
你真的了解for循环遍历么(Java集合容器)
你真的了解for循环遍历么
今天讲的for循环主要是针对Java语言的JDK1.8,在编程过程中或多或少的遇到过for循环遍历,比如:List、Set、Map等等集合容器,有时候碰到需要对集合容器数据进行相应的增删改操作的时候,都会纠结一番到底会不会出现修改问题呢,如何遍历会更好呢。
等看完这篇你会觉得真的不一样了。
日常遍历的几种方式
首先我们先了解一下集合容器中日常遍历的几种方式:
List集合遍历方式(ArrayList)
// 遍历list集合 private static void listTest() { List<String> list = new ArrayList<String>(); list.add("liubei"); list.add("guanyu"); list.add("zhangfei"); // 使用传统for循环进行遍历 for (int i = 0, size = list.size(); i < size; i++) { String value = list.get(i); System.out.println(value); } // 使用增强for循环进行遍历 与iterator迭代器一致 for (String value : list) { System.out.println(value); } // 使用iterator遍历 Iterator<String> it = list.iterator(); while (it.hasNext()) { String value = it.next(); System.out.println(value); } //ArrayList 继承父类 Iterable 重写forEach 方法,进行相应校验判断,传统fori循环调用accept输出 list.forEach(new Consumer<String>() { @Override public void accept(String key) { System.out.println(key); } }); //Lambda 函数式Consumer list.forEach(key -> { System.err.println(key); }); }
Set集合遍历方式(HashSet)
private static void setTest() { Set<String> set = new HashSet<String>(); set.add("JAVA"); set.add("C"); set.add("C++"); // 使用iterator遍历set集合 Iterator<String> it = set.iterator(); while (it.hasNext()) { String value = it.next(); System.out.println(value); } // 使用增强for循环遍历set集合 字节码查看底层实际也是Iterator迭代器实现,与上面一样,写法区别而已 for (String s : set) { System.out.println(s); } //HashSet 继承父类 Iterable 直接调用父类forEach循环Consumer this 迭代器 循环accept方式 set.forEach(new Consumer<String>() { @Override public void accept(String key) { System.err.println(key); } }); //Lambda 函数式Consumer set.forEach(key -> { System.err.println(key); }); }
Map集合容器的遍历方式(HashMap)
public static void mapTest() { Map<String, String> maps = new HashMap<String, String>(); maps.put("1", "PHP"); maps.put("2", "Java"); maps.put("3", "C"); maps.put("4", "C++"); maps.put("5", "HTML"); Set<Map.Entry<String, String>> set = maps.entrySet(); //取key的增强遍历 实际 迭代器行为 Set<String> keySet = maps.keySet(); for (String s : keySet) { String key = s; String value = maps.get(s); System.out.println(key + " : " + value); } // 增强循环 实际 迭代器行为 for (Map.Entry<String, String> entry : set) { String key = entry.getKey(); String value = entry.getValue(); System.out.println(key + " : " + value); } // 迭代器遍历。 Iterator<Map.Entry<String, String>> it = set.iterator(); while (it.hasNext()) { Map.Entry<String, String> entry = (Map.Entry<String, String>) it.next(); String key = entry.getKey(); String value = entry.getValue(); System.out.println(key + " : " + value); } //HashMap 重写Map接口的forEach默认实现,进行相应的判断,传统fori遍历数组形式 maps.forEach(new BiConsumer<String, String>() { @Override public void accept(String key, String value) { System.err.println(key + " : " + value); } }); //Lambda 函数式Consumer maps.forEach((key,value)->{ System.err.println(key + " : " + value); }); }
遍历的问题
1、用那种遍历更好呢!
2、遍历的时候能操作(增删)集合信息么!
3、遍历中断、跳过怎么玩的!
每次撸代码的时候都会或多或少的思考一下这些问题,这也是基本工。
第一个问题:用那种遍历更好呢!
个人理解,主要还是要看业务中需要遍历的是什么类型的集合(数组),内部需要怎么操作,有时候就是需要获取根据下标位置进行业务逻辑处理,那就需要传统的for循环了。若是只是遍历进行key处理不涉及下标位置的,一般会选择foreach形式,比较简单快捷,其内部原理还是Iterator迭代器行为,Iterator一般不写主要原因比较麻烦复杂了点。
第二个问题:遍历的时候能操作(增删)集合信息么!
这个问题是本文中主要的部分,也是大多数人都会思考的问题,但是好像好多时候都理解错了。接下来我要颠覆认知的操作了。(也有可能是小丑)
在遍历增加删除的时候,首先大部分人都会想用那种遍历好,那种不会报错呢!报错的原因都以为是数组大小等问题,借着网上一堆解释糊弄了自己,结果一群人都被糊弄了。
举几个栗子:
ArrayList的传统的fori方式
应该都知道这个方式的增删没有问题吧

若是将传统for循环换成这样的,就会出现意想不到意思了--》【死循环】
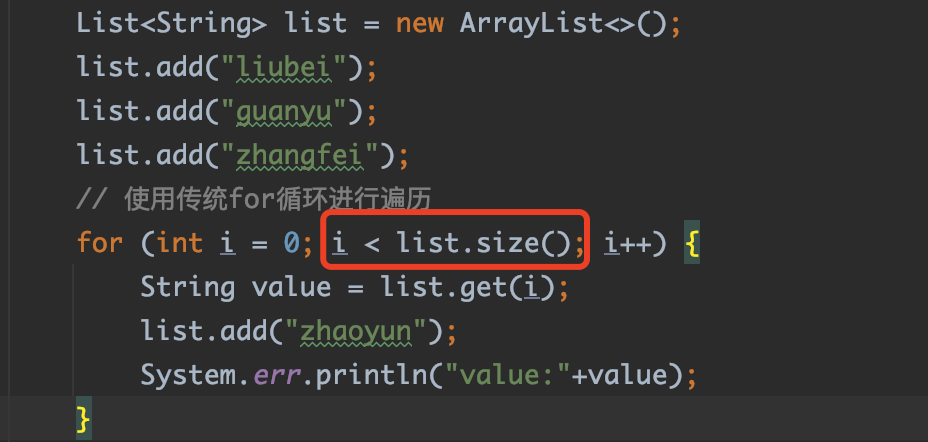
出现以上问题的原因是,list的add每次添加的时候是都会将size增加【size++】,所有判断一直有效,死循环。remove的时候会对size递减【--size】,并不会出现null的出现,但是elementData数组大小是没变的,判断的是size。
说明在传统的for循环中,对集合的操作没有任何限制,只是写法问题会出现逻辑死循环。
ArrayList的foreach和Iterator方式
通过查看字节码信息了解到这两种方式其实是一样的原理
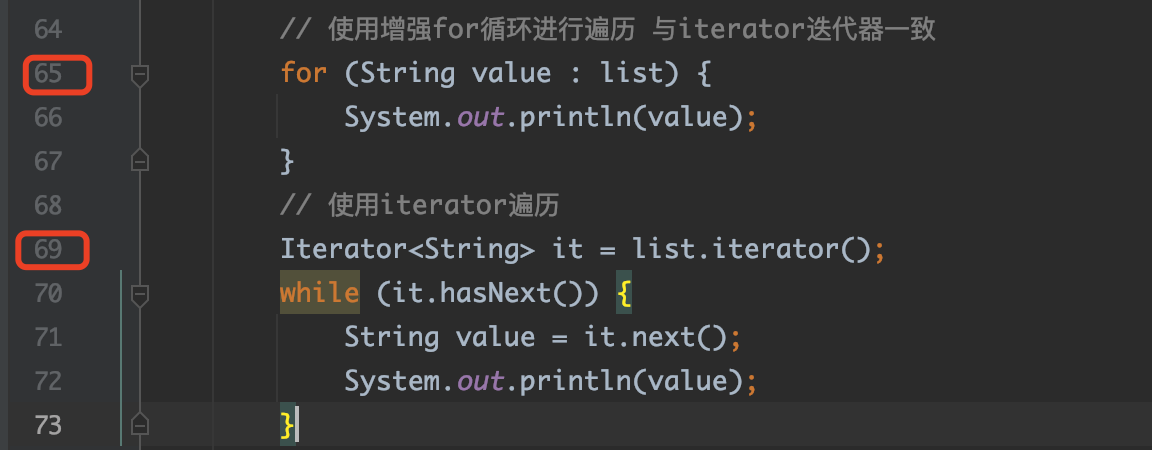
以下是上面的是字节码体现,可根据行号,对号入座,可以发现原理是一致的。

所有对这个的研究就直接针对迭代器就OK了,先看看ArrayList是否有对迭代器进行实现重写。一看还真有,对hasNext()、next()、remove()都进行了重写,在迭代器中没有元素的添加add行为,那我们来看看这些迭代器为啥有时候出问题有时候不会出问题。
其实关键这些都是围绕这modCount 属性做各种判断检查,主要意思是监控集合被修改的次数。
在ArrayList中使用迭代器遍历,迭代器在初始化的时候就将modCount属性赋值给迭代器自身的expectedModCount属性,需要仔细好好的看看源码,了解其中设计思想。

看看hasNext(),主要原理是看看cursor索引是否是到最后(size)了
public boolean hasNext() { return cursor != size; }
next(),主要原理是检查元素是否被修改、索引的大小、与内部数组大小的比较
public E next() { //检查集合是否被修改 checkForComodification(); int i = cursor; //索引是否超过集合大小 if (i >= size) //抛出没有这样的元素 异常 throw new NoSuchElementException(); //判断索引是否超过集合内部数组大小 Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) //抛出被并发修改异常 throw new ConcurrentModificationException(); //索引++ cursor = i + 1; //返回指定位置的元素 return (E) elementData[lastRet = i]; }
我们在看一下checkForComodification()方法就大概知道啥意思了
final void checkForComodification() { //检查集合的修改次数和迭代器预期的次数(初始化赋值那个)是否一致 if (modCount != expectedModCount) throw new ConcurrentModificationException(); }
最后看一下迭代器中的remove()方法,主要先检查是否有并发修改问题,然后利用ArrayList自身的remove()方法进行删除,修改modCount,并赋值给expectedModCount,差不多就是哪些俗称Fail-Fast以便下次checkForComodification()方法检查时不会出现问题。
public void remove() { // if (lastRet < 0) throw new IllegalStateException(); //检查是否被修改过 checkForComodification(); try { //调用ArrayList的自身的remove删除元素 ArrayList.this.remove(lastRet); //将索引值赋值为当前索引值,因为next的时候cursor++了 cursor = lastRet; //防止同一次遍历过程中删除两次 lastRet = -1; //将ArrayList中修改过的modCount 重新赋值给迭代器expectedModCount属性 expectedModCount = modCount; } catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException(); } }
总结:从以上代码我们可以很容易的知道,在foreach和迭代器中删除元素时不会出现问题的,原因是ArrayList自身实现迭代器Iterator进行了一些逻辑处理,迭代器检查并调用ArrayList的删除方法,修改modCount的值,主要是modCount的灵活运用。但是对于添加元素add,迭代器中未做相关处理,所有会出现modCount的修改,并未同步给迭代器的expectedModCount属性,导致会出现同步修改问题ConcurrentModificationException。
ArrayList的foreach方法
应该知道集合循环有foreach方式底层原理是迭代器Iterator行为,但ArrayList中有一个foreach方法真实存在的,是实现Iterable重写foreach方法。
其实大部分的集合容器都有foreach方法,也比较实用,使用方式在上面ArrayList遍历方式中已经写过。
主要原理跟迭代器的remove有些类似,也是fail-fast行为策略,判断这个过程值modCount是否变化。
@Override public void forEach(Consumer<? super E> action) { Objects.requireNonNull(action); //将modCount值先保存一下 final int expectedModCount = modCount; @SuppressWarnings("unchecked") final E[] elementData = (E[]) this.elementData; final int size = this.size; //传统的for循环,每次循环还要判读modCount是否变化了 for (int i=0; modCount == expectedModCount && i < size; i++) { //业务逻辑点 action.accept(elementData[i]); } //判断这个过程中modCount是否变化了 if (modCount != expectedModCount) { //变化,则抛出异常 throw new ConcurrentModificationException(); } }
ArrayList使用Lambda的foreach函数方式
先说一下Lambda的实现原理
- 在类编译时,动态生成会生成一个私有静态方法+一个内部类;
- 在内部类中实现了函数式接口,在实现接口的方法中,会调用编译器生成的静态方法,这个静态方法与遍历对象的方法一致;
- 在使用lambda表达式的地方,通过传递内部类实例,来调用函数式接口方法。
参考地址:https://blog.csdn.net/jiankunking/article/details/79825928
从以上可以理解到,其实Lambda的函数式是根据集合方法实现个壳,内部还是调用了集合foreach方法进行遍历的,类似动态代理行为。
所以其原理和遍历策略是与集合ArrayList的内部foreach方法一致。
总结
1、以上只是针对ArrayList进行了深入分析,每个集合都有自己相对应的foreach方法和Iterator迭代器的实现,所以是否遍历有问题,遍历时的集合操作是否有问题,需要根据不同的集合类型进行不同的判断,而不是一味的理解操作的时候为foreach方法就是有问题,迭代器Iterator就是不会出现问题,传统for循环不好啥的,一定得有一股劲深入研究,才会拨开云雾。
2、还有好多栗子:如CopyOnWriteArrayList与ArrayList又有所不同,HashMap也不一样,每个都有自己的个性,可以查看源码,
3、这些都是对Collection或者Iterator进行相应的实现,其中差不多都是跟modCount有着千丝万缕的关系,又有着所谓的fail-fast机制。

