
程序分析与优化 - 8 寄存器分配
本章是系列文章的第八章,用着色算法进行寄存器的分配过程。
本文中的所有内容来自学习DCC888的学习笔记或者自己理解的整理,如需转载请注明出处。周荣华@燧原科技
寄存器分配
- 寄存器分配是为程序处理的值找到存储位置的问题
- 这些值可以存放到寄存器,也可以存放在内存中
- 寄存器更快,但数量有限
- 内存很多,但访问速度慢
- 好的寄存器分配算法尽量将使用更频繁的变量保存的寄存器中
8.1.1 寄存器分配的主要工作
- 寄存器指派
- 寄存器溢出处理
- 寄存器使用合并
8.1.2 寄存器的约束
硬盘硬件或者编译器的限制,某些值只能保存在特定的寄存器中
虚拟寄存器(程序中的变量)和物理寄存器(实际的寄存器)
calling convention(调用约定)
同一个程序点alive的多个变量必须指派不同的寄存器
8.1.3 寄存器分配与生命周期管理
最小寄存器数量 ≥ 最大生命周期变量集合
不过DCC888课程胶片里面给的这个例子,我不太认同:
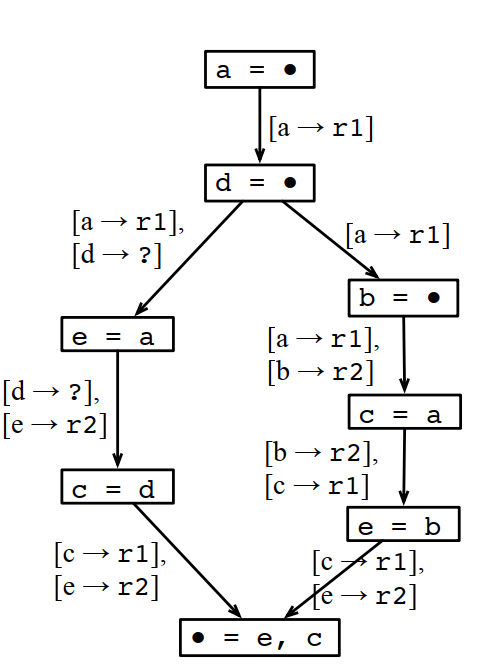
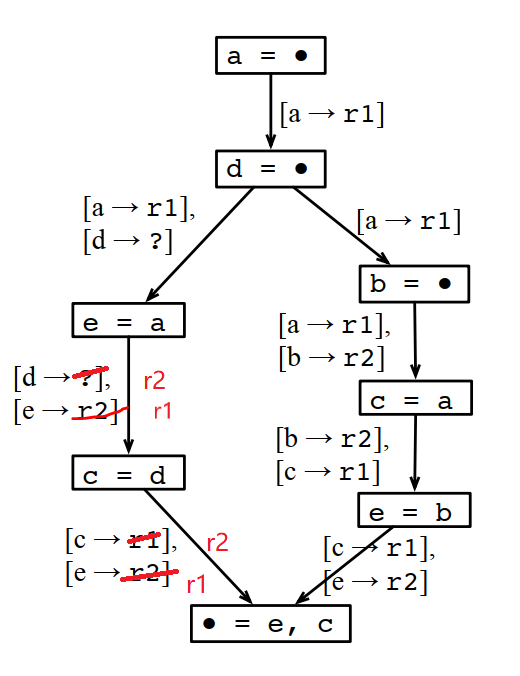
这样分配下来虽然MaxLive是2个,但MinReg需要3个。
为什么不能这样分配?因为最后输出是e和c,如果多个分支使用的e和c的寄存器不一样,那到汇聚点的时候,就没法直接用,还要做一次转移,这个转移也是需要额外的寄存器的,或者至少需要额外的计算。如果不做转移,就要插入一条store和一条load指令,这个成本更高。
8.1.4 寄存器分配是个NP完成问题
它的复杂度和逻辑等同于图的着色问题。
同样的,对于这样的CFG,同样汇聚点上输出的变量往上的多个分支中,同一个变量需要使用同样的寄存器:
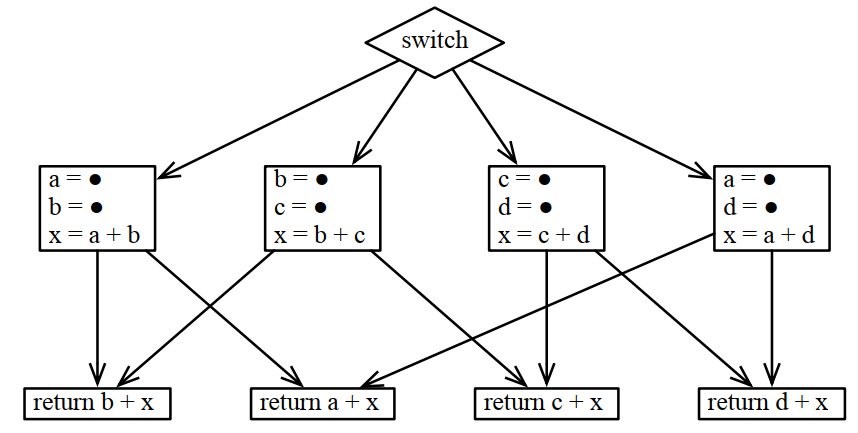
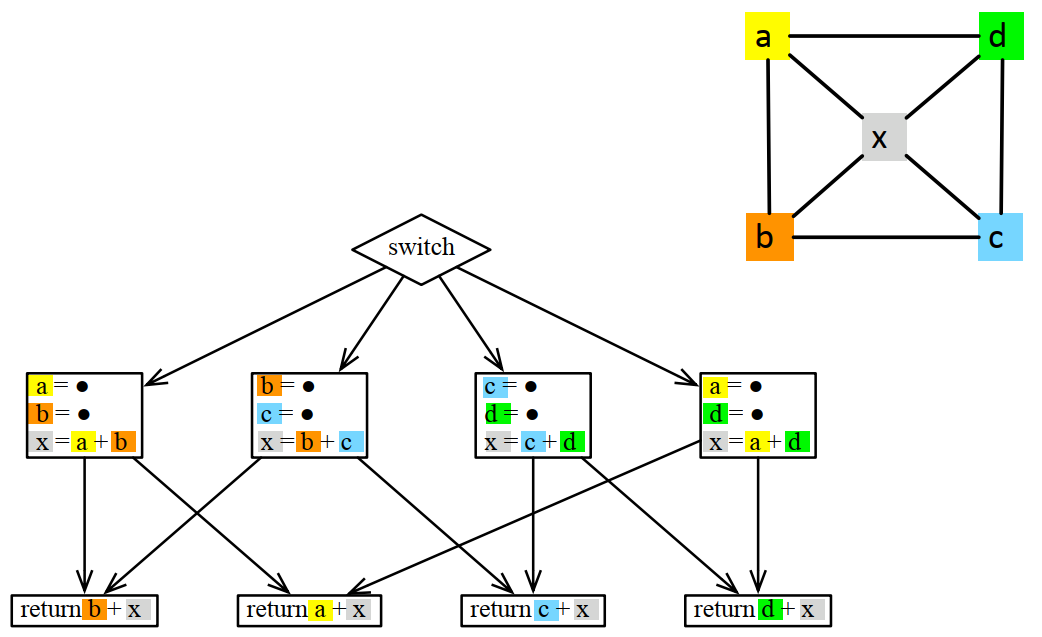
转换成着色问题的逻辑变成这样,对下面的k种颜色,需要k+1个寄存器:
8.2 线性扫描
线性扫描基于区间图的贪婪着色算法:
- 给定一个区间序列,重叠的区间必须给定不同的颜色,求最小颜色数。
- 贪婪着色有最优算法
- 但线性扫描不是贪婪着色的最优算法,而是最优算法的一个近似解。
8.2.1 基本块的线性化
通常用逆后根排序对CFG做排序生成线性化的BB块序列(前面worklist算法也用了逆后根排序,看来这个排序和程序执行之间的关系非常密切)。
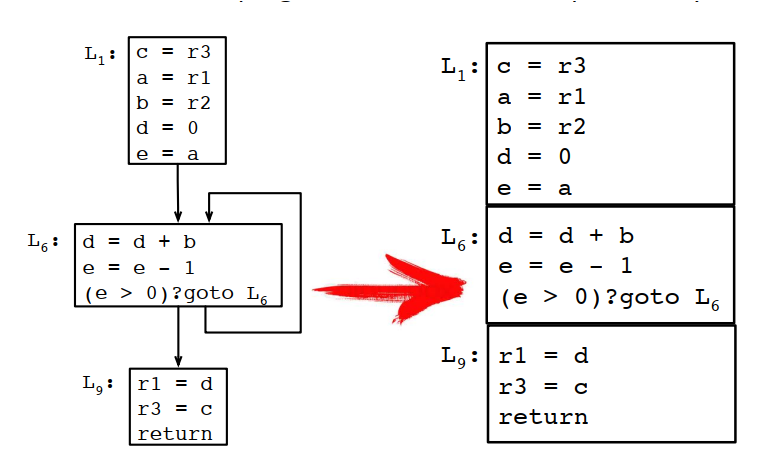
8.2.2 生成区间线
变量v的区间线Iv从v的生命期开始的程序点开始,到v的生命期结束的程序点结束。
为什么b和e的区间线要到第二个BB块最后,而不是在最后一次使用后就结束?因为后面还有分支,根据条件不同,第二个BB块还有可能从L6继续执行。
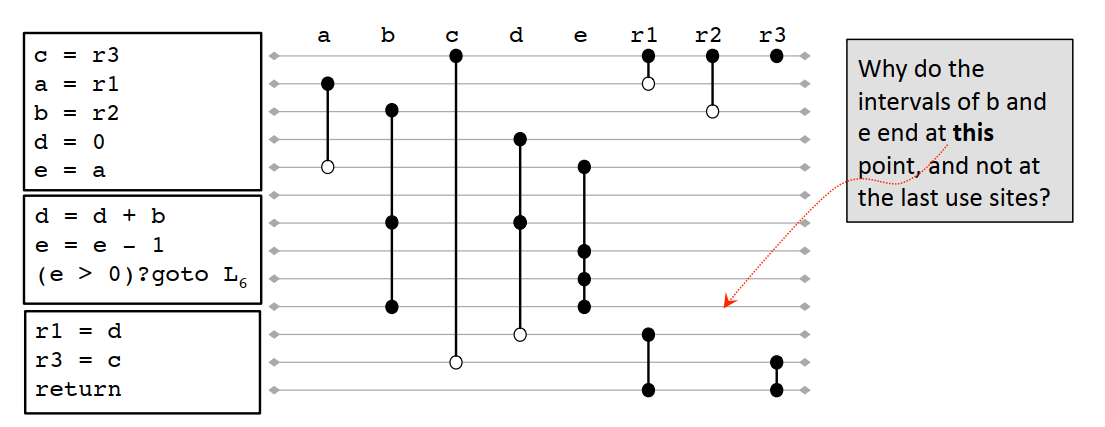
8.2.3 区间线的线性扫描算法
算法描述如下
1 LINEARSCANREGISTERALLOCATION♧ 2 active = {} 3 foreach interval i, in order of increasing start point 4 EXPIREOLDINTERVALS(i) 5 if length(active) = R then 6 SPILLATINTERVAL(i) 7 else 8 register[i] = a register removed from the pool of free registers. 9 Add i to active, sorted by increasing end point 10 11 EXPIREOLDINTERVALS(i) 12 foreach interval j in active, in order of increasing end point 13 if endpoint[j] ≥ startpoint[i] then 14 return 15 remove j from active 16 add register[j] to pool of free registers 17 18 SPILLATINTERVAL(i) 19 spill = last interval in active 20 register[i] = register[spill] 21 location[spill] = new stack location 22 remove spill from active 23 add i to active, sorted by increasing end point
上面的例程经过算法处理之后的寄存器分配结果如下:
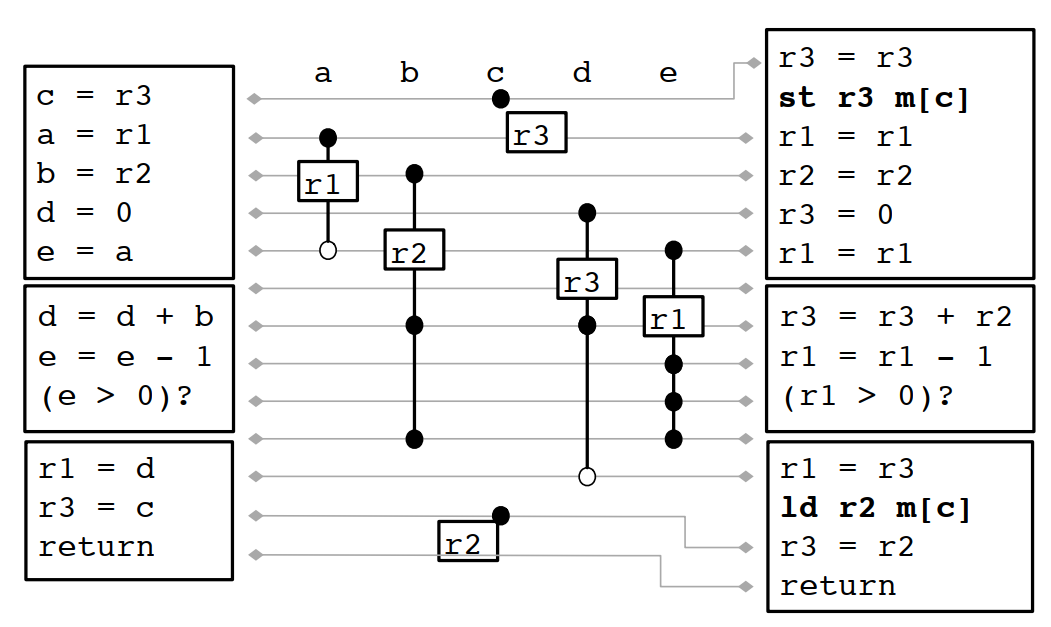
8.2.4 合并
上面的结果还不是最优解,需要经过合并
带合并过程的线性扫描算法如下:
1 LINEARSCANREGISTERALLOCATIONWITHCOALESCING 2 active = {} 3 foreach interval i, in order of increasing start point 4 EXPIREOLDINTERVALS(i) 5 if length(active) = R then 6 SPILLATINTERVAL(i) 7 else 8 if definition of i is "a = b" and register[b] ∈ free registers 9 register[i] = register[i(b)] 10 remove register[i(b)] from the list of free registers 11 else 12 register[i] = a register removed from the list of free registers 13 add i to active, sorted by increasing end point
合并之后的结果如下:

8.2.5 生命周期黑洞
线性扫描不是最优解,在一些场景下,和最优解相差还非差大,例如多个分支之间存在生命周期黑洞的情况。
例如对下面的CFG:
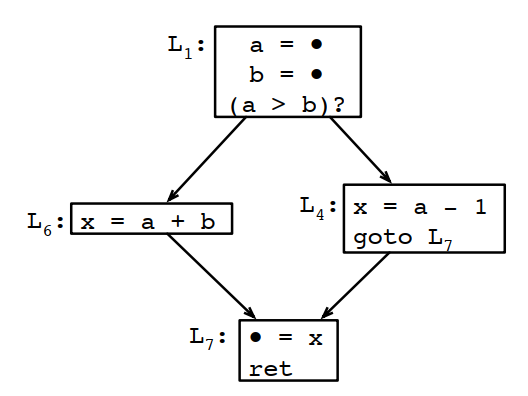
线性扫描处理的结果如下:
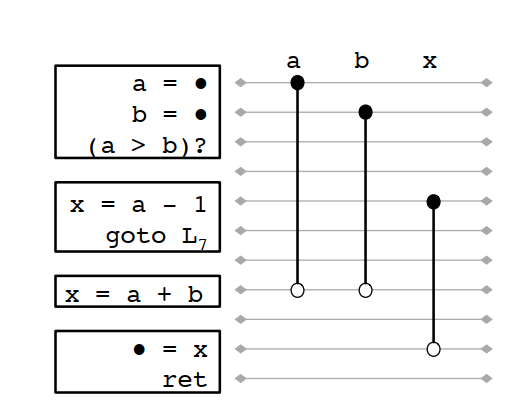
按线性扫描的结果x和a是不能共寄存器的。但如果看生命周期分析结果:
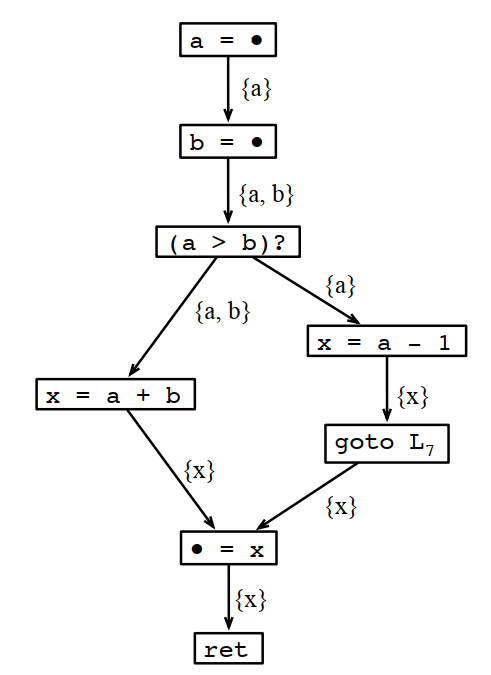
x出现后,a和b都不会再使用,也就是说x肯定是可以和a或者b共用一个寄存器的。
8.3 基于图着色的寄存器分配
8.3.1 干涉图(The Interference Graph)
最常见的寄存器分配算法家族是基于干涉图的理念推演出来的。
干涉图是基于控制流图中变量的生命周期范围的网络图:
- 每个变量是图的一个结点;
- 如果两个变量的生命周期存在重叠,则这2个节点在图上邻接,也就是存在一条边将2个节点连接起来,这样的边也称为干涉边(interference edges)。
- 除了干涉边,如果2个变量存在且仅存在一条move指令将2个变量关联起来,则在2个变量之间画一条虚线,称为合并边(coalescing edges)
8.3.2 肯普简化算法(Kempe's Simplification)
如果图中存在一个节点m,它的邻接节点小于k,设G' = G \ {m},如果G'能被k种颜色着色,那么G也能被k种颜色着色。
通过肯普简化算法,可以将图简化到只有一个节点,或者简化到只剩下一些高阶节点,这样方便求出图的最小可着色的颜色数。
下面是简化过程:
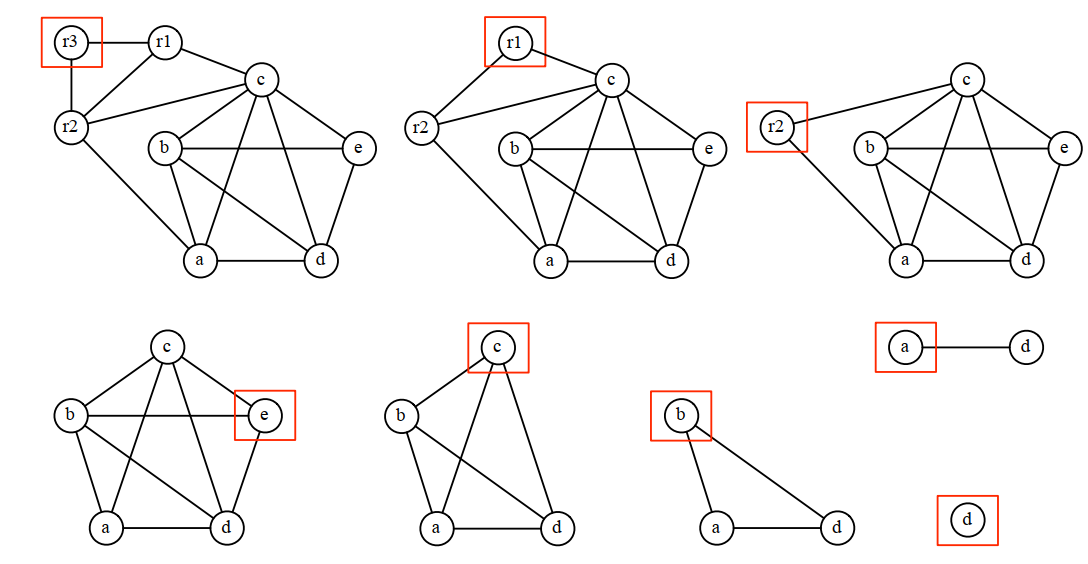
8.3.3 贪婪着色算法(Greedy Coloring)
贪婪着色的顺序是肯普简化算法删除节点的顺序的逆序,每次着色都要找一个邻接节点中不存在的颜色进行着色。
针对上面的简化过程,着色过程是这样的:

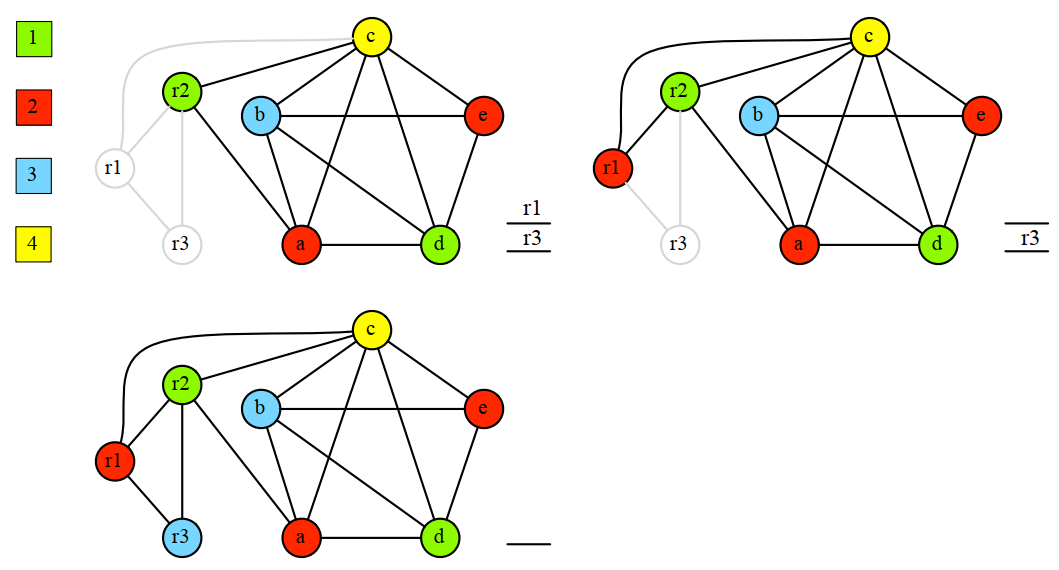
注意,上面的算法只是为了证明一个图是否能被K种颜色进行着色,但不关心是否可以用更少的颜色来着色。
8.4 循环进行寄存器合并
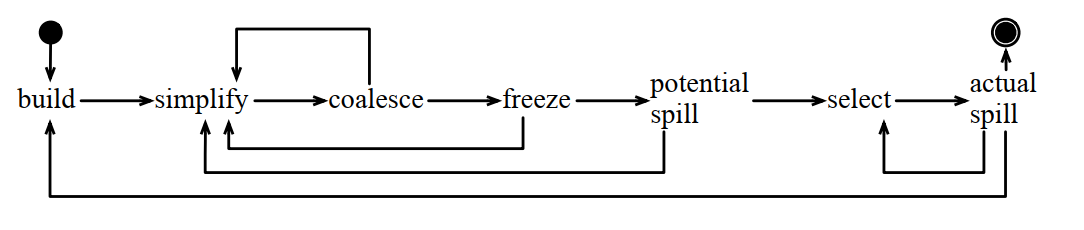
8.4.1 build
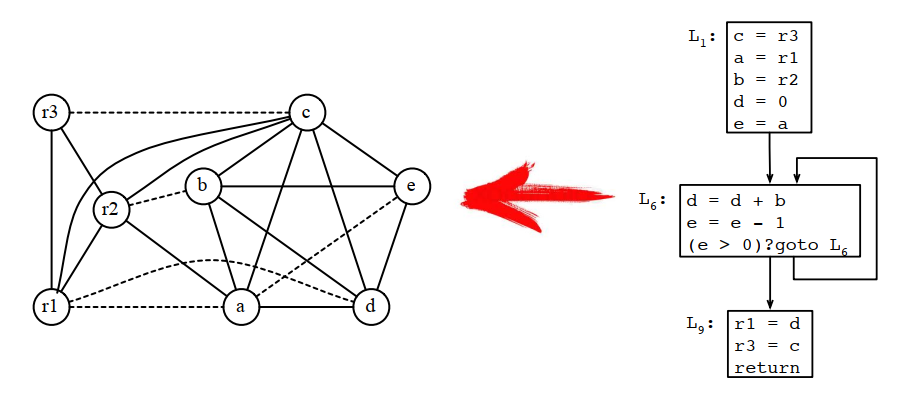
就是基于生命周期生成干涉图的过程:
8.4.2 simplify
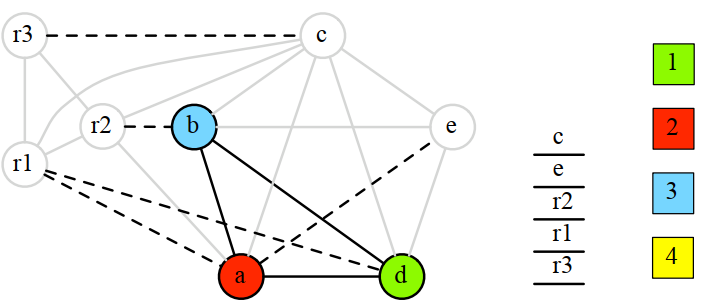
使用肯普算法删除非move相关节点:
8.4.3 Coalesce
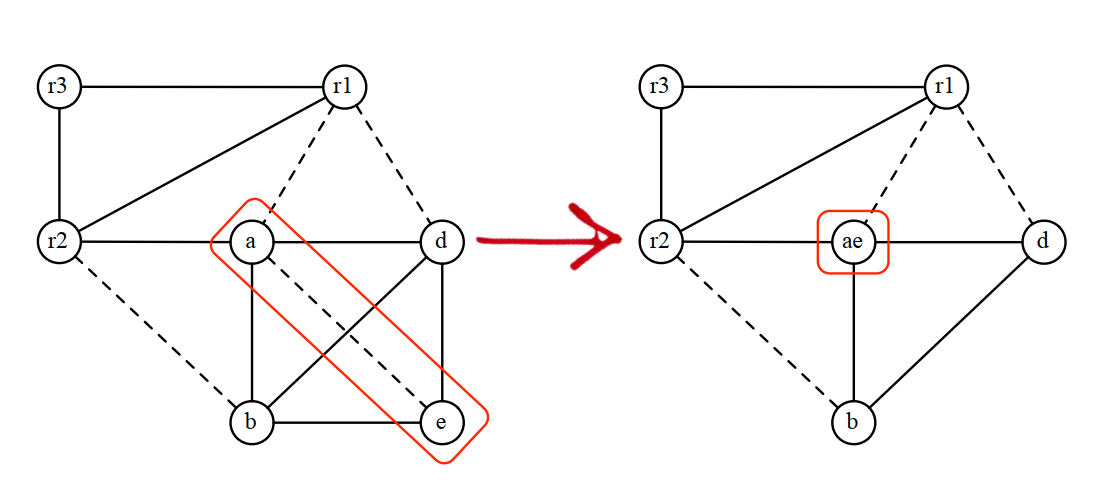
合并过程是将move关联节点合并成一个:
保守合并算法:
Briggs:节点a和b能合并当且仅当ab有更少的高阶(≥k)邻接节点
George:节点a和b能合并,当且仅当,所有a的邻接节点要么和b相互干涉,要么是一个低阶节点
8.4.4 freeze
如果前面的的简化和合并都没有影响干涉图,尝试删除一条move干涉关系。
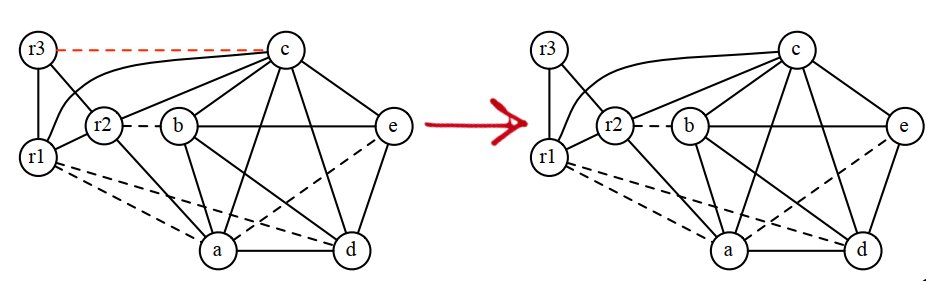
8.4.5 潜在溢出
如果找不到低阶节点,就要选择一个节点作为潜在的溢出节点,并将它加入到简化节点栈中。
现在还没有确定会溢出,有可能着色时,发现很多标记了溢出的节点,能够有效着色。
8.4.6 溢出算法(Spilling Heuristics)
溢出算法的核心是找到一个溢出代价最小的节点,我们给循环内的节点一个更高的代价因子:
1 SPILLCOST(v) 2 cost = 0 3 foreach definition at block B, or use at block B 4 cost += 10^N/D, where 5 N is B's loop nesting factor 6 D is v's degree in the interference graph
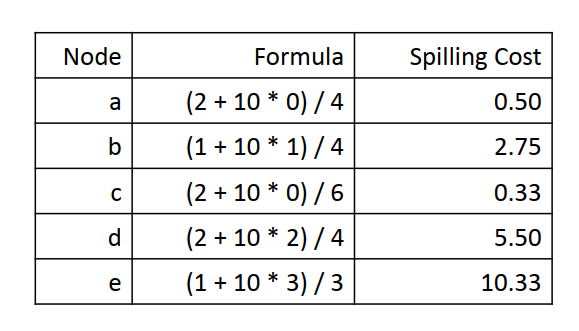
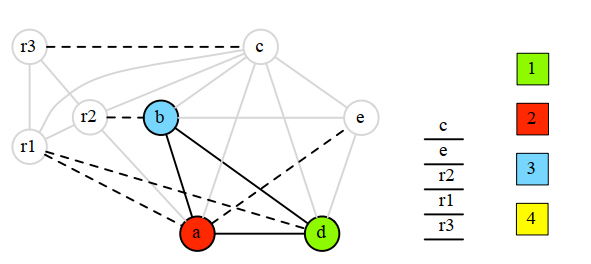
8.4.7 select
将栈中的节点出栈,并尝试用贪婪着色算法进行着色
8.4.8 溢出
如果确定需要溢出,在变量前后增加load和store指令,并重新走一遍从build开始的整个迭代过程。
在只有3个寄存器的情况下,通过上面的计算,应该溢出c,将两次c的使用改成c0和c1,重新进行计算:
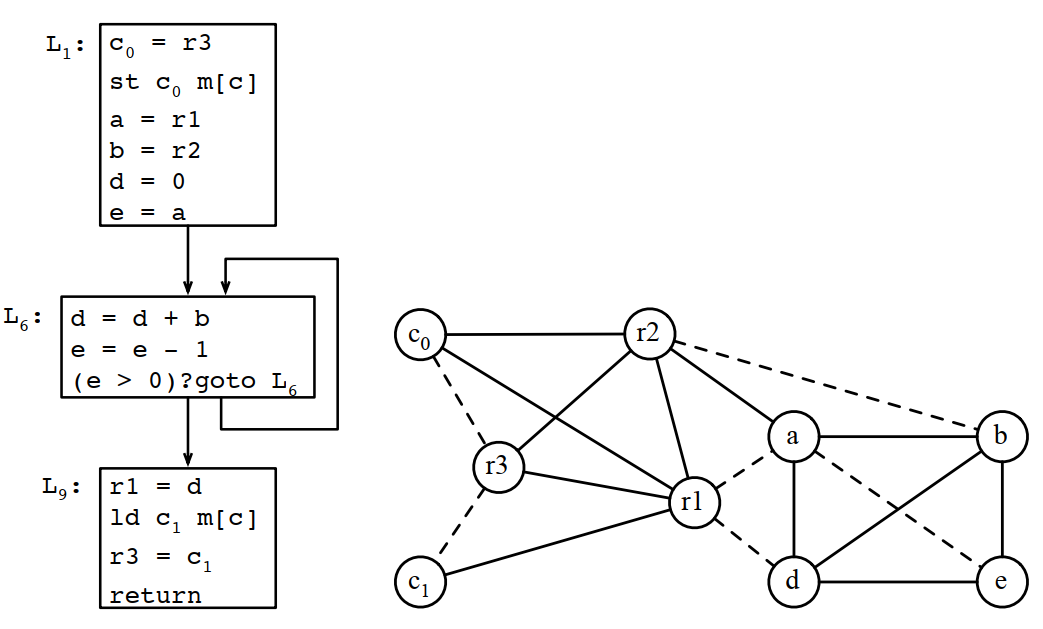
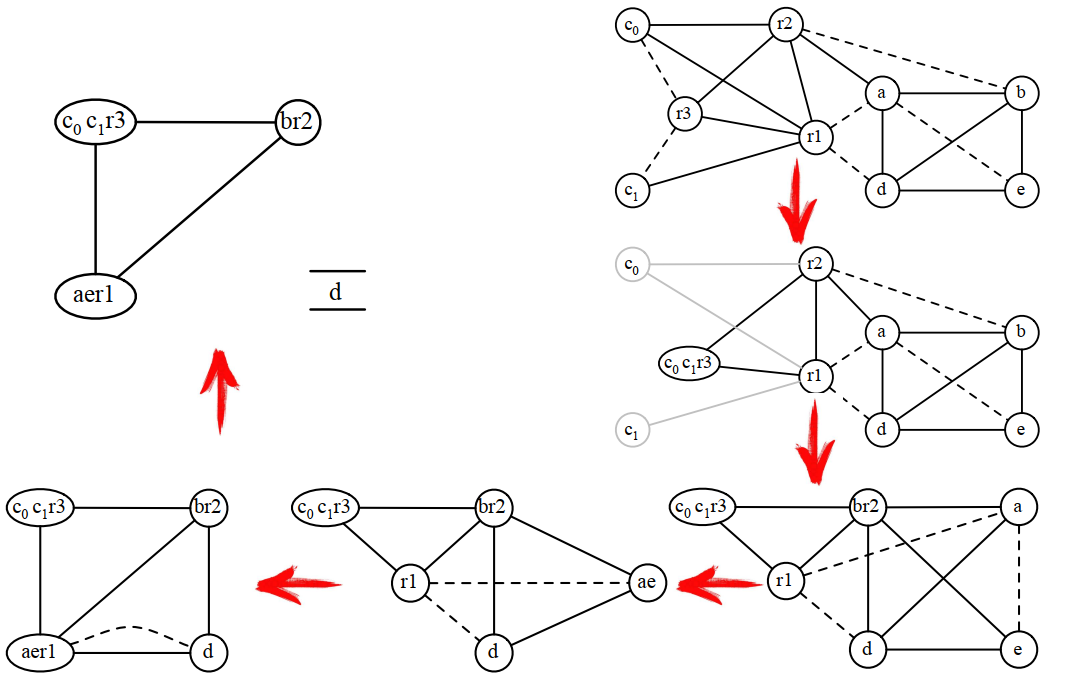
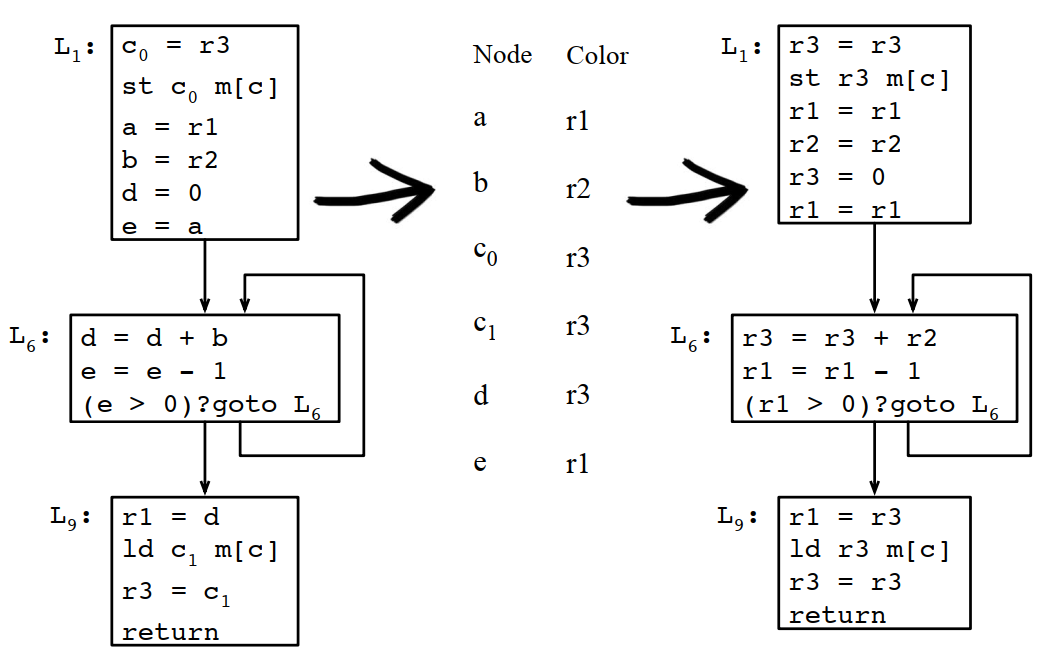
8.4.9 根据最终寄存器分配结果重写程序
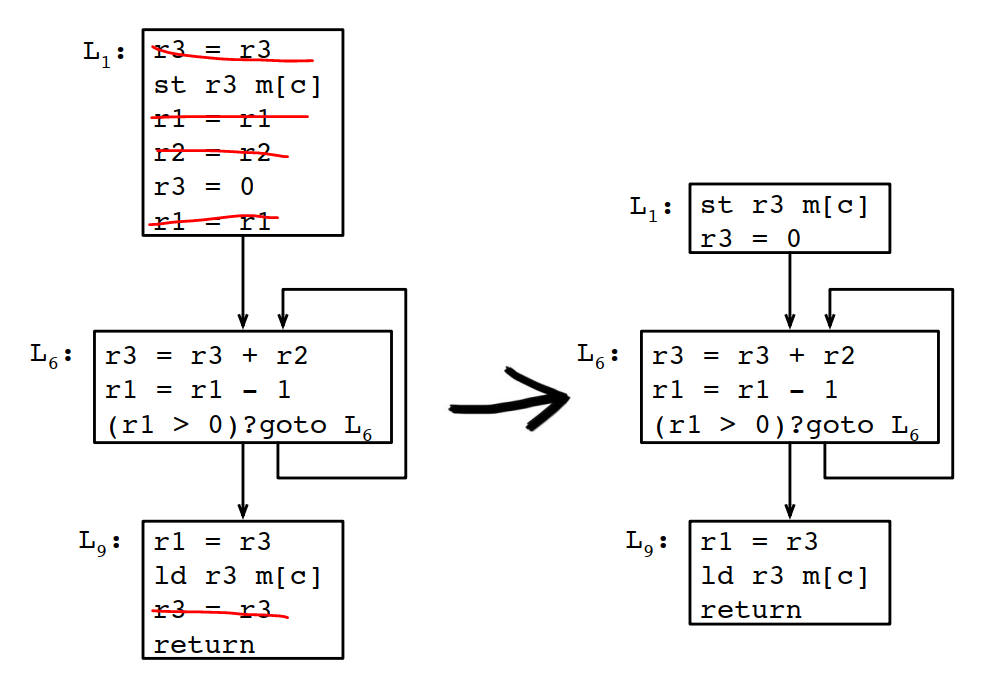
8.4.10 删除冗余的copy操作
8.5 寄存器分配简史
- Chaitin, G., Auslander, M., Chandra, A., Cocke, J., Hopkins, M., and Markstein, P. "Register allocation via coloring", Computer Languages, p 47-57 (1981),首次将图着色引入寄存器分配
- George, L., and Appel, A., "Iterated Register Coalescing", North Holland, TOPLAS, p 300-324 (1996),引入寄存器合并的迭代过程
- Poletto, M., and Sarkar, V., "Linear Scan Register Allocation", TOPLAS, p895-913 (1999),将线性扫描引入寄存器分配
