


关于openstack和虚拟化
首先要说到虚拟化技术
虚拟化是云计算的基础。简单的说,虚拟化使得在一台物理的服务器上可以跑多台虚拟机,虚拟机共享物理机的 CPU、内存、IO 硬件资源,但逻辑上虚拟机之间是相互隔离的。
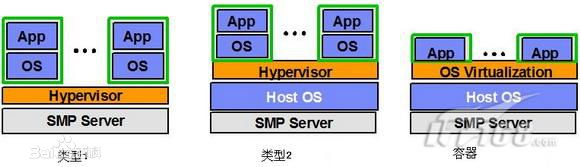
根据 Hypervisor 的实现方式和所处的位置,虚拟化又分为三种:
1型虚拟化:
Hypervisor 直接安装在物理机上,多个虚拟机在 Hypervisor 上运行。Hypervisor 实现方式一般是一个特殊定制的 Linux 系统。KVM和 VMWare 的 ESXi 都属于这个类型。
2型虚拟化:
物理机上首先安装常规的操作系统,比如 Redhat、Ubuntu 和 Windows。Hypervisor 作为 OS 上的一个程序模块运行,并对管理虚拟机进行管理。XEN、VirtualBox 和 VMWare Workstation 都属于这个类型。
还有一种容器型:
虚拟机运行在传统操作系统上,创建一个独立的虚拟化实例(容器),指向底层托管操作系统,被称为“操作系统虚拟化”。操作系统虚拟化是在操作系统中模拟出运行应用程序的容器,所有虚拟机共享内核空间,性能最好,耗费资源最少。但是缺点是底层和上层必须使用同一种操作系统。
KVM:开源虚拟化技术
KVM(Kernel-based Virtual Machine)是一个开源的系统虚拟化模块,它需要硬件(CPU)支持,如Intel VT技术或者AMD V技术,内存的相关如Intel的EPT和AMD的RVI技术。是基于硬件的完全虚拟化,完全内置于Linux。
KVM 是作为内核模块实现的,因此 Linux 只要加载该模块就会成为一个hypervisor。
KVM包含一个内核模块kvm.ko用来实现核心虚拟化功能,以及一个和处理器强相关的模块如kvm-intel.ko或kvm-amd.ko。KVM本身不实现任何模拟,仅仅是暴露了一个/dev/kvm接口,这个接口可被宿主机用来主要负责vCPU的创建,虚拟内存的地址空间分配,vCPU寄存器的读写以及vCPU的运行。有了KVM以后,guest os的CPU指令不用再经过QEMU来转译便可直接运行,大大提高了运行速度。但KVM的kvm.ko本身只提供了CPU和内存的虚拟化,所以它必须结合QEMU才能构成一个完整的虚拟化技术。
QEMU是一个独立的虚拟化解决方案,通过动态二进制转换来模拟CPU,并提供一系列的硬件模型,使guest os认为自己和硬件直接打交道,其实是同QEMU模拟出来的硬件打交道,QEMU再将这些指令翻译给真正硬件进行操作。通过这种模式,guest os可以和主机上的硬盘,网卡,CPU,CD-ROM,音频设备和USB设备进行交互。但由于所有指令都需要经过QEMU来翻译,因而性能会比较差:
从前面的介绍可知,KVM负责cpu虚拟化+内存虚拟化,实现了cpu和内存的虚拟化,但kvm并不能模拟其他设备,还必须有个运行在用户空间的工具才行。KVM的开发者选择了比较成熟的开源虚拟化软件QEMU来作为这个工具,QEMU模拟IO设备(网卡,磁盘等),对其进行了修改,最后形成了QEMU-KVM。
在QEMU-KVM中,KVM运行在内核空间,QEMU运行在用户空间,实际模拟创建、管理各种虚拟硬件,QEMU将KVM整合了进来,通过/ioctl 调用 /dev/kvm,从而将CPU指令的部分交给内核模块来做,KVM实现了CPU和内存的虚拟化,但KVM不能虚拟其他硬件设备,因此qemu还有模拟IO设备(磁盘,网卡,显卡等)的作用,KVM加上QEMU后就是完整意义上的服务器虚拟化。
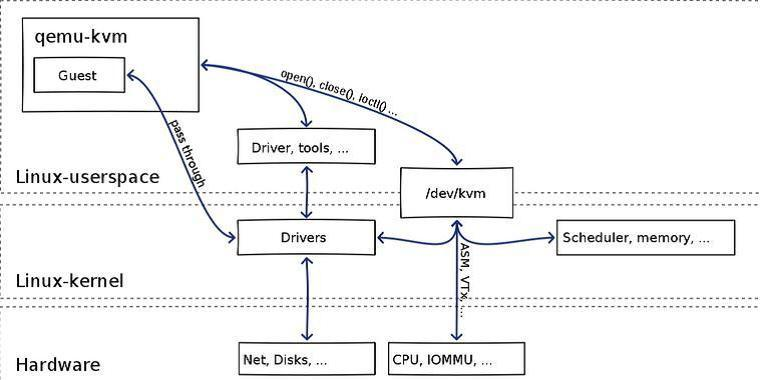
综上所述,QEMU-KVM具有两大作用:
- 提供对cpu,内存(KVM负责),IO设备(QEMU负责)的虚拟
- 对各种虚拟设备的创建,调用进行管理(QEMU负责)
当然,由于qemu模拟io设备效率不高的原因,现在常常采用半虚拟化的virtio方式来虚拟IO设备。
总的来说:QEMU是一个独立的虚拟化解决方案,并不依赖KVM(它本身自己可以做CPU和内存的模拟,只不过效率较低),而KVM是另一套虚拟化解决方案,对CPU进行虚拟效率较高(采用了硬件辅助虚拟化),但本身不提供其他设备的虚拟化,借用了QEMU的代码进行了定制,所以KVM方案一定要依赖QEMU
libvirt
顺带提一提libvirt,这是RedHat开始支持KVM后,大概是觉得QEMU+KVM方案中的用户空间虚拟机管理工具不太好用或者通用性不强,所以干脆搞了个libvirt出来,一个针对各种虚拟化平台的虚拟机管理的API库,一些常用的虚拟机管理工具如virsh(类似vim编辑器),virt-install,virt-manager等和云计算框架平台(如OpenStack,OpenNebula,Eucalyptus等)都在底层使用libvirt提供的应用程序接口。
libvirt主要由三个部分组成:API库,一个守护进程 libvirtd 和一个默认命令行管理工具 virsh。
Xen:
Xen是另一套独立的虚拟化解决方案,最初的Xen只支持半虚拟化,Intel VT技术出现后,添加了全虚拟化功能,这个全虚拟化功能也是借助了qemu实现,但不是完全依赖qemu。
Xen支持全虚拟化和半虚拟化,半虚拟化场景下,操作系统必须进行显式地修改(“移植”)以在Xen上运行(但是提供对用户应用的兼容性)。这使得Xen无需特殊硬件支持,就能达到高性能的虚拟化。
PV(Para-Vritralization)和FV(Full-Vritralization)的差别,主要以guest OS的硬件仿真程度做区分。
FV:FV是一般较常看到的作法,所有的guest OS完全不会看到实际的硬件为何,只能使用由Supervisor所提供的所有虚拟硬件,因此,在这种机制下,guest OS动作的性能一定会大受虚拟接口的影响。另外还有一个特点,就是因为完全仿真的关系,不支持新的技术,连ACPI开关机的机制都无法使用,也就是当使用 者在FV的guest OS下,若直接触动关机的按钮(这里的按钮是由VMM所提供的,不是主机上的)会直接断电,而不会进行关机程序。
PV:至于PV的作法,有鉴于一般Virtual Machine工具都是以完全仿真的方式,造成性能上的降低,因此,XEN在设计上,希望各操作系统可以在开发时就已经将XEN的技术包括进去,这样在使 用时,就可以用局部仿真的方式,让操作系统可以直接使用到硬件中的CPU、内存等,而不需要通过XEN做仿真的操作。
FV: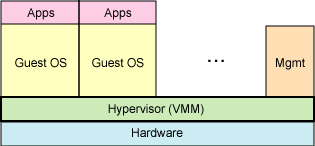 PV:
PV: 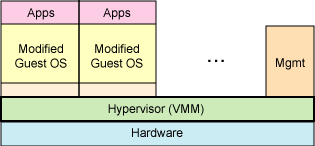
关于半虚拟化的历史:
ring0是指CPU的运行级别,ring0是最高级别,ring1次之,ring2更次之……
拿Linux+x86来说,
操作系统(内核)的代码运行在最高运行级别ring0上,可以使用特权指令,控制中断、修改页表、访问设备等等。
应用程序的代码运行在最低运行级别上ring3上,不能做受控操作。如果要做,比如要访问磁盘,写文件,那就要通过执行系统调用(函数),执行系统调用的时候,CPU的运行级别会发生从ring3到ring0的切换,并跳转到系统调用对应的内核代码位置执行,这样内核就为你完成了设备访问,完成之后再从ring0返回ring3。这个过程也称作用户态和内核态的切换。
那么,虚拟化在这里就遇到了一个难题,因为宿主操作系统是工作在ring0的,客户操作系统就不能也在ring0了,但是它不知道这一点,以前执行什么指令,现在还是执行什么指令,那肯定不行啊,没权限啊,玩不转啊。所以这时候虚拟机管理程序(VMM)就要避免这件事情发生。
(VMM在ring0上,一般以驱动程序的形式体现,驱动程序都是工作在ring0上,否则驱动不了设备)
一般是这样做,客户操作系统执行特权指令时,会触发异常(CPU机制,没权限的指令,触发异常),然后VMM捕获这个异常,在异常里面做翻译,模拟,最后返回到客户操作系统内,客户操作系统认为自己的特权指令工作正常,继续运行。但是这个性能损耗,就非常的大,你想想原来,简单的一条指令,执行完,了事,现在却要通过复杂的异常处理过程。
这时候半虚拟化就来了,半虚拟化的思想就是,让客户操作系统知道自己是在虚拟机上跑的,工作在非ring0状态,那么它原先在物理机上执行的一些特权指令,就会修改成其他方式,这种方式是可以和VMM约定好的,这就相当于,我通过修改代码把操作系统移植到一种新的架构上来,就是定制化。所以像XEN这种半虚拟化技术,客户机操作系统都是有一个专门的定制内核版本,和x86、mips、arm这些内核版本等价。这样以来,就不会有捕获异常、翻译、模拟的过程了,性能损耗非常低。这就是XEN这种半虚拟化架构的优势。这也是为什么XEN只支持虚拟化Linux,无法虚拟化windows原因,微软不改代码啊。
可以后来,CPU厂商,开始支持虚拟化了,情况有发生变化,拿X86 CPU来说,引入了Intel-VT 技术,支持Intel-VT 的CPU,有VMX root operation 和 VMX non-root operation两种模式,两种模式都支持Ring 0 ~ Ring 3 这 4 个运行级别。这下好了,VMM可以运行在VMX root operation模式下,客户OS运行在VMX non-root operation模式下。也就说,硬件这层做了些区分,这样全虚拟化下,有些靠“捕获异常-翻译-模拟”的实现就不需要了。而且CPU厂商,支持虚拟化的力度越来越大,靠硬件辅助的全虚拟化技术的性能逐渐逼近半虚拟化,再加上全虚拟化不需要修改客户操作系统这一优势,全虚拟化技术应该是未来的发展趋势。
OpenStack:开源管理项目
OpenStack是一个旨在为公共及私有云的建设与管理提供软件的开源项目。它不是一个软件,而是由几个主要的组件组合起来完成一些具体的工作。OpenStack由以下五个相对独立的组件构成:
lOpenStack Compute(Nova)是一套控制器,用于虚拟机计算或使用群组启动虚拟机实例;
lOpenStack镜像服务(Glance)是一套虚拟机镜像查找及检索系统,实现虚拟机镜像管理;
lOpenStack对象存储(Swift)是一套用于在大规模可扩展系统中通过内置冗余及容错机制,以对象为单位的存储系统,类似于Amazon S3;
lOpenStack Keystone,用于用户身份服务与资源管理以及
lOpenStack Horizon,基于Django的仪表板接口,是个图形化管理前端。
这个起初由美国国家航空航天局和Rackspace在2010年末合作研发的开源项目,旨在打造易于部署、功能丰富且易于扩展的云计算平台。OpenStack项目的首要任务是简化云的部署过程并为其带来良好的可扩展性,企图成为数据中心的操作系统,即云操作系统。
由此可以看出,OpenStack是一个框架,一个可以建立公有云和私有云的基础架构。它并不是一个现成的产品。
OpenStack几乎支持所有的虚拟化管理程序,不论是开源的(Xen与KVM)还是厂商的(Hyper-V与VMware)。但在以前,OpenStack是基于KVM开发的,KVM常常成为默认的虚拟机管理程序。两者都使用相同的开放源理念与开发方法。
OpenStack支持多种类型的虚拟化技术


图中可以看到,支持KVM、Hyper-v、VMWare、Xen、Docker等虚拟化技术。可以看到,OpenStack主要是利用Libvirt进行的虚拟机操作,但是也支持直接调用原生的API进行操作。
OpenStack所说的公有云和私有云管理,并不是可以管理第三方公有云,而是企业可以借助OpenStack,搭建云管平台,对外提供服务,自己作为公有云厂商。
