


RabbitMQ集群(普通队列)原理详解
RabbitMQ是基于Erlang编写,Erlang语言天生具备分布式特性(通过同步Erlang集群各节点的magic cookie来实现)。因此,RabbitMQ天然支持Clustering。这使得RabbitMQ本身不需要像ActiveMQ、Kafka那样通过ZooKeeper分别来实现HA高可用方案和保存集群的元数据。集群是保证可靠性的一种方式,同时可以通过水平扩展以达到增加消息吞吐量能力的目的。
【普通模式】
普通集群模式就是将多台Rabbit MQ服务器连接组成一个集群,在连接过程中需要正确的Erlang Cookie和节点名称才能保证机器之间相互进行连接访问,并且集群需要要局域网内进行部署。
一、RabbitMQ集群元数据的同步
Rabbit MQ的集群不是每个节点都有所有队列的完全拷贝。交换机的元数据信息在所有节点上都是一致的,但是存放消息的队列的完整信息都只存在它所创建的节点上,所有其他节点只知道队列的元数据和指向该队列存在的那个节点的指针,元数据信息包括以下内容:
RabbitMQ集群会始终同步四种类型的内部元数据:
1.队列元数据:队列名称、属性;
2.交换器元数据:交换器名称、类型和属性;
3.绑定元数据:交换器与队列绑定关系,如binding_key;
4.vhost元数据:虚拟主机内部配置和属性;
因此,当用户访问其中任何一个RabbitMQ节点时,通过rabbitmqctl查询到的queue/user/exchange/ vhost等信息都是相同的。
注意:队列只同步元数据信息,不会同步存储的消息,消息只会存在于创建该队列的节点上,其它节点只知道这个队列的元数据信息和一个指向队列的owner node的地址。
二、为何RabbitMQ集群仅采用元数据同步的方式
RabbitMQ这么设计主要是基于集群本身的性能和存储空间上来考虑。
第一,存储空间,如果每个集群节点都拥有所有Queue的完全数据拷贝,那么每个节点的存储空间会非常大,集群的消息积压能力会非常弱(无法通过集群节点的扩容提高消息积压能力);
第二,性能,消息的发布者需要将消息复制到每一个集群节点,对于持久化消息,网络和磁盘同步复制的开销都会明显增加。
三、集群节点间的消息流转
以三个节点(node1、node2、node3)的集群为例来进行说明。消息实体是存在于队列之中的,而节点之间只有相同的元数据信息,假设消息存在于node1节点的A队列上,当消费者从node2节点上的B队列消费时,这时RabbitMQ会临时在node1和node2节点进行消息传输,把A队列上的消息实体传到B队列上,然后发送给消费者。
这个过程其实会对node1节点产生性能瓶颈,因为无论consumer连node1或node2,都会从node1拉取数据。针对这种情况,有一个中庸的做法就是将consumer尽量连接每一个节点。
四、集群节点类型
集群节点类型分为以下两类:
磁盘节点
内存节点
磁盘节点的数据信息是存储在磁盘上的,内存节点的信息是存储在内存上的,因此内存节点的性能要高于磁盘节点。
注意: Rabbit MQ要求集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入和离开集群时,必须通知磁盘节点。
当唯一的磁盘节点崩溃时,
集群可以继续发送或者接收消息, 但是不能执行创建队列、交换器、绑定关系、用户,以及更改权限、添加或删除集群节点的操作了。 也就是说,如果集群中唯一的磁盘节点崩溃,集群仍然可以保持运行,但是直到将该节点恢复到集群前,你无法更改任何东西。所以在建立集群的时候应该保证有两个或者多个磁盘节点的存在。
五、集群节点异常处理
当集群节点崩溃时,该节点的队列进程和关联的绑定都会消失。附加在那些队列上的消费者 会丢失其所订阅的信息 井且任何匹配该队列绑定信息的新消息也都会消失。那么面临这种情况应该如何处理呢:
持久化处理,当该节点重启的时候可以再次获取到该消息。
使用镜像模式,就是指创建一个镜像节点,镜像节点保存有崩溃节点的所有信息,那么该节点崩溃时,镜像节点可以接替它继续工作,直至崩溃节点重启。
六、RabbitMQ集群的基本原理
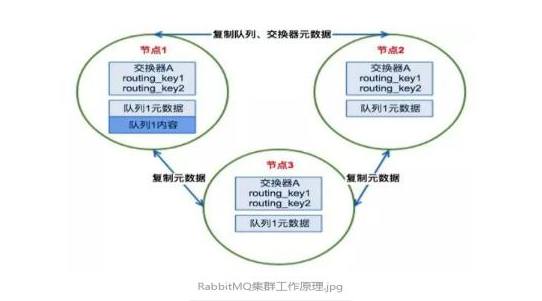
场景1、客户端直接连接队列所在节点
如果有一个消息生产者或者消息消费者通过amqp-client的客户端连接至节点1进行消息的发布或者订阅,那么此时的集群中的消息收发只与节点1相关。
场景2、客户端连接的是非队列数据所在节点
如果消息生产者所连接的是节点2或者节点3,此时队列1的完整数据不在该两个节点上,那么在发送消息过程中这两个节点主要起了一个路由转发作用,根据这两个节点上的元数据(也就是上文提到的:指向queue的owner node的指针)转发至节点1上,最终发送的消息还是会存储至节点1的队列1上。
同样,如果消息消费者所连接的节点2或者节点3,那这两个节点也会作为路由节点起到转发作用,将会从节点1的队列1中拉取消息进行消费。
由于节点之间存在路由转发的情况,所以对于RabbitMQ集群最好是在一个局域网。
七、普通集群模式总结:
多机集群提高了系统的吞吐量和可靠性。但是并没有做到高可用性,因为当磁盘节点崩溃的话,其它节点不能进行创建队列、创建交换器等,可以这样说吧,其它内存节点就是为磁盘节点服务的,下面介绍的镜像模式部署解决了这个缺点,实现了集群的高可用性。
1、在哪台服务器创建的exchange,queue,那哪台服务器就存储的就是原始数据,其他服务器存储的只是这台服务器的引用地址;
2、不管在哪个服务器往queue添加消息,只看queue是在哪台服务器创建的,数据本身就会存入对应的服务器上,而不是添加时连接的服务器;同理,消费者在消费时不管从哪台服务器读取,最终都是从数据本身的服务器上读取
例:server1:创建exchange,queue; server2:给queue添加消息;添加后消息会存入server1而不是存入server2,server2还是只保存引用;消费消息连接server2,会从server1把消息拿到server2,在传输给消费者
3、如果server1宕机了,该机器上的存储的消息都将不可读取,如果有做持久化,等服务器重启后会自动恢复;
4、普通模式不是高可用模式,针对不是那么强一致性的业务可用,相对来说吞吐量高一些;
5、使用普通模式,不要把exchange,queue创建在同一台服务器上,要均匀分布,否则某一台挂了,会导致整个集群都宕掉;或者使用代理和负载均衡处理;

