

percona-toolkit 之 【pt-archiver】
背景:
工作上需要删除或则归档一张大表,这时候用pt-archiver可以很好的满足要求,其不仅可以归档数据,还有删除、导出到文件等功能。并且在主从架构当中,可以兼顾从库(一个或则多个)进行归档,避免归档、删除数据时候压力太大,造成从库的延迟。该工具的目标是一个低影响,从表中剔除旧数据,而不会影响OLTP查询。也可以将数据插入到另一个表中,该表不必位于同一服务器上。
使用方法:
pt-archiver [OPTIONS] --source DSN --where WHERE
1)将所有行从oltp_server归档到olap_server并归档到文件:
pt-archiver --source h=oltp_server,D=test,t=tbl --dest h=olap_server \ --file '/var/log/archive/%Y-%m-%d-%D.%t' \ --where "1=1" --limit 1000 --commit-each
2)从子表中删除行:
pt-archiver --source h=host,D=db,t=child --purge \ --where 'NOT EXISTS(SELECT * FROM parent WHERE col=child.col)'
参数说明:注意:至少需要指定--dest,--file,--purge 其中的一个。
1:--source :指定要归档表的信息,兼容DSN选项。
a:执行查询时要使用的数据库。 b:如果为true,则使用SQL_LOG_BIN禁用binlog。 h:连接的MySQL主机名或IP地址。 D:连接时使用的默认数据库,可以在运行时使用不同的数据库。 t:要被归档、删除、导出的表。 i:进行归档、删除、导出时,被指定使用的索引。 p:连接时使用的MySQL密码。 P:连接时使用的MySQL端口。 S:用于连接的MySQL套接字文件(在Unix系统上)。 u:连接时使用的MySQL用户名。 L:启用LOAD DATA LOCAL INFILE。 A:连接MySQL的默认字符集(SET NAMES)。 F:通过配置文件读取用户名和密码,如配置了〜/ .my.cnf,就会自动连接工具而无需用户名或密码。格式为: [client] user=your_user_name pass=secret
此项指定一个表,pt-archiver将在其中插入从--source归档的行。 它使用与--source相同的参数格式。 大多数缺失值默认为与--source相同的值,因此不必重复--source和--dest中相同的选项。如果--source和--dest的用户名密码不一样,需要单独各自指定,并且注意F和S参数。
3:--analyze:在--source或--dest上运行ANALYZE TABLE。字母's',将分析来源。 如果它包含'd',则将分析目的地。 您可以指定其中一个或两个
--analyze=ds
4:--ascend-first:升序索引优化,提供最左索引(多列主键)的升序。
5:--no-ascend: 不要使用升序索引优化。注意多列主键索引。
6:--ask-pass:连接MySQL时提示输入密码。
7:--buffer:缓冲区输出到--file并在提交时刷新,每次事务提交禁止刷写到磁盘,有操作系统决定刷写。该参数可以提高刷写到文件的性能,但崩溃可能会有数据丢失。
8:--commit-each:控制事务大小,每次提取、归档就提交。禁用--txn-size。
9:--config:以逗号分隔的配置文件列表; 如果指定,则必须是命令行上的第一个选项。
10:--database:D,连接时使用的默认数据库。
11:--delayed-insert:在insert后面添加delayed,延迟写入。
12:--dry-run:打印查询并退出而不做任何事情。
13:--file:要归档到的文件,使用以SELECT INTO OUTFILE相同的格式。如:--file '/var/log/archive/%Y-%m-%d-%D.%t'
%d Day of the month, numeric (01..31) %H Hour (00..23) %i Minutes, numeric (00..59) %m Month, numeric (01..12) %s Seconds (00..59) %Y Year, numeric, four digits %D Database name %t Table name
14:--for-update:在每个select语句后面加入for update。
15:--header:在--file顶部打印列标题。如果文件存在,不写,可以用LOAD DATA INFILE保存文件。
16:--high-priority-select:在每个select语句上加入HIGH_PRIORITY。
17:--host:连接的MySQL地址。
18:--ignore:insert语句加入ignore。
19:--local:添加NO_WRITE_TO_BINLOG参数,OPTIMIZE 和 ANALYZE不写binlog。
20:--low-priority-delete:每个delete语句加入LOW_PRIORITY。
21:--low-priority-insert:每隔insert和replace语句加入LOW_PRIORITY。
22:--max-lag:默认1s,由--check-slave-lag给出的从延迟。获取行时查看从库,如果slave的延迟大于选项的值,或者slave没有运行(因此它的滞后为NULL),则pt-table-checksum会休眠--check-interval seconds,然后再次查看滞后。 它会一直重复,直到slave小于该参数,然后继续获取并归档该行。
23:--no-delete:不要删除存档的行,默认会删除。不允许--no-ascend,因为启用它们都会导致无限循环。
24:--optimize:在--source或--dest上运行之后OPTIMIZE TABLE。
25:--output-format:与--file一起使用以指定输出格式,格式相当于FIELDS TERMINATED BY','OPTIONALLY ENCLOSED BY'''。
26:--password:-p,连接MySQL时使用的密码。 如果密码包含逗号,则必须使用反斜杠进行转义。
27:--pid:创建给定的PID文件。 如果PID文件已存在并且其包含的PID与当前PID不同,则该工具将不会启动。 但是,如果PID文件存在且其包含的PID不再运行,则该工具将使用当前PID覆盖PID文件。 退出工具时会自动删除PID文件。
28:--port:-P,连接MySQL时的端口。
29:--primary-key-only:仅限主键列。用于指定具有主键列的--columns的快捷方式,当DELETE语句只需要主键列时,它可以避免获取整行。
30:--progress:每多少行打印进度信息:打印当前时间,已用时间以及每X行存档的行数。
31:--purge:清除而不是归档; 允许省略--file和--dest。如果只想清除行,请考虑使用--primary-key-only指定表的主键列。 这样可以防止无缘无故地从服务器获取所有列。
32:--quick-delete:delete语句里添加quick。
33:--quite:-q,不打印任何输出,包括--statistics的输出,对--why-quit的输出无效。
34:--replace:replace into代替insert into。
35:--retries:每次超时或死锁的重试次数,默认1。
36:--run-time:退出前的时间。可选后缀s =秒,m =分钟,h =小时,d =天; 默认s
37:--[no]safe-auto-increment:不要使用最大AUTO_INCREMENT归档行,默认yes。防止在服务器重新启动时重新使用AUTO_INCREMENT值。
38:--sentinel:优雅的退出操作。指定的文件的存在将导致pt-archiver停止存档并退出。 默认值为/tmp/pt-archiver-sentinel。
39:--slave-user:连接从库的用户。用户必须存在于所有从属服务器上
40:--slave-password:连接从库的密码。用户的密码在所有从站上必须相同。
41:--set-vars:逗号分隔的variable = value对列表中设置MySQL变量。如:--set-vars wait_timeout = 500
42:--share-lock:在SELECT语句里添加LOCK IN SHARE MODE。
43:--skip-foreign-key-checks:使用SET FOREIGN_KEY_CHECKS = 0禁用外键检查。
44:--sleep:指定SELECT语句之间的休眠时间。 默认不sleep。 未提交事务,并且在休眠之前不会刷新--file文件。如果指定了--commit-each,则在休眠之前发生提交和刷新。
45:--sleep-coef:pt-archiver将在最后一次SELECT乘以指定系数的查询时间内休眠。在每个SELECT之间休眠不同的时间,具体取决于SELECT所花费的时间。
46:--socket:-S,用于连接的套接字文件。
47:--statistics:收集并打印时间统计信息。
Started at 2008-07-18T07:18:53, ended at 2008-07-18T07:18:53 Source: D=db,t=table SELECT 4 INSERT 4 DELETE 4 Action Count Time Pct commit 10 0.1079 88.27 select 5 0.0047 3.87 deleting 4 0.0028 2.29 inserting 4 0.0028 2.28 other 0 0.0040 3.29 前两行(或三行)显示时间以及源表和目标表。接下来的三行显示了提取,插入和删除的行数。 其余行显示计数和时间。列是操作,操作计时的总次数,花费的总时间以及程序总运行时间的百分比。行按照总时间下降的顺序排序。最后一行是剩余的时间没有明确归因于任何东西。操作将根据命令行选项而有所不同。 如果给出了--why-quit,它的行为会略有改变。此选项使其打印退出的原因,即使只是因为没有更多的行。
48:--stop:通过创建sentinel文件停止运行实例。
49:--txn-size:每个事务的行数,默认1。指定每个事务的大小(行数)。0完全禁用事务。在pt-archiver处理这么多行之后,如果指定该参数,它会提交--source和--dest,并刷新--file给出的文件。
此参数对性能至关重要。如果要从实时服务器(例如正在执行大量OLTP工作)进行存档,则需要在事务大小和提交开销之间选择良好的平衡。较大的事务会产生更多的锁争用和死锁,但较小的事务会导致更频繁的提交开销,如果没有从事务存储引擎进行归档,则可能需要禁用事务。
50:--user:-u,连接MySQL时的用户。
51:--version:查看版本号。
52:--[no]version-check:不检查版本号,默认yes。适用于RDS。
53:--where:指定WHERE子句以限制存档的行。 子句里不要包含单词WHERE,不需要WHERE子句,请使用--where 1=1。如:
--where 'ts < current_date - interval 90 day'
54:--limit:限制检索要归档的行的SELECT语句返回的行数,默认是1。这可能会导致与其他查询的更多争用,具体取决于存储引擎,事务隔离级别和--for-update等选项。
55:--bulk-delete:使用单个DELETE语句批量删除每个行块。该语句删除块的第一行和最后一行之间的每一行,隐含--commit-each。
56:--[no]bulk-delete-limit:添加--limit到--bulk-delete语句,默认yes。
57:--bulk-insert:使用LOAD DATA LOCAL INFILE插入每个行块。 比使用INSERT语句一次插入行快得多。 通过为每个行块创建一个临时文件,并将行写入此文件而不是插入它来实现的。此选项会强制使用批量删除。
58:--charset:-A,设置默认字符集。
59:--[no]check-charset:不检查字符集, 禁用此检查可能会导致文本被错误地从一个字符集转换为另一个字符集。进行字符集转换时,禁用此检查可能有用。
60:--[no]check-columns:检查--source和--dest具有相同的列,默认yes。它不检查列顺序,数据类型等。它只检查源中的所有列是否存在于目标中。存在差异则退出。不检查则用参数–no-check-columns。
61:--columns:指定归档的列,以逗号分隔的列的列表以获取写入文件并插入目标表。 如果指定,将忽略其他列,除非它需要将它们添加到SELECT语句以提升索引或删除行。
62:--check-slave-lag:暂停归档,直到指定的DSN的slave延迟小于--max-lag。可以多次指定此选项以检查多个从库。
63:--check-interval:检查从库延迟的间隔时间,默认1s。或则每100行执行一次检查。
64:--why-quit:除非行耗尽,否则打印退出原因。
注意:下面几个参数都是互斥的,只能选其一:
"--ignore" and "--replace" are mutually exclusive. "--txn-size" and "--commit-each" are mutually exclusive. "--low-priority-insert" and "--delayed-insert" are mutually exclusive. "--share-lock" and "--for-update" are mutually exclusive. "--analyze" and "--optimize" are mutually exclusive. "--no-ascend" and "--no-delete" are mutually exclusive.
使用场景
注意: 归档的表大小写敏感,表必须至少有一个索引(Cannot find an ascendable index in table )。
①:导出到文件,不删除源数据(--no-delete,默认删除):
pt-archiver --source u=root,p=dba,h=100.47.47.47,P=16500,D=sbtest,t=abc --file=/tmp/%Y-%m-%d-%D.%t --where="1=1" --no-delete --no-safe-auto-increment --progress=1000 --statistics
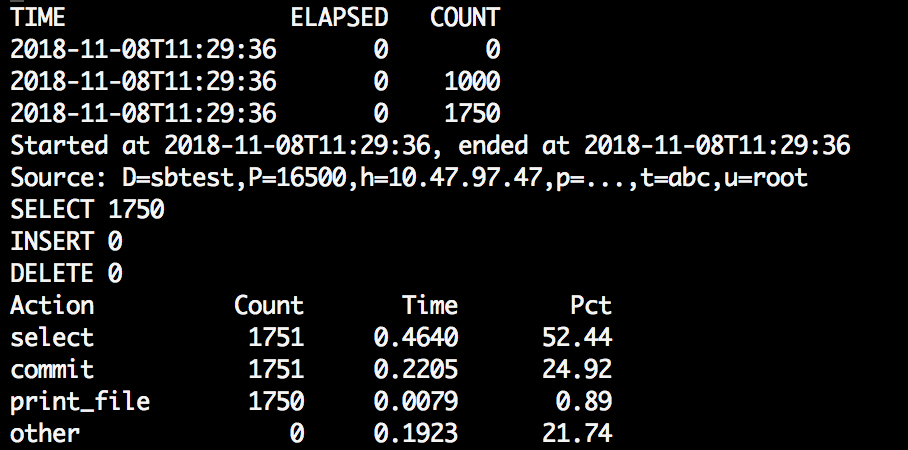
分析:从general_log里看到的流程是:source服务器读取一条,file写入一条,可以通过--txn-size进行指定行数的提交。这里需要注意的是,根据自增id进行归档的话,默认最大的id不会进行归档,需要添加参数:--no-safe-auto-increment 才能对最大id进行处理。
②:删除,不导出和迁移:
pt-archiver --source u=root,p=dba,h=100.47.47.47,P=16500,D=sbtest,t=abc --purge --where="1=1" --no-safe-auto-increment --progress=100 --statistics
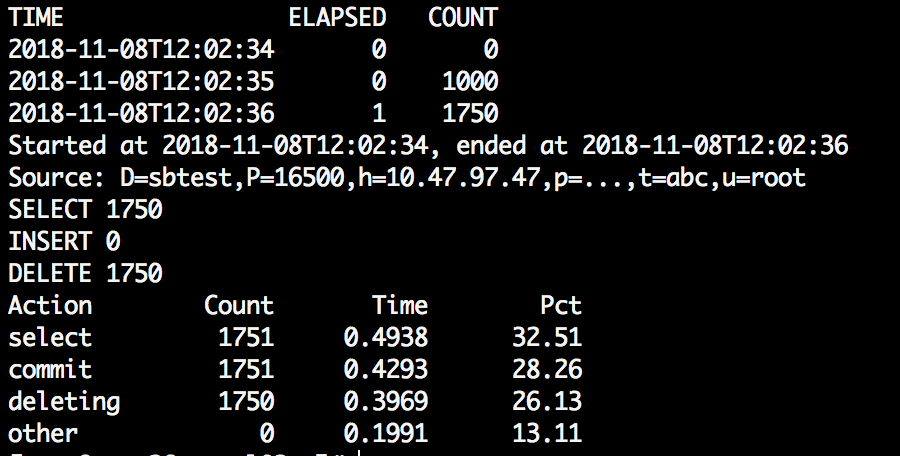
分析: 从general_log里看到的流程是:source服务器读取一条再删除一条提交,可以加上--txn-size进行多个删除放到一个事务提交。
③:全表归档(迁移),源表不删除,非批量
pt-archiver --source u=root,p=dba,h=100.47.47.47,P=16500,D=sbtest,t=abc --dest u=root,p=dba,h=100.47.47.47,P=17500,D=sbtest,t=ABC --where="1=1" --progress=1000 --statistics --no-delete
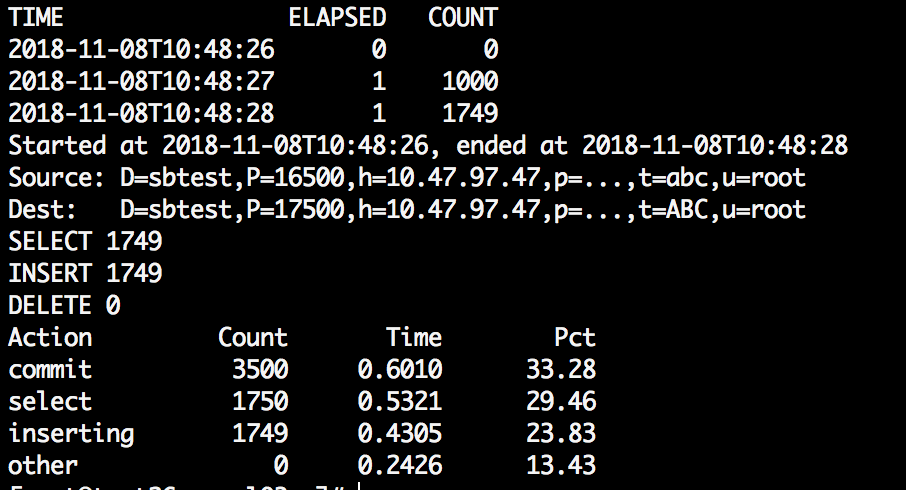
分析:从general_log里看到的流程是:source服务器读取一条,dest服务器写入一条并commit,source再delete并commit(如果删除源数据)。
④:全表归档(迁移),源表不删除,批量插入
pt-archiver --source u=root,p=dba,h=100.47.47.47,P=16500,D=sbtest,t=abc --dest u=root,p=dba,h=100.47.47.47,P=17500,D=sbtest,t=ABC --where="1=1" --progress=1000 --limit=1000 --statistics --bulk-insert --txn-size=1000 --no-delete

分析:从general_log里看到的流程是:source服务器读取一个范围【FORCE INDEX(`PRIMARY`) WHERE (1=1) AND (`id` < '4999') AND ((`id` > '2733'))】,dest服务器通过【LOAD DATA LOCAL INFILE】进行批量插入。
⑤:全表归档(迁移),源表删除,批量插入,批量删除
pt-archiver --source u=root,p=dba,h=100.47.47.47,P=16500,D=sbtest,t=abc --dest u=root,p=dba,h=100.47.47.47,P=17500,D=sbtest,t=ABC --where="1=1" --progress=1000 --limit=1000 --statistics --bulk-insert --bulk-delete --txn-size=1000

分析:从general_log里看到的流程是:source服务器读取一个范围【FORCE INDEX(`PRIMARY`) WHERE (1=1) AND (`id` < '4999') AND ((`id` > '2733'))】,dest服务器通过【LOAD DATA LOCAL INFILE】进行批量插入,source再delete【WHERE (((`id` >= '1'))) AND (((`id` <= '2733'))) AND (1=1) LIMIT 1000】并commit。这里需要注意的是,根据自增id进行归档的话,默认最大的id不会进行归档,需要添加参数:--no-safe-auto-increment 才能对最大id进行处理。
⑥:指定条件归档,源表删除,批量(每1000个插入提交一次),如果源表不删除,加上--no-delete即可。
pt-archiver --source u=root,p=dba,h=100.47.47.47,P=16500,D=sbtest,t=abc --dest u=root,p=dba,h=100.47.47.47,P=17500,D=sbtest,t=ABC --where="id<=49999" --progress=1000 --statistics --bulk-insert --bulk-delete --txn-size=1000 --limit=1000
⑦:指定索引的归档,不走自增主键索引。参数:i
pt-archiver --source u=root,p=dba,h=100.47.47.47,P=16500,D=sbtest,t=abc,i=idx_age --dest u=root,p=dba,h=100.47.47.47,P=17500,D=sbtest,t=ABC --where="age >=80000 and age<100000" --progress=1000 --statistics --bulk-insert --bulk-delete --txn-size=1000 --limit=1000 --no-delete
⑧:有从库的归档,从库延迟大于1s就暂停归档:--check-slave-lag
pt-archiver --source u=root,p=dba,h=100.47.47.47,P=16500,D=sbtest,t=abc,i=idx_age --dest u=root,p=dba,h=100.47.47.47,P=17500,D=sbtest,t=ABC --where="age >=100000 and age<150000" --progress=1000 --statistics --bulk-insert --bulk-delete --txn-size=1000 --limit=1000 --no-delete --max-lag=1 --check-slave-lag u=root,p=dba,h=10.24.35.181,P=16500

当从库延迟小于--max-lag设置的时间之后,继续归档。要是有多个从库的话,继续指定--check-slave-lag参数,该参数可以重复指定多个从库。
⑨:不做任何操作,只打印要执行的查询语句
pt-archiver --source u=root,p=dba,h=100.47.47.47,P=16500,D=sbtest,t=abc,i=idx_age --dest u=root,p=dba,h=100.47.47.47,P=17500,D=sbtest,t=ABC --where="age >=80000 and age<100000" --progress=1000 --statistics --replace --txn-size=1000 --limit=1000 --no-delete --dry-run
![]()
⑩:常用的命令:归档到另一个数据库,源表删除,批量删除和插入,每1000次修改进行提交。跳过错误并且指定字符集连接。
pt-archiver --source u=root,p=dba,h=100.47.47.47,P=16500,D=sbtest,t=abc,i=idx_age --dest u=root,p=dba,h=100.47.47.47,P=17500,D=sbtest,t=ABC --no-version-check --charset=UTF8 --where="age >=100000 and age<500000" --ignore --txn-size=1000 --limit=1000 --bulk-delete --bulk-insert --progress=5000 --statistics --why-quit
可以根据自己的实际情况,进行相关参数的调整。另外其他相关参数说明:
--ignore或则--replace:归档冲突记录跳过或则覆盖,批量插入的时候因为是load data,索引看不到主键冲突记录的报错。要是非批量插入,则需要添加。 --sleep:指定两次SELECT语句的sleep时间.默认是没有sleep的。 --why-quit:打印退出的原因,归档数据正常完成的除外。 --charset=UTF8:指定字符集。 --analyze:结束归档后,优化表空间。
常用的参数:
| --where 'id<3000' | 设置操作条件 |
| --limit 10000 | 每次取1000行数据给pt-archive处理 |
| --txn-size 1000 | 设置1000行为一个事务提交一次 |
| --progress 5000 | 每处理5000行输出一次处理信息 |
| --statistics | 结束的时候给出统计信息:开始的时间点,结束的时间点,查询的行数,归档的行数,删除的行数,以及各个阶段消耗的总的时间和比例,便于以此进行优化。只要不加上--quiet,默认情况下pt-archive都会输出执行过程的 |
| --charset=UTF8 | 指定字符集为UTF8 |
| --no-delete | 表示不删除原来的数据,注意:如果不指定此参数,所有处理完成后,都会清理原表中的数据 |
| --bulk-delete | 批量删除source上的旧数据 |
| --bulk-insert | 批量插入数据到dest主机 (看dest的general log发现它是通过在dest主机上LOAD DATA LOCAL INFILE插入数据的) |
| --purge | 删除source数据库的相关匹配记录 |
| --local | 不把optimize或analyze操作写入到binlog里面(防止造成主从延迟巨大) |
| --analyze=ds | 操作结束后,优化表空间(d表示dest,s表示source) 默认情况下,pt-archiver操作结束后,不会对source、dest表执行analyze或optimize操作,因为这种操作费时间,并且需要你提前预估有足够的磁盘空间用于拷贝表。一般建议也是pt-archiver操作结束后,在业务低谷手动执行analyze table用以回收表空间 |
注意:批量操作和单条操作提交性能有近10倍的差距。
总结
pt-archiver实现的功能很简单,工具也很轻量,能非常好的对数据进行低影响的归档和删除,支持大部分场景。需要注意的是,毕竟是操作生产数据,使用之前还得多测试,根据实际情况进行参数的调整优化。

