【python第八日】类
类、对象、实例
类:具有相同特征的一类事物(人、狗、老虎)
对象/实例:具体的某一个事物(隔壁阿花、楼下旺财)
实例化:类——>对象的过程
class Person: #定义一个人类
“”“类的文档”“” role = 'person' #人的角色属性都是人 数据属性 def walk(self): #人都可以走路,也就是有一个走路方法 方法属性 print("person is walking...")
看属性用Person.__dict__
新式类与经典类:
在Python 2及以前的版本中,由任意内置类型派生出的类(只要一个内置类型位于类树的某个位置),都属于“新式类”,都会获得所有“新式类”的特性;反之,即不由任意内置类型派生出的类,则称之为“经典类”。
“新式类”和“经典类”的区分在Python 3之后就已经不存在,在Python 3.x之后的版本,因为所有的类都派生自内置类型object(即使没有显示的继承object类型),即所有的类都是“新式类”。
类初始化
data1 = "外部数据" class A: data1 = "内部数据" def __init__(self, name): print("这里是初始化方法:", self) print("内部数据为:", self.data1) #加上self表示内部数据 print("外部数据为:", data1) #不加self表示外部数据 self.name = name return None #一般不谢,但是如果要返回,只可以返回None类型 def __new__(cls, *args, **kwargs): print("这里是类构造方法:", cls) print("参数为:", *args, **kwargs) return object.__new__(cls) b = A("爸爸")
- 用类内部数据时候,用self.xxxx,否则指的是外部数据
- 构造方法和初始化方法分开了
类方法、静态方法、实例方法、普通方法、抽象方法、属性
类方法、静态方法、实例方法、普通方法
class Chinese: def c1(self): #实例方法,只可以被实例调用,类一般不可以调用,除非给一个参数 print("c1",self) @classmethod def c2(cls): #类方法。实例和类都可以调用,参数,是调用者的类 print("c2:",cls) @staticmethod def c3(): #静态方法,类和实例都可以调用 print("c3:") def c4(): #类普通方法,只可以被类调用 print("c4") Chinese.c4() #c4 Chinese.c3() #c3: Chinese.c2() #c2: <class '__main__.Chinese'> # Chinese.c1() #需要个东西,所以这个处所 Chinese.c1("test") #c1 test a = Chinese() a.c1() #c1 <__main__.Chinese object at 0x00FA10B0> 是对象 a.c2() # c2: <class '__main__.Chinese'> 传的是类,不是实例 a.c3() #c3: # a.c4() #c4不需要东西所以不能用
抽象方法与接口
抽象方法必须在子类中实现,本身基类不可实例化
import abc class A(metaclass = abc.ABCMeta): @abc.abstractmethod def a1(self): print("这里是a1",self) def a2(self): print("这里是a2",self) # a = A() #不可以实例化 # a.a1() # a.a2() class A_1(A): def a1(self): print("这里是是A_1的a1",self) b = A_1() b.a1() b.a2()
输出如下:
这里是是A_1的a1 <__main__.A_1 object at 0x009A5370>
这里是a2 <__main__.A_1 object at 0x009A5370>
数据属性和函数属性
b_data_new = "外部数据区" class B(): b_data = "B的数据区" def b(self): print("这里是b的活动区,b_data的值为",b_data) class child_B(B): pass b_instance = B() b_child_instance = child_B() print(B.__dict__) print(child_B.__dict__) print(b_instance.__dict__) print(b_child_instance.__dict__) b_instance.b_data = "这里是实例的数据区" child_B.b_data = "这里B儿子的类数据区" print(B.__dict__) print(child_B.__dict__) print(b_instance.__dict__) print(b_child_instance.__dict__) print(b.b_data_new) #报错

- 类只查找自己的数据区,B.XXXXX,如果没有就报错,但是如果前面没有B.表示的外部数据,或者局部变量
- 实例先查找自己的数据区,如果没有查找B的,再没有报错
- 儿子类,同上
属性的增删改查
class A:
data1 = "吃饭"
list1 = [1,2]
def a(self):
print("这是A的a的方法")
#查看属性
print(A.__dict__) #{'__module__': '__main__', 'data1': '吃饭', 'list1': [1, 2], 'a': <function A.a at 0x00AB8DF8>, '__dict__': <attribute '__dict__' of 'A' objects>, '__weakref__': <attribute '__weakref__' of 'A' objects>, '__doc__': None}
print(A.data1, A.a) #吃饭 <function A.a at 0x00AB8DF8>
#增加
A.data2 = "游泳" #添加数据
def a1():
print("这是外部a1函数:", A.data1) #这是外部a1函数: 吃饭 不能直接用哪个data1 否则是外面的数据
A.a1 = a1 #添加方法
A.a1()
A.a2 = lambda x,y:x+y #添加方法
print(A.a2(1,2)) #3
#改同添加
#删除
del A.data2
p = A()
p.data4 = "4"
p.data1 = "1"
print(p.__dict__) # {'data4': '4', 'data1': '1'}
p.list1.append(3)
print(p.__dict__) #{'data4': '4', 'data1': '1'}
print(A.__dict__) #'__module__': '__main__', 'data1': '吃饭', 'list1': [1, 2, 3]
- 实例修改数据时候,如果是直接赋值,则在实例字典中修改属性
- 如果是使用append,extend修改数据时候,是修改原有数据,即类中的数据
组合
组合指的是,在一个类中以另外一个类的对象作为数据属性,称为类的组合。
class Weapon: def prick(self,obj): # 这是该装备的主动技能,扎死对方 obj -= 500 # 假设攻击力是500 print(obj) class Person: # 定义一个人类 role = 'person' # 人的角色属性都是人 def __init__(self, name): self.name = name # 每一个角色都有自己的昵称; self.weapon = Weapon() # 给角色绑定一个武器; egg = Person('egon') obj = 1000 egg.weapon.prick(obj)
继承 多态 封装 派生 接口 反射
继承 派生
继承:指的是父亲遗传给儿子,类没变,比如上一辈,下一辈
派生:指的是出现新的类,比如动物变成狗
父类:子类的基类,用__base__查看,或者超类
继承顺序 C3算法
通用计算公式为:
mro(Child(Base1,Base2)) = [ Child ] + merge( mro(Base1), mro(Base2), [ Base1, Base2] ) (其中Child继承自Base1, Base2)
-
表头:
列表的第一个元素 -
表尾:
列表中表头以外的元素集合(可以为空) -
示例
列表:[A, B, C]
表头是A,表尾是B和C
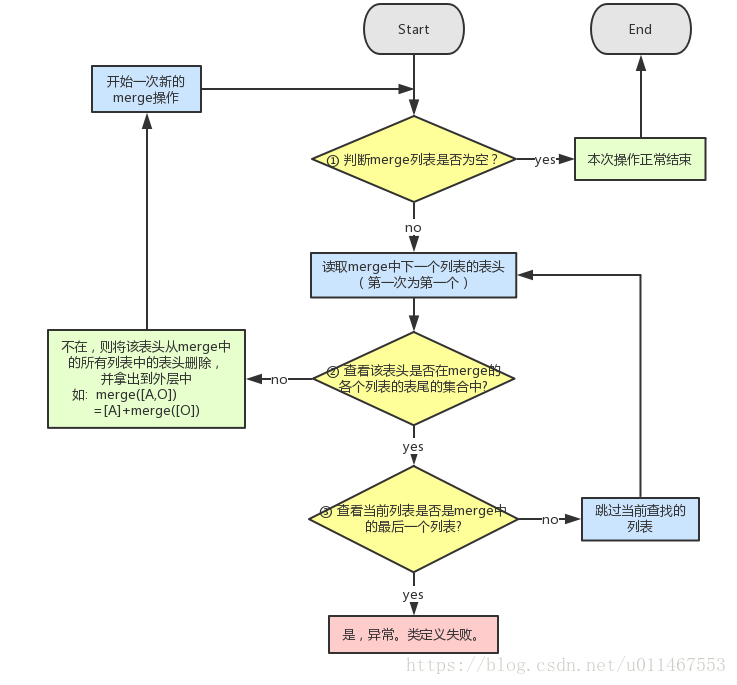
- 1、先拿出第一个合并序列的表头,看是否在后面的表尾巴,如果在后面的队列,进入2,否则进入3
- 2、如果是在后面的表尾巴,如果当前序列是最后一个序列,报错,否则,进入下一个队列,重新1
- 3、如果不在后面的队尾序列,则把当前第一个元素拿出来,重新1
如计算merge( [E,O], [C,E,F,O], [C] ) 有三个列表 : ① ② ③ 1、先看1中的E,在后面2.3的队尾中,所以下一个看2中的C,
2.2中的C,没在其他的队尾,输出【C】+{[E,O],[E,F,O]}
3、在看E,没在其他队尾,输出E 变成了,【C,E】+{[O],[F,O]}
4、再看O,在【F,O】的第二个,所以下一个看F,F不在其他队尾,所以输出F,[C,E,F]+{[O][O]}
5、最后输出【C,E,F,O】
重要规律:
1、拓扑图,从左往右,先看第一个序列第一个元素是否有前沿,如果没有就选,选了就刷新重新来,否则看第二个,
2、选一次要记得刷新,然后再看第一个序列,
几个训练
一/
class A1: pass class A2: pass class A3: pass class B1(A1,A2): pass class B2(A2): pass class B3(A2,A3): pass class C1(B1): pass class C2(B1,B2): pass class C3(B2,B3): pass class D(C1, C2, C3): pass print("从D开始查找:") for s in D.__mro__: print(s) print("从C3开始查找:") for s in C3.__mro__: print(s)
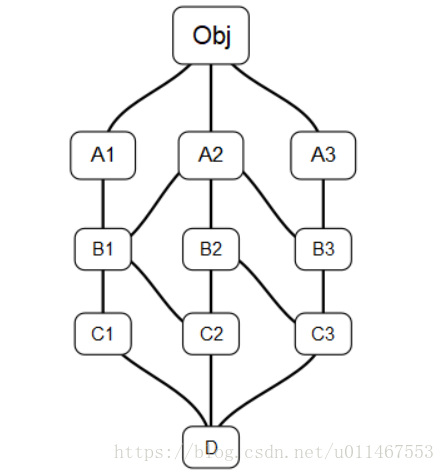
- 第一下选D
- 选完D的第一个子元素,C1没有前沿,所以选C1,
- 然后刷新,查看第一个序列的B1,有C2前沿,所以看第二个序列第一个元素C2
- 然后刷新,查看第一个序列的第一个元素B1,不是C3
- 一次类推,以此未 D C1 C2 B1 A1 C3 B2 B3 A2 A3 O
第二个训练,

F D E A B C O
三/错误示范:
class A(): def __init__(self): print("这里是A类") class B(): def __init__(self): print("这里是B类") class D(A,B): def __init__(self): print("这里是D类") class C(D): def __init__(self): print("这里是C类") class E(A,C): def __init__(self): print("这里是E类") print(E.__mro__)
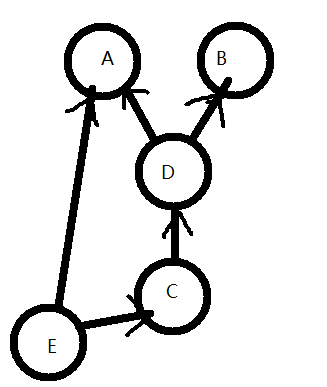

第一个E就是A,A有后续,然后还是最后一个,就错了
Super()是个什么鬼
super()可以帮我们执行MRO中下一个父类的方法,通常super()有两个使用的地方:
1. 可以访问父类的构造方法
2. 当子类方法想调用父类(MRO)中的方法
3.super(A,self) self的__mro__下的A类下面的类
class A: def func(self): print("这是A的类") class B: def func(self): print("这是B的类") class C(A,B): def func(self): super().func() #默认是__mro__的第一个 super(C, self).func() #第一个是指定的类,第二个是用谁的__mro__, 用自己的__mro__的C类下一个类 super(A,self).func() #self的__mro__中的A的下一个类 c = C() c.func()
class A: def __init__(self,name): self.name = name def func(self): print("这是A的类") class B: def __init__(self,age): self.age = age def func(self): print("这是B的类") class C(A,B): def __init__(self,name, age): super(C,self).__init__(name) super(A,self).__init__(age) def func(self): super().func() super(C, self).func() super(A,self).func() c = C("zhou",18 ) print(c.__dict__)
#输出如下
{'name': 'zhou', 'age': 18}
多态
class File: def read(self): pass def write(self): pass class Disk: def read(self): print('disk read') def write(self): print('disk write') class Text: def read(self): print('text read') def write(self): print('text write') disk = Disk() text = Text() disk.read() disk.write() text.read() text.write()
封装
class People:
data = "People"
_name = "人类" #一个_表示约定隐藏,但是并未隐藏
__age = 100000 # 两个__表示不应该用,初始化用,变量实际会变成_People__age存储
def bar(self):
self.__foo()
def __foo(self):
print("------People---foo----")
print(self, self.__dict__)
print("data,name,age为:", self.data, self._name, self.__age, self._People__age, self._Chinese__age) #self.__age 在什么类中就是对应哪个_People__age
class Chinese(People):
data = "Chinese"
_name = "中国人"
__age = 1 # 两个__表示不应该用,初始化用,变量实际会变成_Chinese__age存储
def __foo(self):
print("------Chinese---foo----")
print(self, self.__dict__)
print("data,name,age为:", self.data, self._name, self.__age, self._People__age, self._Chinese__age)
a = Chinese()
print(a)
print(a.__dict__)
print(Chinese.__dict__)
print(People.__dict__)
a.bar()
a.__x = 3
print(a.__x) #封装生效,实际就是按照__x存储的
print(a.__dict__)
#输出如下:
<__main__.Chinese object at 0x009CDCB0>
{}
{'__module__': '__main__', 'data': 'Chinese', '_name': '中国人', '_Chinese__age': 1, '_Chinese__foo': <function Chinese.__foo at 0x00E78C00>, '__doc__': None}
{'__module__': '__main__', 'data': 'People', '_name': '人类', '_People__age': 100000, 'bar': <function People.bar at 0x00E78B70>, '_People__foo': <function People.__foo at 0x00E78BB8>, '__dict__': <attribute '__dict__' of 'People' objects>, '__weakref__': <attribute '__weakref__' of 'People' objects>, '__doc__': None}
------People---foo----
<__main__.Chinese object at 0x009CDCB0> {}
data,name,age为: Chinese 中国人 100000 100000 1
3
{'__x': 3}
变形只在定义是起作用,只有一次,定义后就不再重命名了
上面两种都不是真正隐藏
在 python New style class 中, 有一个方法 __getattribute__ 在访问每个类成员时都会被调用,可以覆盖这个方法对名称进行过滤,在发现要访问指定名称变量时检查有无特殊标志,没有则返回其它值,内部需要使用变量时加入特殊标志调用 __getattribute__ 方法
class HideMemberClass(object): def __init__(self): self._db = 'this is real value' def __getattribute__(self,name,flag=None): if name=='_db' and flag != '*': return '** No Access **' return object.__getattribute__(self, name) def getdb(self): return self.__getattribute__('_db', '*') a=HideMemberClass() a._db '** No Access **' a.getdb() 'this is real value'
通过内部自己调用self._db也不可以调用,只有通过getdb方法
接口
python 没有接口,只有抽象函数,还一种说法,接口指的调用数据的函数
反射
反射即想到4个内置函数分别为:getattr、hasattr、setattr、delattr 获取成员、检查成员、设置成员、删除成员下面逐一介绍先看例子:
class Foo(object): def __init__(self): self.name = 'abc' def func(self): return 'ok' obj = Foo() #获取成员 ret = getattr(obj, 'func')#获取的是个对象
r = ret()
a =1
ret = getattr(sys.module('__main__'),"a") #也可以调用某个木块的函数或者变量
print(r) #检查成员 ret = hasattr(obj,'func')#因为有func方法所以返回True print(ret) #设置成员 print(obj.name) #设置之前为:abc ret = setattr(obj,'name',19) print(obj.name) #设置之后为:19 #删除成员 print(obj.name) #abc delattr(obj,'name') print(obj.name) #报错
@property @x.setter @x.deleter
property函数形式
property函数的声明为
def property(fget = None, fset = None, fdel = None, doc = None) -> <property object>
其中fget, fset, fdel对应变量操作的读取(get),设置(set)和删除(del)函数。
而property对象<property object>有三个类方法,即setter, getter和delete,用于之后设置相应的函数。
class Student: def get_score(self): return self.__score def set_score(self, value): if not isinstance(value, int): raise TypeError self.__score = value def del_score(self): del self.__score score = property(get_score, set_score, del_score, "这是说明") a = Student() a.score = 60 print(a.score) del a.score
修饰器使用
class Student1: # 使用装饰器的时候,需要注意: # 1. 装饰器名,函数名需要一致 # 2. property需要先声明,再写setter,顺序不能倒过来
# 3 . 如果类内部要使用score,也是只能property类型变量,不再是其他值
@property def score(self): return self.__score @score.setter def score(self, value): if not isinstance(value, int): raise TypeError self.__score = value @score.deleter def score(self): del self.__score a = Student1() a.score = 61 print(a.score) #60 del a.score
__setattr__, __getattr__,__getattribute__, __call__
- __getattribute__的返回值应该是上一层的调用,比如object.__getattribute(self, item)
- __getattribute__如果抛出AttributeError异常,则进入到__getattr__里面,如果修改了__getattr__,则不会报错,其他的都会报错
- 如果__getattribute__和__getattr__同时覆盖,当找不到属性的时候,先执行__getattribute__再执行__getattr__
__getitem__, __setitem__, __delitem__
这里的item指的字典操作[],如果有字典操作的时候运行,操作的也是self.__dict__
比如a["age"]="haha" 触发 __setitem__
print(a["age"]) 触发__getitem__, 然后触发__getattribute__
del a["age"] 触发__delitem__
class C: def __getattribute__(self, item): print("这里是getattribute") return object.__getattribute__(self, item) def __getitem__(self, item): print("这里getitem") return self.__dict__[item] def __setitem__(self, key, value): print("这里setitem") self.__dict__[key] = value # self.key = value def __delitem__(self, item): print("这里delitem") del self.item c = C() c["age"] = 18 print(c["age"])
输出如下:
这里setitem
这里是getattribute
这里getitem
这里是getattribute
18
__get__, __set__,__delete__方法
class Descriptor: def __get__(self, instance, owner): print("这里__get__",self,instance, owner) def __set__(self, key, value): print("这里是__set__",key,value) def __delete__(self, instance): print("这里是__delete__") class A: age = Descriptor() #只能在别的类中使用,描述数据
a = A()
当a.age A.age时候触发__get__
当a.age = 10 时候触发__set__ A.age = 10 不触发,因为变成了别的
当 del a.age 时候触发__delete__ del A.age 不触发,被删除了
描述符分为两种:
-
如果一个对象同时定义了__get__()和__set__()方法,则这个描述符被称为 data descriptor 。
-
如果一个对象只定义了__get__()方法,则这个描述符被称为 non-data descriptor 。
描述符只可以是类中数据,不可以是实例属性
我们对属性进行访问的时候存在下面四种情况:
- data descriptor
- instance dict
- non-data descriptor
- __getattr__()
它们的优先级大小是:
类属性> 数据描述符>实例属性>非数据描述符>__getattr__
data descriptor > instance dict > non-data descriptor > __getattr__()
这是什么意思呢?就是说如果实例对象obj中出现了同名的 data descriptor->d 和 instance attribute->d , obj.d 对属性 d 进行访问的时候,由于data descriptor具有更高的优先级,Python便会调用 type(obj).__dict__['d'].__get__(obj, type(obj)) 而不是调用obj.__dict__[‘d’]。但是如果描述符是个non-data descriptor,Python则会调用 obj.__dict__['d'] 。
描述符触发
上面这个例子中,我们分别从实例属性和类属性的角度列举了描述符的用法,下面我们来仔细分析一下内部的原理:
-
如果是对 实例属性 进行访问,实际上调用了基类object的__getattribute__方法,在这个方法中将obj.d转译成了 type(obj).__dict__['d'].__get__(obj, type(obj)) 。
-
如果是对 类属性 进行访问,相当于调用了元类type的__getattribute__方法,它将cls.d转译成 cls.__dict__['d'].__get__(None, cls) ,这里__get__()的obj为的None,因为不存在实例。
描述符含义:
class Int_validation: def __getattribute__(self, item): #即使用字典也会用到这个函数,顺序比getitem低 print("这是attribute") def __get__(self, instance, owner): #self指的C类的实例,也就是stu.age, instance指的是D的实例,也就是stu , owner指的D类 print("11111") return self.value def __set__(self, instance, value): #self指的C的实例,也就是stu.age, instance指的是D的实例,也就是stu, value是赋的值 print("222222") if isinstance(value,int) and 0<value<100: self.value=value #这个要注意 要用value,不能用instance.name 否则会陷入死循环 可以这么用instance.__dict__["name"]=value修改实例属性 else: print("请输入合法的数字") def __delete__(self, instance): print("3333") pass class Student: age=Int_validation() #只能作为属性的时候才可以触发 stu=Student() stu.age = 50 stu.age = 60 stu.age = 60 print(Student.__dict__) print(stu.age) #输出如下 222222 222222 222222 {'__module__': '__main__', 'age': <__main__.Int_validation object at 0x0092DCF0>, '__dict__': <attribute '__dict__' of 'Student' objects>, '__weakref__': <attribute '__weakref__' of 'Student' objects>, '__doc__': None} 11111 这是attribute None
描述符只能在类中属性实例化的时候才可以触发,直接对其它类中的属性进行描述,如果定义了__get__,一旦读取age就会调用__get__,如果定义了__set__,一但对age复制就会触发
- stu.age = 10 会调用__set__,但是不会修改,也不会修改stu字典, 如果是数据描述符(get,set都存在)则什么也不会发生, 如果是非数据描述符(只有get)则会修改stu的属性字典,Student的age不会改变
- stu.age 会调用__get__,比__getAttribute的值还要优先度搞
- Student.age 会调用__get__
- Student.age =10 不会调用__set__ ,真修改了age的值, 因为类属性优先级最高
__del__方法:
几种消亡方式都会调用__del__,1、程序结束,2、实例结束3、其他类中有这个类的实例, 4.其他类(其中有这个类的实例属性)的实例消亡 注意:类如果没实例化不会触发
在定义的类中存在__del__方法时,当类被删除的时候,程序会自动执行__del__当中的代码(正好与__init__方法相反).
object._getattr_(self, name)
实例instance通过instance.name访问属性name,只有当属性name没有在实例的__dict__或它构造类的__dict__或基类的__dict__中没有找到,才会调用__getattr__。当属性name可以通过正常机制追溯到时,__getattr__是不会被调用的。如果在__getattr__(self, attr)存在通过self.attr访问属性,会出现无限递归错误。
object.__getattribute__(self, name)
实例instance通过instance.name访问属性name,__getattribute__方法一直会被调用,无论属性name是否追溯到。如果类还定义了__getattr__方法,除非通过__getattribute__显式的调用它,或者__getattribute__方法出现AttributeError错误,否则__getattr__方法不会被调用了。如果在__getattribute__(self, attr)方法下存在通过self.attr访问属性,会出现无限递归错误。如下所示,ClassA中定义了__getattribute__方法,实例insA获取属性时,都会调用__getattribute__返回结果,即使是访问__dict__属性。
object.__setattr__(self, name, value)
如果类自定义了__setattr__方法,当通过实例获取属性尝试赋值时,就会调用__setattr__。常规的对实例属性赋值,被赋值的属性和值会存入实例属性字典__dict__中。
object.__delattr__(self, name)
对象删除的时候,执行的操作,必须加上del self.name 否则没用
class A: x = 1 def __init__(self): self.y = 2 def __delattr__(self, item): print("已经删除") a = A() print(a.__dict__) del a.y #执行 __delattr__ ,但是上面没删除 del A.x #不执行__delattr__ print(a.__dict__) #输出如下 {'y': 2} 已经删除 {'y': 2}
Like __setattr__() but for attribute deletion instead of assignment. This should only be implemented if del obj.name is meaningful for the object.
__str__, __repr__ , __format__
__str__的优先级高于__repr__,如果输出的时候找不到__str__,就找__repr__,都是用来控制输出格式的
class Student: name = "zgl" def __str__(self): return "我的str名字是%s" % self.name def __repr__(self): return "我的repr名字是%s" % self.name stu = Student() print(stu) #我的str名字是zgl 优先输出 print(repr(stu)) #我的repr名字是zgl
__format__
class A: def __init__(self, name, school, addr): self.name = name self.school = school self.addr = addr def __format__(self, format_spec): # format_spec = '{obj.name}-{obj.addr}-{obj.school}' return format_spec.format(obj=self) # 此行的format_spec等同于上面一行 a = A("大表哥", "哈工大", "南岗区") format_spec = "{obj.name}-{obj.school}-{obj.addr}" print(format(a, format_spec)) #大表哥-哈工大-南岗区
__dict__
关于__dict__的修改,好像只实例的可以修改__dict__,类的__dict__是不可以使用update或者赋值的,想要修改的话,修改类的属性,不能直接操作类的字典
可以使用setattr(obj, key, value)修改
__module__, __class__
__module__ 返回实例或者类出自哪个模块
__class__ 返回实例的类,或者类的类型
from day6tmp.a import E c = E() print(c.__module__) print(c.__class__) print(E.__module__) print(E.__class__) #输出如下 day6tmp.a <class 'day6tmp.a.E'> day6tmp.a <class 'type'>
__doc__
子类不继承
object.__dir__(self)
dir()作用在一个实例对象上时,__dir__会被调用。返回值必须是序列。dir()将返回的序列转换成列表并排序。
object.__call__(self[, args...])
Called when the instance is “called” as a function; if this method is defined, x(arg1, arg2, ...) is a shorthand for x.__call__(arg1, arg2, ...).
Python中有一个有趣的语法,只要定义类型的时候,实现__call__函数,这个类型就成为可调用的。换句话说,我们可以把这个类的对象当作函数来使用,相当于重载了括号运算符。
通过使用__setattr__,__getattr__,__delattr__可以重写dict,使之通过“.”调用键值。
class Dict(dict): ''' 通过使用__setattr__,__getattr__,__delattr__ 可以重写dict,使之通过“.”调用 ''' def __setattr__(self, key, value): print("In '__setattr__") self[key] = value def __getattr__(self, key): try: print("In '__getattr__") return self[key] except KeyError as k: return None def __delattr__(self, key): try: del self[key] except KeyError as k: return None # __call__方法用于实例自身的调用,达到()调用的效果 def __call__(self, key): # 带参数key的__call__方法 try: print("In '__call__'") return self[key] except KeyError as k: return "In '__call__' error" s = Dict() print(s.__dict__) # {} s.name = "hello" # 调用__setattr__ # In '__setattr__ print(s.__dict__) # 由于调用的'__setattr__', name属性没有加入实例属性字典中。 # {} print(s("name")) # 调用__call__ # In '__call__' # hello print(s["name"]) # dict默认行为 # hello # print(s) print(s.name) # 调用__getattr__ # In '__getattr__ # hello del s.name # 调用__delattr__ print(s("name")) # 调用__call__ # None
属性描述符、property(@setter,@deleter)和__setattr__
我这是么理解的,
- property用于的是少数属性的控制,1个2个
- 属性描述符用于的是某些的相同属性的控制 具有相同属性
- __setattr__ 全部属性的控制,当然也可以部分,不够代码结构复杂
类中类
class A: name = "A" data1 = "A的数据" class B: data2 = "B的数据" a = A.B() # print(a.name) #访问不到A的数据 print(a.data2) # print(a.data1) #访问不到A的数据
子类和类互转
子类实例是父类的实例,相反不行
动态加载模块
第一种方式:python解释器内部使用,不建议用
#!/usr/bin/env python # _*_ coding:utf-8 _*_ # Author:CarsonLi '''Python 解释器内部动态导入方式''' module_name='import_lib.metaclass' #模块名的字符串 import_lib=__import__(module_name) #这是解释器自己内部用的 '''import_lib代表的其实是这个模块,而不是下面的metaclass''' c=import_lib.metaclass.Ccc("Bert")#调用下面的方法 print(c.name) #运行结果:Bert
第二种方式:与上面效果一样,官方建议用这个
#!/usr/bin/env python # _*_ coding:utf-8 _*_ # Author:CarsonLi '''官方建议用这个''' import importlib module_name='import_lib.metaclass' #模块名的字符串 metaclass=importlib.import_module(module_name) #导入的就是需要导入的那个metaclass c=metaclass.Ccc("Bert") #调用下面的方法 print(c.name) #运行结果:Bert

支付宝
您的资助是我最大的动力!
金额随意,欢迎来赏!
微信


