程序分析与优化 - 1 导论
本章是整个课程的第一章,主要介绍了一下文章的起源,编译器的历史和相关概念。
本文中的所有内容来自学习DCC888的学习笔记或者自己理解的整理,如需转载请注明出处。周荣华@燧原科技
1. 导论
1.1. 什么是DCC888
DCC是葡萄牙语Departamento de Ciência da Computação的简称,翻译成中文就是计算机科学学院。DCC是巴西UFMG(Federal University of Minas Gerais,中文米纳斯吉拉斯州联邦大学)下面的一个学院。DCC888是UFMG里面计算机学院的Fernado教授开通的一个课程,原名是CODE ANALYSIS AND OPTIMIZATION,也可以称为PROGRAM ANALYSIS AND OPTIMIZATION,翻译过来就是代码或者程序的分析和优化,课程结合离散数据、图论等理论知识讲解了代码的分析和优化的过程和方法,并以LLVM为例子讲解了相关实践过程。
1.2. 为什么要学习DCC888
各个学校针对编译原理相关的课程很多,但编译优化的可能比较少,结合当前主流的LLVM编译器的理论联系实际的可能更有限。DCC888不论从理论,还是从实践上来说,都是难得的好教程。
另外,计算机科学从上世纪50年代兴起到今天,历经了早期的专用计算机,到上世纪90年的PC和通用计算机的普及,当前计算机科学面临从通用计算到各种异构计算并存的时代转变。为了能在不同芯片上都发挥出代码的最优性能,一方面,每个芯片设计公司需要专注对自己芯片做专有的优化;另外一方面,提供云基础设施的集成厂商,也需要做一些通用的编译优化,已实现跨芯片运算优化;对每个程序设计师而言,了解下层的编译优化过程,对自己代码实现的性能最优,也会有比较大的帮助。
套用LLVM之父Chris Lattner的一句话就是,(现在是)计算机体系架构的黄金时代,也是编译器的黄金时代。
1.3. 编译器缔造者
计算机科学发展到现在,程序员面对的编程语言从最底层的机器码,到各种汇编语言,基础的C语言,到各种高级语言,到现在的无代码平台,为了提升程序员的生产力,编程语言不断抽象,越来越接近现实人类世界。
相对的,物理层面,芯片本身也在不断更新换代,新的硬件技术层出不穷,怎么让很久之前写的老代码在新的芯片架构上运行,并且发挥出更高的性能,是每个芯片设计商需要特别关注的。
编译器就是人类世界和机器世界的桥梁,没有编译器编程语言做的任何优化都无法落地,更加谈不上更高性能。
1.4. 课程目标
1.4.1. 了解编译过程
- 编译器如何自动的将程序转换成计算机可识别的代码(学习编译器的前端、中端和后端各自的职责是什么?)
- 转换过程中要保留原始语义(如何分析代码的语义?)
- 转换之后的代码在时间、空间和能耗上综合性能更高
- 我们尤其关注运行时间(当前代码里面哪些代码对最终结果是无意义的,可以删除的?怎么通过一种新的逻辑能实现当前语义但计算量更小?)
Proebsting's Law:编译器每隔18年可以把代码的算力提升一倍。
芯片硬件可以每年把算力提升60%,但编译器实际上只能每年提升4%,也就是叠加18年才能把算力提升一倍。尽管如此,由于编译器的优化的低成本,即使是4%,对大规模集群而言,也是非常可观的,因为软件优化相对于新增硬件采购的成本而言,基本上可以忽略不计。
1.4.2. 理解程序的底层语义
- 代码的静态分析技术
- 通过静态分析来优化性能
- 通过静态分析来证明程序的正确性
- 通过静态分析来发现代码的bug
代码性能优化的技术有很多:
- 删除冗余拷贝
- 常量折叠
- Lazy Code Motion(延迟执行)
- 寄存器分配
- 循环展开
- 值标记
- 计算强度降维
- 等等
哪些bug是编译器能发现的:
- 空指针求值
- 数组越界
- 非法类转换
- 缓冲区溢出漏洞
- 整数溢出
- 信息泄漏
下面代码里面有个安全漏洞,看看大家能否找出来?
1 void read_matrix(int* data, char w, char h) { 2 char buf_size = w * h; 3 if (buf_size < BUF_SIZE) { 4 int c0, c1; 5 int buf[BUF_SIZE]; 6 for (c0 = 0; c0 < h; c0++) { 7 for (c1 = 0; c1 < w; c1++) { 8 int index = c0 * w + c1; 9 buf[index] = data[index]; 10 } 11 } 12 process(buf); 13 } 14 }
1.5. 课程主要内容
本课程的主要内容都可以在http://www.dcc.ufmg.br/~fernando/classes/dcc888 网站下载到,包括培训胶片,实验项目,课堂作业,参考链接。另外,链接里面还有整个课程的更新记录和之前对课程积分体系的讨论。
课程大纲:
1.导论
2.控制流图CFG
3.数据流分析
4.支撑数据流分析的算法5.栅格6.延迟运行7.基于类型的分析
8.指针分析
9.循环优化
10.静态单赋值SSA11.稀疏分析12.污染流分析13. 取值范围分析14. 程序切片
15. 寄存器分配16. 基于SSA的寄存器分配17. 操作语义18. 类型系统19. 机械证明20. 类型推导21. JIT编译22. 修正
23. 分支分析
24. 自动并行
当前最新的课程分为3部分27章,基于实用的原则,也考虑到时间成本,我们做了一些精简,主要讲其中的10章,上面被划掉的章节本次不讲,大家可以自己学习。
1.6. 常见的编译器的架构
每个编译器都有自己的前端、中端和后端,其中前端对接各种编程语言,对编程语言本身进行语法和语义分析,中端负责代码优化,后端对接各种硬件架构,负责生成对应硬件下的可执行软件。当前课程主要专注于中端的功能,也就是代码本身的分析和优化。
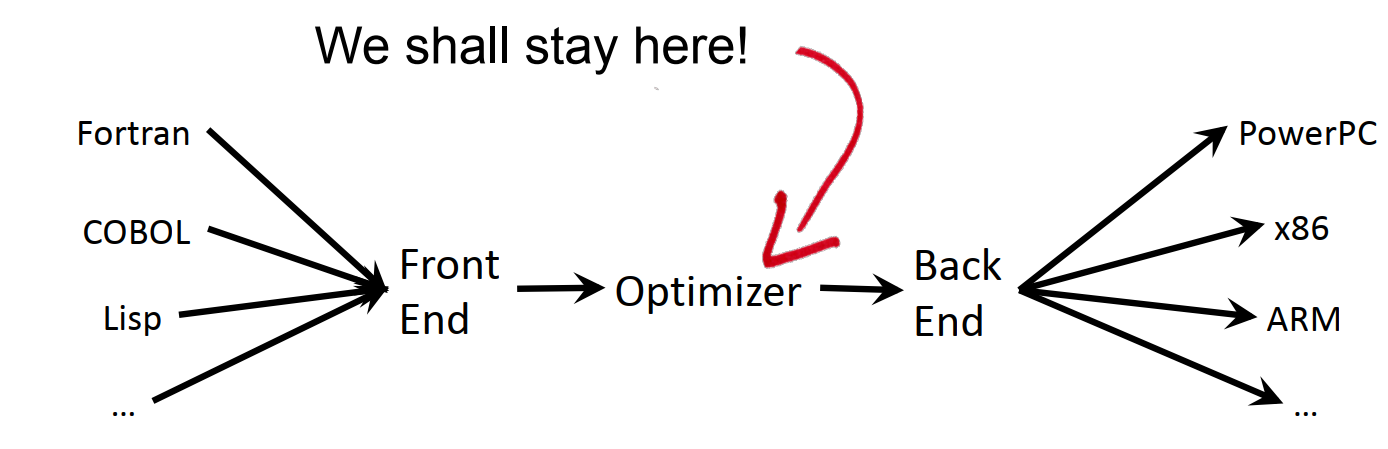
下面是一些常见的编译器框架,大家哪些框架用的比较多?
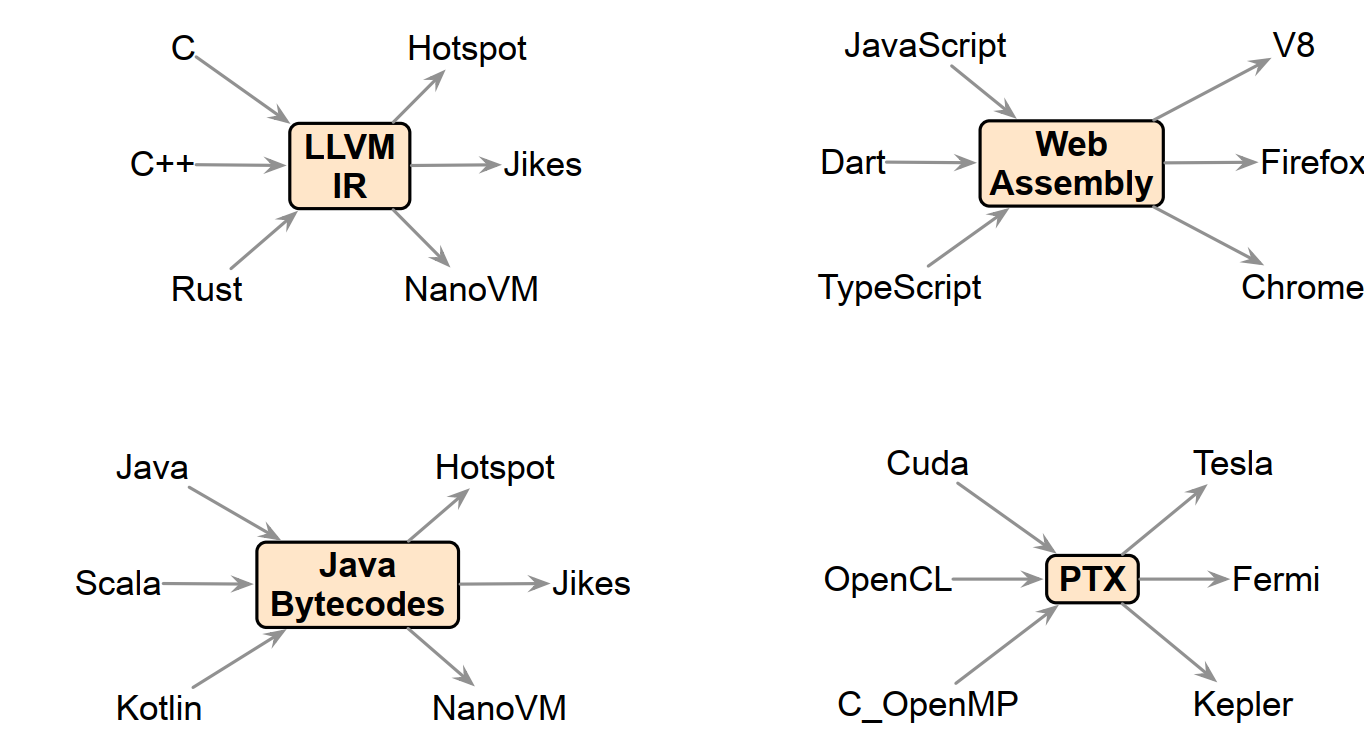
1.7. 完美编译器
完美的编译器,基于当前的程序P,生成Popt,后者保持同样的输入和输出流,但程序规模最少。
但由于输出很难界定,所以不可能存在完美的编译器。例如一个永不终止的程序的最简版本是这样的:
Pleast= L: goto L;
但这个代码不解决实际问题。
所以,对于任意一个图灵完备语言,总是有办法产生一个更好的编译器。
1.8. 为什么要学习编译器
1.8.1. 成为更好的程序员
gcc编译中有很多优化选项,下图是gcc5.4的不完全的优化选项列表:
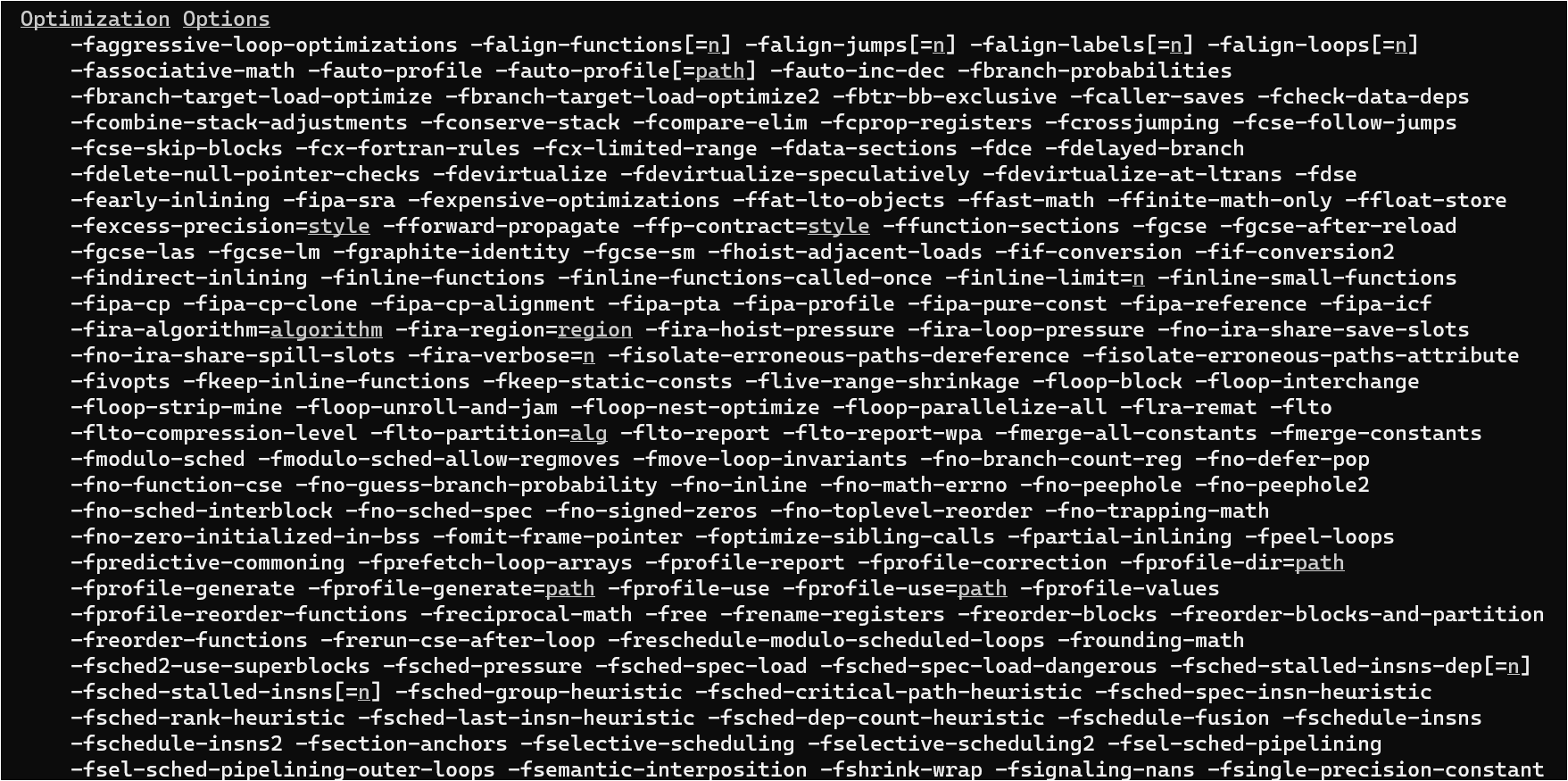
如果想要知道这些优化选项分别是什么含义,并且应该在什么场合使用哪些特定的优化选项,什么情况下不能打开某个优化选项?这对程序的性能优化会非常有帮助。
通过对编译器的了解,也可以消除一些误解。
有的人认为少用变量名,所有变量都复用一个名称会减少内存占用?
也有人认为应该少用继承,这样函数调用过程中的遍历会减少?
使用宏比函数能减少函数调用过程中的开销?
1.8.2. 更多的工作机会
很多高级岗位都要求C/C++专家,熟悉计算机的理论。
很多大型公司本身就要发布自己的编译器版本。
还有一些专门做编译器或者编译优化的公司。
1.8.3. 更好的计算机科学家
理解编译器技术在geek圈也是非常酷的事。
1.9. 能从这次课程中获得的信息
编译器是计算机科学各种理论的综合系统。
1.9.1. 编译器涉及的理论知识
- 算法(图论,集合论,动态规划)
- 人工智能(贪婪算法,机器学习)
- 自动机理论(DFA确定有限自动机,解析器生成器,上下文无关语法)
- 线性代数(栅格,定点理论,伽罗瓦连接,类型系统)
- 体系架构(流水线管理,内存体系架构,指令集)
- 优化(运算研究,负荷均衡,打包,调度)
1.9.2. 动态分析
- 打点采样,例如gprof
- 测试用例生成,例如Klee
- 仿真,例如valgrind,CFGGrind
- 编排,例如AddressSanitizer
1.9.3. 静态分析
- 数据流分析
- 基于属性的分析
- 类型分析
1.10. 理论基础
1.10.1. 图论
很多地方用到图论:
- 控制流图
- 属性图
- 依赖图
- 强连接组件图
- 图的着色
1.10.2. 不动点原理
如果总的信息是有限的,每次迭代都会有新的信息增加的情况下,稳定的算法的迭代是否会终止?
1.10.3. 结构归纳法
1.10.4. 程序演示方法
- 抽象语法树
- 控制流图(SSA表)
- 程序依赖图
- 属性系统
1.11. 开源社区
- gcc
- LLVM
- Mozilla's Monkey
- Ocelot
- Glasgow Haskell 编译器
1.12. 会议和杂志
- PLDI: Programming Languages Design and Implementation
- POPL: Principles of Programming Languages
- ASPLOS: Architectural Support for Programming Languages and Operating Systems
- CGO: Code Generation and Optimization
- CC: Compiler Construction
- TOPLAS – ACM Transactions on Programming Languages and Systems
1.13. 振奋人心的时代
- Rust编程语言的所有者类型
- Scala的路径依赖类型
- Idris的依赖类型
- Elixir角色模型中的大规模并行
- 量子计算
- 张量编译器
- WebAssembly
1.14. 优化编译器简史
- 1951-1952年,工作在Eckert-Mauchly Computer Corporation的Grace Hopper开发的面向UNIVAC I的A0系统是第一个有文献记载的编译器实现。
- 第一代优化编译器,Fortran
- 早期代码优化,Frances E. Allen和John Cocke引入控制流图,数据流分析,进程间数据流分析,工作列表算法
- Gary Kildall,代码优化和分析之父,数据流单调框架,信息折叠,迭代算法,不动点原理
- Abstract Interpretation,程序的静态行为表达
- 寄存器分配,1981年Gregory Chaitin利用图着色理论引入了寄存器分配算法;1999年Poletto and Sarkar将线性扫描算法引入JIT编译器
- SSA,80年代后期,Cytron et al. 引入SSA表格,这之后SSA经过多次改进,现在被广泛用到几乎所有编译器中
- 1988年,Olin Shivers在PLDI上引入了控制流分析法,多人创立了指针分析法
- 类型理论
1.15. 编译器的未来
- 并行计算
- 动态语言
- 正确性
- 安全

 浙公网安备 33010602011771号
浙公网安备 33010602011771号