python小专题——JSON
python对json的相关操作
说实话,不做前端开发,对json真没有太特殊的感情,最近遇到python操作json,束手无策,也准备简单了解下相关知识。以前刚听到json的时候,总把它误以为一种语言,不料,它却是一种数据结构。我按了tab键发现json的方法很少,只有6个,并且两两互逆。查看json的使用方法,除了官方的文档(http://docs.python.org/2/library/json.html),还可以一个命令解决:>>> help(json),看了这个说明之后,然后下面所有的都是废话了。不过介于这样看不太方便,我还是准备"copy"一份到这里,呵呵~~~
首先JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,或者可理解为一种通讯方式,能被WEB所识别和公认的数据类型,是“名称/值”对的集合(A collection of name/value pairs。在不同的语言,它有不同的表现方式,如:对象(object),纪录(record),结构(struct),字典(dictionary),哈希表(hash table),有键列表(keyed list),或者关联数组 (associative array)。值的有序列表(An ordered list of values)。
dumps方法和loads方法
简单来理解就是:dumps方法——将python类型的数据编码成json类型
loads方法——将json类型的数据解码成python类型
首先学习一下对简单数据类型的encoding,使用json.dumps方法对简单数据类型进行编码:
>>> import json >>> pyobj=[[1,2,3],123,123.123,'abc',{'key1':(1,2,3),'key2':(4,5,6)}] >>> encodedjson = json.dumps(pyobj) >>> print repr(pyobj) [[1, 2, 3], 123, 123.123, 'abc', {'key2': (4, 5, 6), 'key1': (1, 2, 3)}] >>> print encodedjson [[1, 2, 3], 123, 123.123, "abc", {"key2": [4, 5, 6], "key1": [1, 2, 3]}]
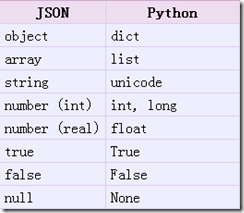
仔细对比下两个print的结果还是有区别的(有些数据类型发生了变化),在json的编码过程中,会存在从python原始类型向json类型的转化过程,具体的转化对照如下:

上述看出,json.dumps()方法返回了一个str对象encodedjson,接下来在对encodedjson进行decode,得到原始数据类型,需要使用的json.loads()函数:
>>> decodejson=json.loads(encodedjson) >>> print type(decodejson) #查看解码后的数据类型 <type 'list'> >>> print decodejson[4]['key1'] [1, 2, 3] >>> print decodejson [[1, 2, 3], 123, 123.123, u'abc', {u'key2': [4, 5, 6], u'key1': [1, 2, 3]}]
loads方法原始的对象,但发生了一些数据类型的转化。比如,上例中‘abc’转化为了unicode类型。从json到python的类型转化对照如下:
json.dumps方法提供了很多好用的参数可供选择,比较常用的有sort_keys(对dict对象进行排序,我们知道默认dict是无序存放的),separators,indent等参数。
排序功能使得存储的数据更加有利于观察,也使得对json输出的对象进行比较,例如:

上例中,本来data1和data2数据应该是一样的,但是由于dict存储的无序特性,造成两者无法比较。因此两者可以通过排序后的结果进行存储就避免了数据比较不一致的情况发生,但是排序后再进行存储,系统必定要多做一些事情,也一定会因此造成一定的性能消耗,所以适当排序是很重要的。
indent参数是缩进的意思,它可以使得数据存储的格式变得更加优雅。

输出的数据被格式化之后,变得可读性更强,但是却是通过增加一些冗余的空白格来进行填充的。json主要是作为一种数据通信的格式存在的,而网络通信是很在乎数据的大小的,无用的空格会占据很多通信带宽,所以适当时候也要对数据进行压缩。separator参数可以起到这样的作用,该参数传递是一个元组,包含分割对象的字符串。

通过移除多余的空白符,达到了压缩数据的目的,而且效果还是比较明显的。
另一个比较有用的dumps参数是skipkeys,默认为False。 dumps方法存储dict对象时,key必须是str类型,如果出现了其他类型的话,那么会产生TypeError异常,如果开启该参数,设为True的话,则会比较优雅的过度。
>>> data = {'b':789,'c':456,(1,2):123}
>>> print json.dumps(data,skipkeys=True)
{"c": 456, "b": 789}
当然还有一些其他参数,完整的参数是:
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True,allow_nan=True,
cls=None, indent=None, separators=None, encoding="utf-8",default=None,
sort_keys=False, **kw)
上述都是默认的值,当然可以对它进行改变,ensure_ascii默认是true,所有的非ASCII码都会以\uXXXX的序列显示出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号