mongodb集群故障转移实践
简介
NOSQL有这些优势:
- 大数据量,可以通过廉价服务器存储大量的数据,轻松摆脱传统mysql单表存储量级限制。
- 高扩展性,Nosql去掉了关系数据库的关系型特性,很容易横向扩展,摆脱了以往老是纵向扩展的诟病。
- 高性能,Nosql通过简单的key-value方式获取数据,非常快速。还有NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多。
- 灵活的数据模型,NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。
- 高可用,NoSQL在不太影响性能的情况,就可以方便的实现高可用的架构。比如mongodb通过mongos、mongo分片就可以快速配置出高可用配置。
- 支持查询、聚合、完全索引,包含内部对象
- 支持复制和故障转移、自动恢复
- 易扩展
在nosql数据库里,大部分的查询都是键值对(key、value)的方式。MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中最像关系数据库的。支持类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。所以这个非常方便,我们可以用sql操作MongoDB,从关系型数据库迁移过来,开发人员学习成本会大大减少。如果再对底层的sql API做一层封装,开发基本可以感觉不到mongodb和关系型数据库的区别。
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写;旨在为WEB应用提供可扩展的高性能数据存储解决方案。
安装mongodb
安装环境
操作系统:Centos7.2
mongodb版本: v3.6.1
下载安装
wget http://fastdl.mongodb.org/linux/mongodb-linux-x86_64-amazon-3.6.1.tgz tar zxvf mongodb-linux-x86_64-amazon-3.6.1.tgz mv /root/mongodb-linux-x86_64-amazon-3.6.1 /usr/local/mongodb/
创建数据/日志目录
mkdir -p /data/mongodb/{data, logs} mkdir /data/mongodb/data/mongod touch /data/mongodb/logs/mongo.logs
创建配置文件
mkdir /usr/local/mongodb/config cd /usr/local/mongodb/config && touch mongo.conf
配置文件
1. 普通配置文件示例
dbpath=/data/mongodb/data/mongod logpath=/data/mongodb/logs/mongo.log logappend=true replSet=mongo-rs bind_ip=0.0.0.0 port=27017 fork=true journal=true
mongodb3.x版本后就是要yaml语法格式的配置文件,下面是yaml配置文件格式如下:
官方yaml配置文件选项参考:https://docs.mongodb.org/manual/reference/configuration-options/#configuration-file
注意:只能使用空格,不支持tab键
2.yaml格式配置文件示例
storage:
dbPath: /data/mongodb/data/mongod
journal:
enabled: true
systemLog:
destination: file
path: /data/mongodb/logs/mongo.log
logAppend: true
logRotate: rename
net:
bindIp: 0.0.0.0
port: 27017
processManagement:
pidFilePath: /var/run/pid/mongodb.pid
fork: true
replication:
oplogSizeMB: 20480
replSetName: mongo-rs
配置文件参数说明
1.基本参数
--quiet # 安静输出 --port arg # 指定服务端口号,默认端口27017 --bind_ip arg # 绑定服务IP,若绑定127.0.0.1,则只能本机访问,不指定默认本地所有IP --logpath arg # 指定MongoDB日志文件,注意是指定文件不是目录 --logappend # 使用追加的方式写日志 --pidfilepath arg # PID File 的完整路径,如果没有设置,则没有PID文件 --keyFile arg # 集群的私钥的完整路径,只对于Replica Set 架构有效 --unixSocketPrefix arg # UNIX域套接字替代目录,(默认为 /tmp) --fork # 以守护进程的方式运行MongoDB,创建服务器进程 --auth # 启用验证 --cpu # 定期显示CPU的CPU利用率和iowait --dbpath arg # 指定数据库路径 --diaglog arg # diaglog选项 0=off 1=W 2=R 3=both 7=W+some reads --directoryperdb # 设置每个数据库将被保存在一个单独的目录 --journal # 启用日志选项,MongoDB的数据操作将会写入到journal文件夹的文件里 --journalOptions arg # 启用日志诊断选项 --ipv6 # 启用IPv6选项 --jsonp # 允许JSONP形式通过HTTP访问(有安全影响) --maxConns arg # 最大同时连接数 默认2000 --noauth # 不启用验证 --nohttpinterface # 关闭http接口,默认关闭27018端口访问 --noprealloc # 禁用数据文件预分配(往往影响性能) --noscripting # 禁用脚本引擎 --notablescan # 不允许表扫描 --nounixsocket # 禁用Unix套接字监听 --nssize arg (=16) # 设置信数据库.ns文件大小(MB) --objcheck # 在收到客户数据,检查的有效性, --profile arg # 档案参数 0=off 1=slow, 2=all --quota # 限制每个数据库的文件数,设置默认为8 --quotaFiles arg # number of files allower per db, requires --quota --rest # 开启简单的rest API --repair # 修复所有数据库run repair on all dbs --repairpath arg # 修复库生成的文件的目录,默认为目录名称dbpath --slowms arg (=100) # value of slow for profile and console log --smallfiles # 使用较小的默认文件 --syncdelay arg (=60) # 数据写入磁盘的时间秒数(0=never,不推荐) --sysinfo # 打印一些诊断系统信息 --upgrade # 如果需要升级数据库
2.Replicaton 参数
--fastsync # 从一个dbpath里启用从库复制服务,该dbpath的数据库是主库的快照,可用于快速启用同步 --autoresync # 如果从库与主库同步数据差得多,自动重新同步, --oplogSize arg # 设置oplog的大小(MB)
3.主/从参数
--master # 主库模式 --slave # 从库模式 --source arg # 从库 端口号 --only arg # 指定单一的数据库复制 --slavedelay arg # 设置从库同步主库的延迟时间
4.Replica set(副本集)选项
--replSet arg # 设置副本集名称 Sharding(分片)选项 --configsvr # 声明这是一个集群的config服务,默认端口27019,默认目录/data/configdb --shardsvr # 声明这是一个集群的分片,默认端口27018 --noMoveParanoia # 关闭偏执为moveChunk数据保存
启动
mongod --quiet -f /usr/local/mongodb/config/mongo.conf
配置文件里设置里fork:true,所以会在后台启动,值得注意的是,用到了”–fork”参数就必须启用”–logpath”参数,如不指定配置文件启动,如下:
mongod --dbpath=/data/mongodb/data/mongod --fork --logpath=/data/mongodb/logs/mongo.logs
集群搭建
官方不建议再使用主从集群模式,推荐的集群方式是Replica Set(副本集),主从模式其实就是一个单副本的应用,没有很好的扩展性和容错性。而副本集具有多个副本保证了容错性,就算一个副本挂掉了还有很多副本存在,并且解决了上面第一个问题“主节点挂掉了,整个集群内会自动切换”。
副本集的设计结构
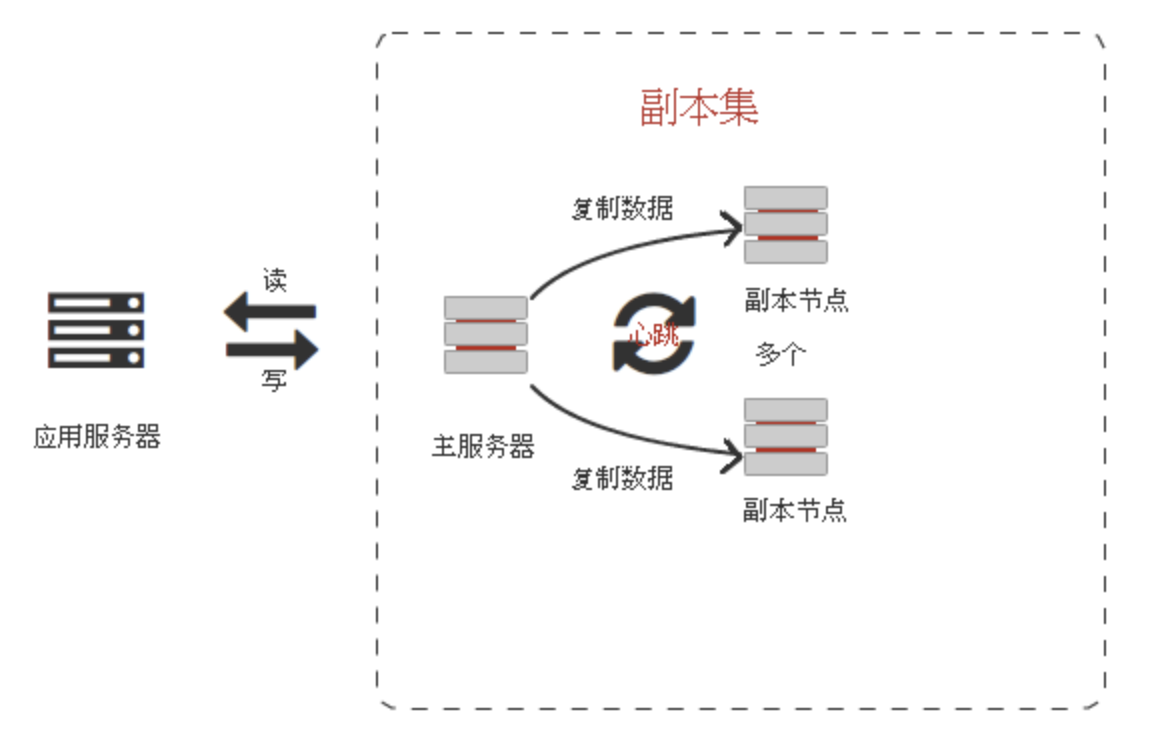
由图可以看到客户端连接到整个副本集,不关心具体哪一台机器是否挂掉。主服务器负责整个副本集的读写,副本集定期同步数据备份,一但主节点挂掉,副本节点就会选举一个新的主服务器,这一切对于应用服务器不需要关心。
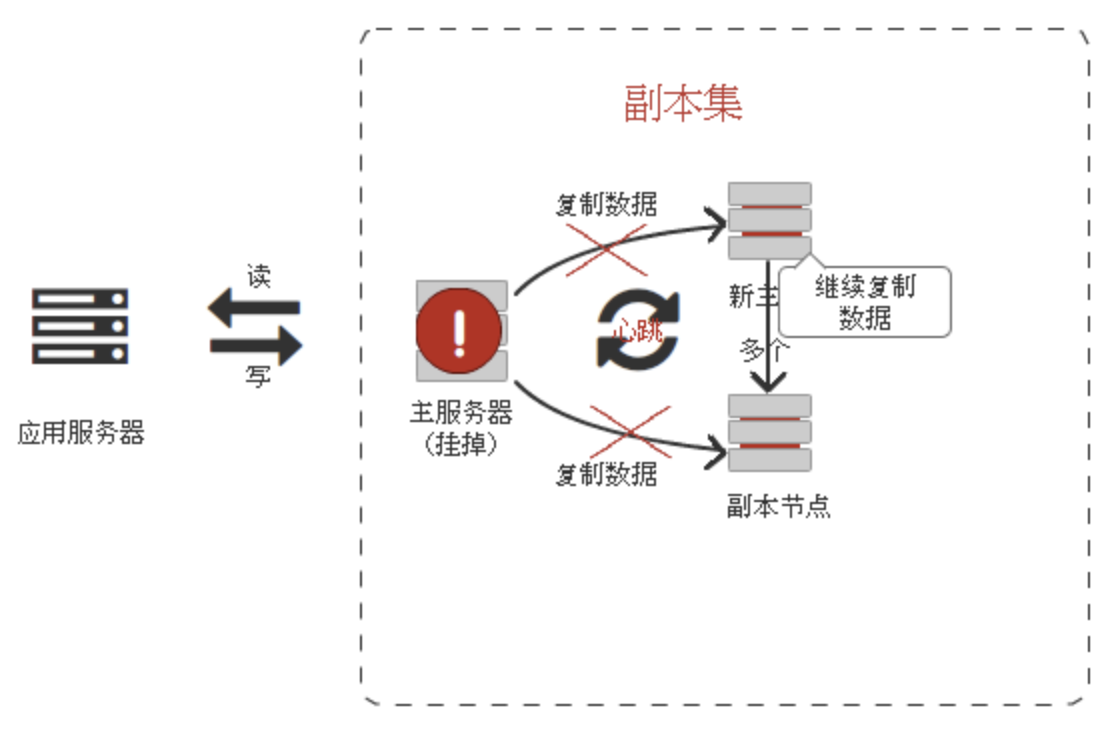
注意:
仲裁节点是一种特殊的节点,它本身并不存储数据,主要的作用是决定哪一个备节点在主节点挂掉之后提升为主节点,所以客户端不需要连接此节点。这里虽然只有一个备节点,但是仍然需要一个仲裁节点来提升备节点级别。
必须要有仲裁节点,没仲裁节点的话,主节点挂了备节点还是备节点。
配置步骤
准备三台机器
172.29.142.17 主 172.29.142.18 备 172.28.226.199 仲裁
按照第二步安装依次在三台机器上安装并启动
/usr/local/mongodb/bin/mongod --quiet -f /usr/local/mongodb/config/mongo.conf
初始化集群配置
三台服务启动并不能表示他们在一个集群,因此需要将集群初始化。连接任意一个节点(不要是仲裁点),执行如下:
rs.initiate({ _id:"mongo-rs", #集群名称 members:[ {_id:0,host:'172.29.142.18:27017',priority:2}, #主 {_id:1,host:'172.29.142.17:27017',priority:1}, #备 {_id:2,host:'172.28.226.199:27017',arbiterOnly:true}] #仲裁节点 })
成功上面会返回OK,然后查看集群状态,下面是在备节点上执行的
rs.status()
返回集群的名称和members信息,如:


{ "set" : "mongo-rs", "date" : ISODate("2018-06-26T14:56:08.032Z"), "myState" : 2, "term" : NumberLong(2), "syncingTo" : "172.29.142.18:27017", "heartbeatIntervalMillis" : NumberLong(2000), "optimes" : { "lastCommittedOpTime" : { "ts" : Timestamp(1530024958, 1), "t" : NumberLong(2) }, "appliedOpTime" : { "ts" : Timestamp(1530024958, 1), "t" : NumberLong(2) }, "durableOpTime" : { "ts" : Timestamp(1530024958, 1), "t" : NumberLong(2) } }, "members" : [ { "_id" : 0, "name" : "172.29.142.18:27017", "health" : 1.0, "state" : 1, "stateStr" : "PRIMARY", "uptime" : 382251, "optime" : { "ts" : Timestamp(1530024958, 1), "t" : NumberLong(2) }, "optimeDurable" : { "ts" : Timestamp(1530024958, 1), "t" : NumberLong(2) }, "optimeDate" : ISODate("2018-06-26T14:55:58.000Z"), "optimeDurableDate" : ISODate("2018-06-26T14:55:58.000Z"), "lastHeartbeat" : ISODate("2018-06-26T14:56:07.329Z"), "lastHeartbeatRecv" : ISODate("2018-06-26T14:56:06.453Z"), "pingMs" : NumberLong(0), "electionTime" : Timestamp(1529642739, 1), "electionDate" : ISODate("2018-06-22T04:45:39.000Z"), "configVersion" : 1 }, { "_id" : 1, "name" : "172.29.142.17:27017", "health" : 1.0, "state" : 2, "stateStr" : "SECONDARY", "uptime" : 382552, "optime" : { "ts" : Timestamp(1530024958, 1), "t" : NumberLong(2) }, "optimeDate" : ISODate("2018-06-26T14:55:58.000Z"), "syncingTo" : "172.29.142.18:27017", "configVersion" : 1, "self" : true }, { "_id" : 2, "name" : "172.28.226.199:27017", "health" : 1.0, "state" : 7, "stateStr" : "ARBITER", "uptime" : 168617, "lastHeartbeat" : ISODate("2018-06-26T14:56:06.895Z"), "lastHeartbeatRecv" : ISODate("2018-06-26T14:56:04.092Z"), "pingMs" : NumberLong(35), "configVersion" : 1 } ], "ok" : 1.0 }
返回参数说明
“health” : 1, #代表机器正常
“stteStr” : “PRIMARY”, #代表是主节点,可读写,其中有以下几下状态:
STARTUP:刚加入到复制集中,配置还未加载
STARTUP2:配置已加载完,初始化状态
RECOVERING:正在恢复,不适用读
ARBITER: 仲裁者
DOWN:节点不可到达
UNKNOWN:未获取其他节点状态而不知是什么状态,一般发生在只有两个成员的架构,脑裂
REMOVED:移除复制集
ROLLBACK:数据回滚,在回滚结束时,转移到RECOVERING或SECONDARY状态
FATAL:出错。查看日志grep “replSet FATAL”找出错原因,重新做同步
PRIMARY:主节点
SECONDARY:备份节点
测试副本集数据复制
注意:mongodb默认是从主节点读写数据的,副本节点上不允许读,需要设置副本节点可以读:
repset:SECONDARY> db.getMongo().setSlaveOk();
这个很好测试,直接在主节点插入一条数据,在备节点查询即可
或者可以使用客户端以集群模式连接mongo集群:
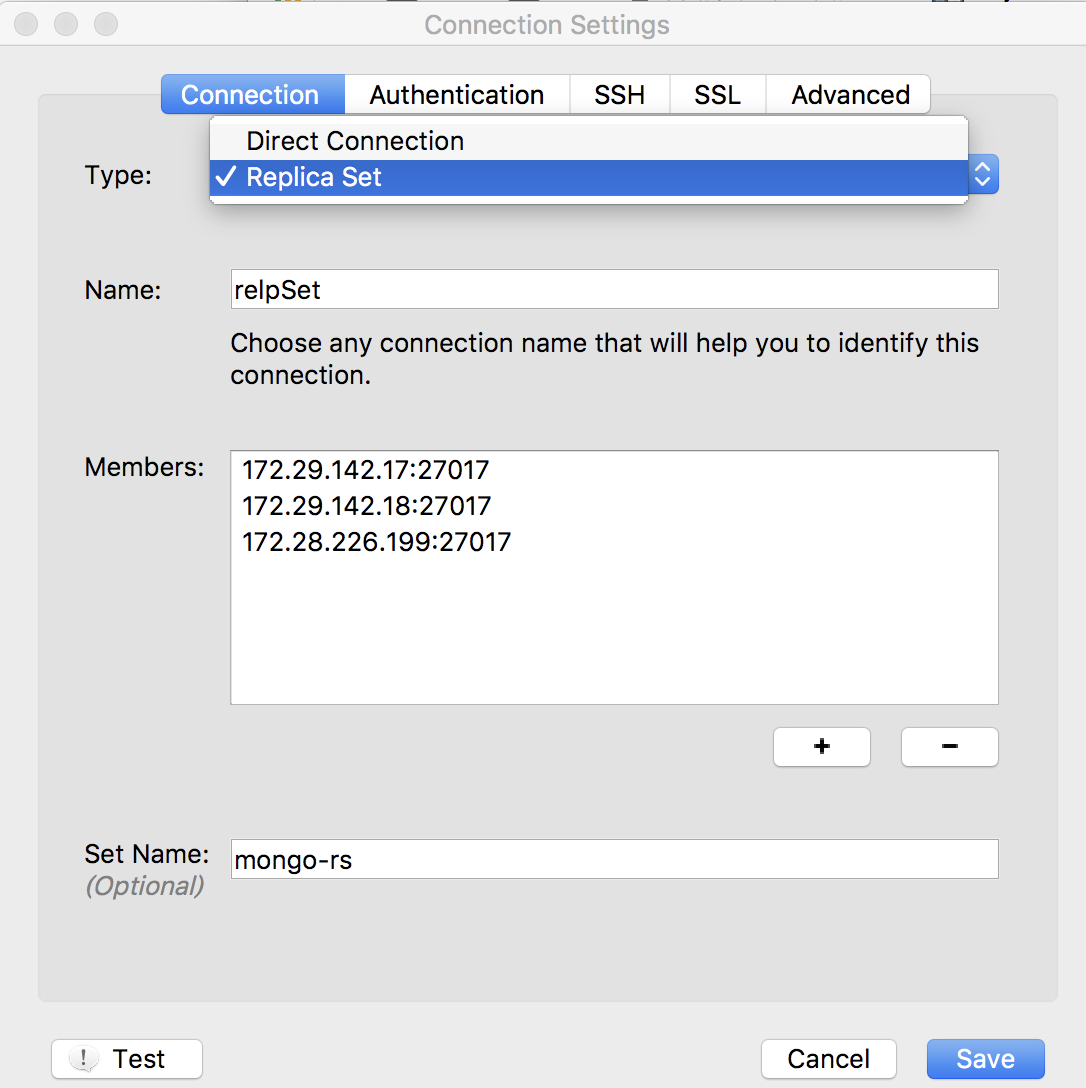
点Test 测试连接:
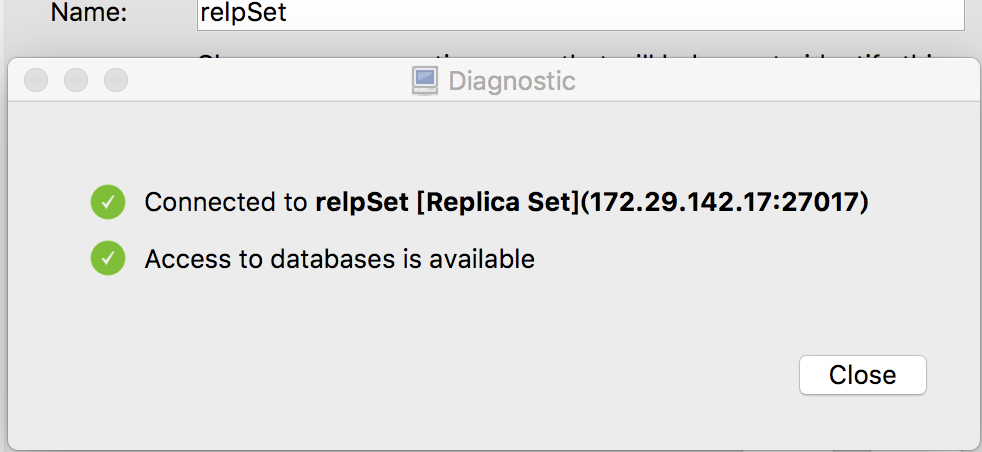
三个节点的数据是同步的。
测试副本集故障转移功能
1.查看集群当前状态,如上返回
当前172.29.142.18是Primary, 172.29.142.17是Secondary
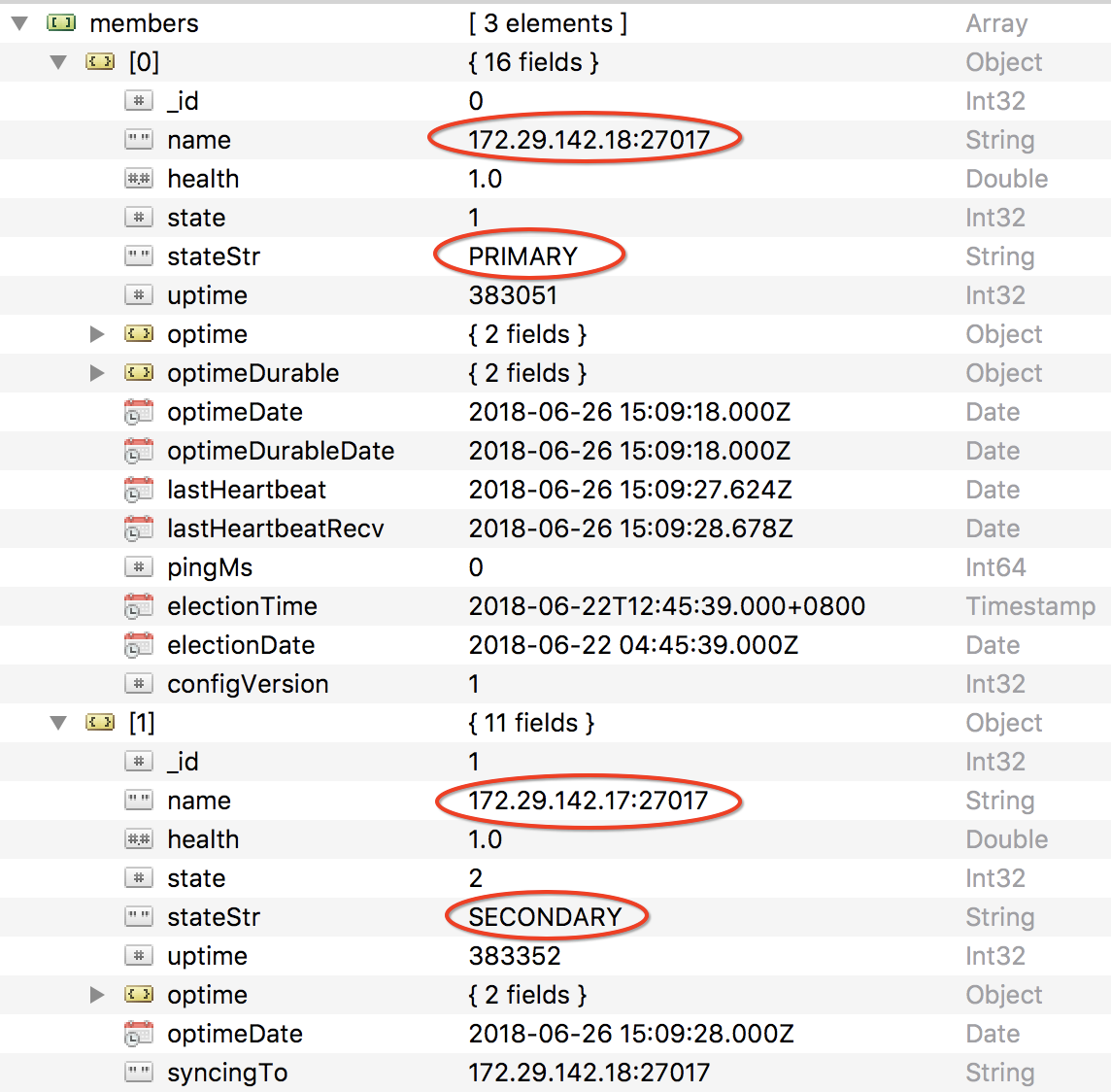
2.停掉主节点172.29.142.18,查看另两台的选票结果
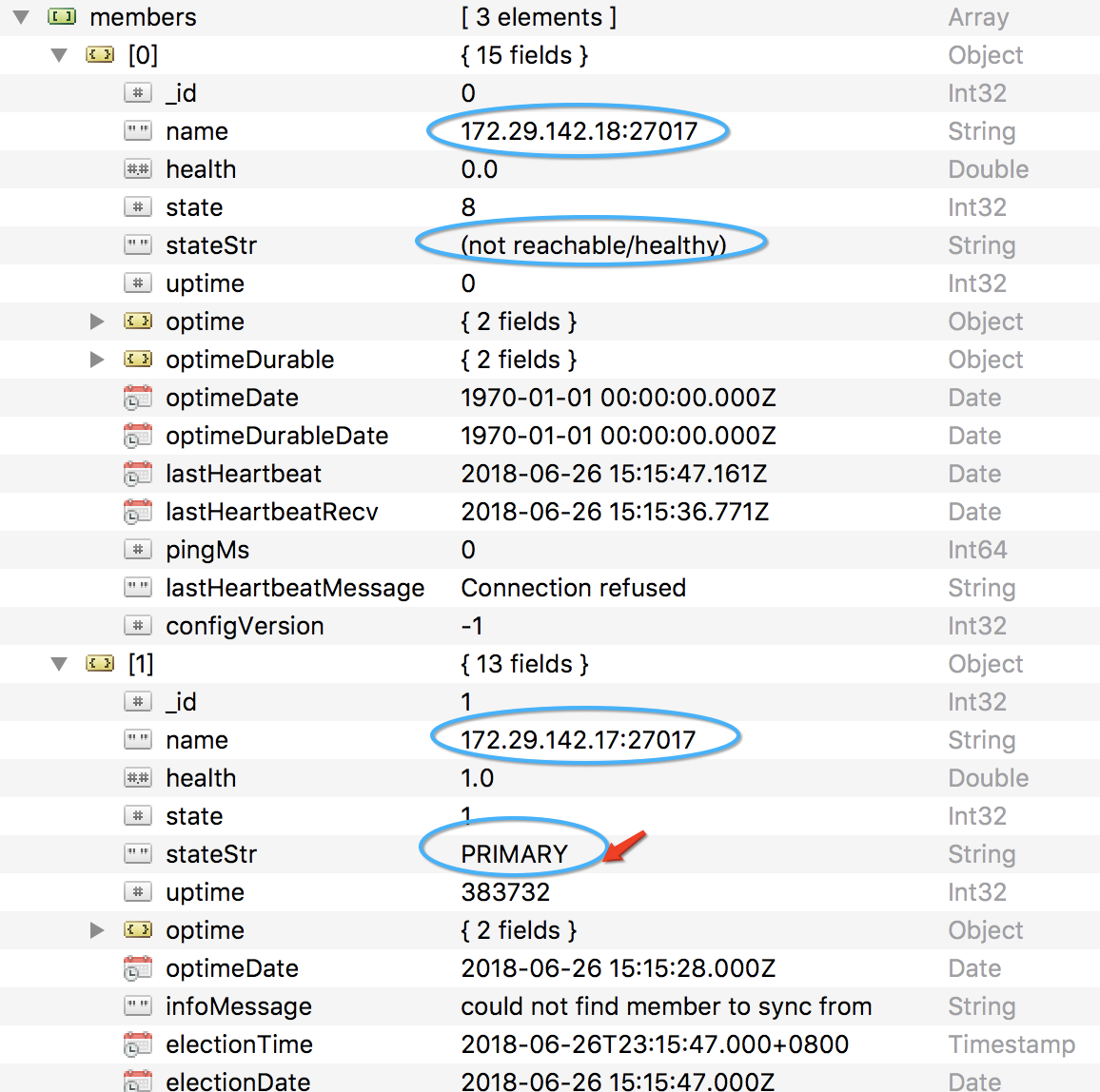
此时17变成了主节点,原先的仲裁节点不变,重新启动第一次的Primary,则主节点又发生变化,不再截图,整个过程业务是不中断的。只要有一台可用即可。
Nodejs连接mongo集群示例
这里强烈不推荐连接单台mongo服务,因为如果一个mongo节点挂掉,业务就挂了,连接集群的话有一台可用就行。
下面举了个nodejs连接mongo集群的示例:
const mongoose = require('mongoose');
let url = "mongodb://172.29.142.17:27017/testdb,mongodb://172.29.142.18:27017/testdb,mongodb://172.28.226.199:27017/testdb";
let options = {
"replset": {
"ha": true,
"haInterval": 1000,
"replicaSet": "mongo-rs",
"connectWithNoPrimary": true,
"auto_reconnect": true,
"socketOptions": {
"keepAlive": 120,
connectTimeoutMS: 30000
}
}
}
mongoose.connect(url, options).connection
.on('error', function (error) {
console.log('mongo 连接错误', error)
}).on('disconnected', mongoConnect).once('open', function () {
console.log('mongo 连接成功');
})
reference:
https://blog.csdn.net/luonanqin/article/details/8497860
https://blog.csdn.net/wangshuang1631/article/details/53857319

 浙公网安备 33010602011771号
浙公网安备 33010602011771号