
Fiddler 网页采集抓包利器
最近这段时间,网页采集方面的工作做得比较多。用curl技术开发了一个微信文章聚合类产品,把抓取到的数据转换成json格式,并在android端调用json数据接口加以显示;基于weiphp做了一个掌上头条插件,也是用的网页采集技术;和一个创业团队一起在做一个高考志愿填报系统,所有的数据也是从别的地方抓取。总而言之,网页抓取与网页采集技术是一项非常实用的技能,他能让我们高效快速的获取我们开发产品所需要的一些基本数据。
网页抓取与网页采集过程中难免需要用到抓包技术,所谓抓包,就是我们在访问一个目标网站的时候,需要分析我们提交给浏览器的一些http请求以及提交给浏览器的一些数据,在知道请求是如何发起的以及post了哪些数据之后,我们才能针对目标网页写出相应的采集程序。特别是在模拟登陆一些需要用户进行登陆验证的网站时,抓包分析就变得很重要。
一些浏览器自带抓包分析工具或者有其可扩展的抓包插件,像火狐浏览器有firebug插件,IE浏览器有HttpWatch。每个抓包工具都有其独特的功能,这里就不一一介绍了,今天给大家介绍一个好用的抓包工具Fiddler。
可以查看只允许微信浏览器访问的页面 例如

一、下载地址:
链接:http://pan.baidu.com/s/1nunXD6D 密码:yoy9
二、基本介绍:
三、使用教程:
http://jingyan.baidu.com/article/5d6edee221f0b399ebdeec7f.html
四、补充介绍:
手机APP抓包:http://my.oschina.net/u/587105/blog/322952
现在我们来结合一个具体的例子来讲一下如何抓包分析手机APP的请求数据,并达到自己的需求。我这里给大家讲一个LOL盒子的抓包实例。
我们知道,LOL盒子没有网页版,或者说网页版的功能并不像手机APP一样数据整合的那么齐全。如果我们要做一个微信版的LOL盒子,让用户在微信端回复一些关键词就能查看一些基本信息,比如用户在微信中回复“英雄”就能查看LOL全部的英雄信息,包括出装、符文之类的。那么我们想在微信端实现这些功能,肯定需要数据库的支持,如果我们的数据从LOL官网抓取的话,免不了要写很多匹配规则,所以一个简单高效的方法是直接抓取LOL盒子已经整合了的数据。那么正题开始,我们开始抓LOL盒子集成的全部英雄的数据。
1、首先在手机下载LOL盒子,并进入首页(请忽略我这个战五渣的战斗力指数)

2、打开Fiddler并点Remove all把抓包信息全部清除

3、在LOL盒子中点击英雄进入查看英雄页面
4、可以看到查看英雄页面有免费、我的英雄、全部三个选项

5、这时候我们可以看到Fiddler已经抓到我们需要的数据接口了

6、我们在其中一个数据接口上面点击右键,复制url地址并在浏览器中打开
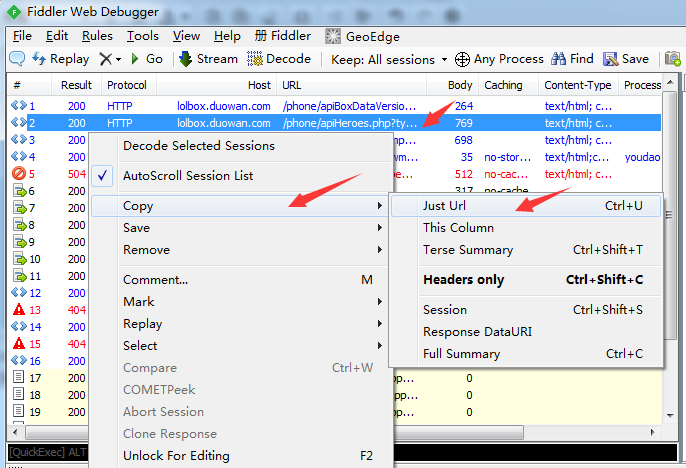
7、就能看到我们需要的周免英雄的数据接口了,是json格式的
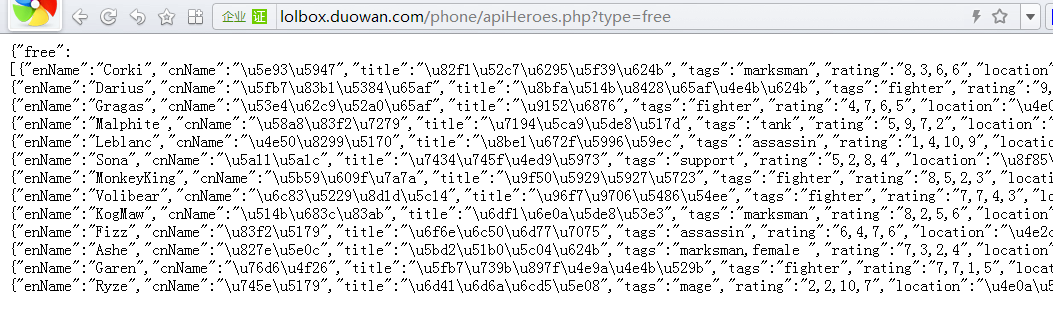
到此为止,抓包分析的整个流程大家一目了然了,得到了json接口之后,我们就能用curl技术把数据采集下来,并把json格式的数据转换成数组或者其他格式,然后就可以存到我们自己的数据库中了,当用户在微信中回复关键词时,我们就从数据库中取出相应的数据并回复给用户就行了。

