


第五章、redis集群模式详解
哨兵机制虽然解决了主从在主节点挂掉后无法自动切换问题,但是仍然存在主节点单点压力。存储能力受单机限制,以及无法实现写操作的负载均衡。
1、概述
集群,即Redis Cluster,是Redis 3.0开始引入的分布式存储方案。
集群由多个节点(Node)组成,Redis的数据分布在这些节点中。集群中的节点分为主节点和从节点:只有主节点负责读写请求和集群信息的维护;从节点只进行主节点数据和状态信息的复制。
集群的作用,可以归纳为两点:
1、数据分区:数据分区(或称数据分片)是集群最核心的功能。
集群将数据分散到多个节点,一方面突破了Redis单机内存大小的限制,存储容量大大增加;另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
Redis单机内存大小受限问题,在介绍持久化和主从复制时都有提及;例如,如果单机内存太大,bgsave和bgrewriteaof的fork操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出……。
2、高可用:集群支持主从复制和主节点的自动故障转移(与哨兵类似);当任一节点发生故障时,集群仍然可以对外提供服务。
2、集群的基本原理
1. 数据分区方案
数据分区有顺序分区、哈希分区等,其中哈希分区由于其天然的随机性,使用广泛;集群的分区方案便是哈希分区的一种。
哈希分区的基本思路是:对数据的特征值(如key)进行哈希,然后根据哈希值决定数据落在哪个节点。常见的哈希分区包括:哈希取余分区、一致性哈希分区、带虚拟节点的一致性哈希分区等。
衡量数据分区方法好坏的标准有很多,其中比较重要的两个因素是(1)数据分布是否均匀(2)增加或删减节点对数据分布的影响。由于哈希的随机性,哈希分区基本可以保证数据分布均匀;因此在比较哈希分区方案时,重点要看增减节点对数据分布的影响。
(1)哈希取余分区
哈希取余分区思路非常简单:计算key的hash值,然后对节点数量进行取余,从而决定数据映射到哪个节点上。该方案最大的问题是,当新增或删减节点时,节点数量发生变化,系统中所有的数据都需要重新计算映射关系,引发大规模数据迁移。
(2)一致性哈希分区
一致性哈希算法将整个哈希值空间组织成一个虚拟的圆环,如下图所示,范围为0-2^32-1;对于每个数据,根据key计算hash值,确定数据在环上的位置,然后从此位置沿环顺时针行走,找到的第一台服务器就是其应该映射到的服务器。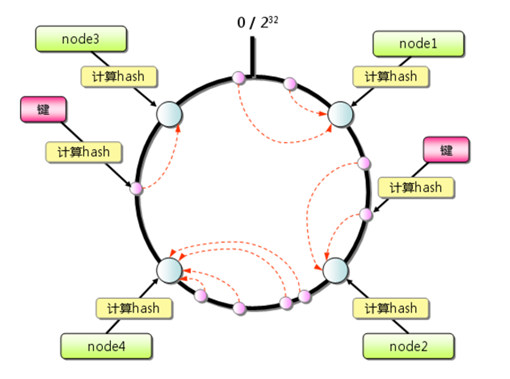
与哈希取余分区相比,一致性哈希分区将增减节点的影响限制在相邻节点。以上图为例,如果在node1和node2之间增加node5,则只有node2中的一部分数据会迁移到node5;如果去掉node2,则原node2中的数据只会迁移到node4中,只有node4会受影响。
一致性哈希分区的主要问题在于,当节点数量较少时,增加或删减节点,对单个节点的影响可能很大,造成数据的严重不平衡。还是以上图为例,如果去掉node2,node4中的数据由总数据的1/4左右变为1/2左右,与其他节点相比负载过高。
(3)带虚拟节点的一致性哈希分区
该方案在一致性哈希分区的基础上,引入了虚拟节点的概念。Redis集群使用的便是该方案,其中的虚拟节点称为槽(slot)。槽是介于数据和实际节点之间的虚拟概念;每个实际节点包含一定数量的槽,每个槽包含哈希值在一定范围内的数据。引入槽以后,数据的映射关系由数据hash->实际节点,变成了数据hash->槽->实际节点。
在使用了槽的一致性哈希分区中,槽是数据管理和迁移的基本单位。槽解耦了数据和实际节点之间的关系,增加或删除节点对系统的影响很小。仍以上图为例,系统中有4个实际节点,假设为其分配16个槽(0-15); 槽0-3位于node1,4-7位于node2,以此类推。如果此时删除node2,只需要将槽4-7重新分配即可,例如槽4-5分配给node1,槽6分配给node3,槽7分配给node4;可以看出删除node2后,数据在其他节点的分布仍然较为均衡。
槽的数量一般远小于2^32,远大于实际节点的数量;在Redis集群中,槽的数量为16384。
下面这张图很好的总结了Redis集群将数据映射到实际节点的过程:
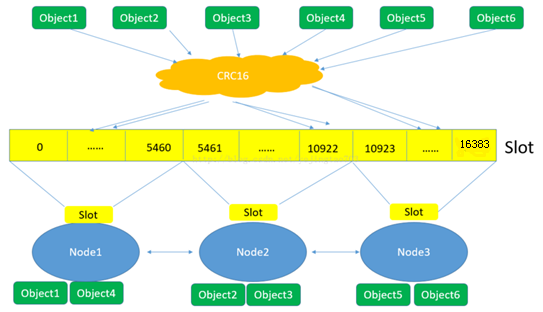
(1)Redis对数据的特征值(一般是key)计算哈希值,使用的算法是CRC16。
(2)根据哈希值,计算数据属于哪个槽。
(3)根据槽与节点的映射关系,计算数据属于哪个节点。
2. 节点通信机制
集群要作为一个整体工作,离不开节点之间的通信。
两个端口
在哨兵系统中,节点分为数据节点和哨兵节点:前者存储数据,后者实现额外的控制功能。在集群中,没有数据节点与非数据节点之分:所有的节点都存储数据,也都参与集群状态的维护。为此,集群中的每个节点,都提供了两个TCP端口:
- 普通端口:即我们在前面指定的端口(7000等)。普通端口主要用于为客户端提供服务(与单机节点类似);但在节点间数据迁移时也会使用。
- 集群端口:端口号是普通端口+10000(10000是固定值,无法改变),如7000节点的集群端口为17000。集群端口只用于节点之间的通信,如搭建集群、增减节点、故障转移等操作时节点间的通信;不要使用客户端连接集群接口。为了保证集群可以正常工作,在配置防火墙时,要同时开启普通端口和集群端口。
Gossip协议
节点间通信,按照通信协议可以分为几种类型:单对单、广播、Gossip协议等。重点是广播和Gossip的对比。
广播是指向集群内所有节点发送消息;优点是集群的收敛速度快(集群收敛是指集群内所有节点获得的集群信息是一致的),缺点是每条消息都要发送给所有节点,CPU、带宽等消耗较大。
Gossip协议的特点是:在节点数量有限的网络中,每个节点都“随机”的与部分节点通信(并不是真正的随机,而是根据特定的规则选择通信的节点),经过一番杂乱无章的通信,每个节点的状态很快会达到一致。Gossip协议的优点有负载(比广播)低、去中心化、容错性高(因为通信有冗余)等;缺点主要是集群的收敛速度慢。
消息类型
集群中的节点采用固定频率(每秒10次)的定时任务进行通信相关的工作:判断是否需要发送消息及消息类型、确定接收节点、发送消息等。如果集群状态发生了变化,如增减节点、槽状态变更,通过节点间的通信,所有节点会很快得知整个集群的状态,使集群收敛。
节点间发送的消息主要分为5种:meet消息、ping消息、pong消息、fail消息、publish消息。不同的消息类型,通信协议、发送的频率和时机、接收节点的选择等是不同的。
- MEET消息:在节点握手阶段,当节点收到客户端的CLUSTER MEET命令时,会向新加入的节点发送MEET消息,请求新节点加入到当前集群;新节点收到MEET消息后会回复一个PONG消息。
- PING消息:集群里每个节点每秒钟会选择部分节点发送PING消息,接收者收到消息后会回复一个PONG消息。PING消息的内容是自身节点和部分其他节点的状态信息;作用是彼此交换信息,以及检测节点是否在线。PING消息使用Gossip协议发送,接收节点的选择兼顾了收敛速度和带宽成本,具体规则如下:(1)随机找5个节点,在其中选择最久没有通信的1个节点(2)扫描节点列表,选择最近一次收到PONG消息时间大于cluster_node_timeout/2的所有节点,防止这些节点长时间未更新。
- PONG消息:PONG消息封装了自身状态数据。可以分为两种:第一种是在接到MEET/PING消息后回复的PONG消息;第二种是指节点向集群广播PONG消息,这样其他节点可以获知该节点的最新信息,例如故障恢复后新的主节点会广播PONG消息。
- FAIL消息:当一个主节点判断另一个主节点进入FAIL状态时,会向集群广播这一FAIL消息;接收节点会将这一FAIL消息保存起来,便于后续的判断。
- PUBLISH消息:节点收到PUBLISH命令后,会先执行该命令,然后向集群广播这一消息,接收节点也会执行该PUBLISH命令。
3. 数据结构
节点需要专门的数据结构来存储集群的状态。所谓集群的状态,是一个比较大的概念,包括:集群是否处于上线状态、集群中有哪些节点、节点是否可达、节点的主从状态、槽的分布……
节点为了存储集群状态而提供的数据结构中,最关键的是clusterNode和clusterState结构:前者记录了一个节点的状态,后者记录了集群作为一个整体的状态。
clusterNode
clusterNode结构保存了一个节点的当前状态,包括创建时间、节点id、ip和端口号等。每个节点都会用一个clusterNode结构记录自己的状态,并为集群内所有其他节点都创建一个clusterNode结构来记录节点状态。
下面列举了clusterNode的部分字段,并说明了字段的含义和作用:
|
1 |
|
除了上述字段,clusterNode还包含节点连接、主从复制、故障发现和转移需要的信息等。
clusterState
clusterState结构保存了在当前节点视角下,集群所处的状态。主要字段包括:
|
1 |
|
除此之外,clusterState还包括故障转移、槽迁移等需要的信息。
4. 集群命令的实现
这一部分将以cluster meet(节点握手)、cluster addslots(槽分配)为例,说明节点是如何利用上述数据结构和通信机制实现集群命令的。
cluster meet
假设要向A节点发送cluster meet命令,将B节点加入到A所在的集群,则A节点收到命令后,执行的操作如下:
1) A为B创建一个clusterNode结构,并将其添加到clusterState的nodes字典中
2) A向B发送MEET消息
3) B收到MEET消息后,会为A创建一个clusterNode结构,并将其添加到clusterState的nodes字典中
4) B回复A一个PONG消息
5) A收到B的PONG消息后,便知道B已经成功接收自己的MEET消息
6) 然后,A向B返回一个PING消息
7) B收到A的PING消息后,便知道A已经成功接收自己的PONG消息,握手完成
8) 之后,A通过Gossip协议将B的信息广播给集群内其他节点,其他节点也会与B握手;一段时间后,集群收敛,B成为集群内的一个普通节点
通过上述过程可以发现,集群中两个节点的握手过程与TCP类似,都是三次握手:A向B发送MEET;B向A发送PONG;A向B发送PING。
cluster addslots
集群中槽的分配信息,存储在clusterNode的slots数组和clusterState的slots数组中,两个数组的结构前面已做介绍;二者的区别在于:前者存储的是该节点中分配了哪些槽,后者存储的是集群中所有槽分别分布在哪个节点。
cluster addslots命令接收一个槽或多个槽作为参数,例如在A节点上执行cluster addslots {0..10}命令,是将编号为0-10的槽分配给A节点,具体执行过程如下:
1) 遍历输入槽,检查它们是否都没有分配,如果有一个槽已分配,命令执行失败;方法是检查输入槽在clusterState.slots[]中对应的值是否为NULL。
2) 遍历输入槽,将其分配给节点A;方法是修改clusterNode.slots[]中对应的比特为1,以及clusterState.slots[]中对应的指针指向A节点
3) A节点执行完成后,通过节点通信机制通知其他节点,所有节点都会知道0-10的槽分配给了A节点

