Redis7-集群数据容量
主从复制解决HA问题,未解决容量有限问题
容量的问题
AKF 的 y轴 做纵向业务拆分,这样把存储的数据,在客户端层面就决定好每个redis存储一部分的数据。
如果数据可以分类,交集不多,可以考虑按业务拆分

如果数据量很大,光拆分了业务之后,还是每个业务拥有大量数据,数据没有办法划分拆解
采用sharding分片
- Hash+取模
分布式系统中,假设有 n 个节点,传统方案使用
mod(key, n)映射数据和节点。

当扩容或缩容时(哪怕只是增减1个节点),映射关系变为 mod(key, n+1) / mod(key, n-1),绝大多数数据的映射关系都会失效。这种哈希取模的方式,会影响分布式系统的扩展性。
- random随机分配节点
一端随机往 redis 中不断存储数据,另一端随机从 redis 中取数据,这样就不用太在意数据被存到了哪,只要最终被消费掉即可。

-
一致性哈希算法
一致性哈希算法中,当节点个数变动时,映射关系失效的对象非常少,迁移成本也非常小。
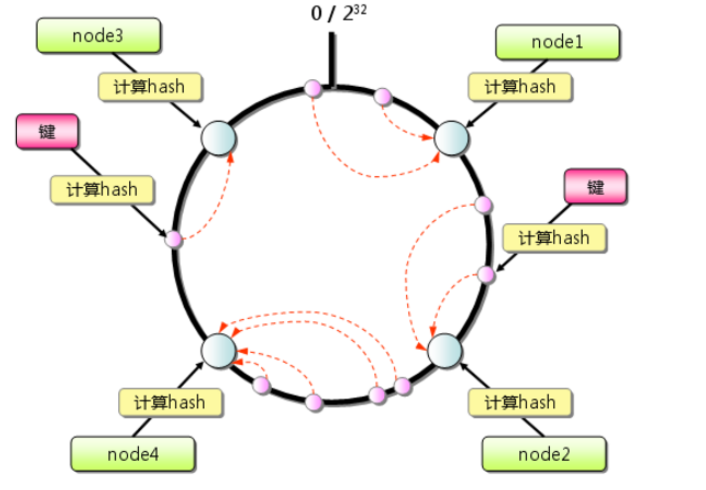
https://baike.baidu.com/item/一致性哈希/2460889?fr=aladdin
https://www.cnblogs.com/lpfuture/p/5796398.html
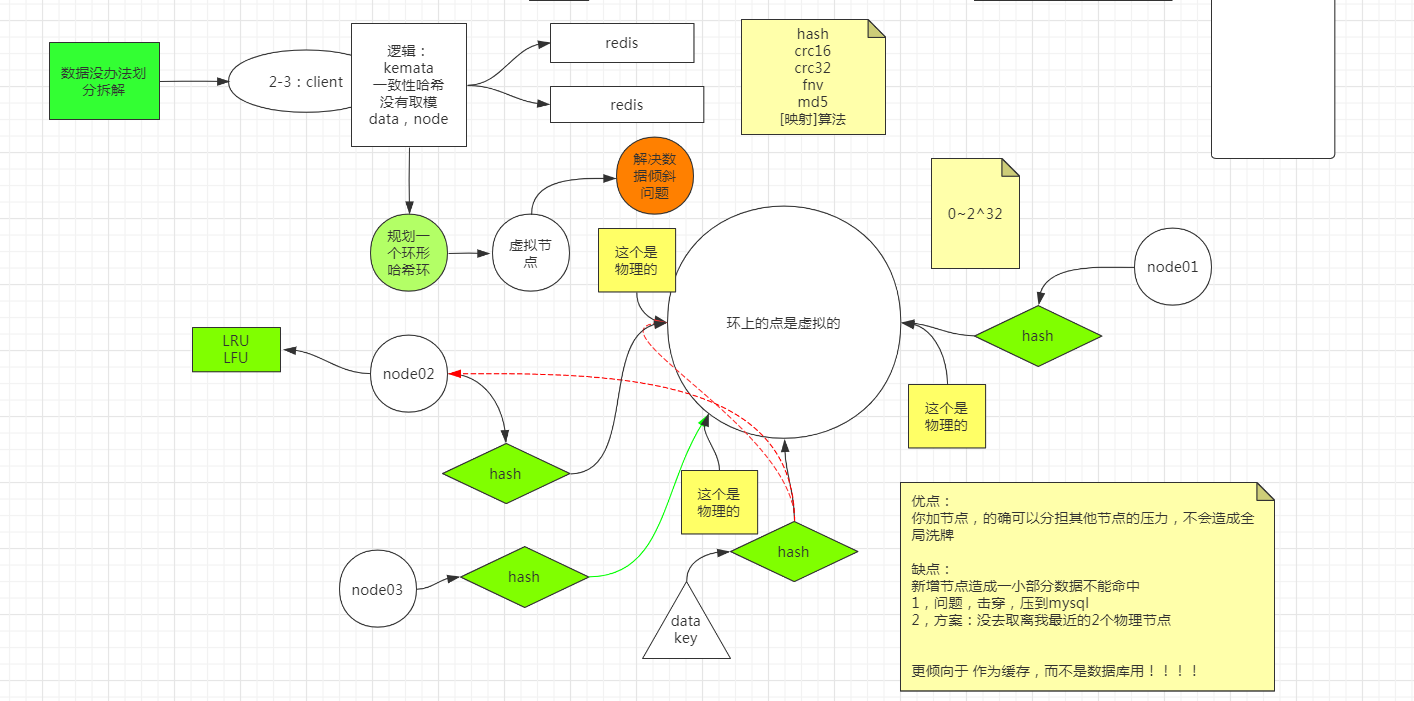
物理节点:两个redis的物理节点。
虚拟结点:通过多个哈希函数,得到多个结果值,将一个节点,分布在环的多个位置上,两个物理节点可以映射环上多个位置,这样解决了数据倾斜的问题。
成本问题
redis 结点可能只有那么几个,但是连接 redis 的客户端数量非常多。
往往客户端会有一个连接池,一个客户端就建立了很多很多连接导致redis连接对server端的成本很高。
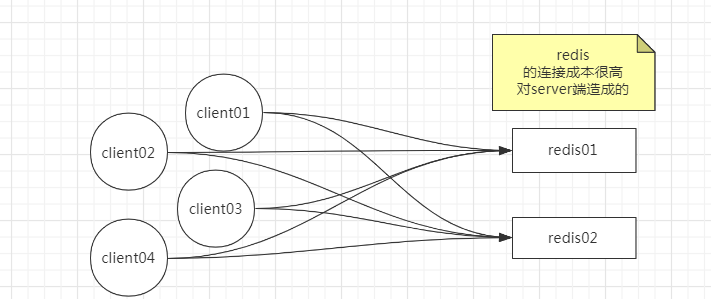
解决方式
增加一个接入层,类似于nginx反向代理,只负责接收来自客户端的请求,把它代理到后端的服务器上。
这样,redis 服务端的连接压力就减轻了,我们就只需要关注代理层的性能。
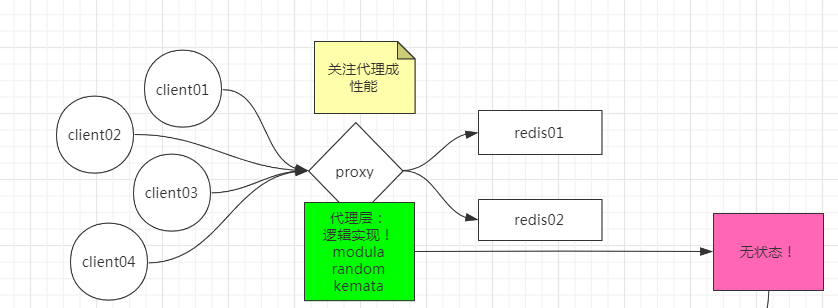
代理层的性能
可以对代理层再做一次集群,其中的每一部分客户端都只连接一个代理。代理层适应例如modula,random,kemata算法映射redis物理节点。
代理层 Nginx 都扛不住怎么办
可以再统一接入一个负载均衡 LVS。LVS做一个主备,主备之间通过keepalived,除了监控两个LVS的健康状态之外,也监控proxy的健康状态。
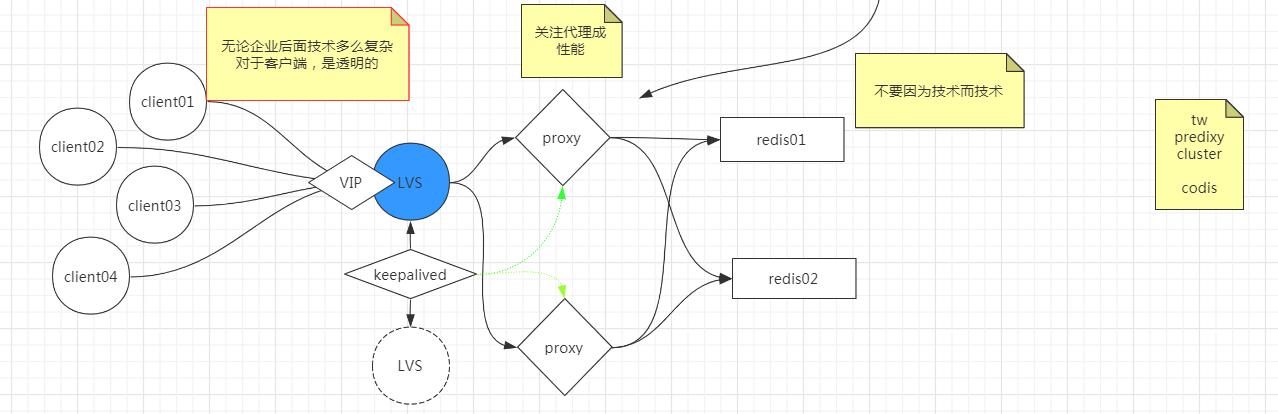
这样,无论后端的技术有多么复杂,对于客户端来说都是透明的,因此,客户端的 API 就可以极其简单。
https://github.com/twitter/twemproxy
同时不要因为技术而技术。redis连多线程都没有使用,它并不希望redis被引入那么多的功能。上面3个模式不能做数据库用。
数据预分区
分区时动态扩容或缩容可能非常复杂。Redis集群在运行时增加或者删除Redis节点,能做到最大程度对用户透明地数据再平衡,但其他一些客户端分区或者代理分区方法则不支持这种特性。然而,有一种预分片的技术也可以较好的解决这个问题。
一般情况下随着时间的推移,数据存储需求总会发生变化。今天可能两个Redis节点就够了,但是明天可能就需要增加到10个节点。
开始要取模的话就是 %2,未来很多次扩容到10个,可以一开始一次性取模%10
中间加一层 mapping,当两个节点时,让其中 0-4 这5份数据存到 1 结点,然后让 5-9 这部分数据,存到 2 结点。
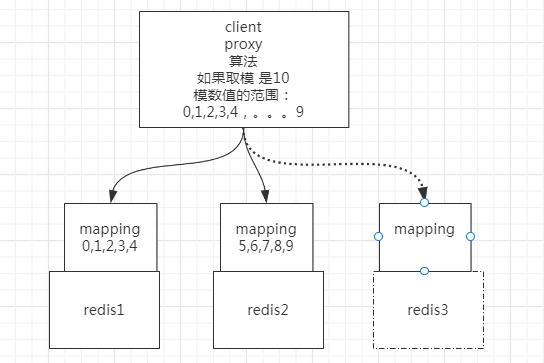
扩容到第三个结点的时候,把 1 号的 3、4 槽位以及数据分给它,把 2 号的 8、9 槽位和数据分给它,这样,就可以继续保持每个节点,持有固定槽位的数据,而不会产生数据丢失。
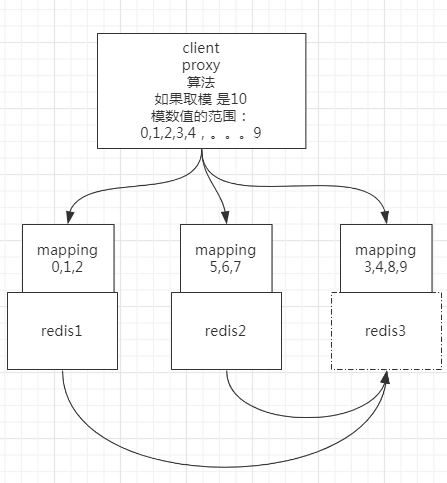
与上面三种分片方式区别
对于之前的哈希取模,或者还是一致性哈希环,它们在新增结点的时候,都需要对数据进行重哈希,重新定位新的数据应存储在哪个结点。
数据迁移会不会有什么问题?
在数据传输的过程中,是先 RDB 把该传的数据全部传过去,由于服务不能停止中断,AOF 传输少量变化的数据。
redis 集群 无主模型
- 查询路由(Query routing) 的意思是客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。Redis Cluster实现了一种混合形式的查询路由,但并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的redis节点。
例如,客户端去redis3上找k1,redis2说,你应该去redis3找。于是客户端就去redis3上取k1(每个redis节点知道其他redis持有的分区信息)
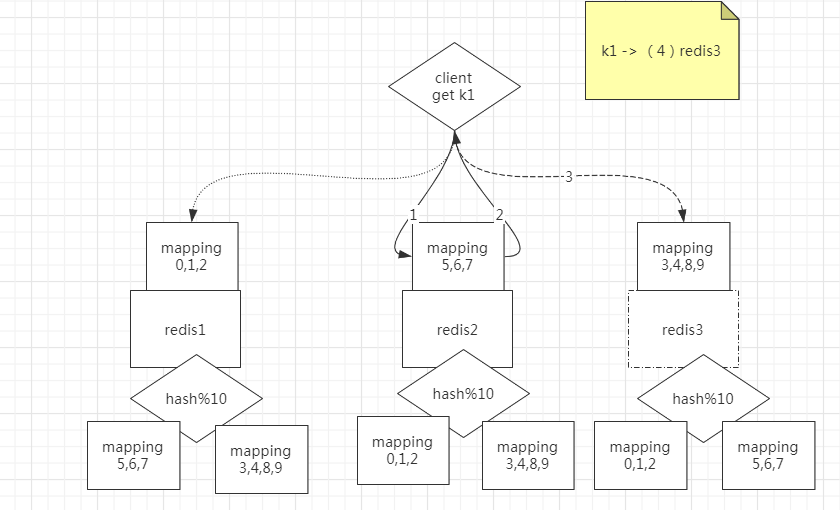
分区的缺点
- 涉及多个key的操作通常不会被支持。例如你不能对两个集合求交集,因为他们可能被存储到不同的Redis实例(实际上这种情况也有办法,但是不能直接使用交集指令)。
- 同时操作多个key,则不能使用Redis事务.
解决方法
因为数据一但被分开,就很难再被合并处理;如果数据不被分开,那就可以进行事务。
可以由人去实现:hash tag 例如我们将带有相同前缀的key放在一个节点上,对前缀key取模
Twemproxy
Twemproxy是一种代理分片机制,由Twitter开源。Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis或memcached服务器,再原路返回。
https://github.com/twitter/twemproxy
Predixy
Predixy 是一款高性能全特征redis代理,支持redis-sentinel和redis-cluster
https://github.com/joyieldInc/predixy/blob/master/README_CN.md
:.,$/#// vim模式替换光标到结束#替换空
:.,$y vim模式复制光标到结束 np 粘贴
Predixy sentinel.conf 文件
SentinelServerPool {
Databases 16
Hash crc16
HashTag "{}"
Distribution modula
MasterReadPriority 60
StaticSlaveReadPriority 50
DynamicSlaveReadPriority 50
RefreshInterval 1
ServerTimeout 1
ServerFailureLimit 10
ServerRetryTimeout 1
KeepAlive 120
Sentinels {
+ 127.0.0.1:26379
+ 127.0.0.1:26380
+ 127.0.0.1:26381
}
Group ooxx {
}
Group xxoo {
}
}
26379.conf 具体哨兵配置文件
[root@node11 test]# cat 26379.conf
port 26379
sentinel monitor ooxx 127.0.0.1 36379 2
sentinel monitor ooxx 127.0.0.1 46379 2
启动步骤
-
redis-server 26379.conf --sentinelredis-server 26380.conf --sentinelredis-server 26381.conf --sentinel启动三个哨兵进程 -
mkdir -p 36379 36380 46379 46380创建redis数据临时目录 -
redis-server --port 36379redis-server --port 36380 --replicaof 127.0.0.1 36379启动一对主从redis -
redis-server --port 46379redis-server --port 46380 --replicaof 127.0.0.1 46379启动一对主从redis -
../bin/predixy predixy.conf启动predixy -
redis-cli -p 7617连接predixy 客户端进行redis操作 -
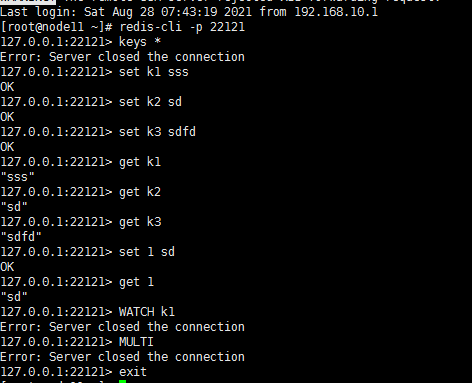
127.0.0.1:7617> set {oo}k1 dffd OK 127.0.0.1:7617> set {oo}k2 dffdddf 127.0.0.1:7617> WATCH {oo}k1 (error) ERR forbid transaction in current server pool设置两个前缀一样的数据,不支持多组的WATCH,只保留一个组
Group ooxx {}配置就可以支持WATCH和开启事务 -
带有相同前缀的key放在一个节点上
127.0.0.1:46379> keys * 1) "k2" 2) "{oo}k2" 3) "{oo}k1"
Redis集群使用
自带create-cluster脚本
#!/bin/bash
# Settings
PORT=30000
TIMEOUT=2000
NODES=6
REPLICAS=1
#node 6 REPLICAS 1 表示 3主3从 6个节点 1个副本(一个主带一个从)
步骤
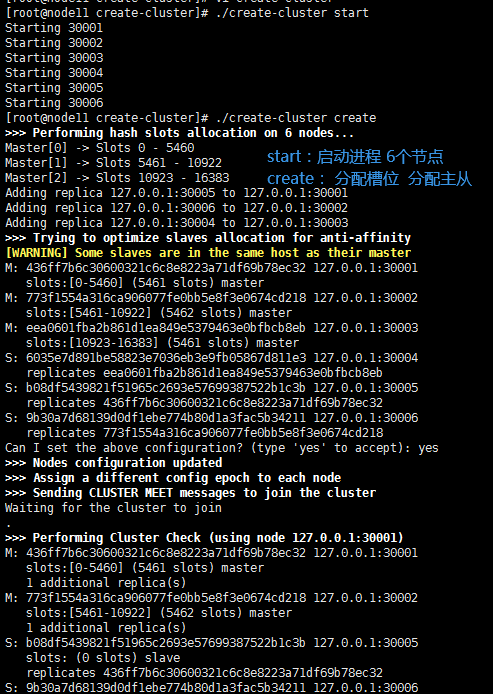
查询路由(Query routing):Redis将请求转发给正确的Redis节点 不支持事务(操作在多个节点)
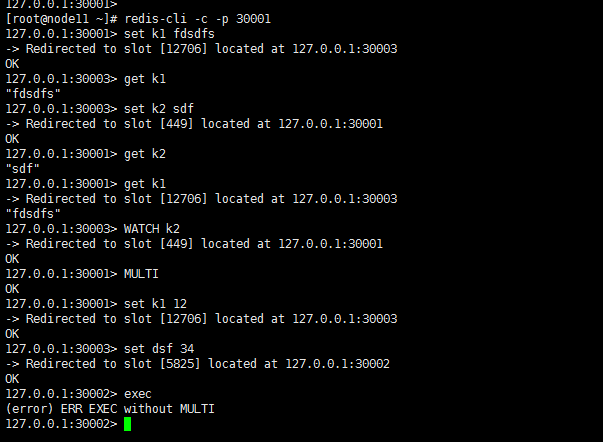
方法:hash tag 例如我们将带有相同前缀的key放在一个节点上 可以支持事务
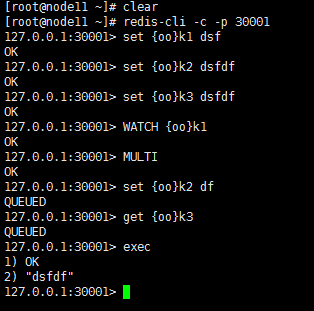
自定义槽位和主从关系
# 自定义命令帮助
redis-cli --cluster help
# 设置 可设置分布式集群redis 修改IP
redis-cli --cluster create 127.0.0.1:30001 127.0.0.1:30002 127.0.0.1:30003 127.0.0.1:30004 127.0.0.1:30005 127.0.0.1:30006 --cluster-replicas 1
解决数据倾斜
# 从127.0.0.1:30001移动2000个槽位到127.0.0.1:30002节点
[root@node11 create-cluster]# redis-cli --cluster reshard 127.0.0.1:30001
>>> Performing Cluster Check (using node 127.0.0.1:30001)
M: 55c3f55d775626d6f6b5f53df57a4298db3c20c8 127.0.0.1:30001
slots:[2000-5460] (3461 slots) master
1 additional replica(s)
M: 3ccd455a998cc9a9357bc6f511ac79201e3c9efb 127.0.0.1:30002
slots:[0-1999],[5461-10922] (7462 slots) master
1 additional replica(s)
M: 2ba179cb27b443e324c430b29566ac76fb3bb925 127.0.0.1:30003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 8b28fb5af0fee14342e91e02c98a10d58f053c2b 127.0.0.1:30005
slots: (0 slots) slave
replicates 2ba179cb27b443e324c430b29566ac76fb3bb925
S: dcc1d0911b1e7ddaad431510395fbe1fc87ef97f 127.0.0.1:30006
slots: (0 slots) slave
replicates 55c3f55d775626d6f6b5f53df57a4298db3c20c8
S: 52027783eef3fb16481a6b5aa5247f1dd2c4dd7f 127.0.0.1:30004
slots: (0 slots) slave
replicates 3ccd455a998cc9a9357bc6f511ac79201e3c9efb
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 2000
What is the receiving node ID? 3ccd455a998cc9a9357bc6f511ac79201e3c9efb
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 55c3f55d775626d6f6b5f53df57a4298db3c20c8
Source node #2: done
# 移动完成后 127.0.0.1:30001节点减少2000个槽位
[root@node11 ~]# redis-cli --cluster info 127.0.0.1:30001
127.0.0.1:30001 (55c3f55d...) -> 0 keys | 3461 slots | 1 slaves.
127.0.0.1:30002 (3ccd455a...) -> 0 keys | 7462 slots | 1 slaves.
127.0.0.1:30003 (2ba179cb...) -> 1 keys | 5461 slots | 1 slaves.
[OK] 1 keys in 3 masters.
0.00 keys per slot on average.
[root@node11 ~]# redis-cli --cluster check 127.0.0.1:30001
本文来自博客园,作者:gary2048,转载请注明原文链接:https://www.cnblogs.com/zhoum/p/15195684.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号