
玩转mongodb(六):索引,速度的引领(普通索引篇)
数据库索引与书籍的索引类似,有了索引就不需要翻整本书,数据库可以直接在索引中查找,在索引中找到条目后,就可以直接跳到目标文档的位置,这可以让查找的速度提高几个数量级。
一、创建索引
我们在person这个集合的age键上创建一个索引,比较一下创建索引前后,一个查询的语句的性能区别。
创建索引:db.person.ensureIndex({"age":1})。这里我们使用了ensureIndex在age上建立了索引。“1”:表示按照age进行升序,“-1”:表示按照age进行降序。
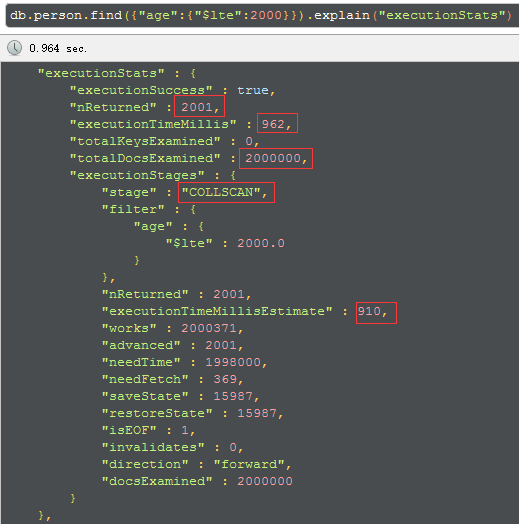
没有索引的查询性能:
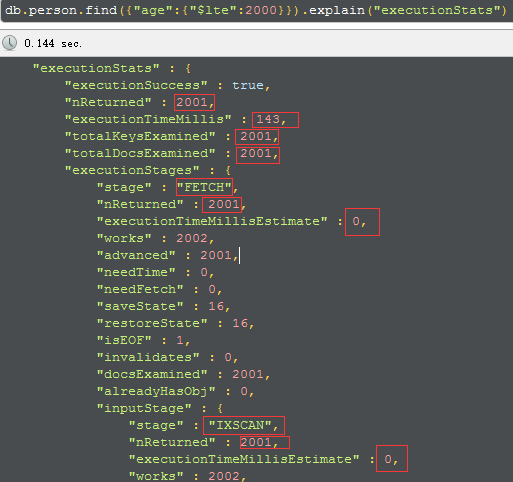
有索引的查询性能:
我们主要来看这几个参数,(参数说明,请看上一篇文章)
executionTimeMillis(这次query整体的耗时):无索引耗时962毫秒 ;有索引耗时143毫秒。
totalDocsExamined(文档扫描条目):无索引是200万条;有索引是2000条。
stage(查询的类型):无索引是COLLSCAN(全表扫描);有索引是FETCH+IXSCAN(索引扫描+根据索引去检索指定document)。
executionStages.executionTimeMillisEstimate(检索document获得数据的耗时):无索引耗时910毫秒;有索引耗时0毫秒。
建好索引后,这个query整体的速度提高了1个数量级 (1个数量级是10倍的意思)。根据查询语句的不同,索引可以使速度提高几个数量级。
二、复合索引
在多个键上建立的索引就是复合索引,有时候我们的查询不是单条件的,可能是多条件,比如查找年龄在20~30名字叫‘ryan1’的同学,那么我们可以建立“age”和“name”的联合索引来加速查询。
为了演示索引的效果,我们来重新生成插入一份200万个文档的集合。
1 //删除原来的集合 2 db.person.drop(); 3 4 //插入200万条数据 5 for(var i=0;i<2000000;i++){ 6 db.person.insert({"name":"ryan"+i%1000,"age":20+i%10}); 7 } 8 9 //创建三个索引 10 db.person.ensureIndex({"age":1}) 11 db.person.ensureIndex({"name":1,"age":1}) 12 db.person.ensureIndex({"age":1,"name":1})
我们可以用hint()方法来强制查询走哪个索引。
我们来看一下,当查询条件是多个的时候,复合索引相比单键索引的强大魅力。
db.person.find({"age":{"$gte":20,"$lte":30},"name":"ryan1"}).hint({"age":1}).explain("executionStats");
1 { 2 ... 3 "executionStats" : { 4 "executionSuccess" : true, 5 "nReturned" : 2000, 6 "executionTimeMillis" : 2031, 7 "totalKeysExamined" : 2000000, 8 "totalDocsExamined" : 2000000, 9 ... 10 }
db.person.find({"age":{"$gte":20,"$lte":30},"name":"ryan1"}).hint({"age":1,"name":1}).explain("executionStats");
1 { 2 ... 3 "executionStats" : { 4 "executionSuccess" : true, 5 "nReturned" : 2000, 6 "executionTimeMillis" : 8, 7 "totalKeysExamined" : 2010, 8 "totalDocsExamined" : 2000, 9 ... 10 }
从executionTimeMillis的值上,一眼就可以看出却别。单间索引耗费了2031毫秒,复合索引用了8毫秒。 由此我们可以看出,根据查询语句的不同,建立正确的索引是非常重要的,对于查询语句中是多条件的,应多考虑复合索引的应用。
下面,我们再说一种复合索引的重要应用情况。有对一个键排序并只要前100个结果的情景(实际项目中经常都是这种情景)。对于这种情况,索引应该这样建{"sortKey":1,"queryCriteria":1},排序的键应该放在复合索引的第一位。
db.person.find({"age":{"$gte":21.0,"$lte":30.0}}).sort({"name":1}).limit(100).hint({"age":1,"name":1}).explain("executionStats");
1 { 2 ... 3 "executionStats" : { 4 "executionSuccess" : true, 5 "nReturned" : 100, 6 "executionTimeMillis" : 6882, 7 "totalKeysExamined" : 1800000, 8 "totalDocsExamined" : 1800000, 9 ... 10 }
db.person.find({"age":{"$gte":21.0,"$lte":30.0}}).sort({"name":1}).limit(100).hint({"name":1,"age":1}).explain("executionStats");
1 { 2 ... 3 "executionStats" : { 4 "executionSuccess" : true, 5 "nReturned" : 100, 6 "executionTimeMillis" : 3, 7 "totalKeysExamined" : 2100, 8 "totalDocsExamined" : 2100, 9 ... 10 }
从上面的结果,我们很容易看出,基于排序键的索引,效果非常好。
分析:第一种索引,需要找到所有复合查询条件的值(依据索引,键和文档可以快速找到),但是找到后,需要对文档在内存中进行排序,这个步骤消耗了非常多的时间。第二种索引,效果非常好,因为不需要在内存中对大量数据进行排序。但是,MongoDB不得不扫描整个索引以便找到所有文档。因此,如果对查询结果的范围做了限制,那么MongoDB在几次匹配之后就可以不再扫描索引,在这种情况下,将排序键放在第一位是一个非常好的策略。
三、唯一索引
唯一索引可以确保集合的每个文档的指定键都有唯一值。如果想保证不同文档的“name”键拥有不同的值,在“name”键上创建一个唯一索引就可以了。
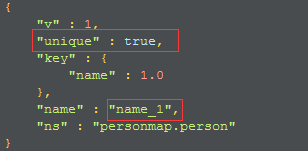
db.person.ensureIndex({"name":1},{"unique":true});
然后用db.person.getIndexes()命令,查看目前person集合所有的索引。
也可以创建复合的唯一索引。创建复合唯一索引时,单个键的值可以相同,但所有键的组合值必须是唯一的。
db.person.ensureIndex({"name":1,"age":1},{"unique":true});

四、稀疏索引
唯一索引会把null看作值,所以无法将多个缺少唯一索引中的键的文档插入到集合中。然而,在有些情况下,你可能希望唯一索引只对包含相应键的文档生效。这个时候我们可以用到MongoDB中的稀疏索引。该索引与关系型数据库中的稀疏索引是完全不同的概念。MongoDB中的稀疏索引只是不需要将每个文档都作为索引条目。
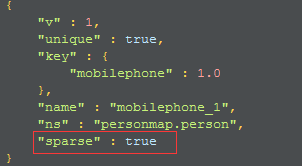
比如,如果有一个可选的mobilephone字段,但是,如果提供了这个字段,那么它的值必须是唯一的:
db.person.ensureIndex({"mobilephone":1}{"unique":true,"sparse":true});
稀疏索引不必是唯一的。只要去掉unique选项,就可以创建一个非唯一的稀疏索引。
五、索引管理
如第一小节所述,可以使用ensureIndex方法创建新的索引,也可以使用createIndex方法。
创建一个索引之后,可以利用getIndexes()方法来查看给定集合上的所有索引的信息。
db.person.getIndexes();得到的结果如下所示。


1 [ 2 { 3 "v" : 1, 4 "key" : { 5 "_id" : 1 6 }, 7 "name" : "_id_", 8 "ns" : "personmap.person" 9 }, 10 { 11 "v" : 1, 12 "unique" : true, 13 "key" : { 14 "name" : 1.0 15 }, 16 "name" : "name_1", 17 "ns" : "personmap.person" 18 }, 19 { 20 "v" : 1, 21 "unique" : true, 22 "key" : { 23 "name" : 1.0, 24 "age" : 1.0 25 }, 26 "name" : "name_1_age_1", 27 "ns" : "personmap.person" 28 }, 29 { 30 "v" : 1, 31 "unique" : true, 32 "key" : { 33 "mobilephone" : 1.0 34 }, 35 "name" : "mobilephone_1", 36 "ns" : "personmap.person", 37 "sparse" : true 38 } 39 ]
随着业务的不断变化,你可能会发现数据或者查询已经发生了改变,原来的索引也不那么好用了。这时可以使用dropIndex()方法删除不需要的索引:
db.person.dropIndex("name_1");//删除索引名为name_1的索引。
喜欢请微信扫描下面二维码,关注我公众号--“精修Java”,做一些实战项目中的问题和解决方案分享。


