C语言相关的基础字符串函数
C语言中没有专门的字符串类型,所以就用字符数组和字符指针形式表示
1 char arr[]="abcdef"; //字符数组表示的字符串 2 char*arr="abcef"; //常量字符串
对字符串进行操作的函数,可以称为字符串函数,比较常见的有:strlen,strcmp,strcpy,strcat,strncpy,strncat,strncmp,strstr,strtok,strerror
strlen
strlen是用来计算字符串长度的函数,函数的参数是指针,从指针指向位置开始计数,遇到‘\0'为止,计数个数为\0前出现的字符个数(不包括'\0')
#include <stdio.h> #include <string.h> int main() { char arr[] = "abcdef"; char p[] = { 'a', 'b', 'c', 'd' }; int i=strlen(arr); int j=strlen(arr + 1); int k = strlen(p); printf("%d %d %d", i, j,k); //结果是6 5 随机值 //6和5表示了strlen是从指针指向的地方开始计算字符串的长度的,而不只是简单从第一个字符开始计算。 //随机值的出现是因为字符数组p没有'\0'的存在,所以计数会一直进行,直到在界外遇到\0才停下 //所以参数指向的字符串必须以\0结束才能用到strlen return 0; }
strlen作为一个函数他有属于自己的返回值类型,它的类型是unsigned int 也就是无符号的整型,所以在strlen的返回值中是不存在负数的 。这个很好理解,因为字符串的字符个数肯定是正数。但是,当遇到strlen的加减法时,也要注意这是无符号整型的加减,最后得出的结果不会是负数。
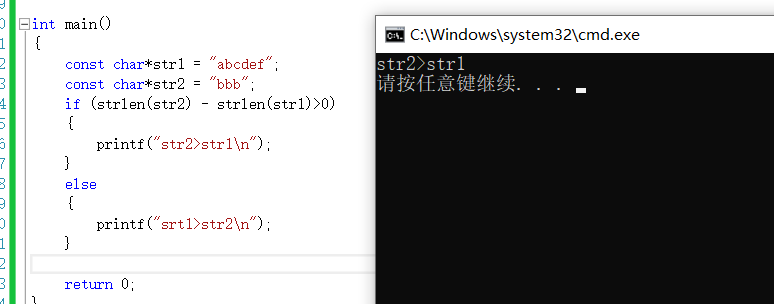
本来strlen(str2)-strlen(str1)这个结果应该是3-6,但在无符号整型中-3写成二进制表达是10000000000000000000000000000011没有符号位,显然是一个庞大的正数。这是strlen的一个细节,值得注意。
模拟实现strlen函数(原来的strlen返回类型应该是unsigned int此处使用int来返回与原来不一致,但不影响运行)
三种方法:1、计数器法 2、递归求解 3、指针减指针
1、计数器法
int my_strlen(const char*str) { //计数器法,字符指针每走一位,计数器加一,一直到'\0'停下 assert(str); int count = 0; while (*str != '\0') { str++; count++; } return count; } int main() { char arr[] = "abcd"; int n=my_strlen(arr); printf("%d", n); return 0; }
2、递归法
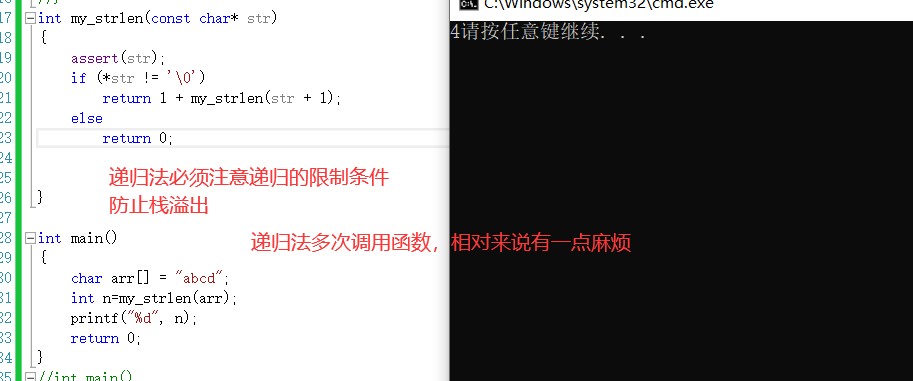
3、指针减指针
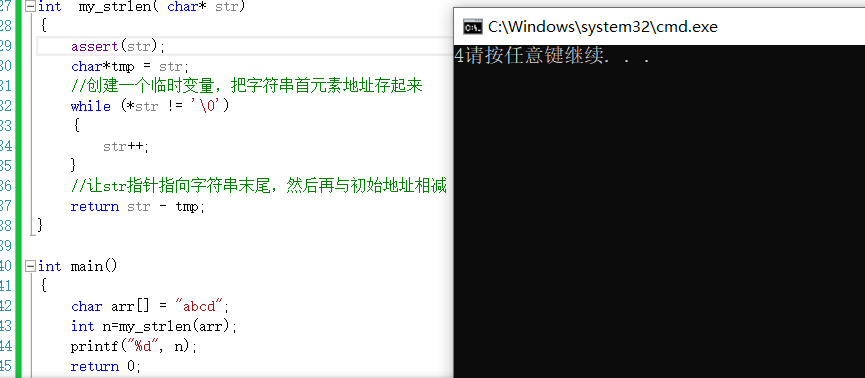
模拟实现strlen这个函数是字符串函数里面比较基础的内容,有助于加深对strlen的理解。
strcmp
strcmp这个函数是用来比较字符串的,可以称为字符串比较函数。字符串之间的比较不能使用大于小于等于这种数学符号,所以C语言专门规定了一个函数叫strcmp用来比较两个字符串。strcmp这个比较函数接受的参数是字符指针
int strcmp(const char*p1,const char*p2) //这是他的类型 //返回值是一个整数,第一个字符串大于第二个字符串,则返回大于0的数字 第一个字符串等于第二个字符串,则返回0 第一个字符串小于第二个字符串,则返回小于0的数字
字符串的比较并不是比较字符串的长度,而是比较字符的ASCII码值,如果ASCII码值相同就比较下一个字符的ASCII值,直到比出大小。
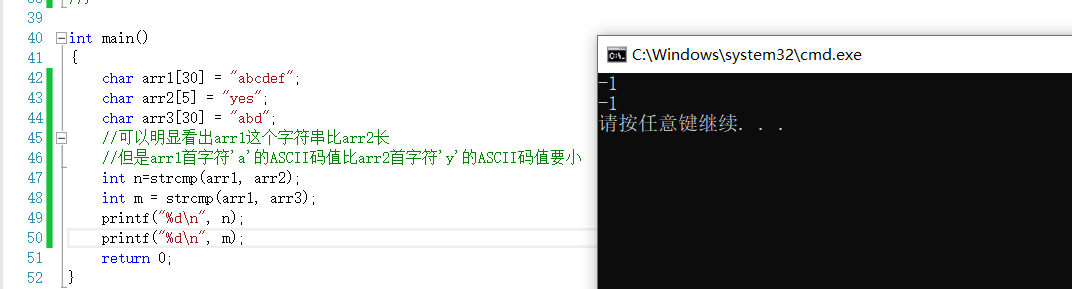
上图展示了strcmp的比较方法,比较字符的ASCII码值。这里的编译器使用了vs2013,默认返回值-1。返回值是一个负数,表示在这两个函数中第一个字符串都小于第二个字符串。但是并不是所有编译器都返回-1这个值,在这种情况下,只要返回值是一个负数,就是合理的。
模拟实现strcmp函数
1 int my_strcmp(const char*str1, const char* str2) 2 { 3 4 assert(str1&&str2); 5 while (*str1&&*str2 && (*str1 == *str2)) 6 { 7 //字符出现不相等或者出现字符串结束时,进入比较环节 8 str1++; 9 str2++; 10 } 11 if (*str1 > *str2) 12 return 1; 13 else if (*str1 < *str2) 14 return -1; 15 else 16 return 0; 17 18 }
此处没有写主函数,这只是一个模拟字符串比较函数,写得较为简单。基本思想就是利用指针,逐个字符对比ASCII码值大小。
相应的,对于不是字符串的类型也可以在内存中进行类似的操作,这时候要用到函数memcmp。(这是内存函数并非字符串函数)
int memcmp ( const void * ptr1,const void * ptr2,size_t num );
基本模型如上。比较的是ptr1和ptr2指针开始的num个字节,返回值类似于strcmp,返回大于0的数就是ptr1指向的数据有更大的值,返回0就是前num个字节相等,返回小于0的数就是ptr1指向的数据在内存中值比ptr2所指向的更小。
strcpy,strncpy
strcpy是字符串拷贝函数,即将一个字符串的内容拷贝到另一个字符串中。
char* strcpy(char * destination, const char * source );
这是strcpy的基本模型,返回值类型是字符指针。参数写的也很清楚,第一个是目的地字符串,也就是用来存放拷贝内容的字符串,第二个是来源字符串,就是把这个字符串的内容拷贝到目的地中。
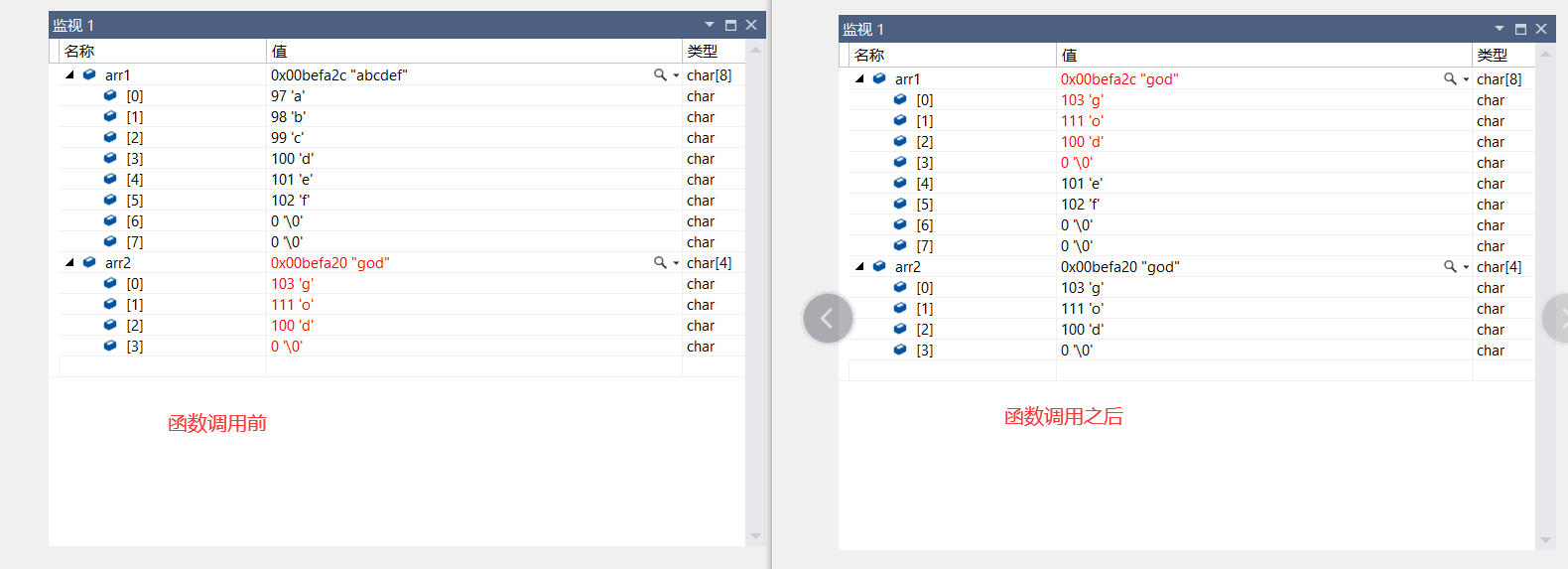
明显可见,函数调用时把arr2的‘\0’也拷贝了过来。这里要注意的是,来源字符串必须以\0’结束,这样才能被正常拷贝。其次便是,目标空间必须足够大,目标空间必须可变。
模拟实现strcpy函数
1 char*my_strcpy(char*dest, const char* src) 2 { 3 assert(dest&&src); 4 char* ret = dest; 5 while (*src != '\0') 6 { 7 *dest = *src; 8 dest++; 9 src++; 10 }//循环结束,src指向'\0',再把'\0'拷贝进去函数就完成了 11 *dest = *src; 12 return ret; 13 } 14 char*my_strcpy(char*dest, const char* src) 15 { 16 assert(dest&&src);//更为简洁的写法 17 while (*dest++ = *src++)//直接在条件里面赋值 18 { 19 ; 20 } 21 }
strncpy就是把来源字符串的前n个字符拷贝到目的字符串中,如果来源字符串字符个数小于n,拷贝的字符后面自动补0
char* strncpy(char * destination, const char * source ,size_t num);
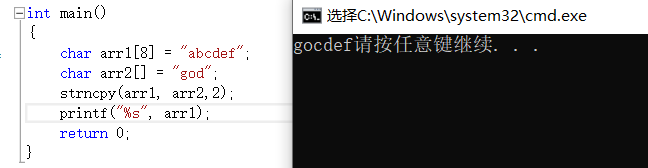
面对非字符串类型的数据,可以用memcpy来进行拷贝(这是内存函数并非字符串函数)
void * memcpy ( void * destination, const void * source, size_t num )
基本模型如上。这个函数把num个字节的内容从来源拷贝到目的处。但是函数在遇到‘\0'时并不会停下来。如果来源和目的有任何重叠,这个结果都是未定义的。
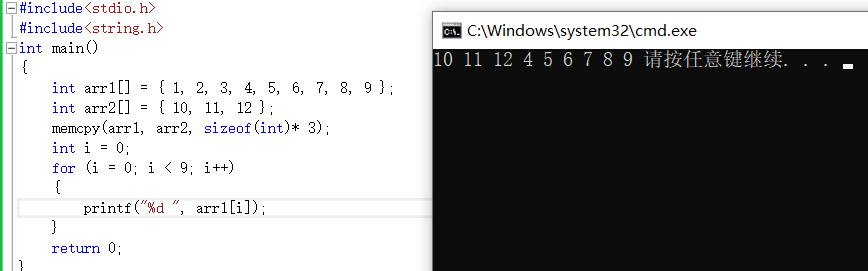
整型数组的拷贝,把来源数组前12个字节的数据拷贝过来替换了目的数组的前3个数字,后面的数字不变。
模拟实现memcpy
void* my_memcpy(void*dest, void* src, int num) { assert(dest&&src); void* ret = dest; int i = 0; for (i = 0; i < num; i++) { *(char*)dest = *(char*)src;//每一个字节进行拷贝 ((char*)src)++;//void*指针不能进行加减操作,转成char*指针可以每次移动一个字节 ((char*)dest)++;//要在++之前整体加上一个括号,不然指针先和++结合,强制类型转换无效 } return ret; }
当出现内存重叠,有时候不能使用memcpy函数,这时候就有函数memmove可以使用(这是内存函数并非字符串函数)
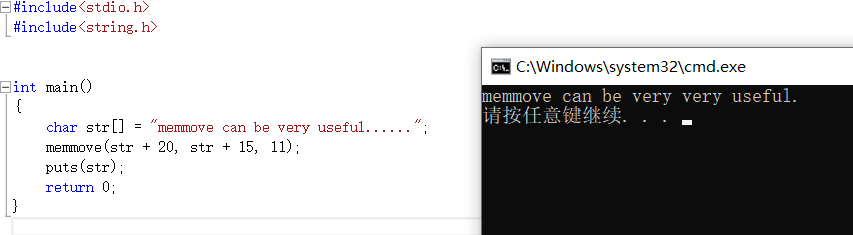
模拟实现memmove
1 void* my_memmove(void* dest, void* src, int count) 2 { 3 assert(dest&&src); 4 void* ret = dest; 5 if (dest < src)//分析从前向后拷贝还是从后向前拷贝 6 //如果dest在src前面只能从前向后拷贝,和memcpy类似 7 //dest在src后面且dest<src+count只能从后向前拷贝(当然void*不能进行加减,此处只是注释而已) 8 { 9 while (count--) 10 { 11 *(char*)dest = *(char*)src; 12 ((char*)src)++; 13 ((char*)dest)++; 14 } 15 } 16 else 17 { 18 while (count--) 19 { 20 *(((char*)dest) + count - 1) = *(((char*)src) + count - 1); 21 } 22 } 23 return ret; 24 25 } 26 int main() 27 { 28 int arr1[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; 29 my_memmove(arr1 , arr1+2, 16); 30 int i = 0; 31 for (i = 0; i < 9; i++) 32 { 33 printf("%d ", arr1[i]); 34 } 35 return 0; 36 }
strcat、strncat
strcat是字符串追加函数,就是将来源字符串追加到目的字符串的‘\0'之后(目的字符串的‘\0'被替换成来源字符串首字符),追加这个过程一定程度上类似于拷贝,也就是把来源字符串拷贝到了目的字符串的后面。同样的要注意,目的字符串必须足够大,目的字符串也必须可变。来源字符串要以‘\0'结束。这几点和刚才的strcpy一样。
特别地,strcat不能用来自身追加,因为这个函数需要先找到目的字符串的‘\0’,然后进行类似于拷贝的操作。如果用于自身追加,‘\0'在拷贝时候被替代,这也就等同于来源字符串被改变了,此时来源字符串也就不是以'\0'结束,追加便出现问题了。
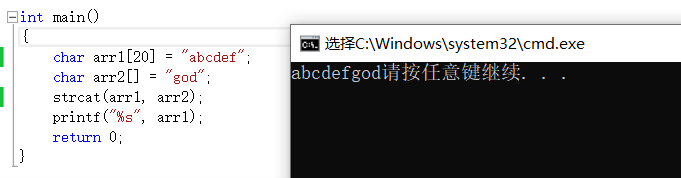
模拟实现strcat函数
char*my_strcat(char*dest, const char* src) { assert(dest&&src); char* ret = dest; while (*dest != '\0') { dest++; }//先找到目的字符串中的'\0' while (*dest++ = *src++) { ; }//追加字符串,此操作同strcpy return ret; }
strncat是追加来源字符串的前n个字符,变化类似于刚才 的strcpy和strncpy。
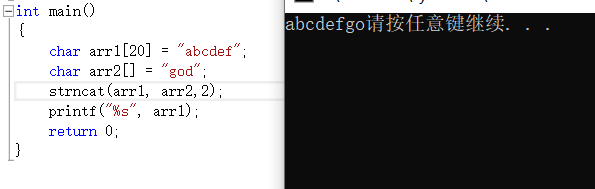
strstr
strstr是搜索子字符串的函数。
char*strstr(const char*str1,const char*str2)
函数基本模型如上。函数返回类型是char*也就是一个指针。当str2不是str1的字串时,就返回空指针。当存在子串时,返回的是第一个字串的首字符地址。
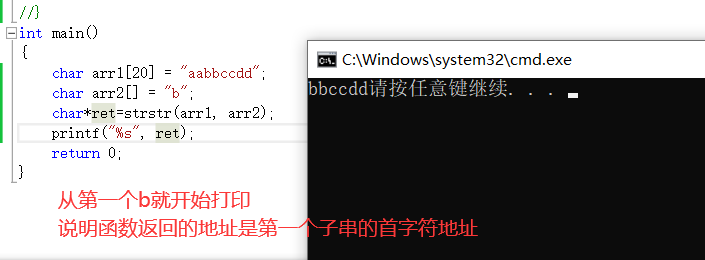
模拟实现strstr
1 char*my_strstr(const char*str1, const char* str2) 2 { 3 assert(str1&&str2); 4 char*cur = (char*) str1; 5 char*s1 = (char*)str1; 6 char*s2 = (char*)str2; 7 //使用cur指针来记录首字符相同的地址 8 //创建s1和s2变量是为了和cur指针不发生冲突 9 while (*cur) 10 { 11 s1 = cur; 12 s2 = (char*)str2; 13 while (*s1&&*s2 && (*s1==*s2)) 14 { 15 s1++; 16 s2++; 17 } 18 if (*s2 == '\0') 19 return cur; 20 cur++; 21 } 22 return NULL; 23 //这种写法保证了出现重复字符时也能正确找到子串 24 25 26 } 27 int main() 28 { 29 char arr1[20] = "aabbbccdd"; 30 char arr2[] = "bbc"; 31 char*ret=my_strstr(arr1, arr2); 32 printf("%s", ret); 33 return 0; 34 }
strtok
strtok是用来提取被分割的字符串的。函数模型如下
char*strtok(char*str,const char* sep)
第一个参数是被操作的原字符串,第二个参数是分隔符形成的字符串。
strtok会找到原字符串中的下一个标记,然后用'\0'结尾,然后返回一个指向这个标记的指针。
当函数的第一个参数不是NULL时,strtok会查找第一个标记,并且保存这个标记的位置。当函数第一个参数是NULL时,strok从被保存位置开始查找下一个标记。当字符串不存在更多标记时,会返回NULL。
以上描述比较抽象,不大好理解,可以看以下代码。
int main() { char arr[] = "abc@def.ghi"; char*p = "@."; char buf[1024] = { 0 }; strcpy(buf, arr); char*ret = NULL; char *ret = strtok(arr, p);//第一次使用函数,找到@将其变为'\0'然后返回a的地址,打印字符串 printf("%s\n", ret); ret = strtok(NULL, p);//第二次使用函数,找到刚才的保存位置,寻找下一个标记 .将其变成'\0'然后返回d的地址,打印字符串 printf("%s\n", ret); ret = strtok(NULL, p);//第三次使用函数,找到刚才的保存位置,寻找下一个标记,找到‘\0',打印字符串 printf("%s\n", ret); return 0; }
当然实际上不会这么写代码,因为这样必须知道分隔符个数,要知道调用几次函数。可以用for循环来实现
int main() { char arr[] = "abc@def.ghi"; char*p = "@."; char buf[1024] = { 0 }; strcpy(buf, arr); char*ret = NULL; for (ret = strtok(arr, p); ret != NULL; ret = strtok(NULL, p)) { //巧妙在于第一步初始化ret的值,for循环进来只用一次初值,而正好strtok(arr,p)只用一次 //判断条件是ret不返回空指针,如果返回空指针就说明字符串不存在更多标记了,不用继续往下循环了 //每走完一次循环ret值都会变化,也就是去查找下一处标记 printf("%s\n", ret); } return 0; }
strerror
这个函数是用来判断错误的,返回相应的错误码
char* strerror(int num)//参数是错误码
这是函数的基本模型,一般会用到errno来判断错误码。要引用头文件<errno.h>
strerror(errno)
写法如上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号