
elasticsearch安装 centos6.5
版本: elasticsearch-6.4.3.tar.gz
jdk:1.7
注意:安装elasticsearch 不能用root用户安装
1.创建用户
groupadd esgroup
useradd esuser -g esgroup -p espawd
2.安装elasticsearch
用新建的用户安装(不可用root用户安装会报错)
tar -zxvf elasticsearch-6.4.3.tar.gz -C /home/hadoop/opt/
elasticsearch.yml 修改
vim elasticsearch-6.4.3/config/elasticsearch.yml
添加内容
network.host: 192.168.179.142
http.port: 9200
#因为Centos6不支持SecComp,而ES默认bootstrap.system_call_filter为true进行检测
elasticsearch.yml添加内容
bootstrap.memory_lock: false bootstrap.system_call_filter: false
用root用户修改/etc/sysctl.conf
vim /etc/sysctl.conf
在文件最后面添加内容:
vm.max_map_count=262144
保存退出后,使用sysctl -p 刷新生效
[root@localhost ~]# sysctl -p net.ipv4.ip_forward = 0 net.ipv4.conf.default.rp_filter = 1 net.ipv4.conf.default.accept_source_route = 0 kernel.sysrq = 0 kernel.core_uses_pid = 1 net.ipv4.tcp_syncookies = 1 kernel.msgmnb = 65536 kernel.msgmax = 65536 kernel.shmmax = 68719476736 kernel.shmall = 4294967296 vm.max_map_count = 262144 [root@localhost ~]#
root用户 修改文件/etc/security/limits.conf
添加如下内容:
* hard nofile 65536 * soft nofile 65536 * soft nproc 2048 * hard nproc 4096
启动elasticesearch 可能还会报如下错误
max number of threads [1024] for user [lish] likely too low, increase to at least [4096]
解决:切换到root用户,进入limits.d目录下修改配置文件。
vi /etc/security/limits.d/90-nproc.conf
修改如下内容:
* soft nproc 1024
#修改为
* soft nproc 4096
3.启动elasticsearch
完成上面配置修改后,切换到es 用户,目录切换到 elasticsearch 安装目录下执行
cd elasticsearch-6.4.3/bin/ ./elasticsearch
在浏览器输入<IP>:9200 验证是否启动成功,如果浏览器输出如下信息,代表安装启动成功
{
"name" : "node-1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "8okSnhNzRr6Xo233szO0Vg",
"version" : {
"number" : "6.3.2",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "053779d",
"build_date" : "2018-07-20T05:20:23.451332Z",
"build_snapshot" : false,
"lucene_version" : "7.3.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
4.安装过程中启动报错解决
异常信息1:expecting token of type [START_OBJECT] but found [VALUE_STRING]]; 错误原因:elasticsearch.yml 文件内部错误 解决办法:仔细检查yml文件中的配置项书写格式: (空格)name:(空格)value --------------------------------------------------------------------------------- 异常信息2:java.lang.UnsupportedOperationException: seccomp unavailable: CONFIG_SECCOMP not compiled into kernel, CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER are needed 错误原因:Centos6不支持SecComp,而ES默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动 解决办法:修改elasticsearch.yml 添加一下内容 : bootstrap.memory_lock: false bootstrap.system_call_filter: false --------------------------------------------------------------------------------- --------------------------------------------------------------------------------- 异常信息3:BindTransportException[Failed to bind to [9300-9400] 解决办法 打开配置文件elasticsearch.yml 将 network.host: 192.168.0.1 修改为本机IP 0.0.0.0 -------------------------------------------------------------------------------------------- 异常信息4:max number of threads [1024] for user [lish] likely too low, increase to at least [2048] 解决办法:切换到root用户,进入limits.d目录下修改配置文件。 vi /etc/security/limits.d/90-nproc.conf 修改如下内容: * soft nproc 1024 #修改为 * soft nproc 2048
5.安装kibana
tar -zxvf kibana-6.4.3-linux-x86_64.tar.gz -C /home/hadoop/opt/kibana/ vim kibana/kibana-6.4.3-linux-x86_64/config/kibana.yml
添加内容
server.port: 5601 server.host: "192.168.179.142" elasticsearch.url: "http://192.168.179.142:9200"
启动
./kibana
验证
http://192.168.179.142:5601/app/kibana
kibnan基本操作命令
创建索引库
#test1 索引库的名称 PUT /test1/ { "settings": { "index":{ #设置默认索引分片个数,默认为5片 "number_of_shards":5, #数据备份数,如果只有一台机器,设置为0 "number_of_replicas":0 } } } GET test1
查看索引
GET /test1/
--------------------------
GET /test1/_settings
添加文档
PUT /test1/user/1 { "name":"zhangsan", "age":32, "interests":["music","eat"] } #返回信息为以下 { "_index": "test1", "_type": "user", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 }
不指定id,用post请求
注:不指定id自动生成uuid值
POST /test1/user/ { "name":"lisi", "age":23, "interests":["forestry"] } #返回信息如下 { "_index": "test1", "_type": "user", "_id": "hSE-am4BgZQzNHtis52h", "_version": 1, "result": "created", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "_seq_no": 1, "_primary_term": 1 }
查看文档
GET /test1/user/1 GET /test1/user/hSE-am4BgZQzNHtis52h GET /test1/user/1?_source=age,name
#返回值如下
{
"_index": "test1",
"_type": "user",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"name": "zhangsan",
"age": 32
}
}
跟新文档
PUT /test1/user/1 { "name":"wangwu", "age":43, "interests":["music"] } #返回值如下 { "_index": "test1", "_type": "user", "_id": "1", "_version": 2, "result": "updated", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "_seq_no": 2, "_primary_term": 1 }
删除一个文档
DELETE /test1/user/1
删除一个索引库
DELETE /test1
springboot整合elasticsearch
application.properties
server.port=8080 spring.application.name=springboot-es #集群名称 spring.data.elasticsearch.cluster-name=moescluster #集群地址9300端口是集群节点之间通信的端口号 spring.data.elasticsearch.cluster-nodes=192.168.179.142:9300
dao接口
package com.zf.mo.springbootes.dao; import com.zf.mo.springbootes.entity.User; import org.springframework.data.repository.CrudRepository; public interface UserRepository extends CrudRepository <User,String>{ }
entity实体类
package com.zf.mo.springbootes.entity; import lombok.Data; import org.springframework.data.annotation.Id; import org.springframework.data.elasticsearch.annotations.Document; import java.io.Serializable; @Data @Document(indexName = "mo",type = "user") public class User implements Serializable { @Id private String id; private String name; private String password; private Integer age; private String gender; }
controller类
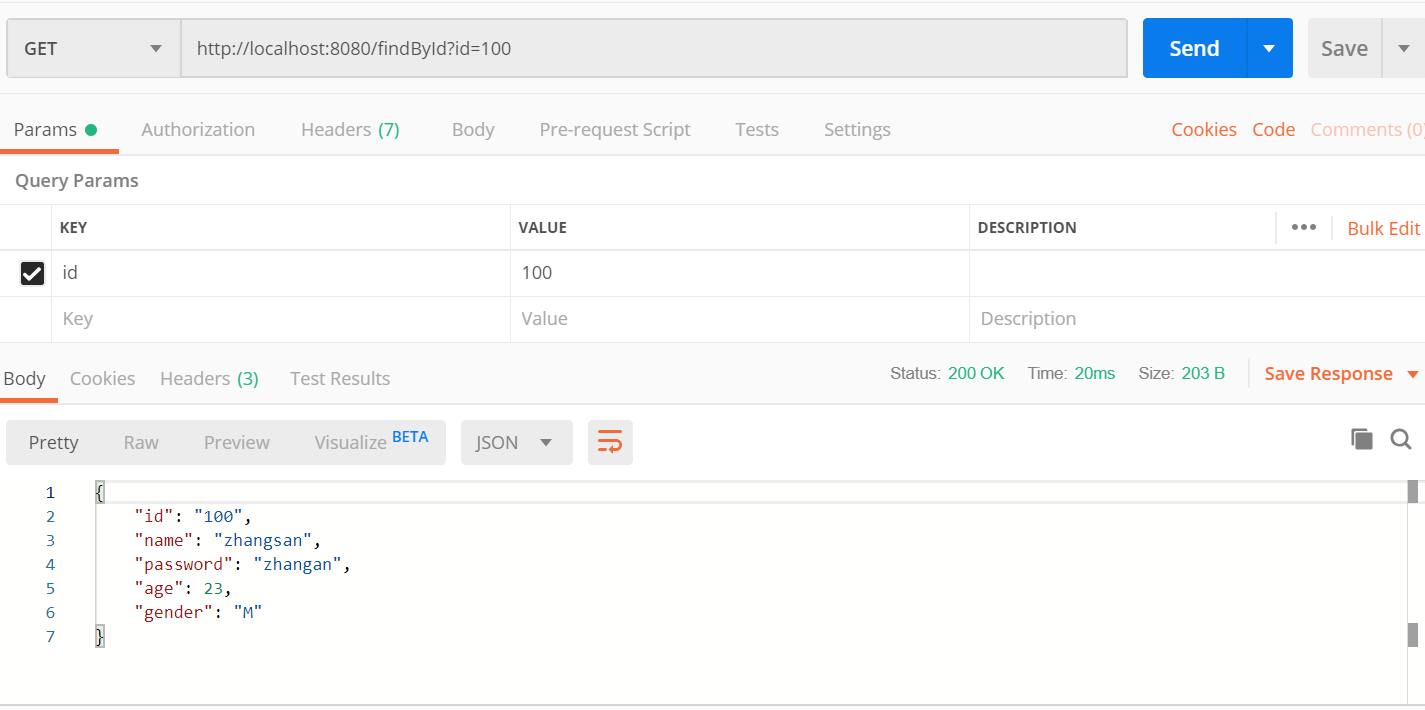
package com.zf.mo.springbootes.controller; import com.zf.mo.springbootes.dao.UserRepository; import com.zf.mo.springbootes.entity.User; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class ElasticsearchController { @Autowired private UserRepository userRepository; @PostMapping("/add") public User add(@RequestBody User user){ return userRepository.save(user); } @RequestMapping("/findById") public User findById(String id){ return userRepository.findById(id).get(); } }
启动类
package com.zf.mo.springbootes; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.data.elasticsearch.repository.config.EnableElasticsearchRepositories; @SpringBootApplication @EnableElasticsearchRepositories() public class SpringbootEsApplication { public static void main(String[] args) { SpringApplication.run(SpringbootEsApplication.class, args); } }
测试
添加数据
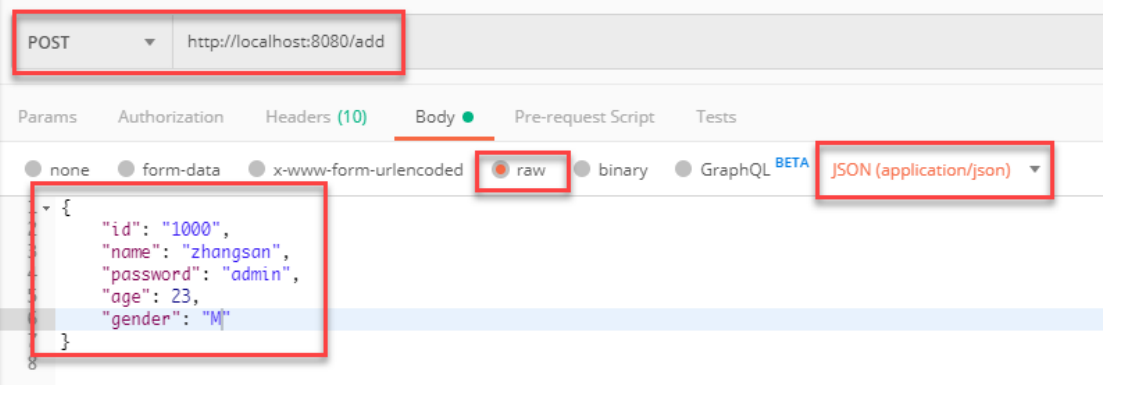
根据id查询文档
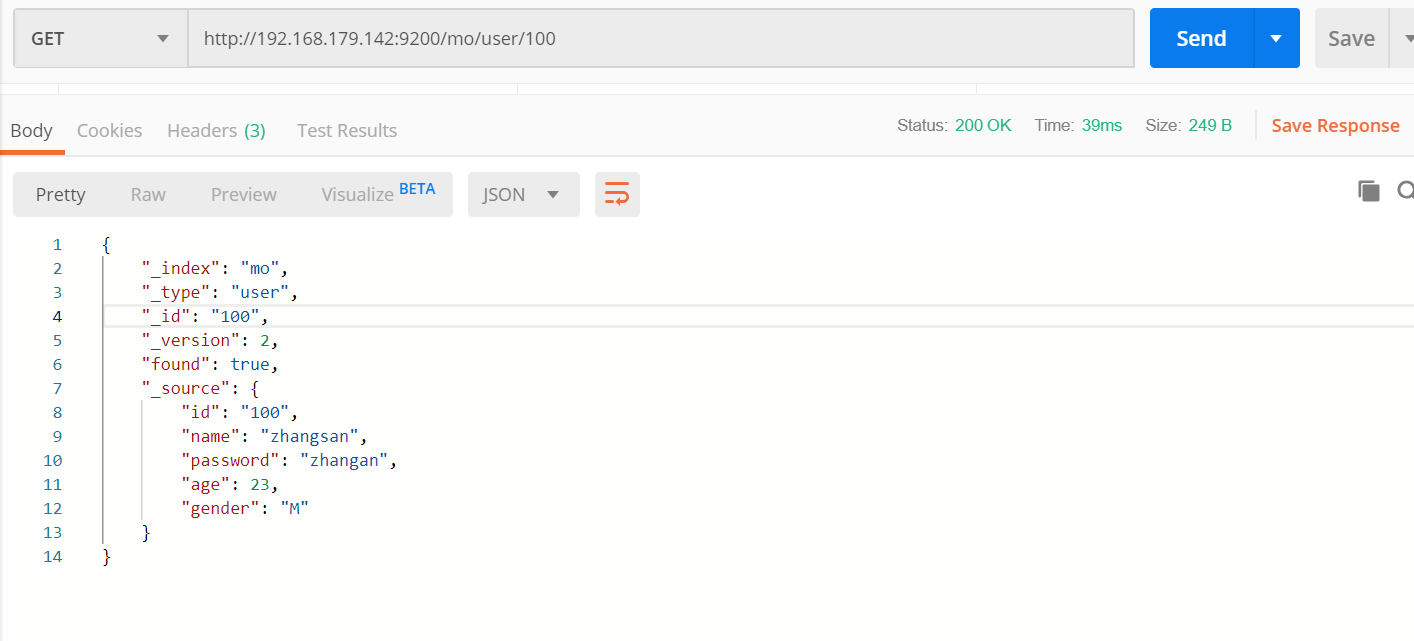
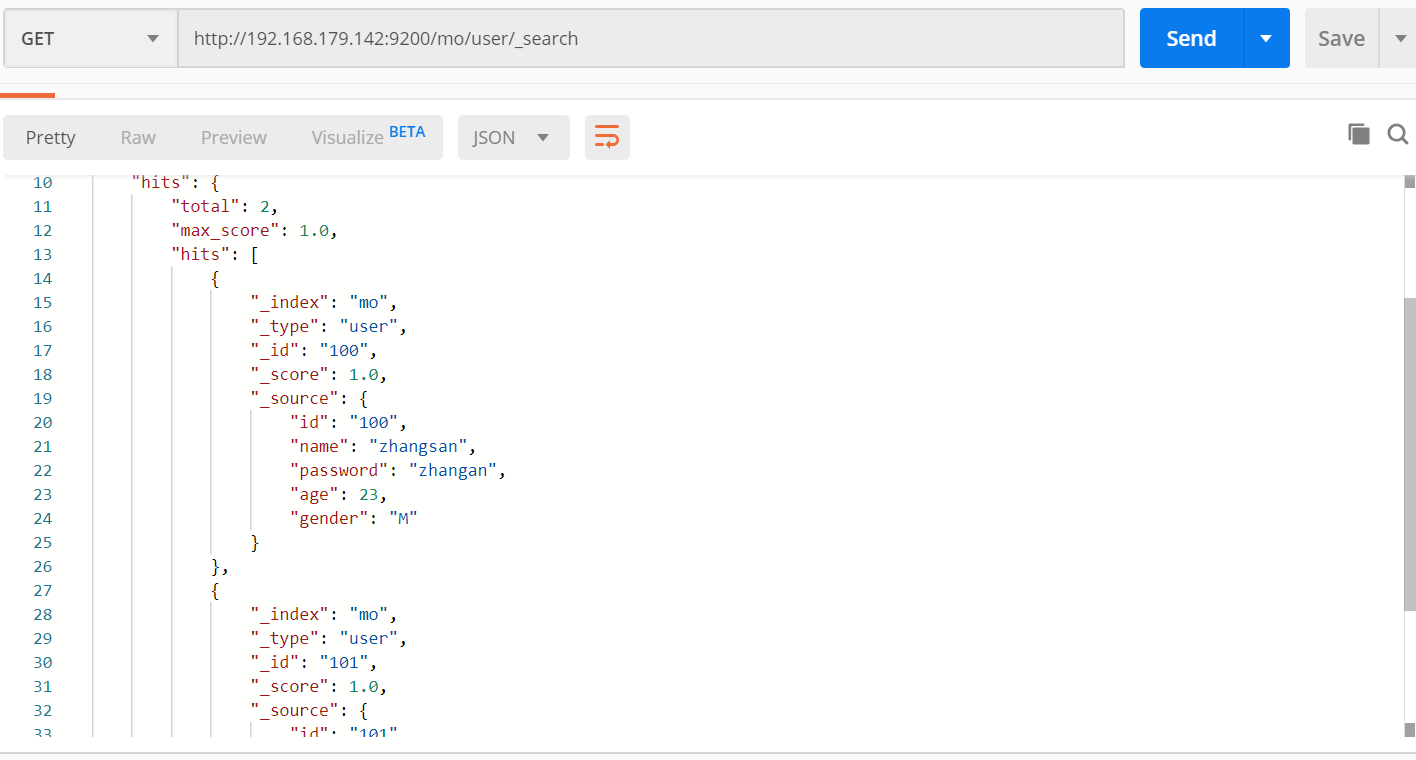
_search 查询所有哦
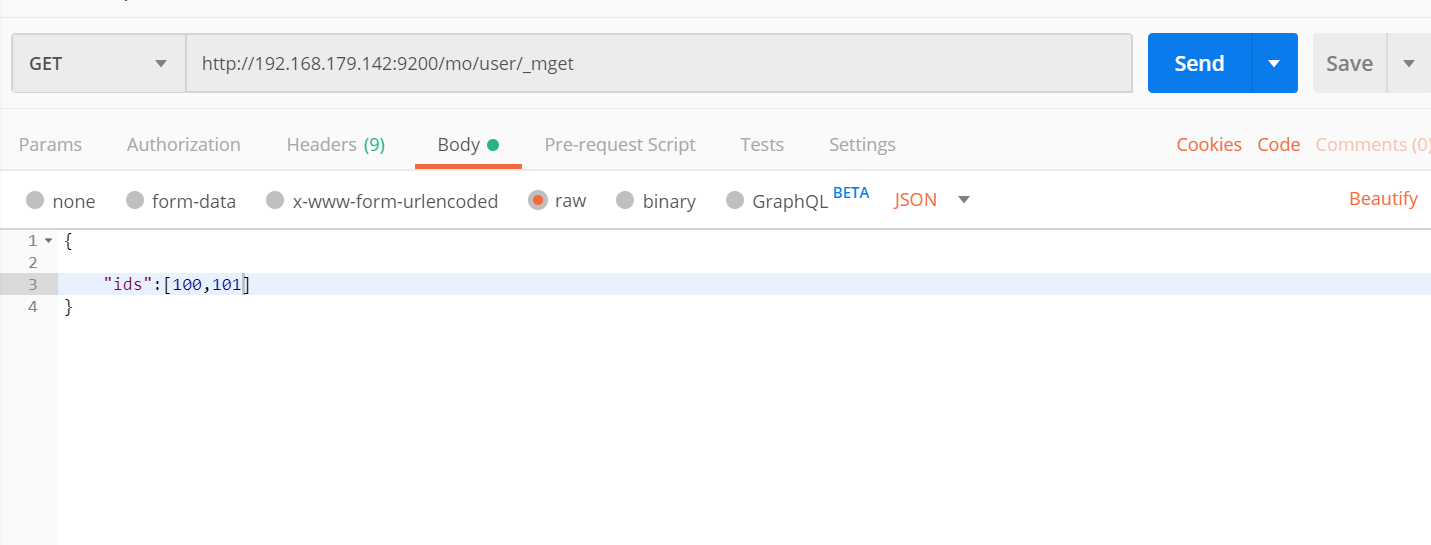
根据多个编号查询文档
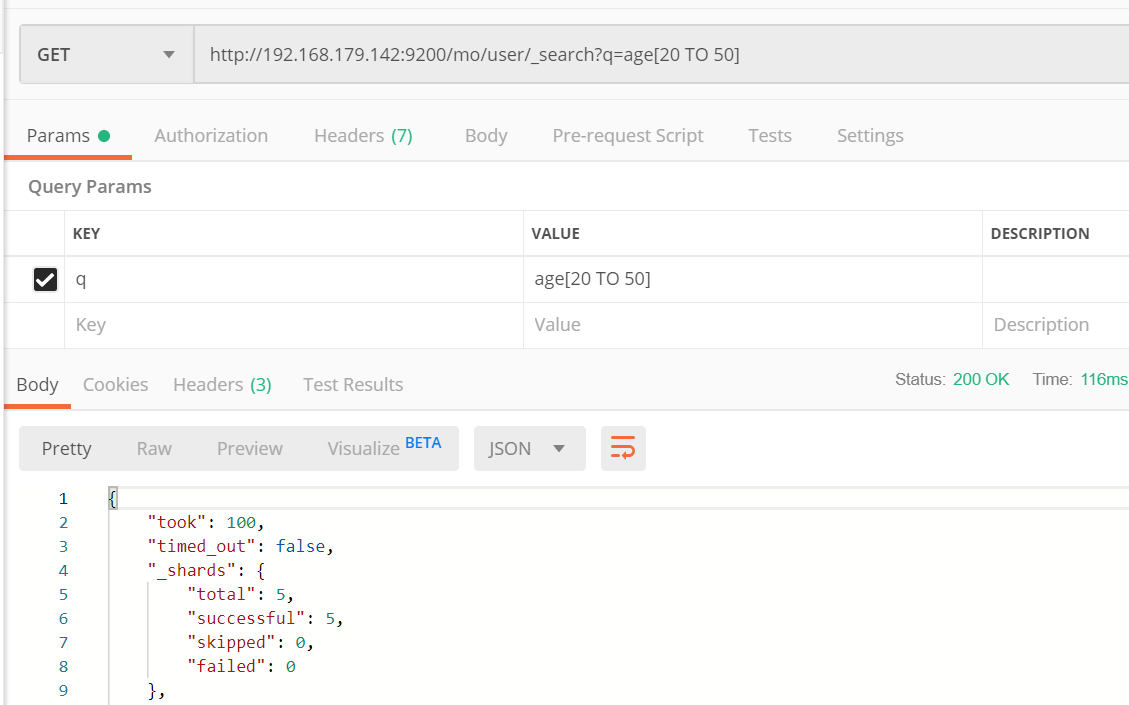
根据范围查询
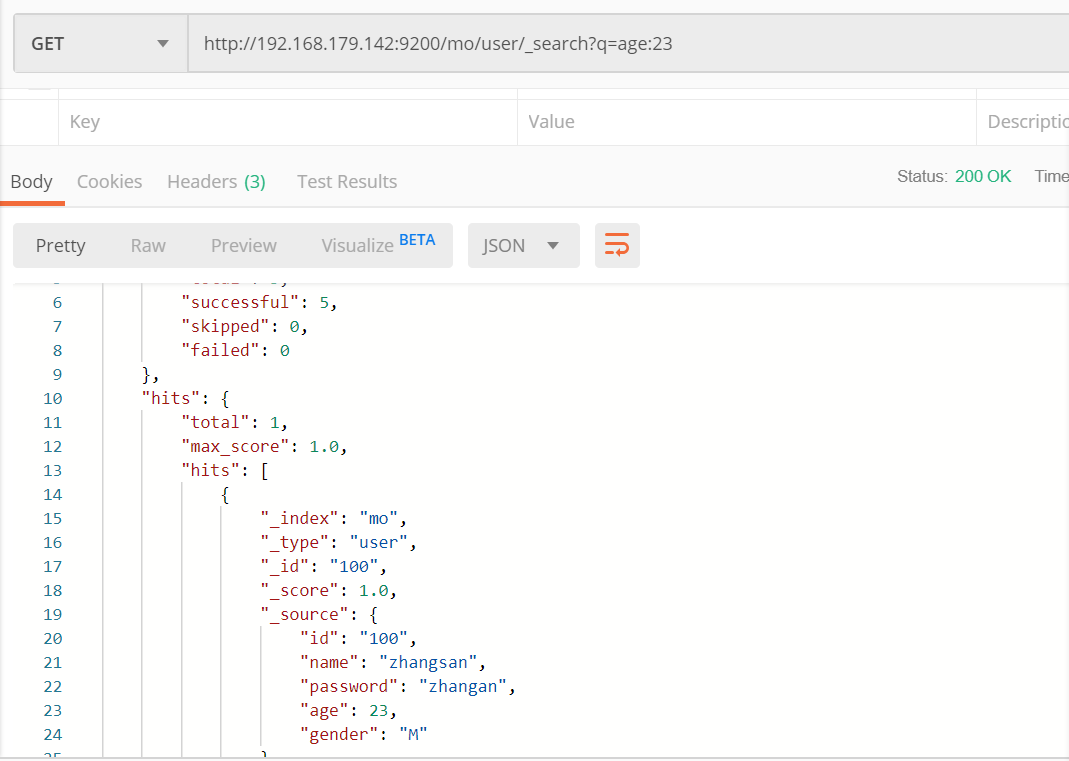
根据参数查询
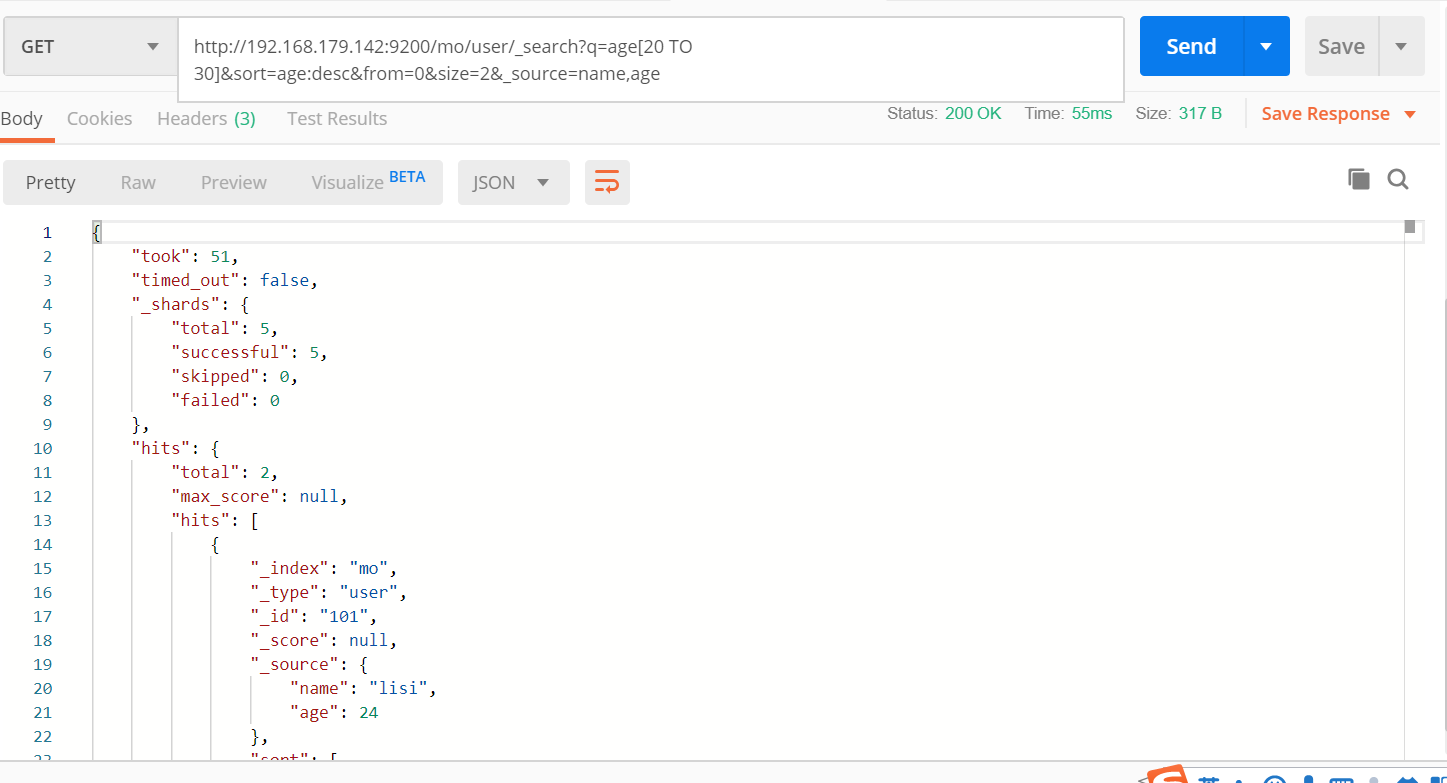
排序查询

Elasticsearch的DSL查询
-
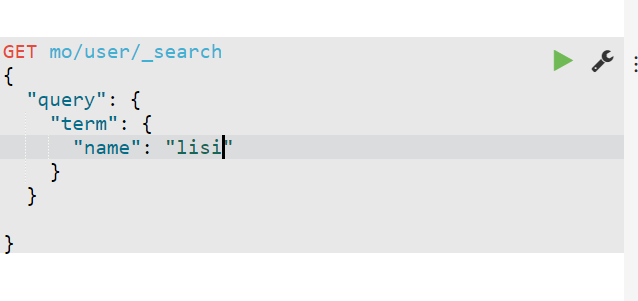
term
- 词元
- 代表完全匹配,⽽且不进⾏分词器分析,⽂档中必须包含整个内容
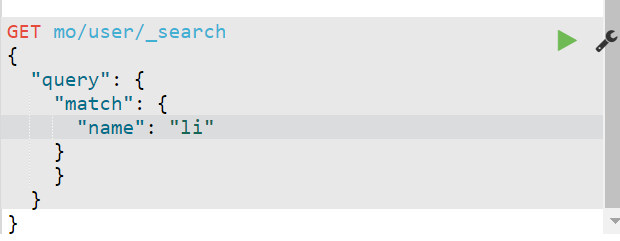
- match
- 代表⼀种模糊查询,只包含其中的⼀部分关键字就可以查询
- filter

分词器
- 什么是分词器
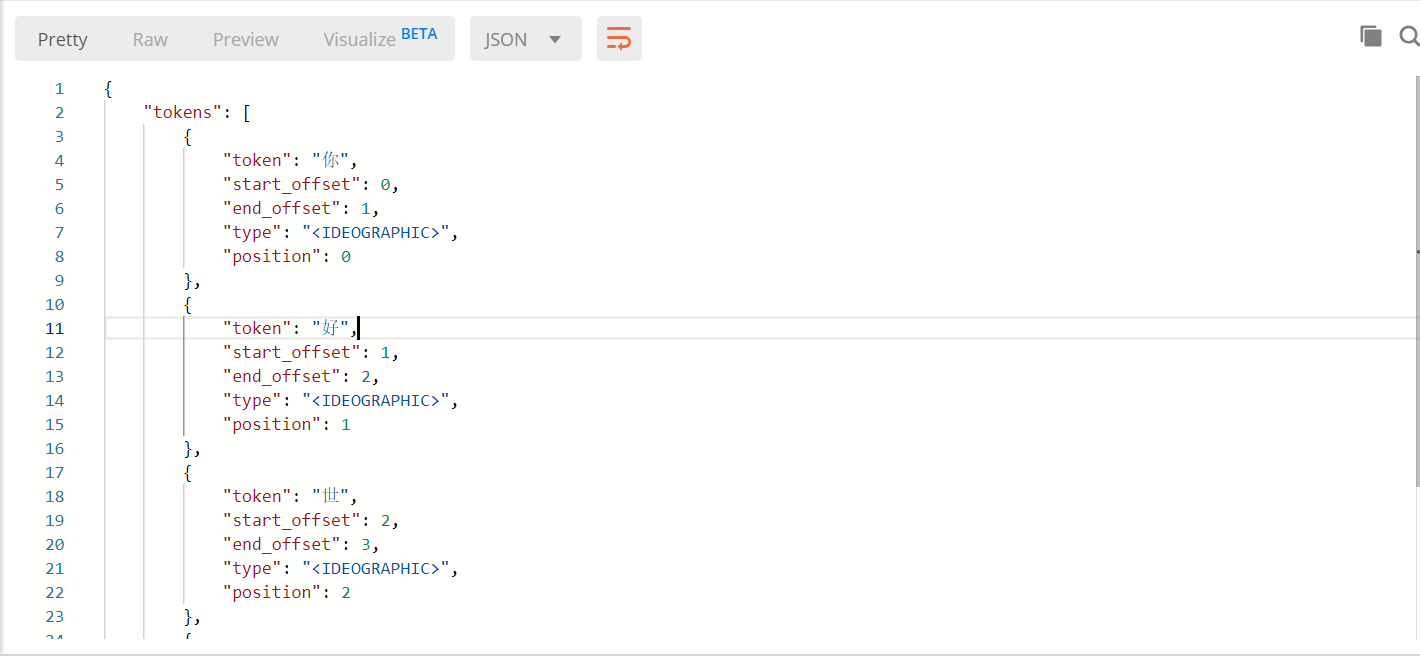
- ES默认的中⽂分词器对中⽂分词⽀持很差。默认情况下是⼀个中⽂字分⼀个词。例如:"你好世界"。分词后的结果为“你”,“好”,"世","界"。
- 基于上⾯的问题,我们需要使⽤另外的分词器(IK分词器)
默认分词器
安装ik分词器
git clone https://github.com/medcl/elasticsearch-analysis-ik mvn package
或者下载地址 zip包
https://github.com/medcl/elasticsearch-analysis-ik
- 注意:es-ik分词器的版本⼀定要与es安装的版本对应
- 将其下载的elasticsearch-analysis-ik-6.4.3.zip上传到linux,解压放到ik⽂件夹中,然后将ik⽂件夹
- 拷⻉到/elasticsearh-6.4.3/plugins下。
unzip elasticsearch-analysis-ik-6.4.3.zip -d ./ik
cp -r ./ik /usr/local/elasticsearch/elasticsearch-6.4.3/plugins/
- 重启es
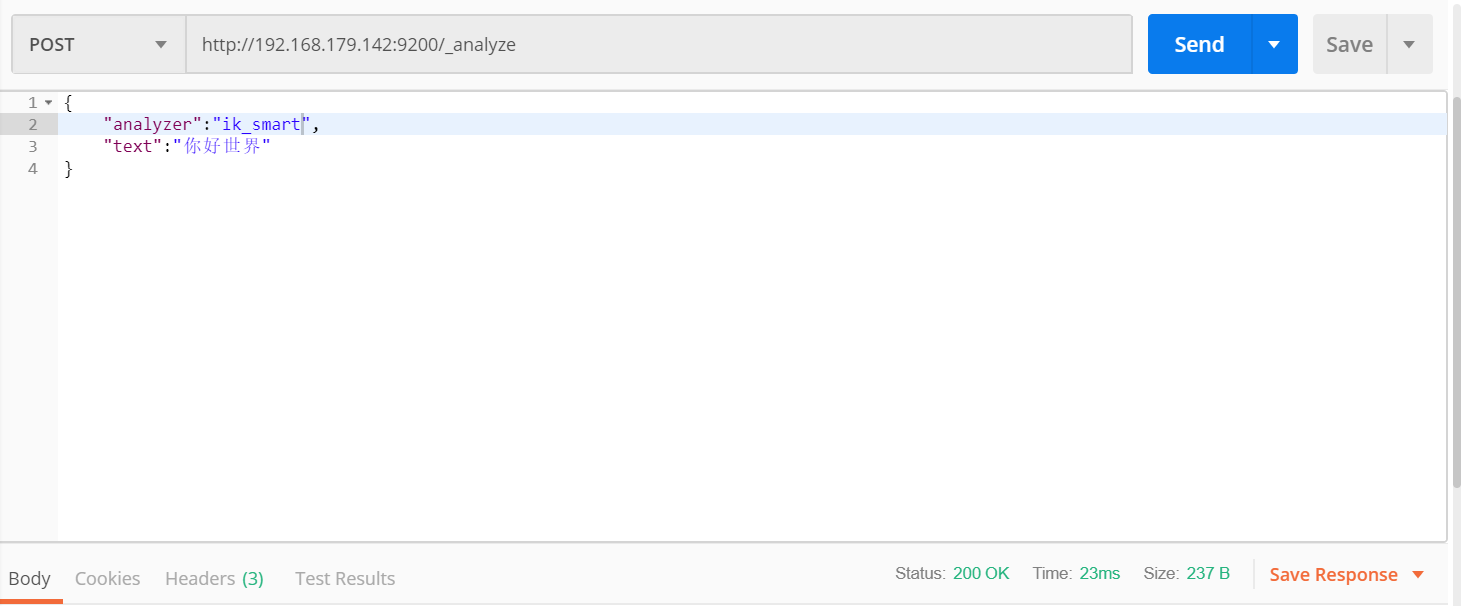
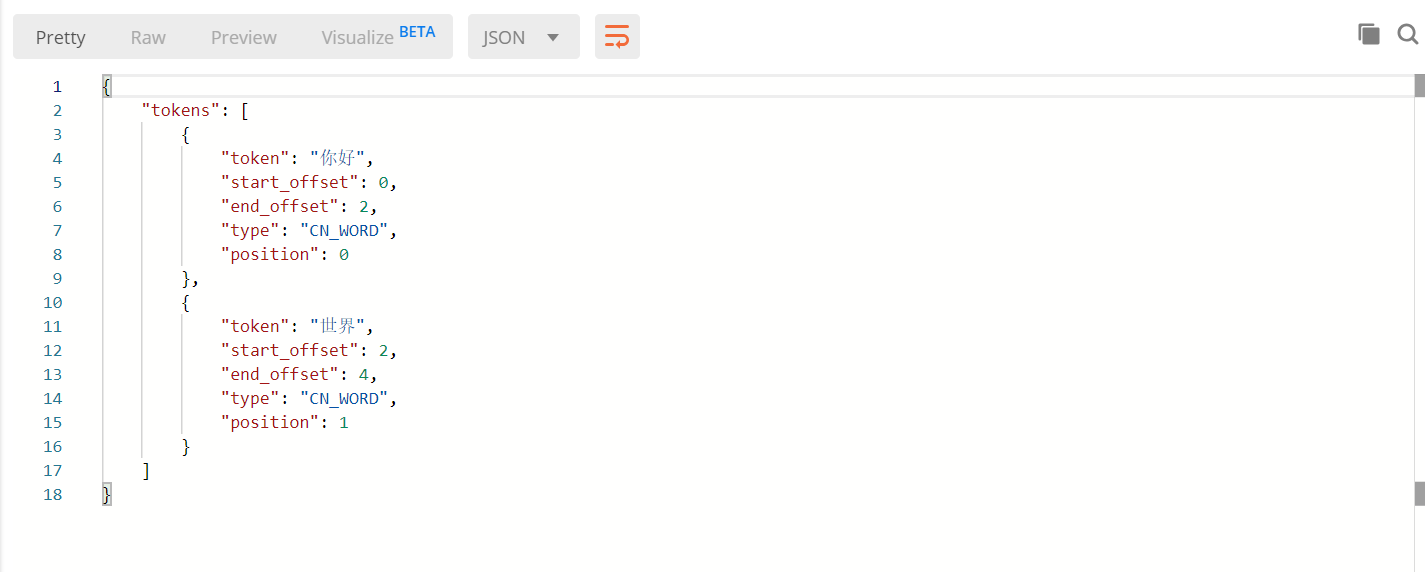
⾃定义扩展字典
概念
- 事先配置好⼀些新词,然后ES就会参考扩展字典,从⽽知道这是⼀个词,然后就可以进⾏分词.
如何定义扩展字典
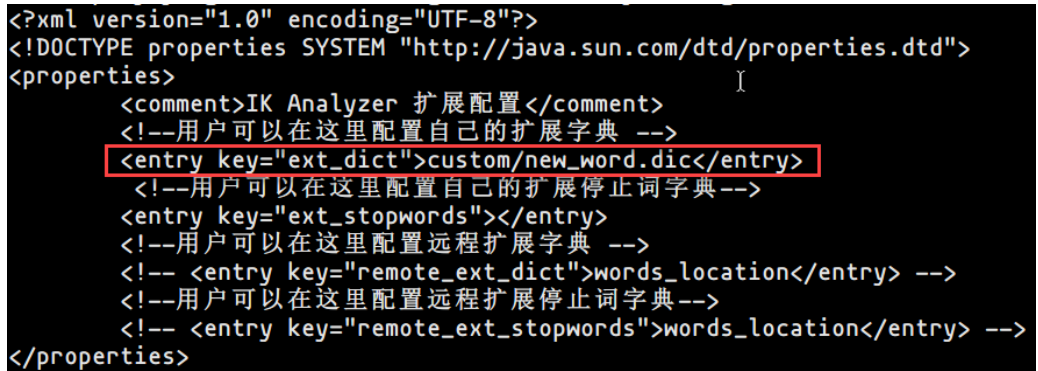
- 在/usr/local/elasticsearch/elasticsearch-6.4.3/plugins/ik/config⽂件夹下建⽴⼀个custom⽂件夹
- 在custom⽂件夹下建⽴⼀个new_word.dic⽂件,想这个⽂件中加⼊新词

- 修改IKAnalyzer.cfg.xml⽂件
ES中的⽂档映射
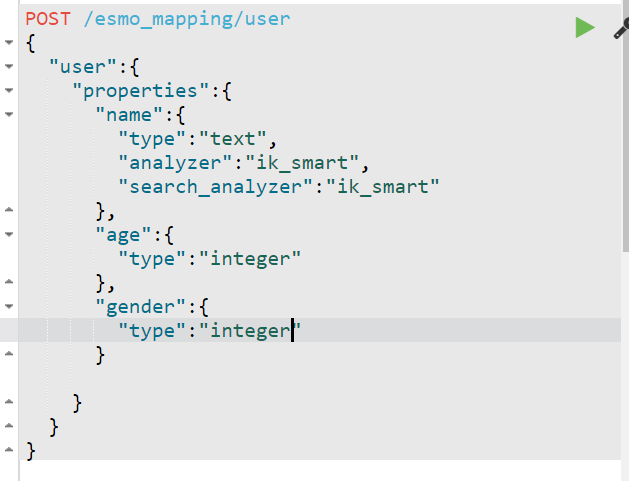
1 概念
- ES中映射就是⽤来定义⼀个⽂档的结构,该结构包括了有哪些字段(Field),字段的类型,字段使
- ⽤什么分词器,字段有哪些属性....
- 动态映射
- ES不需要事先定义好⽂档映射,在⽂档真正写⼊到索引库时根据⽂档的字段⾃动识别
- 静态映射
- 必须事先定义好映射,包括⽂档的各个字段以及类型
- 类型
- 字符串类型:text和keyword。text可以分词,⽽且需要建⽴索引,⽽且不能⽀持聚合和排序;
- keyword不能分词,⽤来实现聚合,排序和过滤
- 基本类型
- 整型:long,integer,short,byte
- 浮点型:double,float
- 布尔型:boolean
- ⽇期型:date
- ⼆进制型:binary
- 数组类型:[]
- 复杂类型
- 对象型:{}
- 地理类型
- 特定类型
- 案例:创建⽂档映射
ELK搭建
安装logstash
tar -zxvf logstash-6.4.3.tar.gz
cd /home/hadoop/opt/logstash/logstash-6.4.3/config
#创建文件
touch logstash.conf
logstash.conf 文件内容(读取文件存储到elasticsearch中)文件内容如下:
input { file { path => "/home/hadoop/opt/elasticsearch/elasticsearch-6.4.3/logs/*.log" start_position => beginning } } filter { } output { elasticsearch { hosts => "192.168.179.11:9200" } }
logstash配置导入mysql数据到es
input { jdbc { jdbc_driver_library => "/home/hadoop/opt/logstash-6.4.3/lib/mysql-connector-java-5.1.48.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://192.168.246.1:3306/clouddb03?autoReconnect=true&useSSL=false" jdbc_user => "root" jdbc_password => "root" jdbc_default_timezone => "Asia/Shanghai" statement => "SELECT * FROM dept" } } output { elasticsearch { index => "mysqldb" document_type => "dept" document_id => "%{elkid}" hosts => ["192.168.179.142:9200"] } }
启动logstash
sh logstash -f /home/hadoop/opt/logstash/logstash-6.4.3/config/logstash.conf &
如果提示--path.data的问题,则需要指定path.data的路径,随便找个路径就行,
我的是这样启动:sh logstash -f
/home/hadoop/opt/logstash/logstash-6.4.3/config/logstash.conf --path.data=/home/elk/logstash-6.4.2/logs &
完了可以看到kibana上面有logstash推送过去的日志了
logstash 导入数据库
