【python 第六日】常用模块
模块和包:
- 在from cal import add的过程中也会把cal的主支程序执行一遍
- os.sys 默认添加执行文件的当前文件夹,即使是其他包的模块中有os.sys也是执行文件的路径
- 跨模块引用
- __file__问题:在pycharm下pycharm会自动拼接成绝对路径 ,在CMD终端下,只是文件名,要想获取绝对路径,用os.path.abspath(__file__)
- 如果模块A引用同文件夹下的模块B,当其他文件夹下文件C引用A时候会搜索不到B,可以直接在C里修改sys.path.append(A的目录),也可以在A中引用之前就加上自己的文件夹,sys.path开头加上os.path.dirname,如果不是开头则可能会先加载其他模块重名的函数或者模块,造成错误,用os.path.curdir不行,这个是执行文件目录
def safe_insert(f_path): """ 把文件的路径添加到sys中去 :param f_path:传入的是文件的绝对路径 :return: """ length = len(sys.path) BASE_DIR=os.path.dirname(f_path) if BASE_DIR in sys.path: sys.path.remove(BASE_DIR) sys.path.insert(0,BASE_DIR)
time datetime calendar
time时间戳<----->元组<--------->时间字符串
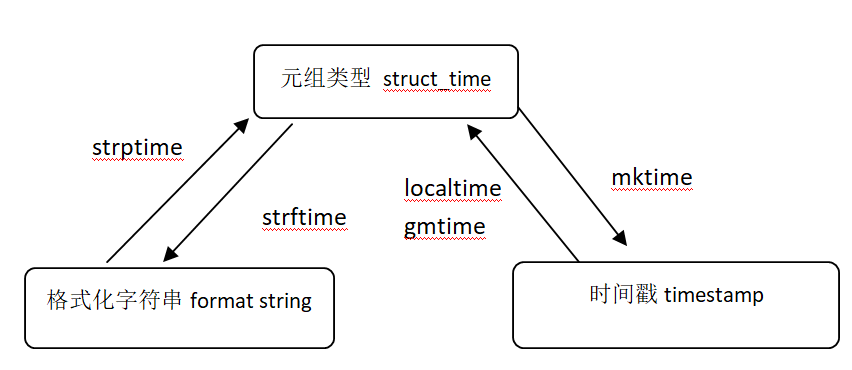
print(time.time()) #1545986511.928391 返回当前时间时间戳 print(time.localtime()) #time.struct_time(tm_year=2018, tm_mon=12, tm_mday=28, tm_hour=16, tm_min=41, tm_sec=51, tm_wday=4, tm_yday=362, tm_isdst=0) #当前时间对应的元祖 print(time.gmtime()) #time.struct_time(tm_year=2018, tm_mon=12, tm_mday=28, tm_hour=8, tm_min=41, tm_sec=51, tm_wday=4, tm_yday=362, tm_isdst=0) #格林时间对应的元祖 print(time.mktime(time.localtime())) #1545986511.0 #本地时间转为时间戳 print(time.mktime(time.strptime("12/28/18 16:37:25","%x %X"))) #1545986245.0 #字符串时间转为时间戳
t = (2009, 2, 17, 17, 3, 38, 2, 438, 3)
print(time.mktime(t)) #1234861418.0 直接把9位元祖转换成时间戳
print(time.strftime("%x %X")) ##12/28/18 16:41:51 #格式化输出当前时间 print(time.strptime("12/28/18 16:37:25","%x %X")) #time.struct_time(tm_year=2018, tm_mon=12, tm_mday=28, tm_hour=16, tm_min=37, tm_sec=25, tm_wday=4, tm_yday=362, tm_isdst=-1) #字符串转元祖格式
格式参照 %a 本地(locale)简化星期名称 %A 本地完整星期名称 %b 本地简化月份名称 %B 本地完整月份名称 %c 本地相应的日期和时间表示 %d 一个月中的第几天(01 - 31) %H 一天中的第几个小时(24小时制,00 - 23) %I 第几个小时(12小时制,01 - 12) %j 一年中的第几天(001 - 366) %m 月份(01 - 12) %M 分钟数(00 - 59) %p 本地am或者pm的相应符 %S 秒(01 - 61) %U 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 %w 一个星期中的第几天(0 - 6,0是星期天) %W 和%U基本相同,不同的是%W以星期一为一个星期的开始。 %x 本地相应日期 %X 本地相应时间 %y 去掉世纪的年份(00 - 99) %Y 完整的年份 %Z 时区的名字(如果不存在为空字符) %% ‘%’字符
time时间戳---->格式化时间<------元祖
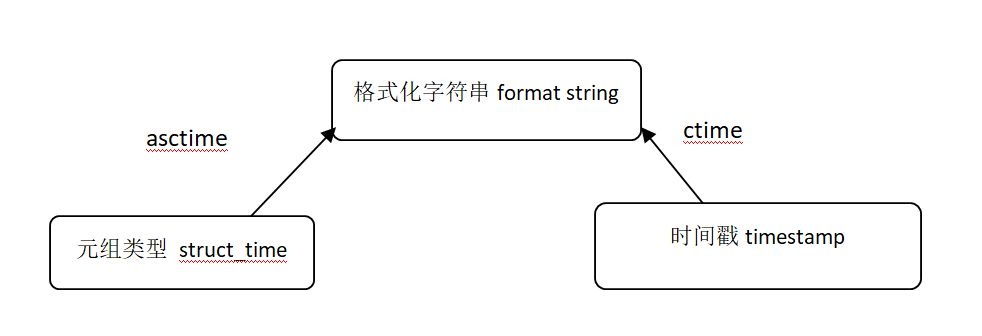
print(time.ctime()) #Fri Dec 28 17:17:39 2018 print(time.ctime(time.mktime((2018,12,28,17,16,15,1,2,3)))) #Fri Dec 28 17:16:15 2018 print(time.asctime((2018,12,28,17,16,15,1,2,3))) #Tue Dec 28 17:16:15 2018
print(time.asctime((2018,12,28,17,16,15,4,11,12))) #Fri Dec 28 17:16:15 2018 #第7个数字表示的星期,0表示星期一
print(time.asctime()) #Fri Dec 28 17:17:39 2018
datetime
datetime.date类
支持的操作:
| 操作 | 结果 |
|---|---|
date2 = date1 + timedelta |
date2为从date1中移除timedelta.days天。(1) |
date2 = date1 - timedelta |
计算date2,以便date2 + timedelta == date1。(2) |
timedelta = date1 - date2 |
(3) |
date1 date2 |
当date1在时间上位于date2之前,则date1小于date2。(4) |
import datetime x=datetime.date(2018,12,28) #date类 date类有三个参数,datetime.date(year,month,day),返回year-month-day 2018-12-28 x_stamp=datetime.date.fromtimestamp(time.mktime((2018,12,28,17,46,12,4,362,-1))) #时间戳变成date类 print(x_stamp) #2018-12-28 print(datetime.date.ctime(x)) #也可以x.ctime() 转为字符串时间格式 Fri Dec 28 00:00:00 2018 print(x.strftime("%Y:%m:%d")) #整理输出格式 2018:12:28 print(x.isocalendar(),x.isoformat(),x.isoweekday()) #(年份 第几周 星期几) 格式化 周几 (2018, 52, 5) 2018-12-28 5 print(x.replace(2018,12,29),x) #不改变原日期 2018-12-29 2018-12-28 print(x.timetuple(),x.weekday(),x.fromordinal(32)) #struct_time元祖,周几,从公元的第几天日期
#time.struct_time(tm_year=2018, tm_mon=12, tm_mday=28, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=362, tm_isdst=-1) 4 0001-02-01
print((x - x_stamp).days) #两个日期差的天数
详细属性


class datetime.date(year, month, day) 所有参数都是必需的。参数可以是以下范围内的整数: MINYEAR <= year <= MAXYEAR 1 <= month <= 12 1 <= day <= number of days in the given month and year 如果给出了这些范围之外的参数,则会引发ValueError。 其他构造函数,所有类方法: classmethod date.today() 返回当前的本地日期。这相当于date.fromtimestamp(time.time())。 classmethod date.fromtimestamp(timestamp) 返回与POSIX时间戳对应的本地日期,例如time.time()返回的时间戳。如果时间戳超出平台C localtime()函数支持的值的范围则引发OverflowError,如果localtime()失败则引发OSError。从1970年到2038年这种情况很常见。请注意,在时间戳中包含闰秒的非POSIX系统上,fromtimestamp()会忽略闰秒。 在版本3.3中更改:如果时间戳超出平台C localtime ()函数支持的值范围,则引发OverflowError而不是ValueError 。在localtime()失败时引发OSError而不是ValueError classmethod date.fromordinal(ordinal) 返回对应于格雷高尔顺序的日期,其中第1年的1月1有序号1。如果不满足1 <= ordinal <= date.max.toordinal(),则引发ValueError。对于任何日期d,date.fromordinal(d.toordinal()) == d。 类属性: date.min 可表示的最早日期,date(MINYEAR, 1, 1)。 date.max 可表示最晚的日期,date(MAXYEAR, 12, 31)。 date.resolution 不相等的日期对象之间的最小可能差异,timedelta(days=1)。 实例属性(只读): date.year 在MINYEAR和MAXYEAR之间,包括这两个值。 date.month 1至12之间。 date.day 在1和给定年的给定月份中的天数之间。 date.replace(year, month, day) 使用相同的值返回一个日期,除了那些由指定的关键字参数给定新值的参数。例如,如果d == date(2002, 12, 31),那么d.replace(day=26) == date(2002, 12, 26)。 date.timetuple() 返回一个time.struct_time,类似time.localtime()的返回值。Hours、minutes和seconds为0,DST标记为-1。d.timetuple()等同于time.struct_time((d.year, d.month, d.day, 0, 0, 0, d.weekday(), yday, -1)),其中yday = d.toordinal() - date(d.year, 1, 1).toordinal() + 1当前年份中的天数,1月1日为开始的第1天。 date.toordinal() 返回该日期的预测格里历序号,其中第一年的1月1号具有序数1。对于任何date对象d,date.fromordinal(d.toordinal()) == d。 date.weekday() 将星期几作为整数返回,其中星期一为0,星期日为6。例如,date(2002, 12, 4).weekday() == 2,是星期三。另请参见isoweekday()。 date.isoweekday() 将星期几作为整数返回,其中星期一为1,星期日为7。例如,date(2002, 12, 4).isoweekday() == 3,是星期三。另请参见weekday(),isocalendar()。 date.isocalendar() 返回3元组(ISO年,ISO周编号,ISO工作日)。 ISO日历是公历日历的广泛使用的变体。有关详细说明,请参阅https://www.staff.science.uu.nl/~gent0113/calendar/isocalendar.htm。 ISO年包括52或53个整周,其中一周从星期一开始并在星期日结束。ISO年的第一周是一年的第一个包含星期四的(公历)日历周。这称为周数1,该周四的ISO年与其公历年相同。 例如,2004年从星期四开始,因此ISO 2004年的第一周从2003年12月29日星期一开始,2004年1月4日星期日结束,因此date(2003, 12, 29).isocalendar() == (2004, 1, 1)以及date(2004, 1, 4).isocalendar() == (2004, 1, 7)。 date.isoformat() 以ISO 8601格式返回表示日期的字符串'YYYY-MM-DD'。例如,date(2002, 12, 4).isoformat() == '2002-12-04'。 date.__str__() 对于日期d,str(d)等同于d.isoformat()。 date.ctime() 返回表示日期的字符串,例如date(2002, 12, 4).ctime() == 'Wed Dec 4 00:00:00 2002'。在原生的C函数ctime()(time.ctime()调用它,但是date.ctime() 不调用它)遵守C标准的平台上,d.ctime()等效于time.ctime(time.mktime(d.timetuple()))。 date.strftime(format) 返回一个表示日期的字符串,由一个明确的格式字符串控制。指代小时,分钟或秒的格式代码将会看到0个值。有关格式化指令的完整列表,请参阅strftime()和strptime()行为。 date.__format__(format) 与date.strftime()相同。这使得可以在使用str.format()时为date对象指定格式字符串。有关格式化指令的完整列表,请参见strftime()和strptime()的行为。
datetime.time类
不支持减法
from datetime import date,datetime,time,timedelta,tzinfo class GMT8(tzinfo): #建立一个时区北京时区 def utcoffset(self, dt): return timedelta(hours=8) def dst(self, dt): return timedelta(0) def tzname(self, dt): return "Beijing/zgl" x = time(18,0,45,23,tzinfo=GMT8()) #5个参数,时,分,秒,毫秒,时区 如果添加了tzinfo信息的时间叫aware-time,None的时间信息是naive-time时间,不可以相互减 print(x) #18:00:45.000023+08:00 print(x.replace(19,0,45,23,tzinfo=GMT8())) #19:00:45.000023+08:00 print(x.isoformat(),x.strftime(f"%H-%M-%S-{x.microsecond}"),x.tzname(),x.utcoffset()) #18:00:45.000023+08:00 18-00-45-23 Beijing/zgl 8:00:00
print(x.replace(19,0,45,23,tzinfo=GMT8()) > x) #True 不支持减法,但可以比较大小
详细属性:
class datetime.time(hour=0, minute=0, second=0, microsecond=0, tzinfo=None) 所有参数都是可选的。tzinfo可以是None或tzinfo子类的实例。其余的参数可以是以下范围内的整数: 0 <= hour < 24 0 <= minute < 60 0 <= second < 60 0 <= microsecond < 1000000. 如果给出了这些范围之外的参数,则会引发ValueError。所有默认值为0,除了tzinfo默认为None。 类属性: time.min 可表示的最早的time,time(0, 0, 0, 0)。 time.max 可表示的最晚的time,time(23, 59, 59, 999999)。 time.resolution 不相等的time对象之间的最小可能差,即timedelta(microseconds=1),还要注意time不支持算术操作。 实例属性(只读): time.hour 在range(24)之间。 time.minute 在range(60)之间。 time.second 在range(60)之间。 time.microsecond 在range(1000000)之间。 time.tzinfo 作为tzinfo参数传递给time构造函数的对象,如果没有传递则为None。 time.replace([hour[, minute[, second[, microsecond[, tzinfo]]]]]) 返回具有相同值的time,但通过任何关键字参数指定新值的那些属性除外。请注意,可以指定tzinfo=None来从aware的time创建一个naive的time,而不需对time数据进行转换。 time.isoformat() 返回以ISO 8601 格式HH:MM:SS.mmmmmm表示间的字符串,如果self.microsecond为0,则以HH:MM:SS的格式。如果utcoffset()不返回None,则会附加一个6个字符的字符串,以(带符号)的小时和分钟为单位提供UTC偏移量:HH:MM:SS.mmmmmm+HH:MM,如果self.microsecond为0,则为HH:MM:SS+HH:MM。 time.__str__() 对于时间t,str(t)等同于t.isoformat()。 time.strftime(format) 返回一个表示time的字符串,由显式的格式字符串控制。有关格式化指令的完整列表,请参见strftime()和strptime()的行为。 time.__format__(format) 与time.strftime()相同。这使得可以在使用str.format()时为time对象指定格式字符串。有关格式化指令的完整列表,请参见strftime()和strptime()的行为。 time.utcoffset() 如果tzinfo为None,则返回None,否则返回self.tzinfo.utcoffset(None);如果后者未返回None或表示小于一天的整数分钟的timedelta对象,则引发一个异常。 time.dst() 如果tzinfo为None,则返回None,否则返回self.tzinfo.utcoffset(None);如果后者未返回None或表示小于一天的整数分钟的timedelta对象,则引发一个异常。 time.tzname() 如果tzinfo为None,则返回None,否则返回self.tzinfo.tzname(None);如果后者不返回None或字符串对象,则引发一个异常。
datetime类
支持的操作:
| 操作 | 结果 |
|---|---|
datetime2 = datetime1 + timedelta |
(1) |
datetime2 = datetime1 - timedelta |
(2) |
timedelta = datetime1 - datetime2 |
(3) |
datetime1 < datetime2 |
比较datetime和datetime。(4) |
-
datetime2是从datetime1移除timedelta的时间,如果
timedelta.days> 0则向前移动,如果timedelta.days< 0则向后移动。结果具有与输入datetime相同的tzinfo属性,并且之后datetime2 - datetime1 == timedelta。如果datetime2.year小于MINYEAR或大于MAXYEAR,则会引发OverflowError。请注意,即使输入是aware对象,也不会执行时区调整。 -
计算datetime2,使datetime2 + timedelta == datetime1。与加法一样,结果具有与输入日期时间相同的
tzinfo属性,即使输入是aware的,也不执行时区调整。这不完全等同于 datetime1 + (-timedelta),因为单独的-timedelta可能会溢出,而在此情况下datetime1 - timedelta不会。 -
只有当两个操作数都是naive的或者两者都是aware的时,才定义从
datetime减去一个datetime。如果一个是aware的而另一个是naive的,则会引发TypeError。如果两者都是naive的,或者两者都是aware的且具有相同的
tzinfo属性,则会忽略tzinfo属性,结果是一个timedelta对象t,使得datetime2 + t == datetime1。在这种情况下不进行时区调整。如果两者都是aware的且具有不同的
tzinfo属性,则a-b表现得好像a和b被首先转换成naive的UTC时间。结果是(a.replace(tzinfo=None) - a.utcoffset()) - (b.replace(tzinfo=None) - b.utcoffset()),除非具体的实现永远不会溢出。 -
当datetime1在时间上位于datetime2 之前,则认为datetime1小于datetime2。
如果一个比较数据是naive的,而另一个是aware的,则尝试进行顺序比较时会产生
TypeError。对于相等性比较,naive实例永远不等于aware实例。如果两个比较数都是aware的并且具有相同的
tzinfo属性,则忽略共同的tzinfo属性,并比较基本的时间数据。如果两个比较数都是aware并且具有不同的tzinfo属性,则首先通过减去它们的UTC偏移(从self.utcoffset()获得)来调整比较数。在版本3.3中已更改:naive的和aware的
datetime实例之间的相等性比较不引发TypeError。注意
为了停止比较回退到默认的比较对象地址的方式,如果另一比较对象不是
datetime对象,datetime比较通常引发TypeError。但是,如果另一个比较对象具有timetuple()属性,则会返回NotImplemented。这个钩子给其他种类的日期对象实现混合型比较的机会。如果不是,当将datetime对象与不同类型的对象进行比较时,则会引发TypeError,除非比较为==或!=。后一种情况分别返回False或True。
datetime对象可以用作字典的键。在布尔上下文中,所有datetime对象都被视为真。
from datetime import date,datetime,time,timedelta,tzinfo x = datetime(2018,12,29,13,31,23,22,tzinfo=None) print(x,x.time(),x.date(),x.ctime()) #2018-12-29 13:31:23.000022 13:31:23.000022 2018-12-29 Sat Dec 29 13:31:23 2018 x,x.time,x.ctime,x.date都是x对应的转换 print(x.now(),x.today()) #2018-12-29 13:46:57.944939 2018-12-29 13:46:57.944940 #x.now(),x.today()都是实时的 print(x.fromtimestamp(222222222),x.strftime("%Y-%m-%d %H:%M:%S %A %B")) #1977-01-16 08:23:42 2018-12-29 13:31:23 Saturday December #创建,转化格式
详细属性:
构造函数: class datetime.datetime(year, month, day, hour=0, minute=0, second=0, microsecond=0, tzinfo=None) 年,月和日的参数是必需的。tzinfo可以是None或tzinfo子类的实例。其余的参数可以是以下范围内的整数: MINYEAR <= year <= MAXYEAR 1 <= month <= 12 1 <= day <= number of days in the given month and year 0 <= hour < 24 0 <= minute < 60 0 <= second < 60 0 <= microsecond < 1000000 如果给出了这些范围之外的参数,则会引发ValueError。 其他构造函数,所有类方法: classmethod datetime.today() 返回当前本地日期时间,其中tzinfo为None。这相当于datetime.fromtimestamp(time.time())。另请参见now()、fromtimestamp()。 classmethod datetime.now(tz=None) 返回当前的本地日期和时间。如果可选参数tz为None或未指定,则这类似于today(),但如果可能,通过time.time()时间戳提供更高的精度(例如,这在提供C gettimeofday()函数的平台上是可能的)。 如果tz不为None,则必须是tzinfo子类的实例,当前日期和时间将转换为tz的时区。在这种情况下,结果等效于tz.fromutc(datetime.utcnow().replace(tzinfo=tz))。另请参见today()、utcnow()。 classmethod datetime.utcnow() 返回当前UTC日期和时间,其中tzinfo为None。这类似now(),但返回当前UTC日期和时间,作为一个naive的datetime对象。可以通过调用datetime.now(timezone.utc)来得到aware的当前UTC datetime。另请参见now()。 classmethod datetime.fromtimestamp(timestamp, tz=None) 返回与POSIX时间戳对应的本地日期和时间,例如time.time()返回的时间戳。如果可选参数tz为None或未指定,则时间戳将转换为平台的本地日期和时间,返回的datetime对象是naive的。 如果tz不是None,则必须是tzinfo子类的实例,此时时间戳将转换为tz的时区。在这种情况下,结果等效于tz.fromutc(datetime.utcfromtimestamp(timestamp).replace(tzinfo=tz))。 如果时间戳超出平台C localtime()或gmtime()函数支持的值的范围,则fromtimestamp()可能引发OverflowError;如果localtime()或gmtime()函数失败,则引发OSError。常见的做法是限制年份在1970和2038之间。请注意,在时间戳中包含闰秒的非POSIX系统上,fromtimestamp()会忽略闰秒,这可能使得两个相差1秒的时间戳产生相同的datetime对象。另请参见utcfromtimestamp()。 在版本3.3中更改:如果时间戳超出平台C localtime ()或gmtime()函数支持的值范围,则引发OverflowError而不是ValueError 。在localtime()或gmtime()失败时引发OSError而不是ValueError classmethod datetime.utcfromtimestamp(timestamp) 返回与POSIX时间戳对应的UTC datetime,其中tzinfo为None。如果时间戳超出平台C gmtime()函数支持的值的范围,则它可能引发OverflowError;如果gmtime()函数失败,则引发OSError。常见的做法是限制年份在1970和2038之间。 classmethod datetime.fromordinal(ordinal) 返回对应于普通公历的序数的datetime,其中第1年的1月1日为序数1。如果不满足1 <= ordinal <= datetime.max.toordinal(),则引发ValueError。结果的hour、minute、second和microsecond都是0,并且tzinfo为None。 classmethod datetime.combine(date, time) 返回一个新的datetime对象,其日期部分等于给定的date对象,其时间部分和tzinfo属性等于给定time对象。对于任何datetime对象d,d == datetime.combine(d.date(), d.timetz())。如果date是一个datetime对象,则会忽略其时间部分和tzinfo属性。 classmethod datetime.strptime(date_string, format) 返回对应于date_string的datetime,根据format进行解析。这相当于datetime(*(time.strptime(date_string, format)[0:6]))如果time.strptime()无法解析date_string和format,或者如果返回的值不是时间元组,则会引发ValueError。有关格式化指令的完整列表,请参见strftime()和strptime()的行为。 类属性: datetime.min 可表示的最早datetime,datetime(MINYEAR, 1, 1, tzinfo=None)。 datetime.max 可表示的最晚datetime,datetime(MAXYEAR, 12, 31, 23, 59, 59, 999999, tzinfo=None)。 datetime.resolution 不相等的datetime对象之间的最小可能差值,timedelta(microseconds=1)。 实例属性(只读): datetime.year 在MINYEAR和MAXYEAR之间,包括这两个值。 datetime.month 1至12之间。 datetime.day 在1和给定年的给定月份中的天数之间。 datetime.hour 在range(24)之间。 datetime.minute 在range(60)之间。 datetime.second 在range(60)之间。 datetime.microsecond 在range(1000000)之间。 datetime.tzinfo 作为tzinfo参数传递给datetime构造函数的对象,如果没有传递则为None。 实例方法: datetime.date() 返回具有相同年、月和日的date对象。 datetime.time() 返回具有相同小时、分钟、秒和微秒的time对象。tzinfo为None。另请参见方法timetz()。 datetime.timetz() 返回具有相同小时、分钟、秒、微秒和tzinfo属性的time对象。另请参见方法time()。 datetime.replace([year[, month[, day[, hour[, minute[, second[, microsecond[, tzinfo]]]]]]]]) 使用相同的属性返回一个日期时间,除了那些通过指定任何关键字参数给出新值的属性。请注意,可以指定tzinfo=None来从aware的datetime创建一个naive的datetime,而不需对date和time数据进行转换。 datetime.astimezone(tz=None) 返回带有新tzinfo属性tz的datetime对象,调整日期和时间数据使结果与self 的UTC时间相同,但为tz的本地时间。 如果提供,tz必须是tzinfo子类的实例,并且其utcoffset()和dst()方法不得返回None。self必须是aware的(self.tzinfo不能是None,以及self.utcoffset()不能返回None)。 如果不带参数调用(或tz=None),则假定使用系统本地时区。转换后的datetime实例的.tzinfo属性将设置为timezone的实例,其带有从操作系统获取的时区名称和偏移量。 如果self.tzinfo为tz,则self.astimezone(tz)等于self:日期调整和时间数据不会调整。否则结果是时区tz中的本地时间,表示与self相同的UTC时间:astz = dt.astimezone(tz)之后,astz - astz.utcoffset()通常具有与dt - dt.utcoffset()相同的日期和时间数据。类tzinfo的讨论解释了无法实现的在夏令时转换边界的情况(仅当tz同时建模标准时和夏令时的时候才出现问题)。 如果你只想在不调整日期和时间数据的情况下将时区对象tz附加到datetimedt,请使用dt.replace(tzinfo=tz)。如果你只想从aware的datetime dt中删除时区对象而不转换日期和时间数据,请使用dt.replace(tzinfo=None)。 datetime.utcoffset() 如果tzinfo为None,则返回None,否则返回self.tzinfo.utcoffset(self);如果后者未返回None或表示小于一天的整数分钟的timedelta对象,则引发一个异常。 datetime.dst() 如果tzinfo为None,则返回None,否则返回self.tzinfo.dst(self);如果后者未返回None或表示小于一天的整数分钟的timedelta对象,则引发一个异常。 datetime.tzname() 如果tzinfo为None,则返回None,否则返回self.tzinfo.tzname(self);如果后者不返回None或字符串对象,则引发一个异常。 datetime.timetuple() 返回一个time.struct_time,类似time.localtime()的返回值。d.timetuple()等同于time.struct_time((d.year, d.month, d.day, d.hour, d.minute, d.second, d.weekday(), yday, dst)),其中yday = d.toordinal() - date(d.year, 1, 1).toordinal() + 1当前年份中的天数,1月1日为开始的第1天。根据dst()方法设置结果的tm_isdst标志:如果tzinfo为None或dst()返回None,则tm_isdst设置为-1;如果dst()返回非零值,tm_isdst设置为1;否则tm_isdst设置为0。 datetime.utctimetuple() 如果datetime实例d是naive的,它等同于d.timetuple(),但是无论d.dst()返回什么,tm_isdst都被强制设置为0。对于UTC时间DST始终不会生效。 如果d是aware的,则通过减去d.utcoffset()归一化d,并返回归一化的时间time.struct_time。tm_isdst被强制为0。请注意,如果d.year是MINYEAR或MAXYEAR且UTC调整溢出超过一年的边界,则可能会引发OverflowError。 datetime.toordinal() 返回日期的公历序数。等同于self.date().toordinal()。 datetime.timestamp() 返回对应于datetime实例的POSIX时间戳。返回值类似于time.time()返回的float。 Naive的datetime实例假设表示本地时间,并且此方法依赖于平台C mktime()函数来执行转换。由于在许多平台上,datetime支持的值范围比mktime()的范围更广,因此此方法可能会在很远的过去或很远的未来时间引发OverflowError。 对于aware的datetime实例,返回值计算为: (dt - datetime(1970, 1, 1, tzinfo=timezone.utc)).total_seconds() datetime.weekday() 将星期几作为整数返回,其中星期一为0,星期日为6。等同于self.date().weekday()。另请参见isoweekday()。 datetime.isoweekday() 将星期几作为整数返回,其中星期一为1,星期日为7。等同于self.date().isoweekday()。另请参阅weekday()、isocalendar()。 datetime.isocalendar() 返回3元组(ISO年,ISO周编号,ISO工作日)。等同于self.date().isocalendar()。 datetime.isoformat(sep='T') 返回以ISO 8601 格式YYYY-MM-DDTHH:MM:SS.mmmmmm表示日期和时间的字符串,如果microsecond为0,则以YYYY-MM-DDTHH:MM:SS的格式。 如果utcoffset()不返回None,则会附加一个6个字符的字符串,以(带符号)的小时和分钟为单位提供UTC偏移量:YYYY-MM-DDTHH:MM:SS.mmmmmm+HH:MM,如果microsecond为0,则为YYYY-MM-DDTHH:MM:SS+HH:MM。 datetime.__str__() 对于datetime实例d,str(d)等效于d.isoformat(' ')。 datetime.ctime() 返回一个表示日期和时间的字符串,例如datetime(2002, 12, 4, 20, 30, 40).ctime() == 'Wed Dec 4 20:30:40 2002'。在原生的C函数ctime()(time.ctime()调用它,但是datetime.ctime() 不调用它)遵守C标准的平台上,d.ctime()等效于time.ctime(time.mktime(d.timetuple()))。 datetime.strftime(format) 返回一个表示日期和时间的字符串,由显式的格式字符串控制。有关格式化指令的完整列表,请参见strftime()和strptime()的行为。 datetime.__format__(format) 与datetime.strftime()相同。这使得可以在使用str.format()时为datetime对象指定格式字符串。有关格式化指令的完整列表,请参见strftime()和strptime()的行为。
timedelta
class datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
支持的操作:
| 操作 | 结果 |
|---|---|
t1 = t2 + t3 |
t2和t3的和。之后,t1-t2 == t3 and t1-t3 == t2为真。(1) |
t1 = t2 - t3 |
t2和t3的差。之后t1 == t2 - t3 and t2 == t1 + t3为真。(1) |
t1 = t2 * i 或 t1 = i * t2 |
Delta乘以一个整数。之后,如果i != 0,则t1 // i == t2为真。 |
| 通常,t1 * i == t1 * (i-1) + t1为真。(1) | |
t1 = t2 * f 或 t1 = f * t2 |
Delta乘以一个浮点数。结果使用round-half-to-even舍入到timedelta.resolution最近的倍数。 |
f = t2 / t3 |
t2除以t3(3)。返回一个float对象。 |
t1 = t2 / f 或 t1 = t2 / i |
Delta除以一个浮点数或整数。结果使用round-half-to-even舍入到timedelta.resolution最近的倍数。 |
t1 = t2 // i或t1 = t2 // t3 |
计算商,余数(如果有的话)被丢弃。在第二种情况下,返回一个整数。(3) |
t1 = t2 % t3 |
计算余数,为一个timedelta对象。(3) |
q, r = divmod(t1, t2) |
计算商和余数:q = t1 // t2 (3)且r = t1 % t2。q一个是整数,r是一个timedelta对象。 |
+t1 |
返回具有相同值的timedelta对象。(2) |
-t1 |
等效于timedelta(-t1.days, -t1.seconds, -t1.microseconds),和t1* -1。(1)(4) |
abs(t) |
当t.days >= 0时等效于+t,当t.days < 0时等效于-t。(2) |
str(t) |
以[D day[s], ][H]H:MM:SS[.UUUUUU]形式返回一个字符串,其中对于负tD为负数。(5) |
repr(t) |
以datetime.timedelta(D[, S[, U]])形式返回一个字符串,其中对于负tD为负数。(5) |
注:
-
虽然相等,但可能会溢出。
-
相等且不会溢出。
-
除0引发
ZeroDivisionError。 -
- timedelta.max不能表示成一个
timedelta对象。 -
timedelta对象的字符串表示形式与其内部表示形式相似。这导致负面timedeltas有点不寻常的结果。例如:>>> timedelta(hours=-5) datetime.timedelta(-1, 68400) >>> print(_) -1 day, 19:00:00
from datetime import date,datetime,time,timedelta,tzinfo x = datetime(2018,12,29,13,31,23,22,tzinfo=None) y = datetime(2018,12,29,12,12,33,22,None) print((x-y).total_seconds()) #4730.0 z = timedelta(days=10) print(x + z) #2019-01-08 13:31:23.000022
详细信息:
class datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0) 所有参数都是可选的且默认为0。参数可以是整数或浮点数,也可以是正数或负数。 只有days(天),seconds(秒)和microseconds(微秒)存储在内部。参数被转换为这些单位: 1毫秒转换为1000微秒。 1分钟转换为60秒。 1小时转换为3600秒。 1周被转换为7天。 然后对天,秒和微秒进行归一化,以便表示是唯一的 0 <= microseconds < 1000000 0 <= seconds < 3600*24(一天中的秒数) -999999999 <= days <= 999999999 timedelta.min 最小的timedelta对象,timedelta(-999999999)。 timedelta.max 最大的timedelta对象,timedelta(days=999999999, hours=23, minutes=59, seconds=59, microseconds=999999)。 timedelta.resolution 不相等的timedelta对象之间的最小可能差值,timedelta(microseconds=1)。 注意,由于归一化,timedelta.max > -timedelta.min。-timedelta.max不能表示成一个timedelta对象。 实例方法: timedelta.total_seconds() 返回持续时间中包含的总秒数。等同于td / timedelta(seconds=1)。 请注意,对于非常大的时间间隔(在大多数平台上超过270年),此方法将失去微秒精度。
Calendar类
import calendar x = calendar.month(2018,12) print(x) x = calendar.calendar(2017) print(x)

class calendar.Calendar(firstweekday=0) 创建Calendar对象。firstweekday是一个整数,指定一周的第一天。0是星期一(默认),6是星期日。 Calendar对象提供了几种可用于准备日历数据进行格式化的方法。此类不做任何格式本身。这是子类的工作。 Calendar实例具有以下方法: iterweekdays() 返回迭代器将用于一周星期天的数字。迭代器的第一个值将与firstweekday属性的值相同。 itermonthdates(year, month) 在今年年中返回迭代器,供月个月(1-12)。此迭代器将返回获取完整周所需的月份和月初之前的所有天以及月末之后的所有天(如datetime.date对象)。 itermonthdays2(year, month) 返回类似于itermonthdates()的年中的月月的迭代器。天返回将元组组成的日数和每周的天数。 itermonthdays(year, month) 返回类似于itermonthdates()的年中的月月的迭代器。天返回只会天的数字。 monthdatescalendar(year, month) 全周在一年的月每月返回列表的几个星期。周是七个datetime.date对象的列表。 monthdays2calendar(year, month) 全周在一年的月每月返回列表的几个星期。周是天数字以及平日七元组的列表。 monthdayscalendar(year, month) 全周在一年的月每月返回列表的几个星期。周有七天的数字列表。 yeardatescalendar(year, width=3) 返回为指定年份的数据准备好格式。返回值是的月行的列表。每个月行包含到宽度(默认为 3) 的几个月。每月包含 4 至 6 个星期,每星期包含 1 — — 7 天。天是datetime.date对象。 yeardays2calendar(year, width=3) 返回指定年份的准备格式化的数据(类似于yeardatescalendar())。星期列表中的条目是天数字以及平日的元组。天外面这个月的数字为零。 yeardayscalendar(year, width=3) 返回指定年份的准备格式化的数据(类似于yeardatescalendar())。星期列表中的条目是一天的数字。天外面这个月的数字为零。 class calendar.TextCalendar(firstweekday=0) 此类可用于生成纯文本的日历。 TextCalendar实例具有以下方法: formatmonth(theyear, themonth, w=0, l=0) 在一个多行字符串返回一个月的日历。如果提供了w ,它指定的日期列,居中的宽度。如果给出l ,它指定每个星期会使用的行的数。取决于构造函数中指定的第一个工作日或由setfirstweekday()方法设置的第一个工作日。 prmonth(theyear, themonth, w=0, l=0) 打印formatmonth()返回的一个月的日历。 formatyear(theyear, w=2, l=1, c=6, m=3) 返回一个m-列作为一个多行字符串的整整一年的日历。可选参数w、 l和c分别为日期列的宽度,每周和每月列之间的空格数行。取决于构造函数中指定的第一个工作日或由setfirstweekday()方法设置的第一个工作日。最早一年可以为其生成的日历是取决于平台。 pryear(theyear, w=2, l=1, c=6, m=3) 打印formatyear()返回的整年的日历。 class calendar.HTMLCalendar(firstweekday=0) 此类可用于生成 HTML 的日历。 HTMLCalendar实例具有以下方法: formatmonth(theyear, themonth, withyear=True) 作为一个 HTML 表中返回一个月的日历。如果withyear为 true 年将包括在页眉中,否则将使用只是月份名称。 formatyear(theyear, width=3) 作为一个 HTML 表返回一年的日历。width(默认值为3)指定每行的月数。 formatyearpage(theyear, width=3, css='calendar.css', encoding=None) 作为一个完整的 HTML 页面返回一年的日历。width(默认值为3)指定每行的月数。css是使用级联样式表的名称。如果不使用样式表,则可以传递None。编码指定的编码将用于输出 (默认设置为系统默认的编码)。 class calendar.LocaleTextCalendar(firstweekday=0, locale=None) TextCalendar的这个子类可以在构造函数中传递一个语言环境名称,并且将返回指定语言环境中的月和周日名称。如果此区域设置包括编码所有字符串包含月份和星期几名称将作为 unicode 返回。 class calendar.LocaleHTMLCalendar(firstweekday=0, locale=None) HTMLCalendar的此子类可在构造函数中传递一个语言环境名称,并将在指定的语言环境中返回月和周日名称。如果此区域设置包括编码所有字符串包含月份和星期几名称将作为 unicode 返回。 注这两个类的formatweekday()和formatmonthname()方法将当前语言环境临时更改为给定的语言环境。因为当前的区域设置是进程范围的设置,他们不是线程安全的。 对于简单的文本日历本模块提供了下列函数。 calendar.setfirstweekday(weekday) 设置每周开始的工作日(0是星期一,6是星期日)。MONDAY,TUESDAY,WEDNESDAY,THURSDAY,FRIDAY,SATURDAY和SUNDAY。例如,若要设置的第一个工作日到星期天: import calendar calendar.setfirstweekday(calendar.SUNDAY) calendar.firstweekday() 返回为平日的当前设置,每个星期开始。 calendar.isleap(year) 如果年是闰年,则返回True,否则False。 calendar.leapdays(y1, y2) 返回闰年的数目范围内从y1到y2 (专用), y1和y2是几年。 此函数适用于跨越一个世纪变化的范围。 calendar.weekday(year, month, day) 返回年(1970 -...),月的星期几(0 (1 - 12),天(1 - 31)。 calendar.weekheader(n) 返回包含缩写的星期几名称的标头。n指定宽度 (以字符为一个工作日。 calendar.monthrange(year, month) 返回月份,为指定的年、月中的工作日的天数,每月的第一天。 calendar.monthcalendar(year, month) 返回一个矩阵,代表一个月的日历。每行代表一周;日期外的月份a由零表示。除非由setfirstweekday()设置,否则每周开始为星期一。 calendar.prmonth(theyear, themonth, w=0, l=0) 打印由month()返回的一个月的日历。 calendar.month(theyear, themonth, w=0, l=0) 使用TextCalendar类的formatmonth()返回多行字符串中的一个月的日历。 calendar.prcal(year, w=0, l=0, c=6, m=3) 打印由calendar()返回的整年的日历。 calendar.calendar(year, w=2, l=1, c=6, m=3) 使用TextCalendar类的formatyear())作为多行字符串返回整年的3列日历。 calendar.timegm(tuple) 一个不相关但方便的函数,它需要一个时间元组,例如由time模块中的gmtime()函数返回,并返回相应的Unix时间戳值, 1970,和POSIX编码。事实上,time.gmtime()和timegm()彼此相反。 calendar模块导出以下数据属性: calendar.day_name 一个数组,表示当前的区域设置中的星期数。 calendar.day_abbr 一个数组,表示当前的区域设置中的缩写的星期数。 calendar.month_name 一个数组,表示今年的几个月中的当前区域设置。这遵循正常惯例的1月是月份1,所以它的长度为13,month_name[0]是空字符串。 calendar.month_abbr 一个数组,表示今年的缩写个月中的当前区域设置。这遵循1月的月份1的正常惯例,因此它的长度为13,而month_abbr[0]是空字符串。
os模块
目录相关操作
#创建 os.mkdir("test1",0o777) #单级创建目录,如果原来存在就报错 os.makedirs("test1",0o777,True) #多级递归创建,如果存在最后一个True,存在也不报错,False想同文件会报错 #查询 os.getcwd() #执行文件目录,和os.path.abspath(os.curidr)一样的 os.listdir("test1") #查看目录下所有的文件和目录 os.stat("test1") #文件状态包括atime查看时间,mtime修改时间,ctime创建时间 os.stat("1.txt").st_size 或者.st_atime os.curdir #执行文件的当前目录,就是. os.pardir #当前工作目录的父目录,就是.. os.sep #路径分隔符 windows是"\\" linux是"/" os.linesep #换行分隔符,windows是"\r\n" linux是"\n" os.pathsep #文件分隔符,windows是";" linux是":" os.name #系统名字,windows是"nt" linux是"posix" os.environ #系统环境 os.getenv("USERNAME") #获取环境变量的值 #修改 os.chdir("test1") #修改当前目录 os.rename("old_name","new_name") #重命名 #删除 os.remove("1.txt") #删除文件 os.removedirs("test1") #删除目录递归删除,如果里面不是空,就不能删除该文件夹,且会报错 os.rmdir("test1") #删除目录单级别
os.path操作
os.path.abspath(path) #绝对路径 os.path.realpath(path) #实际路径,软链接指的实际链接 os.path.dirname(path) #路径的目录,最后不可以"\"结尾,否则报错 os.path.basename(path) #返回路径的最后文件,如果是"\"则返回空 os.path.split(path) #返回(目录,文件) os.path.getatime(path) #返回最后存储时间 #判断 os.path.isabs(path) #是否是绝对路径 os.path.isfile(path) #是否是文件 os.path.isdir(path) #是否是目录
os.path.islink(path) #是否是软链接
os.path.ismount #是否被挂载
os.path.join(path1,path2)#把多个路径拼在一起,第一个是目录,第二个文件则拼接,同时文件和目录,保留第二个
其他操作
os.system("CMD命令") #执行对应命令
sys模块
sys指的是解释器的系统
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.modules 返回系统导入的模块字段,key是模块名,value是模块 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdout.write('please:') val = sys.stdin.readline()[:-1] sys.modules.keys() 返回所有已经导入的模块名 sys.modules.values() 返回所有已经导入的模块 sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息 sys.exit(n) 退出程序,正常退出时exit(0) sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0 sys.version 获取Python解释程序的 sys.api_version 解释器的C的API版本 sys.version_info ‘final’表示最终,也有’candidate’表示候选,serial表示版本级别,是否有后继的发行 sys.displayhook(value) 如果value非空,这个函数会把他输出到sys.stdout,并且将他保存进__builtin__._.指在python的交互式解释器里,’_’ 代表上次你输入得到的结果,hook是钩子的意思,将上次的结果钩过来 sys.getdefaultencoding() 返回当前你所用的默认的字符编码格式 sys.getfilesystemencoding() 返回将Unicode文件名转换成系统文件名的编码的名字 sys.setdefaultencoding(name)用来设置当前默认的字符编码,如果name和任何一个可用的编码都不匹配,抛出 LookupError,这个函数只会被site模块的sitecustomize使用,一旦别site模块使用了,他会从sys模块移除 sys.builtin_module_names Python解释器导入的模块列表 sys.executable Python解释程序路径 sys.getwindowsversion() 获取Windows的版本 sys.copyright 记录python版权相关的东西 sys.byteorder 本地字节规则的指示器,big-endian平台的值是’big’,little-endian平台的值是’little’ sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息 sys.exec_prefix 返回平台独立的python文件安装的位置 sys.stderr 错误输出 sys.stdin 标准输入 sys.stdout 标准输出 sys.platform 返回操作系统平台名称 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.maxunicode 最大的Unicode值 sys.maxint 最大的Int值 sys.version 获取Python解释程序的版本信息 sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0
json & pickle
json
编码:把各种类型转为可以传输或者存储的序列化
解码:把序列化转为各种数据类型
dumps和loads
import json a = 1 #可以是字典,列表,数字,元组,字符串,bool,None #编码:
f_json = open("json文件", "w")
a_json = json.dumps(a)
f_json.write(a_json)
#json.dump(a,f_json) #相当于上两句的综合
f_json.close()
#解码
f_json = open("json文件", "r")
json_str = f_json.read()
data2 = json.loads(json_str)
#data = json.load(f_json) #相当于上面两句综合
f_json.close()
dump和dumps区别:dumps是吧数据类型转为序列化,dump是多一步,存储在文件中
load和loads区别:loads是把序列化转为类型,load是多一步,直接从句柄转为类型,不用read()
pickle
import pickle a=1 f_pickle = open("pickle文件", "wb") # a_pickle = pickle.dumps(a) # f_pickle.write(a_pickle) pickle.dump(a,f_pickle,indent=4) #indent=4表示缩进,可读性强 f_pickle.close() f_pickle = open("pickle文件","rb") # pickle_str = f_pickle.read() # data = pickle.loads(pickle_str) data=pickle.load(f_pickle) f_pickle.close()
pickle和json区别:用法基本一致,
- pickle文件不可读,一堆乱码,json乱码就可以读
- pickle比json支持的类型更多,可以类什么的
shelve
当我们写程序的时候如果不想用关系数据库那么重量级的东东去存储数据,不妨可以试试用shelve。
import shelve #写入 f = shelve.open("shel") f["set"]={1,2,3} f["list"]=[1,2,3,4] f["dict"]={ "1":"2", "3":"4" } # with shelve.open("shel") as f: #读取的时候可以用for # set1 = f.get("set") # list1 = f.get("list") # dict1 = f.get("dict") set1 = f.get("set") list1 = f.get("list") dict1 = f.get("dict") nexit = f.get("baba") #不报错 print(set1,list1,dict1,nexit) #{1, 2, 3} [1, 2, 3, 4] {'1': '2', '3': '4'} None
1、shelve模块是一个简单的key,value将内存数据通过文件持久化的模块。
2、shelve模块可以持久化任何pickle可支持的python数据格式。
3、shelve就是pickle模块的一个封装。
4、shelve模块是可以多次dump和load。
xml模块

SAX
SAX是一种基于事件驱动的API。
利用SAX解析XML文档牵涉到两个部分:解析器和事件处理器。
解析器负责读取XML文档,并向事件处理器发送事件,如元素开始跟元素结束事件;
而事件处理器则负责对事件作出相应,对传递的XML数据进行处理。
1、对大型文件进行处理;
2、只需要文件的部分内容,或者只需从文件中得到特定信息。
3、想建立自己的对象模型的时候。
在python中使用sax方式处理xml要先引入xml.sax中的parse函数,还有xml.sax.handler中的ContentHandler。
import xml.sax class CountryHandler(xml.sax.ContentHandler): def __int__(self): self.currentData = "" self.type = "" self.year = "" self.gdppc="" self.neighbor = "" # 元素开始事件处理 def startElement(self, tag, attributes): self.CurrentData = tag if self.CurrentData == "country": title = attributes["name"] print("*****%s*****" % title) if self.CurrentData == "neighbor": self.neighbor = attributes["name"] # 元素结束事件处理 def endElement(self, tag): if self.CurrentData == "type": print("Type:", self.type) elif self.CurrentData == "year": print("year:", self.year) elif self.CurrentData == "gdppc": print("gdppc:", self.gdppc) elif self.CurrentData == "neighbor": print("neighbor:", self.neighbor) self.CurrentData = "" # 内容事件处理 def characters(self, content): if self.CurrentData == "type": self.type = content elif self.CurrentData == "year": self.year = content elif self.CurrentData == "gdppc": self.gdppc = int(content) + 1 import xml.dom.minidom if __name__ == '__main__': # # 创建一个 XMLReader # parser = xml.sax.make_parser() # # turn off namepsaces # parser.setFeature(xml.sax.handler.feature_namespaces, 0) # # # 重写 ContextHandler # Handler = CountryHandler() # parser.setContentHandler(Handler) # # parser.parse("xml_lesson") #使用xml.sax.parse Handler = CountryHandler() xml.sax.parse("xml_lesson", Handler) #xml.sax.parseString # Handler = CountryHandler() # data = "" # with open("xml_lesson", "r") as f : # data = f.read() # parse = xml.sax.parseString(data, Handler)
DOM
dom = xml.dom.minidom.parse("xml_lesson") #打开xml文档 root = dom.documentElement #得到xml文档对象 print("NodeName:",root.nodeName, root.nodeValue, root.nodeType, root.ELEMENT_NODE) countries = root.getElementsByTagName("country") #这里也可以搜索下一级,比如直接搜索year for country in countries : print("****country*****") if country.hasAttribute("name"): print("Name: %s"%country.getAttribute("name")) taglist=["rank","year","gdppc","neighbor" ] for tag in taglist: for item in country.getElementsByTagName(tag): #有几个满足的获取几个item的列表 if tag == "rank": print("%s: updated:%s data:%s "% (tag, item.getAttribute("updated"), item.firstChild.data)) #item.firstChild.data 获取text内容 if tag == "year": print("%s: age:%s name:%s data:%s "% (tag, item.getAttribute("age"),item.getAttribute("name"),item.firstChild.nodeValue)) item.setAttribute("age", str(int(item.getAttribute("age"))+1 )) if tag == "gdppc": print("%s: data:%s "% (tag,item.firstChild.data)) if tag == "neighbor": print("%s: direction:%s name:%s"% (tag,item.getAttribute("direction"), item.getAttribute("name"))) #新建节点,并赋值和赋属性 if country.getAttribute("name") == "Panama": new_node = dom.createElement("zhouguanglu") country.appendChild(new_node) new_node.setAttribute("xxx","baba") name_text = dom.createTextNode('计算机程序设计语言 第1版') new_node.appendChild(name_text) #修改完写入文件 with open("new_xml","w", encoding='UTF-8') as f: root.writexml(f) # root.writexml(f,indent='',addindent='\t',newl='\n')
Element Tree
tag:string,元素代表的数据种类。
text:string,元素的内容。
tail:string,元素的尾形。
attrib:dictionary,元素的属性字典。
#针对属性的操作
clear():清空元素的后代、属性、text和tail也设置为None。
get(key, default=None):获取key对应的属性值,如该属性不存在则返回default值。
items():根据属性字典返回一个列表,列表元素为(key, value)。
keys():返回包含所有元素属性键的列表。
set(key, value):设置新的属性键与值。
#针对后代的操作
append(subelement):添加直系子元素。
extend(subelements):增加一串元素对象作为子元素。#python2.7新特性
find(match):寻找第一个匹配子元素,匹配对象可以为tag或path。
findall(match):寻找所有匹配子元素,匹配对象可以为tag或path。
findtext(match):寻找第一个匹配子元素,返回其text值。匹配对象可以为tag或path。
insert(index, element):在指定位置插入子元素。
iter(tag=None):生成遍历当前元素所有后代或者给定tag的后代的迭代器。#python2.7新特性
iterfind(match):根据tag或path查找所有的后代。
itertext():遍历所有后代并返回text值。
remove(subelement):删除子元素。
try: import xml.etree.cElementTree as ET except ImportError: import xml.etree.ElementTree as ET tree = ET.parse("xml_lesson") root = tree.getroot() print(root.tag, root.attrib,root.text, root.tail, root[0].items(),list(root) ) print(root[1].tag,root[1][1].attrib) #第二个孩子,直接用索引查找后代 #对子节点进行遍历 for child in root : #只查找儿子 print(child.tag,child.attrib) #所有后代节点 for child in root.iter(): #包含自己,儿子,孙子以及后代的所有属性 print(child.tag,child.attrib) #按tag节点 for child in root.iter("year"): #查找后代中tag为year的节点 print(child.tag,child.attrib) for child in root.iterfind("country/gdppc"): #必须从儿子除法的路径,返回的是列表 print(child.tag, child.text) for child in root.find("country"): #find只查找找到的第一个country,找不到返回None,迭代错误,child为country的儿子迭代 print(child.tag, child.attrib) for child in root.findall("country"): #返回的是country列表 print("--------",child.tag,child.attrib) #属性查找,修改,获取 for child in root.iterfind("country[@name='Panama']"): #就返回一个country {'name': 'Panama'},但是返回的是country列表,所以打印的是country而不是后代 print(child.tag, child.attrib["name"],child.get("name")) child.set("name","new_Panama") #修改用set # del root[2] tree.write("new_xml")
RE模块


基本方法
方法/属性 作用 re.match(pattern, string, flags=0) 从字符串的起始位置匹配,如果起始位置匹配不成功的话,match()就返回none,成功的话返回的是match对象,包含多个属性 re.search(pattern, string, flags=0) 扫描整个字符串并返回第一个成功的匹配 成功返回match对象 不成功返回None re.findall(pattern, string, flags=0) 找到RE匹配的所有字符串,并把他们作为一个列表返回 ,不成功返回空列表 re.finditer(pattern, string, flags=0) 找到RE匹配的所有字符串,并把他们作为一个迭代器返回 ,失败返回空迭代器 re.sub(pattern, repl, string, count=0, flags=0) 替换匹配到的字符串 函数参数说明: pattern:匹配的正则表达式 string:要匹配的字符串 flags:标记为,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 repl:替换的字符串,也可作为一个函数 count:模式匹配后替换的最大次数,默认0表示替换所有匹配
反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
- 如果用原生r模式,反斜杠用于正则的匹配时候,用一个斜杠,如例1;如果用于\匹配,得给re模式两个反斜杠,如例3
- 如果用字符串模式,反斜杠是原生模式的两倍,一半用于python解释器的转义,另外给re模式
print(re.findall(r"c\f", "abc\ftt")) #['c\x0c'] 反斜杠用于转义\f,所以只要一个\ print(re.findall("c\\f", "abc\ftt")) #['c\x0c'] print(re.findall(r"c\\l","abc\ltt")) #['c\\l'] 因为re需要匹配反斜杠,所以把反斜杠转义,re需要两个反斜杠 print(re.findall("c\\\\l","abc\ltt")) #['c\\l'] 显示两个反斜杠,其实只有一个,用于匹配
数量词的贪婪模式与非贪婪模式
python默认是贪婪模式,如果要转化为非贪婪模式在后面加?
- (.*) 贪婪模式
- (.*?)非贪婪模式
print(re.findall("(.*)","abc")) #['abc', ''] print(re.findall("(.*?)","abc")) #['', 'a', '', 'b', '', 'c', ''] 6个
flags定义
flags定义包括:
re.I:忽略大小写
re.L:表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M:多行模式
re.S:' . '并且包括换行符在内的任意字符(注意:' . '不包括换行符)
re.U: 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.findall
re.findall(pattern, string, flags=0) 找到RE匹配的所有字符串,并把他们作为一个列表返回 ,不成功返回空列表
注意事项:
- 如果pattern中有(),则优先输入括号内的东西,如果不想添加优先级可以写(?:),来取消
- 尽量有原生字符,r"xxxxx",简单还比较容易
- .不表示换行符,要想表示需要把flags=re.S
print(re.findall("(?:abc)+","abcabcabc")) #['abcabcabc'] print(re.findall("(abc)+","abcabcabc")) #['abc'] 其实匹配的是abcabcabc,但是优先输出匹配上的abc
print(re.findall("(\w*)(\w*)","helloworld")) #[('helloworld', ''), ('', '')]
print(re.findall("(\w)*(\w)*","helloworld")) #[('d', ''), ('', '')] 输出的是括号内的东西
print(re.findall(r"((?P<name>\w).+(?P=name))","helloworld")) #[('lloworl', 'l')] 这是前后字符相等包含的内容,如果想要保留整个匹配字符,需要在整体上加()
print(re.findall(r"a\b!bc","a!bc")) #['a!bc'] \b表示a后面跟的不是字母,位置关系,不代表元素
print(re.findall("a\b!bc","a!bc")) #没用原生字符,给re的是转义完的\b
print(re.findall(r"a\Bbc","abc")) #a后面跟着字母
print(re.findall("a\B!bc","a!bc")) #没用原生字符,给re的是转义完的\b
re.match
re.match(pattern, string, flags=0) 从字符串的起始位置匹配,如果起始位置匹配不成功的话,match()就返回none,成功的话返回的是match对象,包含多个属性
print(re.match("(e)","ef").groups()) #('e',) 返回元组,匹配到 print(re.match("e","ef").groups()) #()匹配到,但是没有分组,所以 # print(re.match("(e)","aef").groups()) #返回None,报错,无groups分组 print(re.match("e","aef").groups()) #报错
match对象的属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
- group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。 - groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。 - groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。 - start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。 - end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。 - span([group]):
返回(start(group), end(group))。 - expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!') print(m) #<re.Match object; span=(0, 12), match='hello world!'> print("m.string:", m.string) #m.string: hello world! print("m.re:", m.re) #m.re: re.compile('(\\w+) (\\w+)(?P<sign>.*)') print("m.pos:", m.pos) #m.pos: 0 print("m.endpos:", m.endpos) #m.endpos: 12 print("m.lastindex:", m.lastindex) #m.lastindex: 3 指的group的索引,不是字节的索引 print("m.lastgroup:", m.lastgroup) #m.lastgroup: sign print("m.group(1,2):", m.group(1, 2)) # m.group(1,2): ('hello', 'world') print( "m.groups():", m.groups()) #m.groups(): ('hello', 'world', '!') print("m.groupdict():", m.groupdict()) #m.groupdict(): {'sign': '!'} print("m.start(2):", m.start(2)) #m.start(2): 6 print("m.end(2):", m.end(2)) #m.end(2): 11 print("m.span(2):", m.span(2)) #m.span(2): (6, 11) print(r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\3')) #m.expand(r'\2 \1\3'): world hello!
re.search
re.search(pattern, string, flags=0)
- 只匹配一个,当没有()时候可以用group(),当两个以上()时候用groups,或者group查看
re.search('\d','adsf123456we7we').group() #1 只匹配一个
re.finditer
re.finditer(pattern, string, flags=0) 找到RE匹配的所有字符串,并把他们作为一个迭代器返回 ,失败返回空迭代器
迭代器里是match对象
re.compile
创建Pattern实例
m = re.compile(r"\d+")
以后都可以复用了,而且与其他的相比,少写一个Pattern
m.findall("ddddddd")
re.sub
re.sub(pattern, repl, string[, count, flags])
sub(repl, string[, count=0])
说明:在字符串 string 中找到匹配正则表达式 pattern 的所有子串,用另一个字符串 repl 进行替换。如果没有找到匹配 pattern 的串,则返回未被修改的 string。
Repl 既可以是字符串也可以是一个函数。
- 需要将2017-01-22转换成01-22-2017
s = "2017-01-22" print(re.sub("(\d{4})-(\d{2})-(\d{2})",r"\2/\3/\1",s)) print(re.sub("(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})","\g<month>/\g<day>/\g<year>",s))
-
需要将book.txt 中的书籍价格都提高5%
def func(m): price = m.group(2) price = float(price) * 1.05 return "%s %.2f"%(m.group(1),price) print(re.sub("(\w+)\s+(\d+.?\d*)",func,"booka 21.22 bookb 22.33")) #booka 22.28 bookb 23.45 字符串也可以是文件句柄
- 把所有的a或者b都删掉
print(re.sub("a|b","","ddacbdds")) #ddcdds
- 把一换成1,二换成2
#把一转化为1,二转为2 def func(m): if m.group(0) == "一": return "1" elif m.group(0)== "二": return "2" print(re.sub("([一二])",func,"1一2二")) #\2后面跟2应该写成\g<2> 1122
re.subn
与re.sub基本相同,re.sub返回替换后的字符串,re.subn返回一个元组
re.subn("(ab)","22","abcdeabcd") #('22cde22cd', 2)
re.split
re.split(pattern, string[, maxsplit=0, flags=0])
可以多个符号一起分割
import re inputStr = 'abc aa;bb,cc | dd(xx).xxx 12.12'; print(re.split(' ',inputStr)) #['abc', 'aa;bb,cc', '|', 'dd(xx).xxx', '12.12'] print(re.split("[ |;,.]",inputStr)) #['abc', 'aa', 'bb', 'cc', '', '', 'dd(xx)', 'xxx', '12', '12']
logging
logging.basicConfig
import logging logging.addLevelName(15,"name") logging.basicConfig( filename='app.log', level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(message)s', datefmt='%Y-%m-%d %H:%M:%S', #filemode='w' #默认是'a' ) logging.info('test info') logging.debug('test debug') logging.warning('test warning') logging.error('test error') logging.critical('test critical') logging.log(15, '自定义设置级别')
为日志模块配置基本信息。basicconfig的参数kwargs 支持如下几个关键字参数:
filename :日志文件的保存路径。如果配置了些参数,将自动创建一个FileHandler作为Handler;
filemode :日志文件的打开模式。 默认值为'a',表示日志消息以追加的形式添加到日志文件中。如果设为'w', 那么每次程序启动的时候都会创建一个新的日志文件;
format :设置日志输出格式;
datefmt :定义日期格式;
level :设置日志的级别.对低于该级别的日志消息将被忽略;
stream :设置特定的流用于初始化StreamHandler;
format: 指定输出的格式和内容,format可以输出很多有用信息,如上例所示:
%(levelno)s: 打印日志级别的数值
%(levelname)s: 打印日志级别名称
%(pathname)s: 打印当前执行程序的路径,其实就是sys.argv[0]
%(filename)s: 打印当前执行程序名
%(funcName)s: 打印日志的当前函数
%(lineno)d: 打印日志的当前行号
%(asctime)s: 打印日志的时间
%(thread)d: 打印线程ID
%(threadName)s: 打印线程名称
%(process)d: 打印进程ID
%(message)s: 打印日志信息
配置方式
- 显式创建记录器Logger、处理器Handler和格式化器Formatter,并进行相关设置;
- 通过简单方式进行配置,使用basicConfig()函数直接进行配置;
- 通过配置文件进行配置,使用fileConfig()函数读取配置文件;
- 通过配置字典进行配置,使用dictConfig()函数读取配置信息;
- 通过网络进行配置,使用listen()函数进行网络配置。
fileconfig

通过logging.config模块配置日志
|
|
上例3:
|
|
上例4:
|
|
logging.disable(level)
其作用是禁用所有日志(当其级别在给定级及以下),暂时截流日志输出
logging.disable(logging.WARNING)#提供一个覆盖所有优先于日志级别的级别
logging.warn('msg') #没有输出
logging.critical('msg') #CRITICAL:msg
撤销的话,就使用logging.disable(level)或logging.disable(logging.NOSET)
logging.addLevelName(lel,levelname)
增加自定义的logging level,并起名。
logging.addLevelName(88,'myLevelName') logging.log(88, '自定义设置级别') #myLevelName:root:自定义设置级别
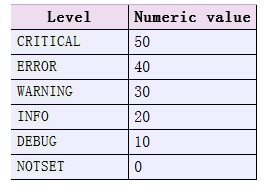
级别是整数,系统设置如下:
logging.getLevelName(lvl)
返回的文本表示的日志级别
logging.addLevelName(88,'myLevelName') logging.log(88, '自定义设置级别') #myLevelName:root:自定义设置级别 print logging.getLevelName(88) #myLevelName print logging.getLevelName(logging.INFO) #INFO
getLogger(name)


#创建对象 import sys LOG = logging.getLogger() LOG1 = logging.getLogger("chat") LOG1_1 = logging.getLogger("chat.gui") #LOG.propagate=False #LOG1.propagate=False #LOG1_1.propagate=False #设置False完LOG1_1就不用把log_record传给父亲,也就是只输出一遍 #设置级别 LOG.setLevel(logging.DEBUG) LOG1.setLevel(logging.INFO) LOG1_1.setLevel(logging.WARNING) #输出处理 fh = logging.FileHandler("filehandle","w") fh.setLevel(logging.INFO) # ch = logging.StreamHandler() ch = logging.StreamHandler(sys.stdout) nh = logging.NullHandler(logging.NOTSET) # wf = logging.handlers.WatchedFileHandler("watchfile") # rf = logging.handlers.RotatingFileHandler("rotatefile") # tf = logging.handlers.TimedRotatingFileHandler("rotatefile",when="H",backupCount=24*7) fmt = logging.Formatter("%(asctime)s %(filename)s[line:%(lineno)d] %(message)-5s") fh.setFormatter(fmt) fmt1 = logging.Formatter("22222 %(asctime)s %(filename)s[line:%(lineno)d] %(message)-5s") ch.setFormatter(fmt1) LOG.addHandler(fh) LOG.addHandler(ch) LOG1.addHandler(fh) LOG1.addHandler(ch) LOG1_1.addHandler(fh) LOG.debug("LOG DEBUG") #按照fh的level执行 LOG.info("LOG INFO") LOG.warning("LOG WARNING") LOG.error("LOG ERROR") LOG.critical("LOG CRITICAL") LOG1.debug("LOG1 DEBUG") LOG1.info("LOG1 INFO") LOG1.warning("LOG1 WARNING") LOG1.error("LOG1 ERROR") LOG1.critical("LOG1 CRITICAL") LOG1_1.debug("LOG1_1 DEBUG") LOG1_1.info("LOG1_1 INFO") LOG1_1.warning("LOG1_1 WARNING") LOG1_1.error("LOG1_1 ERROR") LOG1_1.critical("LOG1_1 CRITICAL")
#输出如下:
22222 2019-01-03 00:31:19,238 log.py[line:66] LOG DEBUG
22222 2019-01-03 00:31:19,238 log.py[line:67] LOG INFO
22222 2019-01-03 00:31:19,238 log.py[line:68] LOG WARNING
22222 2019-01-03 00:31:19,238 log.py[line:69] LOG ERROR
22222 2019-01-03 00:31:19,238 log.py[line:70] LOG CRITICAL
22222 2019-01-03 00:31:19,239 log.py[line:73] LOG1 INFO
22222 2019-01-03 00:31:19,239 log.py[line:73] LOG1 INFO
22222 2019-01-03 00:31:19,239 log.py[line:74] LOG1 WARNING
22222 2019-01-03 00:31:19,239 log.py[line:74] LOG1 WARNING
22222 2019-01-03 00:31:19,239 log.py[line:75] LOG1 ERROR
22222 2019-01-03 00:31:19,239 log.py[line:75] LOG1 ERROR
22222 2019-01-03 00:31:19,239 log.py[line:76] LOG1 CRITICAL
22222 2019-01-03 00:31:19,239 log.py[line:76] LOG1 CRITICAL
22222 2019-01-03 00:31:19,240 log.py[line:80] LOG1_1 WARNING #之后的都不是LOG1_1产生的而是把record传给父亲造成的
22222 2019-01-03 00:31:19,240 log.py[line:80] LOG1_1 WARNING
22222 2019-01-03 00:31:19,240 log.py[line:81] LOG1_1 ERROR
22222 2019-01-03 00:31:19,240 log.py[line:81] LOG1_1 ERROR
22222 2019-01-03 00:31:19,241 log.py[line:82] LOG1_1 CRITICAL
22222 2019-01-03 00:31:19,241 log.py[line:82] LOG1_1 CRITICAL
#文件如下:
2019-01-03 00:31:19,238 log.py[line:67] LOG INFO
2019-01-03 00:31:19,238 log.py[line:68] LOG WARNING
2019-01-03 00:31:19,238 log.py[line:69] LOG ERROR
2019-01-03 00:31:19,238 log.py[line:70] LOG CRITICAL
2019-01-03 00:31:19,239 log.py[line:73] LOG1 INFO
2019-01-03 00:31:19,239 log.py[line:73] LOG1 INFO
2019-01-03 00:31:19,239 log.py[line:74] LOG1 WARNING
2019-01-03 00:31:19,239 log.py[line:74] LOG1 WARNING
2019-01-03 00:31:19,239 log.py[line:75] LOG1 ERROR
2019-01-03 00:31:19,239 log.py[line:75] LOG1 ERROR
2019-01-03 00:31:19,239 log.py[line:76] LOG1 CRITICAL
2019-01-03 00:31:19,239 log.py[line:76] LOG1 CRITICAL
2019-01-03 00:31:19,240 log.py[line:80] LOG1_1 WARNING
2019-01-03 00:31:19,240 log.py[line:80] LOG1_1 WARNING
2019-01-03 00:31:19,240 log.py[line:80] LOG1_1 WARNING
2019-01-03 00:31:19,240 log.py[line:81] LOG1_1 ERROR
2019-01-03 00:31:19,240 log.py[line:81] LOG1_1 ERROR
2019-01-03 00:31:19,240 log.py[line:81] LOG1_1 ERROR
2019-01-03 00:31:19,241 log.py[line:82] LOG1_1 CRITICAL
2019-01-03 00:31:19,241 log.py[line:82] LOG1_1 CRITICAL
2019-01-03 00:31:19,241 log.py[line:82] LOG1_1 CRITICAL
logger命名
logging.getLogger()相当于祖先
logging.getLogger("test") 相当于一代
logging.getLogger("test.child") 相当于二代,用.点来区分后代
多次输出问题
LOG1_1.propagate=False 这个设置一下就不会多次输出
Handler
|
logging.StreamHandler: 日志输出到流,可以是sys.stderr、sys.stdout或者文件 日志回滚方式,实际使用时用RotatingFileHandler和TimedRotatingFileHandler logging.handlers.SocketHandler: 远程输出日志到TCP/IP sockets |
Filter
def filt(record): if record.levelno <50: return False return True ff = logging.Filter() ff.filter = filt #可以是函数,可以是lambda 可以是重新定义类中的filter fh.addFilter(ff)
文件切分按时记录按大小切分
import time import logging import logging.handlers # logging初始化工作 logging.basicConfig() # myapp的初始化工作 myapp = logging.getLogger('myapp') myapp.setLevel(logging.INFO) # 添加TimedRotatingFileHandler # 定义一个1秒换一次log文件的handler # 保留3个旧log文件 filehandler = logging.handlers.TimedRotatingFileHandler("myapp.log", when='S', interval=1, backupCount=3) # 设置后缀名称,跟strftime的格式一样 filehandler.suffix = "%Y-%m-%d_%H-%M-%S.log" myapp.addHandler(filehandler) while True: time.sleep(0.1)
configparser
写入
""" ;在ini中是注释的意思 [DEFAULT] zhou = Asia people = Asian [china] name = china time = UTF-8 city = 1000 [japan] name = japan time = UTF-buzhidao city = 2 """ import configparser config = configparser.ConfigParser() #第一种添加方法 config["DEFAULT"]={ "zhou":"Asia", "people":"Asian" } #第二种添加方法 config["china"]={} config["china"]["name"]="china" config["china"]["time"]="UTF-8" config["china"]["city"]="1000" #第三种添加方法 config.add_section("japan") config.set("japan","name","japan") #config.set(section, option, value) config["japan"]["time"]="UTF-buzhidao" config["japan"]["city"] = "2" #必须是字符串 config.clear() #这里只删除除了default的其他sections #第4中方法 config_dict = { "DEFAULT":{ "zhou":"Asia", "people":"Asian" }, "china":{ "name":"china", "time":"UTF-8", "city":"1000" }, "japan":{ "name": "japan", "time": "UTF-buzhidao", "city": "2" } } config.read_dict(config_dict) # 写入配置文档 with open("config.ini","w") as f: config.write(f)
#config.ini [DEFAULT] zhou = Asia people = Asian [china] name = china time = UTF-8 city = 1000 [japan] name = japan time = UTF-buzhidao city = 2
读取
import configparser config = configparser.ConfigParser() config.read("config.ini") print(config.sections()) #['china', 'japan'] 这里不带DEFAULT ,DEfault在每个setions中 print("china" in config) #True print(config["DEFAULT"]["people"]) #Asian print(config["china"]["city"]) #1000 for key in config["china"]: print(key) #name #time #city #zhou #people #default的每一个都会在sections print(config.options("china")) #['name', 'time', 'city', 'zhou', 'people'] print(config.items("china")) #[('zhou', 'Asia'), ('people', 'Asian'), ('name', 'china'), ('time', 'UTF-8'), ('city', '1000')] print(config.get("china","city")) #1000 #和dict的不同dict(key,默认值), 这里的get(sections,args)
- items()此种方法获取到的配置文件中的options内容均被转换成小写。
- default的参数都在每个sections都有
config.read('example.ini',encoding="utf-8") """读取配置文件,python3可以不加encoding""" options(section) """sections(): 得到所有的section,并以列表的形式返回""" config.defaults() """defaults():返回一个包含实例范围默认值的词典""" config.add_section(section) """添加一个新的section""" config.has_section(section) """判断是否有section""" print(config.options(section)) """得到该section的所有option""" has_option(section, option) """判断如果section和option都存在则返回True否则False""" read_file(f, source=None) """读取配置文件内容,f必须是unicode""" read_string(string, source=’’) """从字符串解析配置数据""" read_dict(dictionary, source=’’) """从词典解析配置数据""" get(section, option, *, raw=False, vars=None[, fallback]) """得到section中option的值,返回为string类型""" getint(section,option) """得到section中option的值,返回为int类型""" getfloat(section,option) """得到section中option的值,返回为float类型""" getboolean(section, option) """得到section中option的值,返回为boolean类型""" items(raw=False, vars=None) """和items(section, raw=False, vars=None):列出选项的名称和值""" set(section, option, value) """对section中的option进行设置""" write(fileobject, space_around_delimiters=True) """将内容写入配置文件。""" remove_option(section, option) """从指定section移除option""" remove_section(section) """移除section""" optionxform(option) """将输入文件中,或客户端代码传递的option名转化成内部结构使用的形式。默认实现返回option的小写形式;""" readfp(fp, filename=None) """从文件fp中解析数据"""
hashlib
import hashlib x = hashlib.md5("zgl".encode("utf8")) print(x.hexdigest()) #fb1153335c84add787134c7891435e88 x.update("hello".encode("utf8")) print(x.hexdigest()) #8bdd67b2306c049917c6eff9ed35a975 y = hashlib.md5("zglhello".encode("utf8")) print(y.hexdigest()) #8bdd67b2306c049917c6eff9ed35a975
- hashlib()初始化必须是字节类型
- update是叠加更新,先更新zgl,在更新hello,和一起更新一样
random
import random random.seed(3) #播种子 print(random.random()) #随机0到1之间的数字 print(random.uniform(1,10)) #大于等于1小于等于10的随机数 print(random.randint(1,2)) #大于等于1 小于等于2的整数 print(random.randrange(1,10,2)) #z在1,3,5,7,9中选一个 print(random.choice(range(0,9))) #从序列中选择一个 print(random.sample(range(1,10),2)) #从序列中随机随机抽取2个序列拍成列表 p =[1,2,3,4,5] random.shuffle(p) #随机打乱 print(p) #输出如下 0.23796462709189137 5.898063027663567 2 9 7 [2, 1] [2, 1, 5, 3, 4]
fileinput
random
集合堆双端序列
Tempate
re
logging
argparse
cmd
csv
datetime
difflib
enum
functools
itertools
statistics
timeit
profile
trace
linecache 大文件取某一行,首选
shutil
suprocess
xlswriter

支付宝
您的资助是我最大的动力!
金额随意,欢迎来赏!
微信



