU(Rectified Linear Unit)
公式:f(x)=max(0,x)
特点:
- 输出范围:[0,+∞)。
- 非线性,但计算简单。
优点:
- 计算效率高:直接截断负值。
- 减少梯度消失问题:正区间的梯度为常数 1。
缺点:
- Dying ReLU 问题:输入为负时,梯度为 0,可能导致神经元“死亡”。
- 输出不平衡:仅有正值输出。
应用场景:
- 大多数隐藏层的默认激活函数。
4. Leaky ReLU
公式:
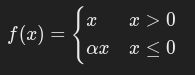
其中,α是一个小的正数(如 0.01)。
特点:
- 输出范围:(−∞,+∞)。
优点:
- 缓解 Dying ReLU 问题:为负值提供非零梯度。
- 保留了 ReLU 的优点。
缺点:
- 超参数 α\alphaα 需要手动设置。
应用场景:
- 高层网络中,替代 ReLU 使用。
5. Parametric ReLU(PReLU)
公式:
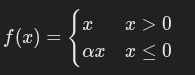
其中 α 是一个可学习参数。
特点:
- 是 Leaky ReLU 的扩展。
优点:
- 自动调整负值的斜率 α。
- 提升模型的表现能力。
缺点:
- 增加了模型的参数量。
应用场景:
- 深层神经网络。
6. Exponential Linear Unit(ELU)
公式:
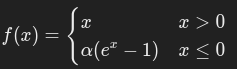
其中 α>0。
特点:
- 输出范围:(−α,+∞)。
优点:
- 负值区域平滑,解决 Dying ReLU 问题。
- 输出均值接近 0,加速收敛。
缺点:
- 计算复杂度比 ReLU 高。
应用场景:
- 对负值敏感的任务。
7. Softmax 激活函数
公式:
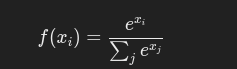
特点:
- 输出范围:[0,1]。
- 将输入转换为概率分布(所有输出的和为 1)。
优点:
- 多分类问题中适用。
缺点:
- 输出概率受所有输入值的影响。
应用场景:
- 输出层(多分类问题)。
8. Swish 激活函数
公式:
f(x) = x⋅σ(x) = x ⋅ 1/(1+e−x)
特点:
- 自然平滑,比 ReLU 更高效。
优点:
- 非单调:允许负值通过。
- 在深层网络中表现优越。
缺点:
- 计算复杂度较高。
应用场景:
- 深度学习中的复杂任务,如图像分类、自然语言处理。
9. GELU(Gaussian Error Linear Unit)
公式:f(x)=x⋅Φ(x)
其中 Φ(x) 是标准正态分布的累积分布函数。
特点:
- 结合了 ReLU 和 Sigmoid 的特性。
优点:
- 性能优于 ReLU 和 Swish。
- 平滑过渡。
缺点:
- 计算复杂。
应用场景:
- Transformer 网络,如 BERT 和 GPT。
10. Maxout 激活函数
公式:f(x)=max( w1Tx + b1, w2Tx + b2 )
特点:
- 可学习多段线性分段函数。
优点:
- 能拟合更复杂的非线性函数。
- 避免 Dying ReLU 问题。
缺点:
- 参数量增加。
- 计算复杂。
应用场景:
- 深层网络,尤其在稀疏数据场景中。
对比总结
| 激活函数 | 输出范围 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| Sigmoid | (0,1) | 简单、连续 | 梯度消失,非零均值 | 输出层(二分类问题) |
| Tanh | (−1,1) | 零均值,梯度较大 | 梯度消失 | 隐藏层(已逐渐被 ReLU 替代) |
| ReLU | [0,+∞) | 简单、高效,减轻梯度消失问题 | Dying ReLU 问题 | 默认激活函数 |
| Leaky ReLU | (−∞,+∞) | 缓解 Dying ReLU 问题 | 超参数需手动设置 | 深层网络 |
| PReLU | (−∞,+∞) | 自动调节负值斜率 | 增加参数量 | 深层网络 |
| ELU | (−α,+∞) | 缓解 Dying ReLU 问题,均值为 0 | 计算复杂度高 | 高性能任务 |
| Softmax | [0,1] | 输出概率分布 | 敏感于所有输入值 | 多分类问题的输出层 |
| Swish | (−∞,+∞) | 非单调,表现优越 | 计算复杂度高 | 高性能深度学习任务 |
| GELU | (−∞,+∞) | 平滑过渡,性能优越 | 计算复杂度高 | Transformer 模型 |
以下是激活函数的选择建议总结:
激活函数选择建议
1. 浅层网络
- 推荐:ReLU
- ReLU 简单高效,适合大多数浅层网络任务。
- 如果遇到 Dying ReLU 问题,可以尝试 Leaky ReLU 或 ELU。
2. 深层网络
- 推荐:Leaky ReLU 或 PReLU
- Leaky ReLU 缓解 Dying ReLU 问题。
- PReLU 通过学习参数自动优化,适合更复杂的网络。
3. 二分类问题的输出层
- 推荐:Sigmoid
- 将输出值映射到 [0,1][0, 1][0,1],易于解释为概率。
4. 多分类问题的输出层
- 推荐:Softmax
- 适用于多分类任务,输出概率分布(总和为 1)。
5. 对计算性能要求高的任务
- 推荐:Swish 或 GELU
- 这类激活函数更平滑且性能优于 ReLU,常用于高性能任务,如 Transformer 网络。
6. 高维稀疏数据
- 推荐:Maxout
- 能更好地拟合复杂函数,同时避免 Dying ReLU 问题。
7. 时间序列或负值敏感任务
- 推荐:Tanh 或 ELU
- Tanh 能提供零均值输出,适合对对称性敏感的任务。
- ELU 平滑处理负值,适合时间序列等需要平滑输出的任务。
总表
| 任务类型/网络结构 | 推荐激活函数 | 备选激活函数 |
|---|---|---|
| 浅层网络 | ReLU | Leaky ReLU, ELU |
| 深层网络 | Leaky ReLU, PReLU | Swish, ELU |
| 二分类问题的输出层 | Sigmoid | Softmax |
| 多分类问题的输出层 | Softmax | 无 |
| 高性能任务 | Swish, GELU | ReLU |
| 时间序列或负值敏感任务 | Tanh, ELU | Leaky ReLU |
| 高维稀疏数据 | Maxout | ReLU |
本文来自博客园,作者:z_s_s,转载请注明原文链接:https://www.cnblogs.com/zhoushusheng/p/18561472


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理