

代码随想录day 56 || 最短路径算法相关
一、连通所有的节点所需的最短路径问题
1.1、Prim 算法
应用场景是主要是找到一个无向连通图的最小生成树,即连接所有节点且权重总和最小的树
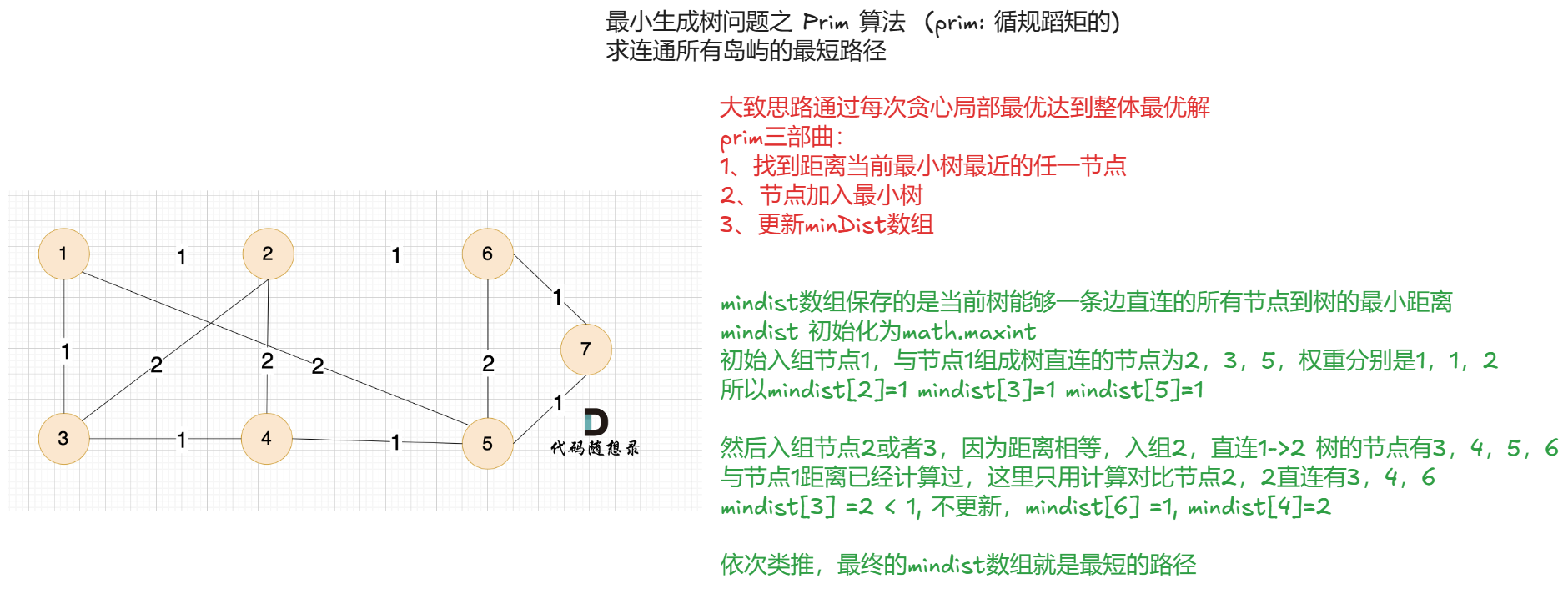
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
// prim三部曲
// 1, 找到距离当前最小树最近节点
// 2,节点入树
// 3,更新mindist
// 更新树
func updateMinDist(edges [][]int, node int) {
for _, edge := range edges {
if edge[0] == node && edge[2] < minDist[edge[1]]{ // 直连当前节点,并且距离更短
minDist[edge[1]] = edge[2]
}
}
}
// 找到不在树中的最近节点
func GetMinNode() int {
var minVal int = math.MaxInt
var minNode int = -1 // 特殊标记一下,如果没有找到最近节点,说明树已经遍历完成
for i, v := range minDist {
if !used[i] && v < minVal {
minVal = v
minNode = i
}
}
return minNode
}
1.2、Kruskal 算法
应用场景是主要是找到一个无向连通图的最小生成树,即连接所有节点且权重总和最小的树,和一个算法场景一致,事项思路不同,一个是节点,一个是边
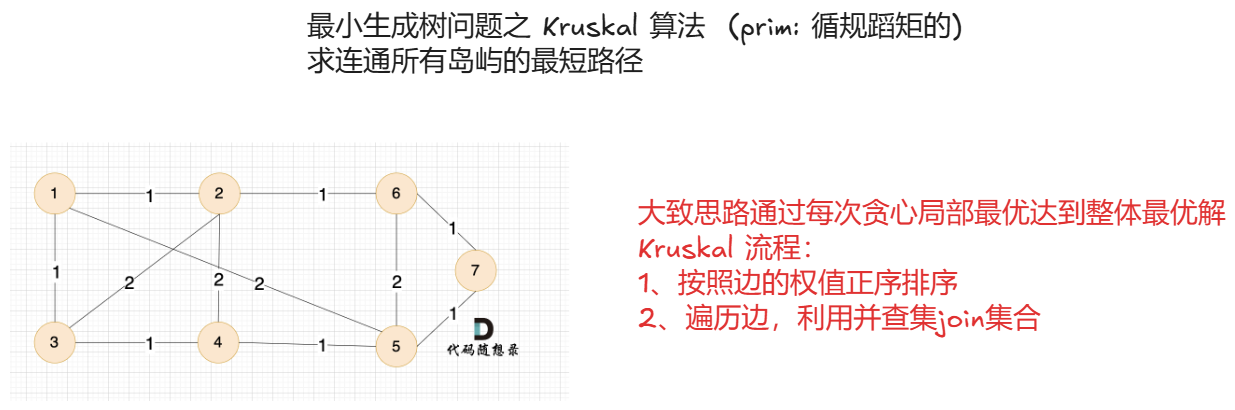
二、拓扑排序(判断有向图是否有环,以及将有向无环图转换成线性的顺序问题)
2.1、拓扑排序之bfs
拓扑排序是图论中用来判断有向无环图的方法,目的是将有向无环图转换成线性的排序
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
package main
import (
"container/list"
)
var queue *list.List
var relate map[int][]int // 存放路径依赖关系,key是节点,value是依赖的节点
var inDegree []int // 存放每个节点的入度
var res []int // 存放拓扑排序的结果
func main() {
// 拓扑排序
var n = 5
var edges = [][]int{{0, 1}, {0, 2}, {1, 3}, {2, 4}}
// 1. 初始化
queue = list.New()
relate = make(map[int][]int)
inDegree = make([]int, n)
// 计算每个节点的入度以及依赖关系
for _, edge := range edges {
relate[edge[0]] = append(relate[edge[0]], edge[1])
inDegree[edge[1]]++
}
// 入度为0的节点加入队列
for i, v := range inDegree {
if v == 0 {
queue.PushBack(i)
}
}
// 2. bfs
bfs()
// 如果res的长度小于n,说明有环,反之就是正常的拓扑排序
}
func bfs() {
for queue.Len() > 0 {
node := queue.Remove(queue.Front()).(int)
res = append(res, node)
// 处理节点, 删除节点相当于将依赖的节点的入度-1
for _, v := range relate[node] {
inDegree[v]--
if inDegree[v] == 0 {
queue.PushBack(v)
}
}
}
}
2.2、拓扑排序之dfs
没讲不会
三、有向图中任意两点之前的最短路径问题
3.1、dijkstra 算法
在有权图(权值非负数)中求从起点到其他节点的最短路径算法
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
package main
import (
"fmt"
"math"
)
var visit = make(map[int]bool) // 访问标记
var minDist = make(map[int]int) // 起点到每个节点的最短距离
func main() {
// dijkstra 算法
var n = 7
var edges = [][]int{{1, 2, 1}, {1, 3, 4}, {2, 3, 2}, {2, 4, 5}, {3, 4, 2}, {4, 5, 3}, {2, 6, 4}, {5, 7, 4}, {6, 7, 9}}
// 1. 初始化
for i := 0; i < n; i++ {
minDist[i] = math.MaxInt
}
// 2. 从起点开始
var start, end = 1, 7 // 任意起点终点都可以的
minDist[start] = 0
for i := 0; i < n; i++ {
dijkstra(edges, findMinDist())
}
fmt.Println(minDist)
fmt.Println(minDist[end])
}
func dijkstra(edges [][]int, cur int) {
// 1, 找到未访问节点中距离最小的节点
// 2,更新与该节点相邻的节点到源点(start)的最短距离
// 3,标记该节点为已访问
visit[cur] = true
for _, edge := range edges {
if edge[0] == cur {
minDist[edge[1]] = minDist[cur] + edge[2]
}
}
}
func findMinDist() int {
min := math.MaxInt
var minIndex int
for i := 0; i < len(minDist); i++ {
if !visit[i] && minDist[i] < min {
min = minDist[i]
minIndex = i
}
}
return minIndex
}
3.2、dijkstra 算法,堆优化
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
// 应用场景是结合邻接表使用,特点就是邻接表特点,对稀疏矩阵有空间和时间优化
// 原理还是dijkstra三部曲
// 1,找到未遍历的到源点最近节点作为起始位置 (初始化起点作为源点,然后起点的临界数组<存放的指向节点以及权重>入最小堆,堆顶就是最小权值)
// 2,标记遍历过 (visit[cur] = true)
// 3,更新mindist数组 (遍历cur对应的邻接表,如果没标记访问过,mindist[x] = mindist[cur] + val<权值>,然后x入最小堆)
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
// 小顶堆
type IntHeap []int
func (h IntHeap) Len() int { return len(h) }
func (h IntHeap) Less(i, j int) bool { return h[i] < h[j] }
func (h IntHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *IntHeap) Push(x any) {
*h = append(*h, x.(int))
}
func (h *IntHeap) Pop() any {
x := (*h)[len(*h)-1]
*h = (*h)[:len(*h)-1]
return x
}
func main() {
h := &IntHeap{2, 1, 5}
heap.Init(h) // 初始化堆
heap.Push(h, 3) // 插入元素
heap.Pop(h) // 移除堆顶
heap.Remove(h, 1) // 移除索引为1的节点
// 修改堆中某个元素的值
(*h)[2] = 0
heap.Fix(h, 2) // 调整堆以保持堆的性质
}
3.3、Bellman_ford 算法
Bellman_ford算法的核心思想是 对所有边进行松弛n-1次操作(n为节点数量),从而求得目标最短路,应用场景是带有负权值的最短路径
负权回路是指一系列道路的总权值为负,这样的回路使得通过反复经过回路中的道路,理论上可以无限地减少总成本或无限地增加总收益。
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
// 思路
进行n-1次松弛,操作,第k次松弛操作会记录通过k条边相连的节点之间的最短路径,并且多次松弛,不会对之前计算k-1条边相连的节点的mindist结果产生影响
for i->n-1{
if edge[0] != max {
mindist[edge[1]] = min(mindist[edge[1]], edge[2]+mindist[edge[0]])
}
}

copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
package main
import (
"fmt"
"math"
)
var mindist = make(map[int]int)
func main() {
var n = 6
var edges = [][]int{{5, 6, -2}, {1, 2, 1}, {5, 3, 1}, {2, 5, 2}, {2, 4, -3}, {4, 6, 4}, {1, 3, 5}}
for i := 1; i <= 6; i++ {
mindist[i] = math.MaxInt
}
mindist[1] = 0
for i := 0; i < n-1; i++ {
bellman_ford(edges)
fmt.Printf("Iteration %d: %v\n", i+1, mindist)
}
}
func bellman_ford(edges [][]int) {
for _, edge := range edges {
if mindist[edge[0]] != math.MaxInt {
mindist[edge[1]] = min(mindist[edge[1]], mindist[edge[0]]+edge[2])
}
}
}
// Iteration 1: map[1:0 2:1 3:5 4:-2 5:3 6:2]
// Iteration 2: map[1:0 2:1 3:4 4:-2 5:3 6:1]
// Iteration 3: map[1:0 2:1 3:4 4:-2 5:3 6:1]
// Iteration 4: map[1:0 2:1 3:4 4:-2 5:3 6:1]
// Iteration 5: map[1:0 2:1 3:4 4:-2 5:3 6:1]
3.4、Bellman_ford 算法之队列优化(SPFA)
copy
- 1
- 2
- 3
- 4
- 5
上面提到过Bellman_Ford 会在多次松弛操作中重复计算k-1条边相连的节点的最小路径,除此之外,对于第k次松弛,如果边是k+i条相连的两个节点的运算是无效的,单纯是为了之后的动态规划min(x,x)服务
所以在上面的基础上,提出了队列优化的思路,通过队列依次入队一条边到n-1条边相连的节点,并记录状态(单向图才能记录),实现提高计算效率
极端境况下,节点会入队n-1次

copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
package main
import (
"container/list"
"fmt"
"math"
)
var mindist = make(map[int]int)
var queue *list.List
func main() {
var edges = [][]int{{5, 6, -2}, {1, 2, 1}, {5, 3, 1}, {2, 5, 2}, {2, 4, -3}, {4, 6, 4}, {1, 3, 5}}
for i := 1; i <= 6; i++ {
mindist[i] = math.MaxInt
}
queue = list.New()
mindist[1] = 0
queue.PushBack(1)
bellman_ford_queue(edges)
fmt.Println(mindist)
}
func bellman_ford_queue(edges [][]int) {
for queue.Len() > 0 {
node := queue.Remove(queue.Front()).(int)
for _, edge := range edges {
if edge[0] == node {
mindist[edge[1]] = min(mindist[edge[1]], edge[2]+mindist[edge[0]])
queue.PushBack(edge[1])
}
}
}
}
3.5、Bellman_ford之判断负权回路

copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
对于无负权回路情况
上面算法以及提到过,对于朴素bf算法,只需要松弛n-1次,之后的计算结果会一致
对于队列优化版bf算法,节点最多入队n-1次
所以,判断负权回路的思路就是多松弛依次判断是否有变化,以及判断节点入队是否超过了n-1次
3.6、Bellman_ford之单源有限最短路
解决有负权回路,以及限制最多松弛k次的问题
copy
- 1
- 2
// 解决思路就是通过拷贝上一次松弛的结果,并且对比min(copy_mindist[x], mindist[y] + z) 来对mindist数组进行更新
// 以避免负权回路松弛过程对计算过的变量不断修改
3.7、Floyd 算法
应用场景是多源最短路径,可以计算多个始末点之间的最短距离,并且对权值正负没有要求
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
func main() {
var n = 7
var edges = [][]int{{2, 3, 4}, {3, 6, 6}, {4, 7, 8}}
// dp五部曲
// 1, 确定dp数组以及下标的含义 dp[i][j][k] 表示从i到j的路径中,经过[1: k]节点的最短路径
// 2, 确定递推公式 dp[i][j][k] = min(dp[i][j][k-1] + , dp[i][k][k-1] + dp[k][j][k-1]) // 从i到j的路径,使用节点k, 和不使用节点k之间的最小值
// 3, 初始化 dp[i][j][0] = 0 // 不经过任何节点的路径 dp[i][j][m] = max // 无穷大
// 4, 确定遍历顺序 k, i , j
// 5, 打印
var dp = make([][][]int, n+1)
for i := 0; i <= n; i++ {
dp[i] = make([][]int, n+1)
for j := 0; j <= n; j++ {
dp[i][j] = make([]int, n+1)
dp[i][j][0] = 0 // 初始化
for k := 1; k <= n; k++ {
dp[i][j][k] = math.MaxInt // 初始化
}
}
}
// 赋值
for _, edge := range edges {
dp[edge[0]][edge[1]][0] = edge[2]
dp[edge[1]][edge[0]][0] = edge[2]
}
for k := 1; k <= n; k++ {
for i := 0; i <= n; i++ {
for j := 0; j <= n; j++ {
dp[i][j][k] = min(dp[i][j][k-1], dp[i][k][k-1]+dp[k][j][k-1])
}
}
}
fmt.Println(dp)
}
3.8、A* 算法
Astar 是一种 广搜的改良版, 但是Astar算法计算出来的结果并不一定是最优解,可能是次优解!!!!,最大优点是省时
2596 检查骑士巡视方案(广搜版本)
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
var queue *list.List
var visited [][]bool
var curIdx int
var dirPath = [][]int{{1, -2}, {1, 2}, {2, -1}, {2, 1}, {-1, -2}, {-1, 2}, {-2, -1}, {-2, 1}} // 马走日八个方向
func checkValidGrid(grid [][]int) bool {
// 简单思路,广搜,每一个出队,判断入队节点是否有下一个坐标
curIdx = 0
visited = make([][]bool, len(grid))
for i, _ := range visited {
visited[i] = make([]bool, len(grid[0]))
}
queue = list.New()
queue.PushBack([]int{0, 0}) // 题设从左上角开始
visited[0][0] = true
return bfs(grid)
}
func bfs(grid [][]int ) bool {
for queue.Len() > 0 {
node := queue.Remove(queue.Front()).([]int)
flag := false // 是否找到下一个节点
for _, dir := range dirPath {
next_x, next_y := node[0] + dir[0], node[1] + dir[1]
if next_x >= 0 && next_x < len(grid) && next_y >= 0 && next_y < len(grid[0]) && !visited[next_x][next_y] {
// 未访问过 并且 没有超出边界
//fmt.Println(next_x, next_y, grid[next_x][next_y], curIdx + 1)
if grid[next_x][next_y] == curIdx + 1 {
visited[next_x][next_y] = true
queue.PushBack([]int{next_x, next_y})
curIdx++
flag = true
if curIdx == len(grid) * len(grid[0]) - 1 { // 到最后一个节点了,直接退出
return true
}
break
}
}
}
if !flag {
return false
}
}
return true
}
copy
- 1
- 2
// 广搜可以解决二维矩阵中两个点直接的最短路径,并可以通过dirpath数组判断是否可达
// 但是广搜最大的缺点是什么呢?广搜他的遍历过程类似一圈一圈的遍历,到达目标点可能需要的时间很长,无用的遍历过程太多
A* 常用距离函数及其优缺点
A(A-star)算法是一种用于路径搜索和图搜索的启发式算法,它在许多应用中非常有效,如游戏中的路径规划、机器人导航等。A算法通过评估启发式函数 ( f(n) = g(n) + h(n) ) 来选择最优路径,其中:
- ( g(n) ) 是从起点到节点 ( n ) 的实际代价。
- ( h(n) ) 是从节点 ( n ) 到目标节点的估计代价(启发式函数)。

选择合适的启发式函数 ( h(n) ) 对于算法的效率和效果至关重要。以下是几种常用的启发式距离函数及其优缺点:
1. 曼哈顿距离(Manhattan Distance)
曼哈顿距离适用于网格地图(如二维平面上的网格),其中只能沿水平或垂直方向移动。
公式:
h(n) = |x1 - x2| + |y1 - y2|
优点:
- 计算简单,效率高。
- 在只能沿水平或垂直方向移动的网格中,曼哈顿距离是一个良好的启发式函数。
缺点:
- 当允许对角线移动时,曼哈顿距离可能低估实际距离,导致次优路径。
2. 欧几里得距离(Euclidean Distance)
欧几里得距离适用于允许沿任意方向移动的连续空间。
公式:
h(n) = sqrt((x1 - x2)^2 + (y1 - y2)^2)
优点:
- 在允许对角线移动的情况下,欧几里得距离提供了更准确的估计。
缺点:
- 计算平方根操作相对较慢,可能影响性能。
3. 切比雪夫距离(Chebyshev Distance)
切比雪夫距离适用于八方向(包括对角线)移动。
公式:
h(n) = max(|x1 - x2|, |y1 - y2|)
优点:
- 在允许对角线移动的网格中,切比雪夫距离是一个良好的启发式函数。
- 计算简单,效率高。
缺点:
- 在不允许对角线移动的情况下,切比雪夫距离可能高估实际距离。
4. 对角线距离(Diagonal Distance)
对角线距离是曼哈顿距离和切比雪夫距离的结合,适用于允许对角线移动的网格。
公式:
h(n) = D * (|x1 - x2| + |y1 - y2|) + (D2 - 2 * D) * min(|x1 - x2|, |y1 - y2|)
其中,( D ) 是水平或垂直移动的代价,( D2 ) 是对角线移动的代价。
优点:
- 提供了更准确的估计,适用于允许对角线移动的网格。
缺点:
- 计算稍微复杂一些,但仍然高效。
5. 平面图中的直线距离(Straight-Line Distance)
适用于平面图中的任意移动。
公式:
h(n) = sqrt((x1 - x2)^2 + (y1 - y2)^2)
优点:
- 提供了准确的估计,适用于任意移动的场景。
缺点:
- 计算平方根操作相对较慢,可能影响性能。
总结
选择启发式函数时需要考虑具体的应用场景和移动规则:
- 如果只能沿水平或垂直方向移动,曼哈顿距离是一个良好的选择。
- 如果允许任意方向移动,欧几里得距离或直线距离是更好的选择。
- 如果允许对角线移动,切比雪夫距离或对角线距离是更好的选择。
在实际应用中,启发式函数的选择需要权衡计算复杂度和估计准确性,以找到最适合具体场景的启发式函数。
本文作者:周公瑾55
本文链接:https://www.cnblogs.com/zhougongjin55/p/18406084
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。
本文作者:周公瑾55
本文链接:https://www.cnblogs.com/zhougongjin55/p/18406084
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步