音乐数据中心数仓综合项目
一、数据来源
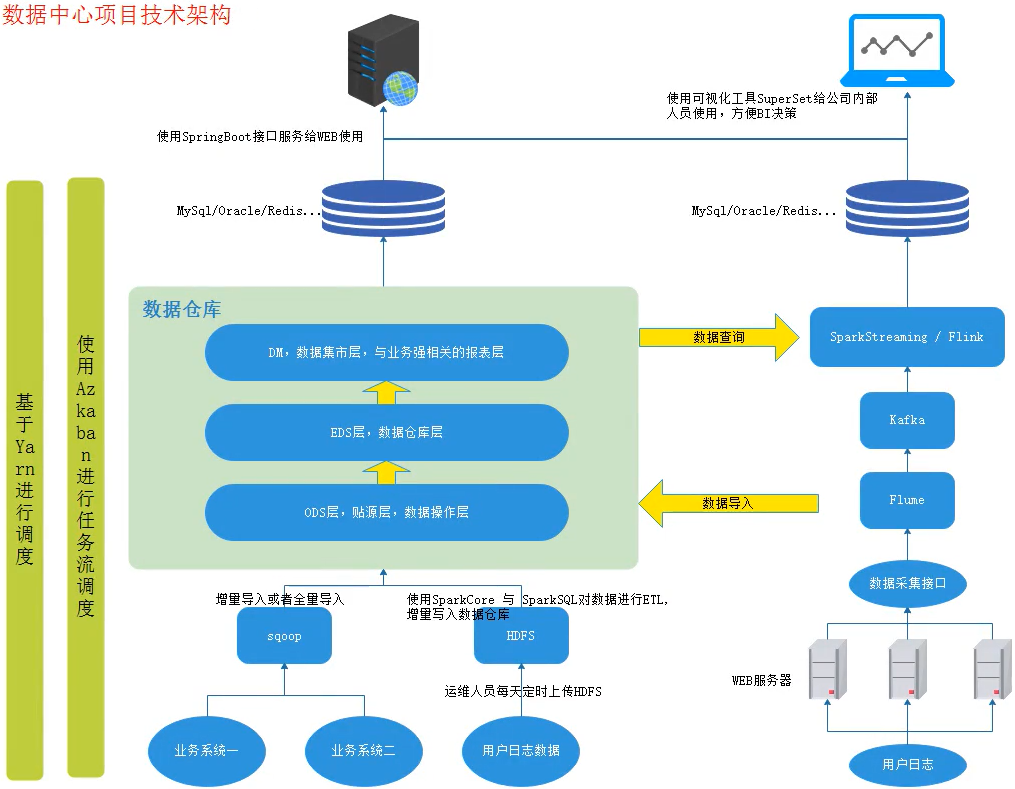
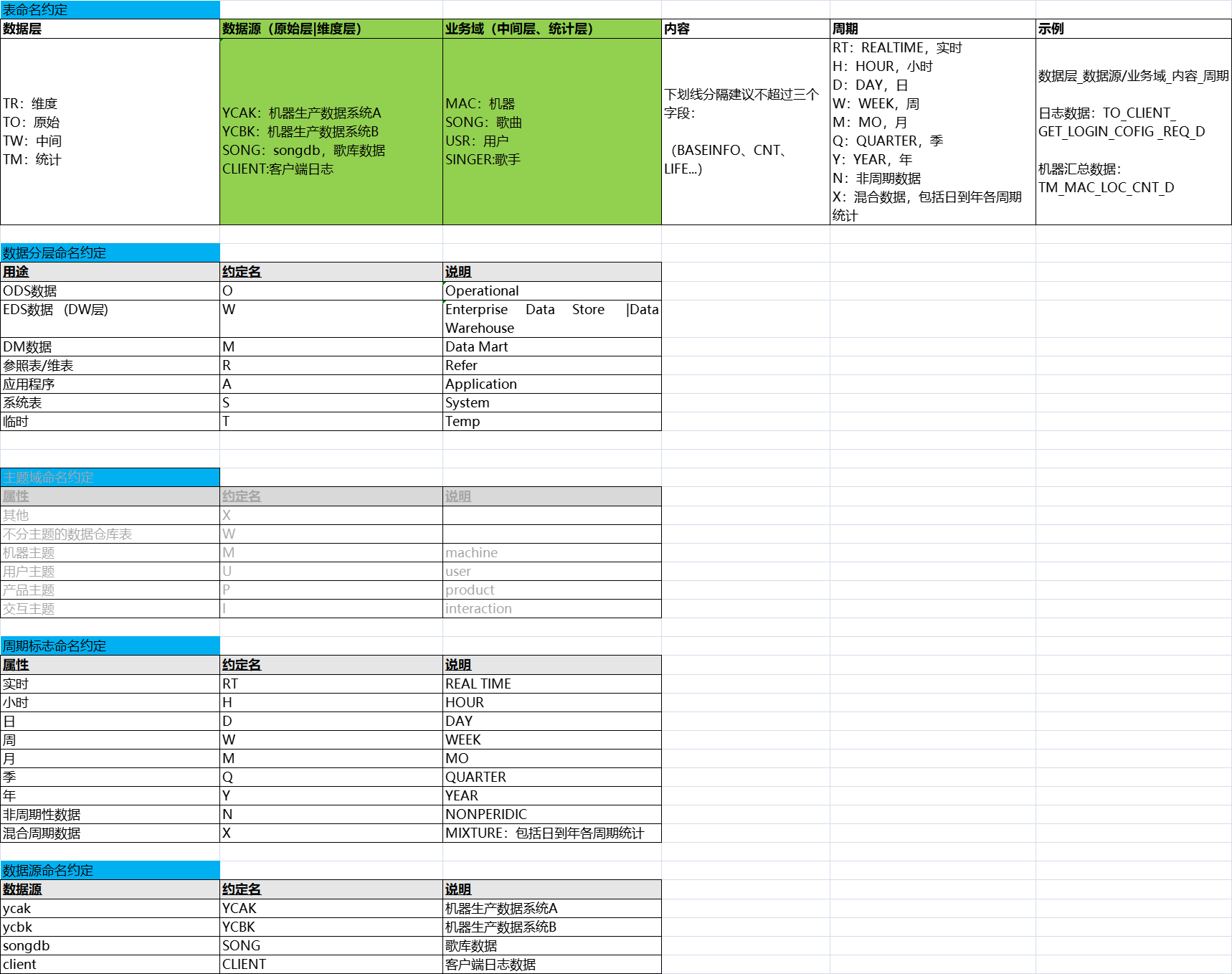
五、业务需求
======第一个业务需求:统计歌曲热度、歌手热度排行 ====== 1日歌曲热度、歌手热度 7日歌曲热度、歌手热度 30日歌曲热度、歌手热度 1日、7日、30日歌曲的点唱数 1日、7日、30日歌曲的点赞数 1日、7日、30日歌曲的点唱用户数 1日、7日、30日歌曲的点唱订单数据 7日、30日歌曲最高点唱、点赞量 1日、7日、30日歌手的点唱数 1日、7日、30日歌手的点赞数 1日、7日、30日歌手的点唱用户数 1日、7日、30日歌手的点唱订单数据 7日、30日歌手最高点唱、点赞量 注意:统计热度借助了微信指数。 ===== 需求分析======= 需要数据: 1).每天用户点播歌曲的日志数据,由运维人员每天上传到HDFS系统中。--数据来源于用户行为日志 2).歌曲基本信息表【歌曲对应歌手信息】--数据来源于原业务系统 ===== 模型表设计 ======= ODS层: TO_CLIENT_SONG_PLAY_OPERATE_REQ_D - 客户端歌曲播放表 TO_SONG_INFO_D - 歌库歌曲表
对ODS中的表数据进行清洗,得到EDS层数据库表
EDS层: TW_SONG_BASEINFO_D - 歌曲基本信息日全量表 TW_SONG_FTUR_D - 歌曲特征日统计 TW_SONG_RSI_D - 歌曲影响力指数日统计 TW_SINGER_RSI_D - 歌手影响力指数日统计 DM层:mysql中 tm_song_rsi -歌曲影响力指数表 tm_singer_rsi -歌手影响力指数表 ====== TW_SONG_FTUR_D 歌曲特征日统计 ===== 1. 当日点唱量 SING_CNT 当日点赞量 SUPP_CNT 当日点唱用户数 USR_CNT 当日点唱订单数 ORDR_CNT SELECT songid , -- 歌曲id count(songid), -- 歌曲当日点唱量 0 as supp_cnt, -- 歌曲当日点赞量 count(distinct uid), -- 当日点唱用户数 count(distinct order_id) --当日点唱订单数 FROM TO_CLIENT_SONG_PLAY_OPERATE_REQ_D WHERE data_dt = 当日日期 GROUP BY songid 2.近七天点唱量 RCT_7_SING_CNT 近七天点赞量 RCT_7_SUPP_CNT 近七天点唱用户数 RCT_7_USR_CNT 近七天点唱订单数 RCT_7_ORDR_CNT SELECT songid , -- 歌曲id count(songid), -- 歌曲7日点唱量 0 as supp_cnt, -- 歌曲7日点赞量 count(distinct uid), -- 7日点唱用户数 count(distinct order_id) --7日点唱订单数 FROM TO_CLIENT_SONG_PLAY_OPERATE_REQ_D WHERE data_dt >= 前7天日期 and data_dt <= 当前天日期 GROUP BY songid 3.近三十天点唱量 RCT_30_SING_CNT 近三十天点赞量 RCT_30_SUPP_CNT 近三十天点唱用户数 RCT_30_USR_CNT 近三十天点唱订单数 RCT_30_ORDR_CNT SELECT songid , -- 歌曲id count(songid), -- 歌曲30日点唱量 0 as supp_cnt, -- 歌曲30日点赞量 count(distinct uid), -- 30日点唱用户数 count(distinct order_id) --30日点唱订单数 FROM TO_CLIENT_SONG_PLAY_OPERATE_REQ_D WHERE data_dt >= 前30天日期 and data_dt <= 当前天日期 GROUP BY songid 4.近七天最高日点唱量 RCT_7_TOP_SING_CNT 近七天最高日点赞量 RCT_7_TOP_SUPP_CNT 近三十天最高日点唱量 RCT_30_TOP_SING_CNT 近三十天最高日点赞量 RCT_30_TOP_SUPP_CNT SELECT NBR, -- 歌曲id max(CASE WHEN DATE_DT >= 前7天日期 THEN SING_CNT ELSE 0 END) as RCT_7_TOP_SING_CNT ,--近七天最高日点唱量 max(CASE WHEN DATE_DT >= 前7天日期 THEN SUPP_CNT ELSE 0 END) as RCT_7_TOP_SUPP_CNT ,--近七天最高日点赞量 max(SING_CNT) as RCT_30_TOP_SING_CNT ,--近三十天最高日点唱量 max(SUPP_CNT) as RCT_30_TOP_SUPP_CNT -- 近三十天最高日点赞量 FROM TW_SONG_FTUR_D WHERE data_dt >= 前30天日期 and data_dt <= 当前天日期 GROUP BY songid ===== 统计歌曲热度 TW_SONG_RSI_D ====== TW_SONG_RSI_D : 周期(1/7/30) PERIOD 歌曲编号 NBR 歌曲名 NAME 近期歌曲热度 RSI 近期歌曲热度排名 RSI_RANK 数据日期 DATA_DT TW_SONG_FTUR_D - 歌曲特征日统计 temp: SELECT NBR,NAME,(xxx) as 1RSI,(xxx) as 7RSI,(xxx) as 30RSI,data_dt FROM TW_SONG_FTUR_D WHERE data_dt = 20201230 统计歌曲1日热度: SELECT "1日" as PERIOD,NBR,NAME,1RSI as RSI,row_number() over(partition by data_dt order by 1RSI desc) as RSI_RANK,DATA_DT FROM temp 统计歌曲7日热度: SELECT "7日" as PERIOD,NBR,NAME,7RSI as RSI,row_number() over(partition by data_dt order by 7RSI desc) as RSI_RANK,DATA_DT FROM temp 统计歌曲30日热度: SELECT "30日" as PERIOD,NBR,NAME,30RSI as RSI,row_number() over(partition by data_dt order by 30RSI desc) as RSI_RANK,DATA_DT FROM temp 以上三个union 得到总结果 ======= 统计歌手热度 TW_SINGER_RSI_D ====== TW_SINGER_RSI_D: 周期 PERIOD 歌手ID SINGER_ID 歌手名称 SINGER_NAME 近期歌手热度 RSI 近期歌手热度排名 RSI_RANK 数据日期 DATA_DT TW_SONG_FTUR_D - 歌曲特征日统计 temp: SELECT SINGER1ID, SINGER1, sum(SING_CNT) as TOTAL_SING_CNT , sum(SUPP_CNT) as TOTAL_SUPP_CNT , sum(RCT_7_SING_CNT) as TOTAL_RCT_7_SING_CNT , sum(RCT_7_SUPP_CNT) as TOTAL_RCT_7_SUPP_CNT , sum(RCT_7_TOP_SING_CNT) as TOTAL_RCT_7_TOP_SING_CNT , sum(RCT_7_TOP_SUPP_CNT) as TOTAL_RCT_7_TOP_SUPP_CNT , sum(RCT_30_SING_CNT) as TOTAL_RCT_30_SING_CNT , sum(RCT_30_SUPP_CNT) as TOTAL_RCT_30_SUPP_CNT , sum(RCT_30_TOP_SING_CNT) as TOTAL_RCT_30_TOP_SING_CNT , sum(RCT_30_RCT_30_ORDR_CNT) as TOTAL_RCT_30_ORDR_CNT FROM TW_SONG_FTUR_D WHERE data_dt = 20201230 GROUP BY SINGER1ID,SINGER1 temp2: SELECT SINGER1ID,SINGER1,(xxx) as 1RSI,(xxx) as 7RSI,(xxx) as 30RSI,data_dt FROM temp 统计歌手1日热度: SELECT "1日" as PERIOD,SINGER1ID as SINGER_ID,SINGER1 as SINGER_NAME, 1RSI as RSI,row_number() over(partition by data_dt order by 1RSI desc) as RSI_RANK FROM temp2 统计歌手7日热度: SELECT "7日" as PERIOD,SINGER1ID as SINGER_ID,SINGER1 as SINGER_NAME, 7RSI as RSI,row_number() over(partition by data_dt order by 7RSI desc) as RSI_RANK FROM temp2 统计歌手30日热度: SELECT "30日" as PERIOD,SINGER1ID as SINGER_ID,SINGER1 as SINGER_NAME, 30RSI as RSI,row_number() over(partition by data_dt order by 30RSI desc) as RSI_RANK FROM temp2 以上三个union 得到总结果
1、用户上报的日志数据 currentday_clientlog.tar.gz 解压之后的部分数据格式如下:(中间用&间隔)
1 1575302350&99712&MINIK_CLIENT_ADVERTISEMENT_RECORD&{"src_verison": 2546, "mid": 99712, "adv_type": 4, "src_type": 2546, "uid": 0, "session_id": 48565, "event_id": 1, "time": 1575302349}&3.0.1.15&2.4.4.30 2 1575302350&89316&MINIK_CLIENT_ADVERTISEMENT_RECORD&{"src_verison": 2565, "mid": 89316, "adv_type": 4, "src_type": 2565, "uid": 0, "session_id": 33762, "event_id": 1, "time": 1575302348}&3.0.1.12&2.4.4.26 3 1575302350&54398&MINIK_CLIENT_ADVERTISEMENT_RECORD&{"src_verison": 2546, "mid": 54398, "adv_type": 4, "src_type": 2546, "uid": 0, "session_id": 31432, "event_id": 1, "time": 1575302349}&3.0.1.14&2.4.4.30 4 1575302350&49120&MINIK_CLIENT_ADVERTISEMENT_RECORD&{"src_verison": 2546, "mid": 49120, "adv_type": 4, "src_type": 2546, "uid": 0, "session_id": 25078, "event_id": 1, "time": 1575302350}&3.0.1.15&2.4.4.30 5 1575302350&57563&MINIK_CLIENT_ADVERTISEMENT_RECORD&{"src_verison": 2571, "mid": 57563, "adv_type": 4, "src_type": 2571, "uid": 0, "session_id": 13577, "event_id": 1, "time": 1575302349}&3.0.1.15&2.4.4.30 6 1575302350&91764&MINIK_CLIENT_ADVERTISEMENT_RECORD&{"src_verison": 2546, "mid": 91764, "adv_type": 4, "src_type": 2546, "uid": 0, "session_id": 7075, "event_id": 1, "time": 1575302348}&3.0.1.12&2.4.4.26 7 1575302351&99695&MINIK_CLIENT_ADVERTISEMENT_RECORD&{"src_verison": 2558, "mid": 99695, "adv_type": 4, "src_type": 2558, "uid": 0, "session_id": 27410, "event_id": 1, "time": 1575302350}&3.0.1.15&2.4.4.30 8 1575302351&98105&MINIK_CLIENT_ADVERTISEMENT_RECORD&{"src_verison": 1619, "mid": 98105, "adv_type": 4, "src_type": 1619, "uid": 0, "session_id": 1553, "event_id": 1, "time": 1575302349}&3.0.1.15&2.4.4.30 9 1575302351&95059&MINIK_CLIENT_ADVERTISEMENT_RECORD&{"src_verison": 2525, "mid": 95059, "adv_type": 2, "src_type": 0, "uid": 49915629, "session_id": 28419, "event_id": 1, "time": 1575302350}&3.0.1.15&2.4.4.30 10 1575302351&1958&MINIK_CLIENT_ADVERTISEMENT_RECORD&{"src_verison": 2546, "mid": 1958, "adv_type": 4, "src_type": 2546, "uid": 0, "session_id": 60656, "event_id": 1, "time": 1575302350}&3.0.1.15&2.4.4.30 11 1575302351&52166&MINIK_CLIENT_ADVERTISEMENT_RECORD&{"src_verison": 2565, "mid": 52166, "adv_type": 4, "src_type": 2565, "uid": 0, "session_id": 42636, "event_id": 1, "time": 1575302350}&3.0.1.15&2.4.4.30 12 1575302351&91267&MINIK_CLIENT_ADVERTISEMENT_RECORD&{"src_verison": 2565, "mid": 91267, "adv_type": 4, "src_type": 2565, "uid": 0, "session_id": 81201, "event_id": 1, "time": 1575302349}&3.0.1.14&2.4.4.30 ............
2、歌曲基本信息表【歌曲对应歌手信息】中的数据来源于原业务系统数据库songdb。
数据库表song的建表sql及部分数据如下:(对应sql文件为 songdb.sql)
-- ----------------------------
-- Table structure for song
-- ----------------------------
DROP TABLE IF EXISTS `song`;
CREATE TABLE `song` (
`source_id` varchar(100) NOT NULL COMMENT '主键ID',
`name` varchar(100) DEFAULT NULL COMMENT '歌曲名字',
`other_name` varchar(100) DEFAULT NULL COMMENT '其他名字',
`source` int(11) DEFAULT NULL COMMENT '来源',
`album` varchar(100) DEFAULT NULL COMMENT '所属专辑',
`product` varchar(100) DEFAULT NULL COMMENT '发行公司',
`language` varchar(100) DEFAULT NULL COMMENT '歌曲语言',
`video_format` varchar(100) DEFAULT NULL COMMENT '视频风格',
`duration` int(11) DEFAULT NULL COMMENT '时长',
`singer_info` varchar(100) DEFAULT NULL COMMENT '歌手信息',
`post_time` varchar(100) DEFAULT NULL COMMENT '发行时间',
`pinyin_first` varchar(100) DEFAULT NULL COMMENT '歌曲首字母',
`pinyin` varchar(100) DEFAULT NULL COMMENT '歌曲全拼',
`singing_type` int(11) DEFAULT NULL COMMENT '演唱类型',
`original_singer` varchar(100) DEFAULT NULL COMMENT '原唱歌手',
`lyricist` varchar(100) DEFAULT NULL COMMENT '填词',
`composer` varchar(100) DEFAULT NULL COMMENT '作曲',
`bpm` int(11) DEFAULT NULL COMMENT 'BPM值',
`star_level` int(11) DEFAULT NULL COMMENT '星级',
`video_quality` int(11) DEFAULT NULL COMMENT '视频画质',
`video_make` int(11) DEFAULT NULL COMMENT '视频制作方式',
`video_feature` int(11) DEFAULT NULL COMMENT '视频画面特征',
`lyric_feature` int(11) DEFAULT NULL COMMENT '歌词字母特点',
`Image_quality` int(11) DEFAULT NULL COMMENT '画质评价',
`subtitles_type` int(11) DEFAULT NULL COMMENT '字幕类型',
`audio_format` int(11) DEFAULT NULL COMMENT '音频格式',
`original_sound_quality` int(11) DEFAULT NULL COMMENT '原唱音质',
`original_track` int(11) DEFAULT NULL COMMENT '音轨',
`original_track_vol` int(11) DEFAULT NULL COMMENT '原唱音量',
`accompany_version` int(11) DEFAULT NULL COMMENT '伴唱版本',
`accompany_quality` int(11) DEFAULT NULL COMMENT '伴唱音质',
`acc_track_vol` int(11) DEFAULT NULL COMMENT '伴唱音量',
`accompany_track` int(11) DEFAULT NULL COMMENT '伴唱音轨',
`width` int(11) DEFAULT NULL COMMENT '视频分辨率W',
`height` int(11) DEFAULT NULL COMMENT '视频分辨率H',
`video_resolution` int(11) DEFAULT NULL COMMENT '视频分辨率',
`song_version` int(11) DEFAULT NULL COMMENT '编曲版本',
`authorized_company` varchar(100) DEFAULT NULL COMMENT '授权公司',
`status` int(11) DEFAULT NULL COMMENT '状态',
`publish_to` varchar(100) DEFAULT NULL COMMENT '产品类型',
PRIMARY KEY (`source_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of song
-- ----------------------------
INSERT INTO `song` VALUES ('10000001', 'Footprints In The Sand(live)', '沙滩上的脚印(live)', '1', '[{\"name\":\"《中国好声音第二季 第十五期》\",\"id\":\"5ce5ffdb2a0b8b6b4707263e\"}]', '', 'E', 'X', '242', '[{\"name\":\"萱萱\",\"id\":\"20342\"}]', '1.3810752E+12', 'FITSSTSDJYL', 'footprintsinthesandshatanshangdejiaoyinlive', '2', '[{\"name\":\"Leona Lewis\",\"id\":\"2734\"}]', '[{\"name\":\"Richard Page\",\"id\":\"1025472\"},{\"name\":\" Per Magnusson\",\"id\":\"1025473\"}]', '[{\"name\":\"David Kreuger\",\"id\":\"1025474\"},{\"name\":\"Simon Cowell\",\"id\":\"1025475\"}]', '0', '0', '2', '0', '0', '0', '0', '1', '3', '0', '1', '50', '2', '1', '50', '0', '1920', '1080', '1', '1', '', '3', '[2.0,8.0]');
INSERT INTO `song` VALUES ('10000002', '不许你注定一人', '', '1', '[{\"name\":\"《不许你注定一人》\",\"id\":\"5c19b89450057d3b20232f7a\"}]', '', 'C', 'M', '305', '[{\"name\":\"Dear Jane\",\"id\":\"1187\"}]', '1.3819392E+12', 'BXNZDYR', 'buxunizhudingyiren', '1', '[]', '[{\"name\":\" Howie@Dear Jane\",\"id\":\"1021658\"}]', '[{\"name\":\" Howie@Dear Jane\",\"id\":\"1021658\"}]', '0', '0', '1', '0', '0', '0', '0', '1', '3', '0', '1', '50', '1', '1', '50', '0', '1920', '1080', '1', '1', '', '3', '[8.0,2.0,9]');
INSERT INTO `song` VALUES ('10000003', '爱上你的美(live)', '', '1', '[{\"name\":\"《最美和声第一季 第13期》\",\"id\":\"5db140bda1b80f5bc4e8960f\"}]', '', 'M', 'M', '220', '[{\"name\":\"胡海泉\",\"id\":\"10306\"},{\"name\":\"丁于\",\"id\":\"6311\"}]', '1.3815072E+12', 'ASNDML', 'aishangnidemeilive', '1', '[]', '[{\"name\":\"胡海泉\",\"id\":\"1027408\"}]', '[{\"name\":\"Bob Crewe\",\"id\":\"1021234\"},{\"name\":\"Bob Gaudio\",\"id\":\"1021235\"}]', '0', '0', '2', '0', '0', '0', '0', '1', '3', '0', '1', '50', '1', '1', '50', '0', '1920', '1080', '1', '2', '', '3', '[2.0,8.0]');
INSERT INTO `song` VALUES ('10000004', '翅膀', '', '1', '[{\"name\":\"《最美和声 第13期》\",\"id\":{\"$oid\":\"5c19ae0e50057d3b202313e3\"}}]', '蓝色火焰', 'M', 'M', '196', '[{\"name\":\"胡海泉\",\"id\":\"10306\"},{\"name\":\"田斯斯\",\"id\":\"20343\"}]', '2013-10-31 00:00:00', 'CB', 'chibang', '0', '', '', '', '0', '0', '2', '0', '0', '0', '0', '0', '0', '0', '1', '50', '0', '0', '50', '0', '1920', '1080', '1', '0', '', '1', '[2.0,8.0]');
INSERT INTO `song` VALUES ('10000005', 'Baby I Love You', '', '1', '[{\"name\":\"《阿里郎》\",\"id\":\"5c19b20850057d3b20231e48\"}]', '', 'M', 'M', '194', '[{\"name\":\"金贵晟\",\"id\":\"20245\"}]', '1.3783968E+12', 'BILY', 'babyiloveyou', '1', '[]', '[{\"name\":\"代岳冬\",\"id\":\"1037983\"}]', '[{\"name\":\"金贵晟\",\"id\":\"20245\"}]', '0', '0', '1', '0', '0', '0', '0', '1', '3', '0', '1', '50', '1', '2', '50', '0', '1920', '1080', '1', '1', '', '3', '[2.0,8.0]');
INSERT INTO `song` VALUES ('10000007', 'My Little Friend', '', '1', '[{\"name\":\"《Say The Words》\",\"id\":\"5c19a78350057d3b2023025d\"}]', '', 'E', 'S', '340', '[{\"name\":\"曲婉婷\",\"id\":\"16277\"}]', '1.3569696E+12', 'MLF', 'mylittlefriend', '1', '[]', '[{\"name\":\"曲婉婷\",\"id\":\"16277\"}]', '[{\"name\":\"曲婉婷\",\"id\":\"16277\"}]', '0', '0', '1', '0', '0', '0', '0', '1', '3', '0', '1', '50', '1', '2', '50', '0', '1920', '1080', '1', '1', '', '3', '[2.0,8.0]');
INSERT INTO `song` VALUES ('10000008', 'X', '', '1', '[{\"name\":\"《痞得胖》\",\"id\":\"5c19adf550057d3b2023139f\"}]', '禾广娱乐', 'M', 'M', '328', '[{\"name\":\"怕胖团\",\"id\":\"20474\"}]', '2013-10-31 00:00:00', 'X', '', '1', '[]', '[{\"name\":\"闪亮\",\"id\":\"1020755\"}]', '[{\"name\":\"闪亮\",\"id\":\"1020755\"}]', '92', '5', '1', '0', '0', '0', '0', '1', '3', '0', '1', '50', '0', '1', '50', '2', '1920', '1080', '1', '0', '', '1', '[8.0,2.0,9]');
INSERT INTO `song` VALUES ('10000009', 'Melody(Live)', '', '1', '[{\"name\":\"《中国好声音第二季 第十五期》\",\"id\":\"5ce5ffdb2a0b8b6b4707263e\"}]', '', 'M', 'X', '205', '[{\"name\":\"萱萱\",\"id\":\"20342\"}]', '1.3810752E+12', 'ML', 'melodylive', '2', '[{\"name\":\" 陶喆 \",\"id\":\"1026474\"}]', '[{\"name\":\"娃娃\",\"id\":\"1023192\"},{\"name\":\" 陶喆 \",\"id\":\"1026474\"}]', '[{\"name\":\" 陶喆 \",\"id\":\"1026474\"}]', '0', '0', '2', '0', '0', '0', '0', '1', '3', '0', '1', '50', '2', '1', '50', '0', '1920', '1080', '1', '2', '', '3', '[2.0,8.0]');
INSERT INTO `song` VALUES ('10000010', '到底是哪个混蛋敢欺负我的朋友', '', '1', '《LANDIVA》', '', 'M', 'M', '229', '[{\"name\":\"蓝心湄\",\"id\":\"15575\"}]', '2013-11-01 00:00:00', 'DDSNGHDGQFWDPY', 'daodishinagehundanganqifuwodepengyou', '0', '', '', '', '0', '0', '1', '0', '0', '0', '0', '0', '0', '0', '1', '50', '0', '0', '49', '0', '1920', '1080', '1', '0', '', '1', '[2.0,8.0]');
INSERT INTO `song` VALUES ('10000011', '爱的海洋', '', '1', '[{\"name\":\"《Say The Words 我为你歌唱》\",\"id\":\"5c19ac9050057d3b20230fe3\"}]', '', 'M', 'M', '230', '[{\"name\":\"曲婉婷\",\"id\":\"16277\"}]', '1.3820256E+12', 'ADHY', 'aidehaiyang', '1', '[]', '[{\"name\":\"曲婉婷\",\"id\":\"16277\"}]', '[{\"name\":\"曲婉婷\",\"id\":\"16277\"}]', '0', '0', '1', '0', '0', '0', '0', '1', '3', '0', '1', '50', '1', '1', '50', '0', '1920', '1080', '1', '1', '', '3', '[8.0,2.0,9]');
INSERT INTO `song` VALUES ('10000012', '爱洗虾米', '', '1', '[{\"name\":\"《旺得福》\",\"id\":{\"$oid\":\"5c19a6c550057d3b20230062\"}}]', '亚神音乐', 'T', 'M', '273', '[{\"name\":\"旺福\",\"id\":\"9300\"}]', '2013-11-01 00:00:00', 'AXXM', 'aixixiami', '0', '', '', '', '0', '0', '2', '0', '0', '0', '0', '0', '0', '0', '1', '50', '0', '0', '50', '0', '1920', '1080', '1', '0', '', '1', '[2.0]');
INSERT INTO `song` VALUES ('10000013', '爱投罗网', '', '1', '[{\"name\":\"《狮子吼》\",\"id\":\"5c19b6a050057d3b20232a58\"}]', '', 'M', 'M', '319', '[{\"name\":\"罗志祥\",\"id\":\"1021663\"}]', '1.38384E+12', 'ATLW', 'aitouluowang', '1', '[]', '[{\"name\":\"李宗恩\",\"id\":\"1021817\"}]', '[{\"name\":\"Drew Ryan Scott\",\"id\":\"1027900\"},{\"name\":\"Jacim Persson\",\"id\":\"1031575\"}]', '0', '0', '1', '0', '0', '0', '0', '1', '3', '0', '1', '50', '1', '1', '50', '0', '1920', '1080', '1', '1', '', '3', '[8.0,2.0,9]');
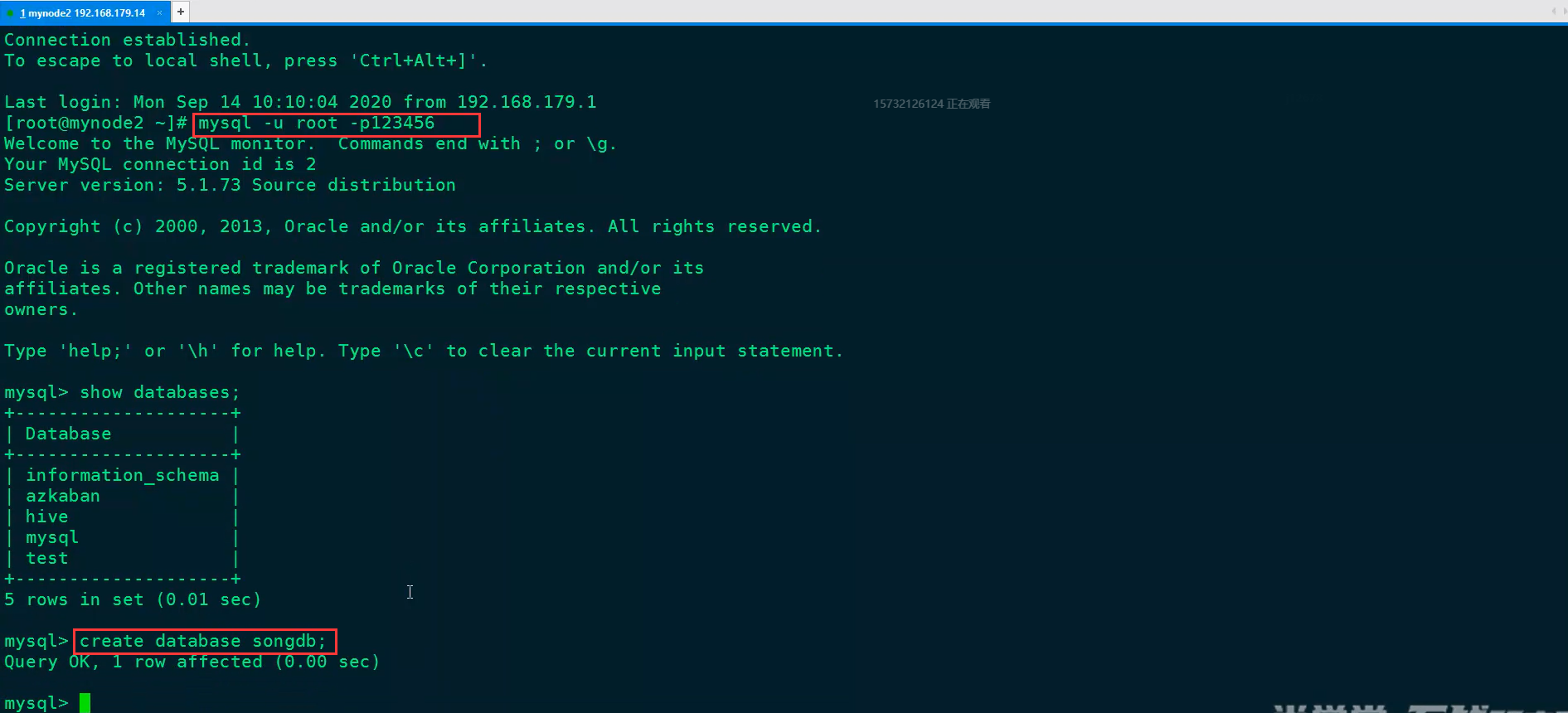
将数据导入到mysql数据库的步骤:
(1)打开xshell,连接mysql数据库,创建songdb数据库
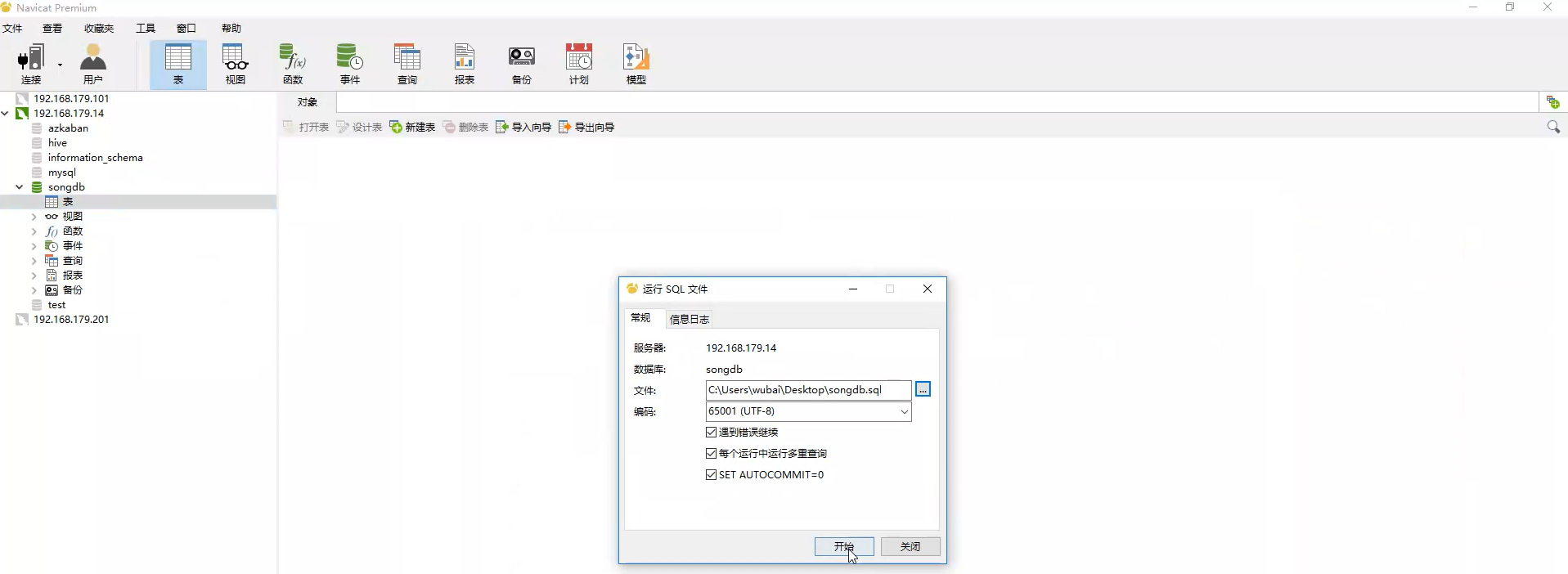
(2)打开Navigate,连接到192.168.179.14节点,运行sql文件songdb.sql
(3)查看导入结果
表数据如下:
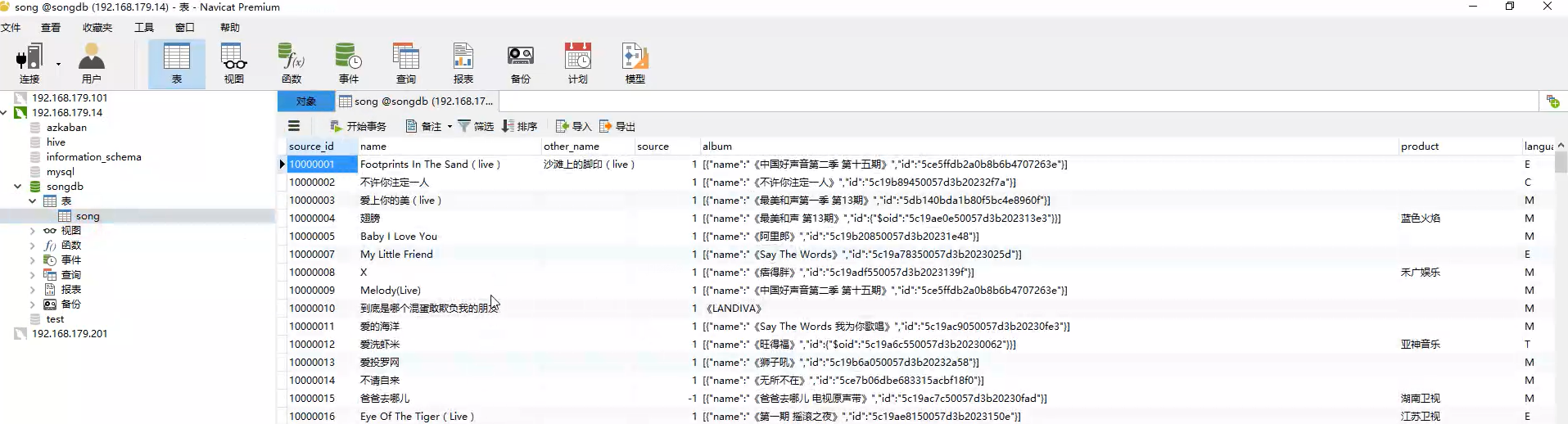
表结构如下:

数据库表song里面的数据会导入到ODS层中的TO_SONG_INFO_D表中,TO_SONG_INFO_D表信息如下:

EDS层对应的表结构如下
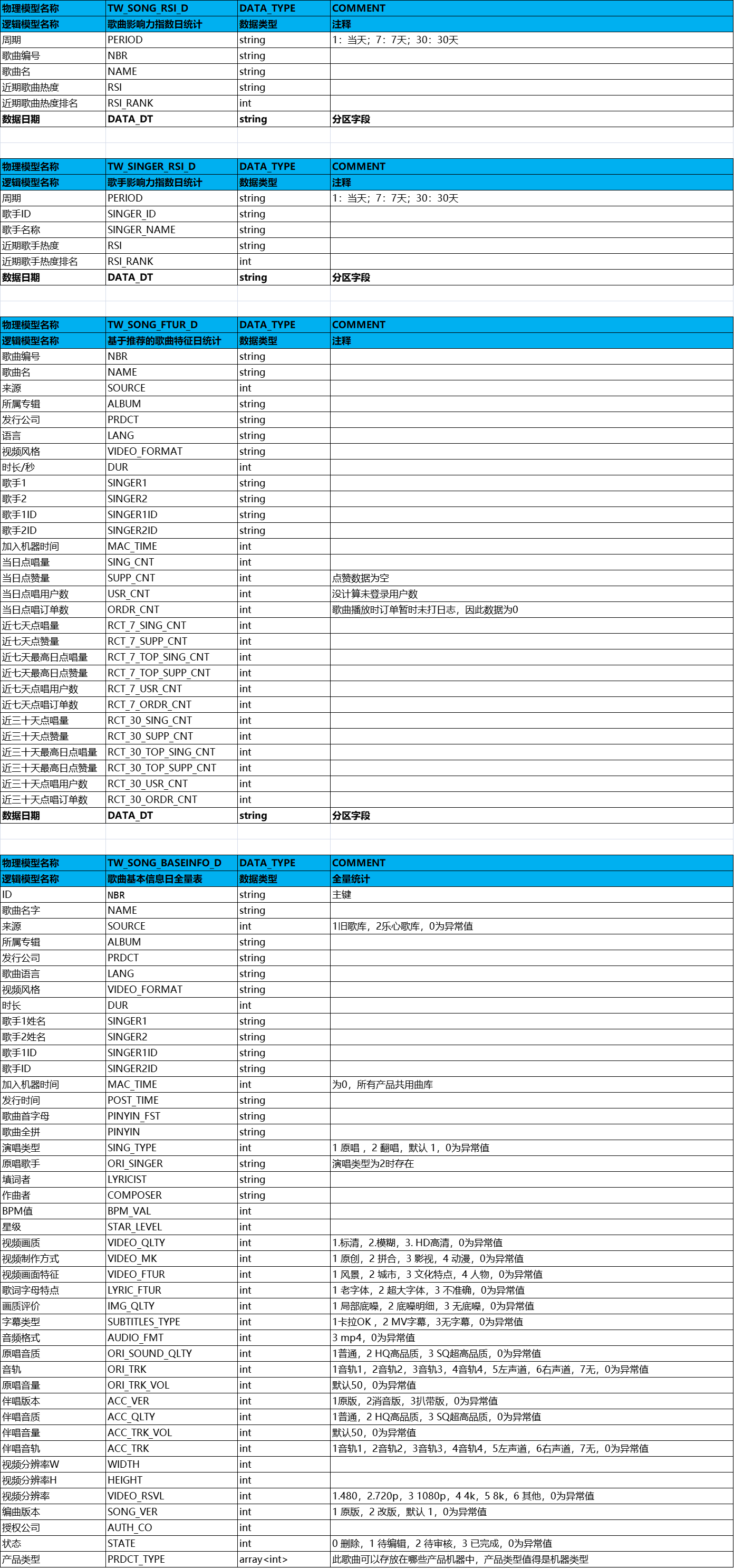
3、数据仓库分层及数据流转处理流程

CREATE EXTERNAL TABLE IF NOT EXISTS `TO_CLIENT_SONG_PLAY_OPERATE_REQ_D`(
`SONGID` string,
`MID` string,
`OPTRATE_TYPE` string,
`UID` string,
`CONSUME_TYPE` string,
`DUR_TIME` string,
`SESSION_ID` string,
`SONGNAME` string,
`PKG_ID` string,
`ORDER_ID` string
)
partitioned by (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TO_CLIENT_SONG_PLAY_OPERATE_REQ_D';
CREATE EXTERNAL TABLE `TO_SONG_INFO_D`(
`NBR` string,
`NAME` string,
`OTHER_NAME` string,
`SOURCE` int,
`ALBUM` string,
`PRDCT` string,
`LANG` string,
`VIDEO_FORMAT` string,
`DUR` int,
`SINGER_INFO` string,
`POST_TIME` string,
`PINYIN_FST` string,
`PINYIN` string,
`SING_TYPE` int,
`ORI_SINGER` string,
`LYRICIST` string,
`COMPOSER` string,
`BPM_VAL` int,
`STAR_LEVEL` int,
`VIDEO_QLTY` int,
`VIDEO_MK` int,
`VIDEO_FTUR` int,
`LYRIC_FTUR` int,
`IMG_QLTY` int,
`SUBTITLES_TYPE` int,
`AUDIO_FMT` int,
`ORI_SOUND_QLTY` int,
`ORI_TRK` int,
`ORI_TRK_VOL` int,
`ACC_VER` int,
`ACC_QLTY` int,
`ACC_TRK_VOL` int,
`ACC_TRK` int,
`WIDTH` int,
`HEIGHT` int,
`VIDEO_RSVL` int,
`SONG_VER` int,
`AUTH_CO` string,
`STATE` int,
`PRDCT_TYPE` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TO_SONG_INFO_D';
CREATE EXTERNAL TABLE `TW_SONG_BASEINFO_D`( `NBR` string, `NAME` string, `SOURCE` int, `ALBUM` string, `PRDCT` string, `LANG` string, `VIDEO_FORMAT` string, `DUR` int, `SINGER1` string, `SINGER2` string, `SINGER1ID` string, `SINGER2ID` string, `MAC_TIME` int, `POST_TIME` string, `PINYIN_FST` string, `PINYIN` string, `SING_TYPE` int, `ORI_SINGER` string, `LYRICIST` string, `COMPOSER` string, `BPM_VAL` int, `STAR_LEVEL` int, `VIDEO_QLTY` int, `VIDEO_MK` int, `VIDEO_FTUR` int, `LYRIC_FTUR` int, `IMG_QLTY` int, `SUBTITLES_TYPE` int, `AUDIO_FMT` int, `ORI_SOUND_QLTY` int, `ORI_TRK` int, `ORI_TRK_VOL` int, `ACC_VER` int, `ACC_QLTY` int, `ACC_TRK_VOL` int, `ACC_TRK` int, `WIDTH` int, `HEIGHT` int, `VIDEO_RSVL` int, `SONG_VER` int, `AUTH_CO` string, `STATE` int, `PRDCT_TYPE` array<string> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS PARQUET LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TW_SONG_BASEINFO_D';
CREATE EXTERNAL TABLE `TW_SONG_FTUR_D`(
`NBR` string,
`NAME` string,
`SOURCE` int,
`ALBUM` string,
`PRDCT` string,
`LANG` string,
`VIDEO_FORMAT` string,
`DUR` int,
`SINGER1` string,
`SINGER2` string,
`SINGER1ID` string,
`SINGER2ID` string,
`MAC_TIME` int,
`SING_CNT` int,
`SUPP_CNT` int,
`USR_CNT` int,
`ORDR_CNT` int,
`RCT_7_SING_CNT` int,
`RCT_7_SUPP_CNT` int,
`RCT_7_TOP_SING_CNT` int,
`RCT_7_TOP_SUPP_CNT` int,
`RCT_7_USR_CNT` int,
`RCT_7_ORDR_CNT` int,
`RCT_30_SING_CNT` int,
`RCT_30_SUPP_CNT` int,
`RCT_30_TOP_SING_CNT` int,
`RCT_30_TOP_SUPP_CNT` int,
`RCT_30_USR_CNT` int,
`RCT_30_ORDR_CNT` int
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TW_SONG_FTUR_D';
CREATE EXTERNAL TABLE `TW_SINGER_RSI_D`(
`PERIOD` string,
`SINGER_ID` string,
`SINGER_NAME` string,
`RSI` string,
`RSI_RANK` int
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TW_SINGER_RSI_D';
CREATE EXTERNAL TABLE `TW_SONG_RSI_D`(
`PERIOD` string,
`NBR` string,
`NAME` string,
`RSI` string,
`RSI_RANK` int
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TW_SONG_RSI_D';

4、项目编码实现
(1)application.conf配置文件
#是否在本地运行 local.run="true" #hive uris hive.metastore.uris="thrift://192.168.179.13:9083" #数据在Hive的哪个库中 hive.database="default" #运维人员上传 clientlog 日志数据所在的HDFS路径 clientlog.hdfs.path="hdfs://mycluster/logdata" #DM 层 结果保存在MySQL中的地址和库 mysql.url = "jdbc:mysql://192.168.179.14:3306/songresult?useUnicode=true&characterEncoding=UTF-8" #mysql登录账号 mysql.user = "root" #mysql登录账号密码 mysql.password = "123456" #kafka 集群 kafka.cluster = "192.168.179.13:9092,192.168.179.14:9092,192.168.179.15:9092" #kafka log topic kafka.userloginInfo.topic = "logtopic" #kafka userplaysonglog topic kafka.userplaysong.topic = "songinfo" #redis host -redis 节点 redis.host = "mynode4" #redis port -redis的端口 redis.port = "6379" #redis offset db -维护offset的redis库 redis.offset.db = "6" #result redis db -结果存放在Redis中的库 redis.db = "7"
(2)ConfigUtils文件
package com.bjsxt.scala.musicproject.common import com.typesafe.config.{Config, ConfigFactory} object ConfigUtils { /** * ConfigFactory.load() 默认加载classpath下的application.conf,application.json和application.properties文件。 * */ lazy val load: Config = ConfigFactory.load() val LOCAL_RUN = load.getBoolean("local.run") val HIVE_METASTORE_URIS = load.getString("hive.metastore.uris") val HIVE_DATABASE = load.getString("hive.database") val HDFS_CLIENT_LOG_PATH = load.getString("clientlog.hdfs.path") val MYSQL_URL = load.getString("mysql.url") val MYSQL_USER = load.getString("mysql.user") val MYSQL_PASSWORD = load.getString("mysql.password") val TOPIC = load.getString("kafka.userloginInfo.topic") val USER_PLAY_SONG_TOPIC = load.getString("kafka.userplaysong.topic") val KAFKA_BROKERS = load.getString("kafka.cluster") val REDIS_HOST = load.getString("redis.host") val REDIS_PORT = load.getInt("redis.port") val REDIS_OFFSET_DB = load.getInt("redis.offset.db") val REDIS_DB = load.getInt("redis.db") }
(3)生成TO_CLIENT_SONG_PLAY_OPERATE_REQ_D客户端歌曲播放表中数据,并保存到Hive对应的路径上
1)编码实现
ProduceClientLog类代码:
package com.bjsxt.scala.musicproject.ods
import com.alibaba.fastjson.{JSON, JSONObject}
import com.bjsxt.scala.musicproject.base.PairRDDMultipleTextOutputFormat
import com.bjsxt.scala.musicproject.common.ConfigUtils
import org.apache.spark.{HashPartitioner, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* 读取 运维人员每天上传到服务器上的客户端日志,进行解析,并加载到 ODS层 的表
* 加载的ODS表如下:
*
* 注意:运行此类需要指定参数是 指定当前日期,格式:20201231 ,
* 第二个参数是指定对应的日志保存的目录,例如:hdfs://mycluster/logdata/currentday_clientlog.tar.gz ,
* 本地直接指定:./MusicProject/data/currentday_clientlog.tar.gz
*/
object ProduceClientLog {
private val localrun: Boolean = ConfigUtils.LOCAL_RUN
private val hiveMetaStoreUris = ConfigUtils.HIVE_METASTORE_URIS
private val hiveDataBase = ConfigUtils.HIVE_DATABASE
private var sparkSession : SparkSession = _
private var sc: SparkContext = _
private val hdfsclientlogpath : String = ConfigUtils.HDFS_CLIENT_LOG_PATH
private var clientLogInfos : RDD[String] = _
def main(args: Array[String]): Unit = {
/**
* 先判断有没有传递一个参数
* 指定当前log数据的日期时间 格式:20201231
* 2.指定当前log的上传路径:例如 : ./MusicProject/data/currentday_clientlog.tar.gz
*/
if(args.length<1){
println(s"需要指定 数据日期")
System.exit(1)
}
val logDate = args(0) // 获取日期参数,日期格式 : 年月日 20201231
if(localrun){
sparkSession = SparkSession.builder()
.master("local")
.appName("ProduceClientLog")
.config("hive.metastore.uris",hiveMetaStoreUris).enableHiveSupport() //配置hiveMetaStoreUris并开启Hive支持
.getOrCreate()
sc = sparkSession.sparkContext
clientLogInfos = sc.textFile("./MusicProject/data/currentday_clientlog.tar.gz")
}else{
sparkSession = SparkSession.builder().appName("ProduceClientLog").enableHiveSupport().getOrCreate()
sc = sparkSession.sparkContext
clientLogInfos = sc.textFile(s"${hdfsclientlogpath}/currentday_clientlog.tar.gz")
}
//组织K,V格式的数据 : (客户端请求类型,对应的info信息)
val tableNameAndInfos = clientLogInfos.map(line => line.split("&"))
.filter(item => item.length == 6) //判断日志类型是否完整
.map(line => (line(2), line(3)))
//获取当日出现的所有的“请求类型”
//val allTableNames = tableNameAndInfos.keys.distinct().collect()
//转换数据,将数据分别以表名的方式存储在某个路径中
tableNameAndInfos.map(tp=>{
val tableName = tp._1//客户端请求类型
val tableInfos = tp._2//请求的json string
if("MINIK_CLIENT_SONG_PLAY_OPERATE_REQ".equals(tableName)){
val jsonObject: JSONObject = JSON.parseObject(tableInfos)
val songid = jsonObject.getString("songid") //歌曲ID
val mid = jsonObject.getString("mid") //机器ID
val optrateType = jsonObject.getString("optrate_type") //0:点歌, 1:切歌,2:歌曲开始播放,3:歌曲播放完成,4:录音试听开始,5:录音试听切歌,6:录音试听完成
val uid = jsonObject.getString("uid") //用户ID(无用户则为0)
val consumeType = jsonObject.getString("consume_type")//消费类型:0免费;1付费
val durTime = jsonObject.getString("dur_time") //总时长单位秒(operate_type:0时此值为0)
val sessionId = jsonObject.getString("session_id") //局数ID
val songName = jsonObject.getString("songname") //歌曲名
val pkgId = jsonObject.getString("pkg_id")//套餐ID类型
val orderId = jsonObject.getString("order_id") //订单号
(tableName,songid+"\t"+mid+"\t"+optrateType+"\t"+uid+"\t"+consumeType+"\t"+durTime+"\t"+sessionId+"\t"+songName+"\t"+pkgId+"\t"+orderId) //返回K,V格式的数据
}else{
//将其他表的infos 信息直接以json格式保存到目录中
tp
}
}).saveAsHadoopFile( //保存到hadoop
s"${hdfsclientlogpath}/all_client_tables/${logDate}", //指定保存到HDFS哪个路径
classOf[String],//指定key的格式
classOf[String],//指定value的格式
classOf[PairRDDMultipleTextOutputFormat]//指定按照什么样的格式化类往外保存数据
)
/**
* 在Hive中创建 ODS层的 TO_CLIENT_SONG_PLAY_OPERATE_REQ_D 表,可以在hive中用命令创建,不存在则创建,存在则忽略
*/
sparkSession.sql(s"use $hiveDataBase ") //设置使用Hive的哪个库
sparkSession.sql(
"""
|CREATE EXTERNAL TABLE IF NOT EXISTS `TO_CLIENT_SONG_PLAY_OPERATE_REQ_D`(
| `SONGID` string, --歌曲ID
| `MID` string, --机器ID
| `OPTRATE_TYPE` string, --操作类型
| `UID` string, --用户ID
| `CONSUME_TYPE` string, --消费类型
| `DUR_TIME` string, --时长
| `SESSION_ID` string, --sessionID
| `SONGNAME` string, --歌曲名称
| `PKG_ID` string, --套餐ID
| `ORDER_ID` string --订单ID
|)
|partitioned by (data_dt string)
|ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
|LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TO_CLIENT_SONG_PLAY_OPERATE_REQ_D'
""".stripMargin)
/* 把指定的hdfs路径中的数据加载到指定的hive表中*/
sparkSession.sql(
s"""
| load data inpath
| '${hdfsclientlogpath}/all_client_tables/${logDate}/MINIK_CLIENT_SONG_PLAY_OPERATE_REQ'
| into table TO_CLIENT_SONG_PLAY_OPERATE_REQ_D partition (data_dt='${logDate}') //指定分区为logDate
""".stripMargin)
println("**** all finished ****")
}
}
PairRDDMultipleTextOutputFormat类代码
package com.bjsxt.scala.musicproject.base
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat
class PairRDDMultipleTextOutputFormat extends MultipleTextOutputFormat[Any, Any] {
//1)文件名:根据key和value自定义输出文件名。 name:对应的part-0001文件名
override def generateFileNameForKeyValue(key: Any, value: Any, name: String): String ={
val fileName=key.asInstanceOf[String]
fileName
}
//2)文件内容:默认同时输出key和value。这里指定不输出key。
override def generateActualKey(key: Any, value: Any): String = {
null
}
}
2)在节点上启动hive metastore,并运行代码
设置192.168.179.13为Hive的服务端,192.168.179.15为Hive的客户端
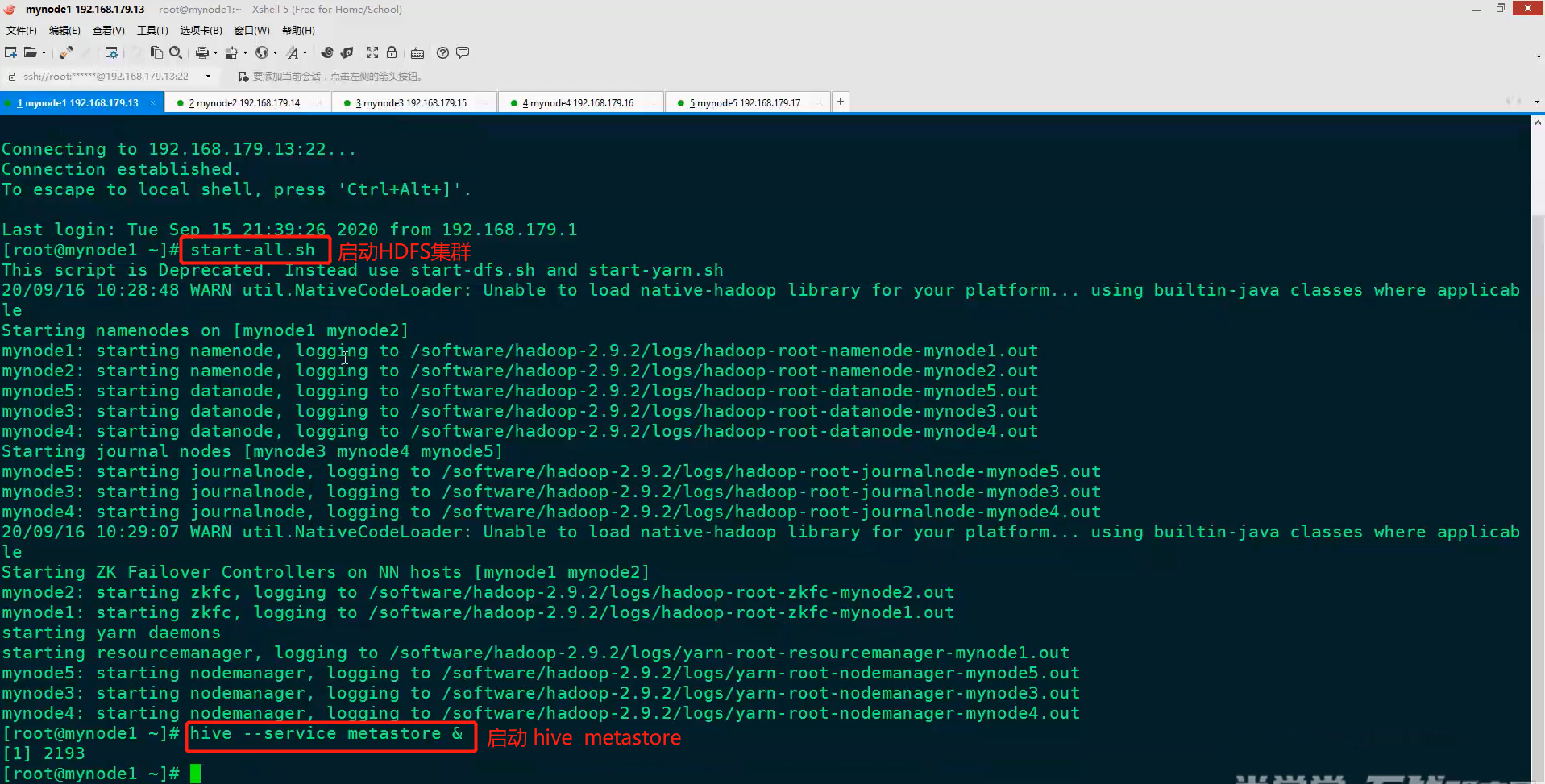
在Hive的客户端启动Hive,查看是否有表,并创建表(可以在代码中创建表,也可以在Hive客户端创建表)

执行完代码,在HDFS上查看保存的数据
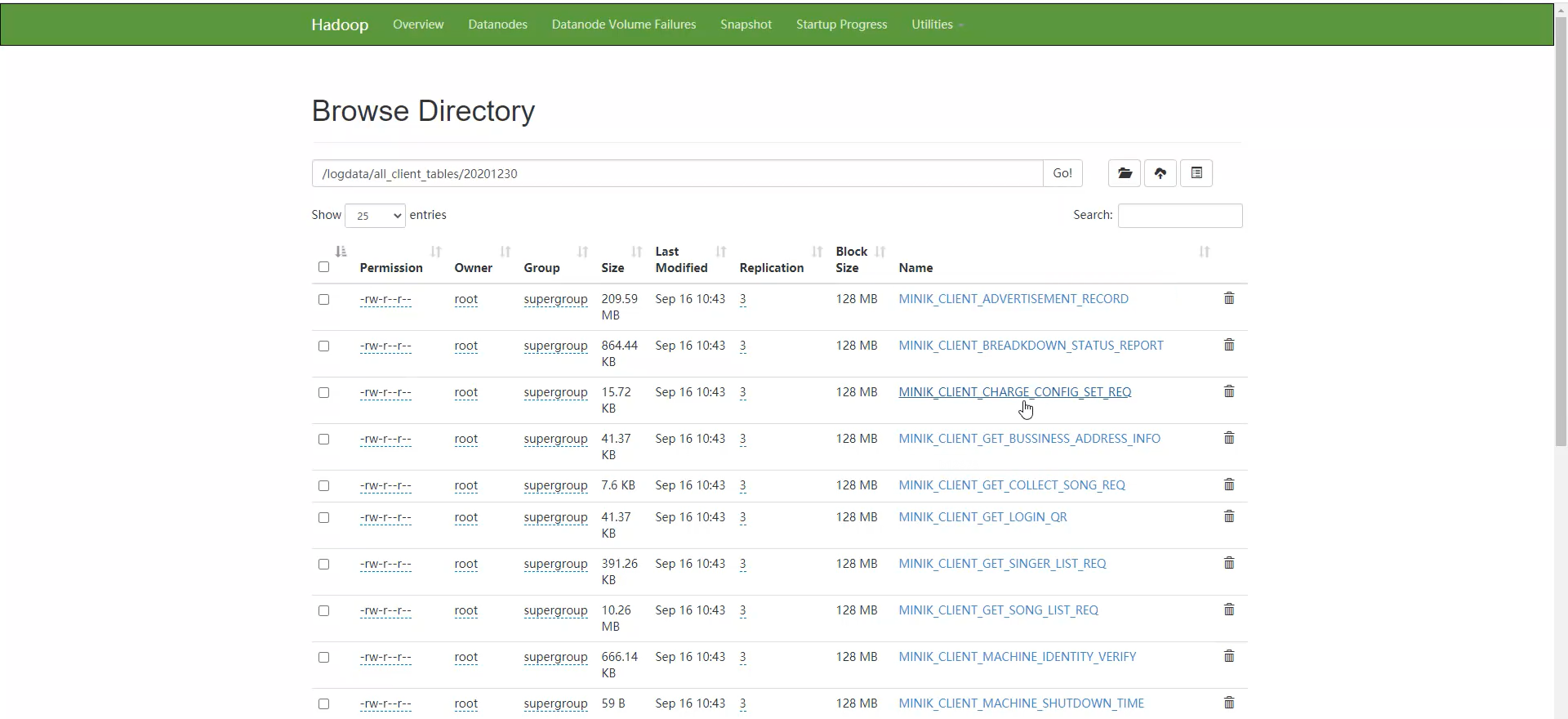
对应的点歌歌曲的数据已经被移动到了指定的hdfs://mycluster/user/hive/warehouse/data/song/TO_CLIENT_SONG_PLAY_OPERATE_REQ_D目录下,在该目录下以分区的方式保存数据
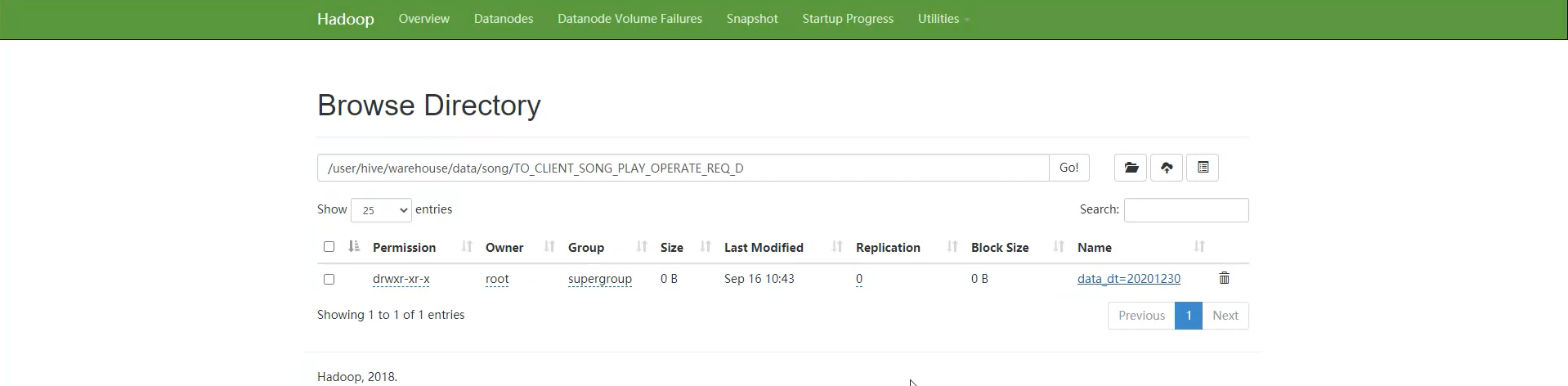
查看分区和数据

5、将mysql关系型数据库中的数据导入到数据仓库中对应的ODS层的Hive表中(使用sqoop工具导入)
(1)安装sqoop
1)上传sqoop安装包
 2)解压安装包
2)解压安装包

3)配置环境变量,在/etc/profile 追加 Sqoop 的环境变量,保存后,执行 source /etc/profile使环境变量生效。



4)拷贝 mysql 的驱动包到 Sqoop lib 下
6)验证是否安装成功

2)在 mynode3 上执 行 sqoop导 入 数 据 脚 本“ods_mysqltohive_to_song_info_d.sh”,将 mysql 中的 song 表数据导入到 Hive数仓“TO_SONG_INFO_D”表中,脚本ods_mysqltohive_to_song_info_d.sh内容如下:
sqoop import \ --connect jdbc:mysql://mynode2:3306/songdb?dontTrackOpenResources=true\&defau ltFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEn coding=utf8 \ --username root \ --password 123456 \ --table song \ --target-dir /user/hive/warehouse/data/song/TO_SONG_INFO_D/ \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by '\t'
3)将脚本ods_mysqltohive_to_song_info_d.sh赋予执行权限,并执行(会转成mapreduce任务执行)

4)查询数据,验证是否导入成功

6、清洗ODS层的TO_SONG_INFO_D歌库歌曲表数据得到TW_SONG_BASEINFO_D歌曲基本信息日全量表中的数据
(1)在Hive中创建TW_SONG_BASEINFO_D表
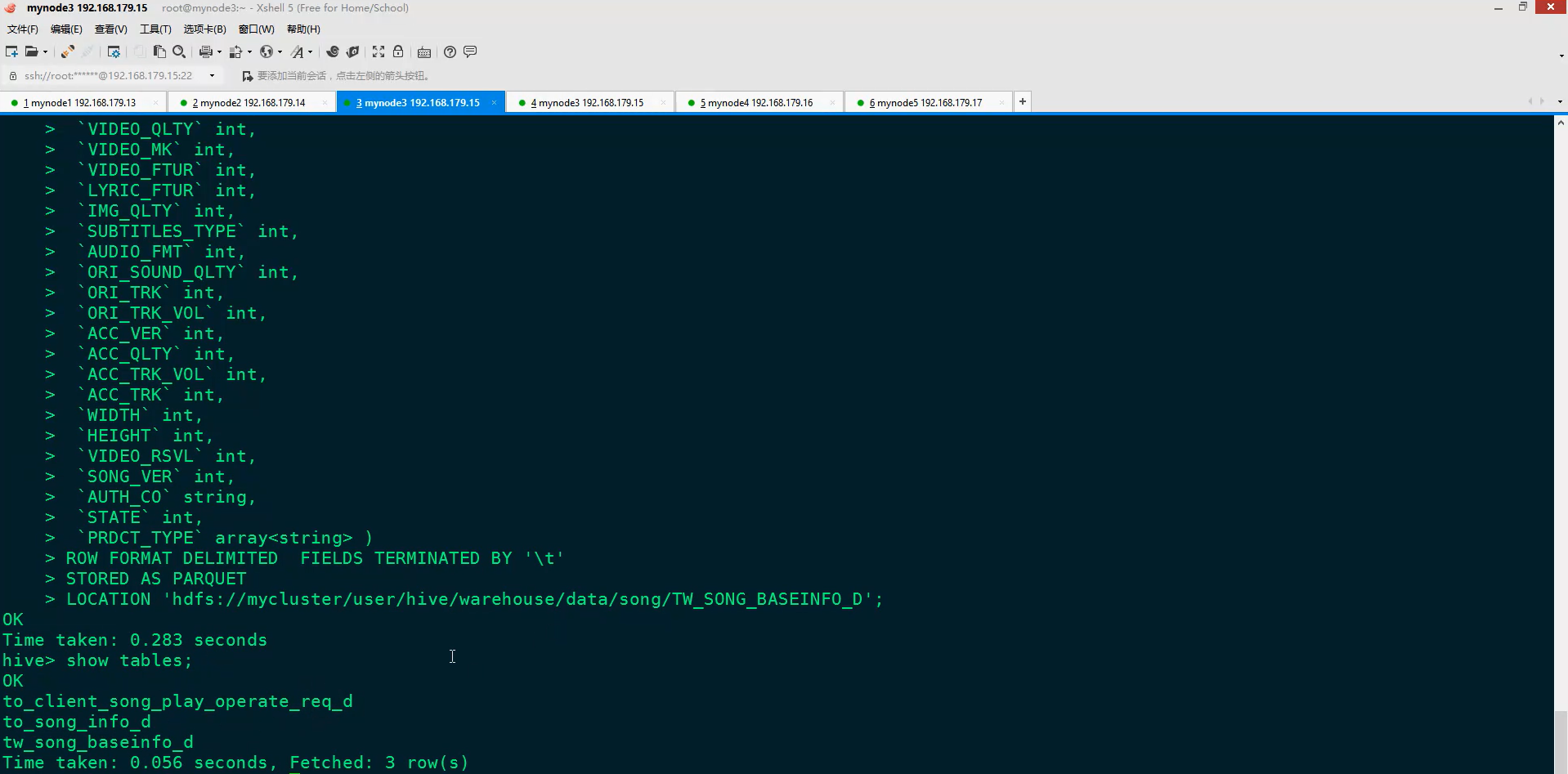
(2)编码将ODS层的TO_SONG_INFO_D歌库歌曲表数据清洗到TW_SONG_BASEINFO_D歌曲基本信息日全量表中
类GenerateTwSongBaseinfoD代码
package com.bjsxt.scala.musicproject.eds.content import com.alibaba.fastjson.{JSON, JSONArray, JSONObject} import com.bjsxt.scala.musicproject.common.{ConfigUtils, DateUtils} import org.apache.spark.sql.{SaveMode, SparkSession} import scala.collection.mutable.ListBuffer /** * 生成TW层 TW_SONG_BASEINFO_D 数据表 * 主要是读取Hive中的ODS层 TO_SONG_INFO_D 表生成 TW层 TW_SONG_BASEINFO_D表, * */ object GenerateTwSongBaseinfoD { val localRun : Boolean = ConfigUtils.LOCAL_RUN val hiveMetaStoreUris = ConfigUtils.HIVE_METASTORE_URIS val hiveDataBase = ConfigUtils.HIVE_DATABASE var sparkSession : SparkSession = _ /** * 定义使用到的UDF函数 对应的方法 */ //获取专辑的名称 val getAlbumName : String => String = (albumInfo:String) => { var albumName = "" try{ val jsonArray: JSONArray = JSON.parseArray(albumInfo) albumName = jsonArray.getJSONObject(0).getString("name") }catch{ case e:Exception =>{ if(albumInfo.contains("《")&&albumInfo.contains("》")){ albumName = albumInfo.substring(albumInfo.indexOf('《'),albumInfo.indexOf('》')+1) }else{ albumName = "暂无专辑" } } } albumName } //获取 发行时间 val getPostTime : String => String = (postTime:String) =>{ DateUtils.formatDate(postTime) } //获取歌手信息 val getSingerInfo : (String,String,String)=> String = (singerInfos:String,singer:String,nameOrId:String) => { var singerNameOrSingerID = "" try{ val jsonArray: JSONArray = JSON.parseArray(singerInfos) if("singer1".equals(singer)&&"name".equals(nameOrId)&&jsonArray.size()>0){ singerNameOrSingerID = jsonArray.getJSONObject(0).getString("name") }else if("singer1".equals(singer)&&"id".equals(nameOrId)&&jsonArray.size()>0){ singerNameOrSingerID = jsonArray.getJSONObject(0).getString("id") }else if("singer2".equals(singer)&&"name".equals(nameOrId)&&jsonArray.size()>1){ singerNameOrSingerID = jsonArray.getJSONObject(1).getString("name") }else if("singer2".equals(singer)&&"id".equals(nameOrId)&&jsonArray.size()>1){ singerNameOrSingerID = jsonArray.getJSONObject(1).getString("id") } }catch{ case e:Exception =>{ singerNameOrSingerID } } singerNameOrSingerID } //获取 授权公司 val getAuthCompany:String => String = (authCompanyInfo :String) =>{ var authCompanyName = "乐心曲库" try{ val jsonObject: JSONObject = JSON.parseObject(authCompanyInfo) authCompanyName = jsonObject.getString("name") }catch{ case e:Exception=>{ authCompanyName } } authCompanyName } //获取产品类型 val getPrdctType : (String =>ListBuffer[Int]) = (productTypeInfo :String) => { // (String =>ListBuffer[Int])表示进来一个String,出去一个ListBuffer[Int]。 val list = new ListBuffer[Int]() if(!"".equals(productTypeInfo.trim)){ val strings = productTypeInfo.stripPrefix("[").stripSuffix("]").split(",") //stripPrefix表示去前缀,stripSuffix表示去后缀 strings.foreach(t=>{ list.append(t.toDouble.toInt) }) } list } def main(args: Array[String]): Unit = { if(localRun){//本地运行 sparkSession = SparkSession.builder().master("local").config("hive.metastore.uris",hiveMetaStoreUris).enableHiveSupport().getOrCreate() }else{//集群运行 sparkSession = SparkSession.builder().enableHiveSupport().getOrCreate() } import org.apache.spark.sql.functions._ //导入函数,可以使用 udf、col 方法 //构建转换数据的udf val udfGetAlbumName = udf(getAlbumName) val udfGetPostTime = udf(getPostTime) val udfGetSingerInfo = udf(getSingerInfo) val udfGetAuthCompany = udf(getAuthCompany) val udfGetPrdctType = udf(getPrdctType) sparkSession.sql(s"use $hiveDataBase ") //表示使用默认Hive库hiveDataBase sparkSession.table("TO_SONG_INFO_D") //加载Hive中表TO_SONG_INFO_D中的数据,准备清洗,使用sparkSession.table可以直接加载Hive中表的数据 .withColumn("ALBUM",udfGetAlbumName(col("ALBUM"))) //把Hive中的ODS层 TO_SONG_INFO_D 表中的ALBUM列传入getAlbumName方法中,获取专辑 .withColumn("POST_TIME",udfGetPostTime(col("POST_TIME"))) //给udf函数设置了SINGER_INFO、singer1、name三个参数,lit表示设置常数列,第1个参数表示要清洗的是歌手的信息,第2个参数表示是要singer1歌手的信息,第3个参数表示singer1歌手的name信息 .withColumn("SINGER1",udfGetSingerInfo(col("SINGER_INFO"),lit("singer1"),lit("name"))) //给udf函数设置了SINGER_INFO、singer1、name三个参数,lit表示设置常数列,第1个参数表示要清洗的是歌手的信息,第2个参数表示是要singer1歌手的信息,第3个参数表示singer1歌手的id信息 .withColumn("SINGER1ID",udfGetSingerInfo(col("SINGER_INFO"),lit("singer1"),lit("id"))) .withColumn("SINGER2",udfGetSingerInfo(col("SINGER_INFO"),lit("singer2"),lit("name"))) .withColumn("SINGER2ID",udfGetSingerInfo(col("SINGER_INFO"),lit("singer2"),lit("id"))) .withColumn("AUTH_CO",udfGetAuthCompany(col("AUTH_CO"))) .withColumn("PRDCT_TYPE",udfGetPrdctType(col("PRDCT_TYPE"))) //将清洗的结果注册为临时表TEMP_TO_SONG_INFO_D,表中包括的字段包括两部分,1、使用withColumn函数增加的列,2、原TO_SONG_INFO_D未被覆盖的所有列 .createTempView("TEMP_TO_SONG_INFO_D") /** * 清洗数据,将结果保存到 Hive TW_SONG_BASEINFO_D 表中 */ sparkSession.sql( """ | select NBR, | nvl(NAME,OTHER_NAME) as NAME, | SOURCE, | ALBUM, | PRDCT, | LANG, | VIDEO_FORMAT, | DUR, | SINGER1, | SINGER2, | SINGER1ID, | SINGER2ID, | 0 as MAC_TIME, | POST_TIME, | PINYIN_FST, | PINYIN, | SING_TYPE, | ORI_SINGER, | LYRICIST, | COMPOSER, | BPM_VAL, | STAR_LEVEL, | VIDEO_QLTY, | VIDEO_MK, | VIDEO_FTUR, | LYRIC_FTUR, | IMG_QLTY, | SUBTITLES_TYPE, | AUDIO_FMT, | ORI_SOUND_QLTY, | ORI_TRK, | ORI_TRK_VOL, | ACC_VER, | ACC_QLTY, | ACC_TRK_VOL, | ACC_TRK, | WIDTH, | HEIGHT, | VIDEO_RSVL, | SONG_VER, | AUTH_CO, | STATE, | case when size(PRDCT_TYPE) =0 then NULL else PRDCT_TYPE end as PRDCT_TYPE | from TEMP_TO_SONG_INFO_D | where NBR != '' """.stripMargin) //得到一个DataFrame .write.format("Hive").mode(SaveMode.Overwrite).saveAsTable("TW_SONG_BASEINFO_D")//SaveMode.Overwrite表示使用全量覆盖的方式往表中写数据 println("**** all finished ****") } }
类DateUtils代码
package com.bjsxt.scala.musicproject.common import java.math.BigDecimal import java.text.SimpleDateFormat import java.util.Date import java.util.Calendar /** * 日期相关的工具 */ object DateUtils { /** * 将字符串格式化成"yyyy-MM-dd HH:mm:ss"格式 * @param stringDate * @return */ def formatDate(stringDate:String):String = { val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") var formatDate = "" try{ formatDate = sdf.format(sdf.parse(stringDate)) }catch{ case e:Exception=>{ try{ val bigDecimal = new BigDecimal(stringDate) val date = new Date(bigDecimal.longValue()) formatDate = sdf.format(date) }catch{ case e:Exception=>{ formatDate } } } } formatDate } /** * 获取输入日期的前几天的日期 * @param currentDate yyyyMMdd * @param i 获取前几天的日期 * @return yyyyMMdd */ def getCurrentDatePreDate(currentDate:String,i:Int) = { val sdf = new SimpleDateFormat("yyyyMMdd") val date: Date = sdf.parse(currentDate) val calendar = Calendar.getInstance() calendar.setTime(date) calendar.add(Calendar.DATE,-i) val per7Date = calendar.getTime sdf.format(per7Date) } }
7、根据TO_CLIENT_SONG_PLAY_OPERATE_REQ_D - 客户端歌曲播放表 和 TO_SONG_INFO_D - 歌库歌曲表得到TW_SONG_FTUR_D - 歌曲特征日统计表
(1)在Hive中创建TW_SONG_FTUR_D表

(2)编码将TO_CLIENT_SONG_PLAY_OPERATE_REQ_D - 客户端歌曲播放表 和 TO_SONG_INFO_D - 歌库歌曲表得到TW_SONG_FTUR_D - 歌曲特征日统计表中
类GenerateTwSongFturD代码
package com.bjsxt.scala.musicproject.eds.content import java.util.Properties import com.bjsxt.scala.musicproject.common.{ConfigUtils, DateUtils} import org.apache.spark.sql.SparkSession /** * 统计得到 TW 层的 TW_SONG_FTUR_D 表 * 结合 TW_SONG_BASEINFO_D 表与 TO_CLIENT_SONG_PLAY_OPERATE_REQ_D 表 生成 TW_SONG_FTUR_D */ object GenerateTwSongFturD { private val localRun : Boolean = ConfigUtils.LOCAL_RUN private val hiveMetaStoreUris = ConfigUtils.HIVE_METASTORE_URIS private val hiveDataBase = ConfigUtils.HIVE_DATABASE private var sparkSession : SparkSession = _ def main(args: Array[String]): Unit = { if(args.length < 1) { println(s"请输入数据日期,格式例如:年月日(20201231)") System.exit(1) } if(localRun){ sparkSession = SparkSession.builder().master("local") .appName("Generate_TW_Song_Ftur_D") .config("spark.sql.shuffle.partitions","1") .config("hive.metastore.uris",hiveMetaStoreUris) .enableHiveSupport() .getOrCreate() sparkSession.sparkContext.setLogLevel("Error") }else{ sparkSession = SparkSession.builder().appName("Generate_TW_Song_Ftur_D").enableHiveSupport().getOrCreate() } //输入数据的日期 ,格式 :年月日 xxxxxxxx val analyticDate = args(0) //获取当前日期的前7天 日期 val per7Date = DateUtils.getCurrentDatePreDate(analyticDate,7) //获取当前日期的前30天日期 val per30Date = DateUtils.getCurrentDatePreDate(analyticDate,30) println(s"输入的日期为 :${analyticDate}") println(s"per7Date = ${per7Date}") println(s"per30Date = ${per30Date}") sparkSession.sql(s"use $hiveDataBase ") //使用Hive默认的库hiveDataBase /** * 获取当天歌曲点唱统计 * 基于 TO_CLIENT_SONG_PLAY_OPERATE_REQ_D 当前数据 统计当天歌曲点唱 */ sparkSession.sql( s""" | select | songid as NBR, --歌曲ID | count(*) as SING_CNT, --当日点唱量 | 0 as SUPP_CNT , --当日点赞量 | count(distinct uid) as USR_CNT, --当日点唱用户数 | count(distinct order_id) as ORDR_CNT --当日点唱订单数 | from TO_CLIENT_SONG_PLAY_OPERATE_REQ_D | where data_dt = ${analyticDate} | group by songid """.stripMargin).createTempView("currentDayTable") //将查询结果注册成一张临时表 /** * 获取近7天的歌曲点唱统计 */ sparkSession.sql( s""" | select | songid as NBR, --歌曲ID | count(*) as RCT_7_SING_CNT, --近七天点唱量 | 0 as RCT_7_SUPP_CNT , --近七天点赞量 | count(distinct uid) as RCT_7_USR_CNT, --近七天点唱用户数 | count(distinct order_id) as RCT_7_ORDR_CNT --近七天点唱订单数 | from to_client_song_play_operate_req_d | where ${per7Date}<= data_dt and data_dt <= ${analyticDate} | group by songid """.stripMargin).createTempView("pre7DayTable") /** * 获取近30天的歌曲点唱统计 */ sparkSession.sql( s""" | select | songid as NBR, --歌曲ID | count(*) as RCT_30_SING_CNT, --近三十天点唱量 | 0 as RCT_30_SUPP_CNT , --近三十天点赞量 | count(distinct uid) as RCT_30_USR_CNT, --近三十天点唱用户数 | count(distinct order_id) as RCT_30_ORDR_CNT --近三十天点唱订单数 | from to_client_song_play_operate_req_d | where ${per30Date}<= data_dt and data_dt <= ${analyticDate} | group by songid """.stripMargin).createTempView("pre30DayTable") /** * 从 TW_SONG_FTUR_D 表中获取过去7天和30天中 每首歌曲的 最高点唱量及点赞量 */ sparkSession.sql( s""" | select | NBR, --歌曲ID | max(case when DATA_DT BETWEEN ${per7Date} and ${analyticDate} then SING_CNT else 0 end) as RCT_7_TOP_SING_CNT, --近七天最高日点唱量 | max(case when DATA_DT BETWEEN ${per7Date} and ${analyticDate} then SUPP_CNT else 0 end) as RCT_7_TOP_SUPP_CNT, --近七天最高日点赞量 | max(SING_CNT) as RCT_30_TOP_SING_CNT, --近三十天最高日点唱量 | max(SUPP_CNT) as RCT_30_TOP_SUPP_CNT --近三十天最高日点赞量 | from TW_SONG_FTUR_D | where DATA_DT BETWEEN ${per30Date} and ${analyticDate} | group by NBR """.stripMargin).createTempView("pre7And30DayInfoTable") sparkSession.sql( s""" |select | A.NBR, --歌曲编号 | B.NAME, --歌曲名称 | B.SOURCE, --来源 | B.ALBUM, --所属专辑 | B.PRDCT, --发行公司 | B.LANG, --语言 | B.VIDEO_FORMAT, --视频风格 | B.DUR, --时长 | B.SINGER1, --歌手1 | B.SINGER2, --歌手2 | B.SINGER1ID, --歌手1ID | B.SINGER2ID, --歌手2ID | B.MAC_TIME, --加入机器时间 | A.SING_CNT, --当日点唱量 | A.SUPP_CNT, --当日点赞量 | A.USR_CNT, --当日点唱用户数 | A.ORDR_CNT, --当日点唱订单数 | nvl(C.RCT_7_SING_CNT,0) as RCT_7_SING_CNT, --近7天点唱量 | nvl(C.RCT_7_SUPP_CNT,0) as RCT_7_SUPP_CNT, --近7天点赞量 | nvl(E.RCT_7_TOP_SING_CNT,0) as RCT_7_TOP_SING_CNT, --近7天最高点唱量 | nvl(E.RCT_7_TOP_SUPP_CNT,0) as RCT_7_TOP_SUPP_CNT, --近7天最高点赞量 | nvl(C.RCT_7_USR_CNT,0) as RCT_7_USR_CNT, --近7天点唱用户数 | nvl(C.RCT_7_ORDR_CNT,0) as RCT_7_ORDR_CNT, --近7天点唱订单数 | nvl(D.RCT_30_SING_CNT,0) as RCT_30_SING_CNT, --近30天点唱量 | nvl(D.RCT_30_SUPP_CNT,0) as RCT_30_SUPP_CNT, --近30天点赞量 | nvl(E.RCT_30_TOP_SING_CNT,0) as RCT_30_TOP_SING_CNT, --近30天最高点唱量 | nvl(E.RCT_30_TOP_SUPP_CNT,0) as RCT_30_TOP_SUPP_CNT, --近30天最高点赞量 | nvl(D.RCT_30_USR_CNT,0) as RCT_30_USR_CNT, --近30天点唱用户数 | nvl(D.RCT_30_ORDR_CNT,0) as RCT_30_ORDR_CNT --近30天点唱订单数 |from | currentDayTable A | JOIN TW_SONG_BASEINFO_D B ON A.NBR = B.NBR | LEFT JOIN pre7DayTable C ON A.NBR = C.NBR | LEFT JOIN pre30DayTable D ON A.NBR = D.NBR | LEFT JOIN pre7And30DayInfoTable E ON A.NBR = E.NBR """.stripMargin).createTempView("result") sparkSession.sql( s""" | insert overwrite table tw_song_ftur_d partition(data_dt=${analyticDate}) select * from result """.stripMargin) println("**** all finished ****") } }
类DateUtils代码
package com.bjsxt.scala.musicproject.common import java.math.BigDecimal import java.text.SimpleDateFormat import java.util.Date import java.util.Calendar /** * 日期相关的工具 */ object DateUtils { /** * 将字符串格式化成"yyyy-MM-dd HH:mm:ss"格式 * @param stringDate * @return */ def formatDate(stringDate:String):String = { val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") var formatDate = "" try{ formatDate = sdf.format(sdf.parse(stringDate)) }catch{ case e:Exception=>{ try{ val bigDecimal = new BigDecimal(stringDate) val date = new Date(bigDecimal.longValue()) formatDate = sdf.format(date) }catch{ case e:Exception=>{ formatDate } } } } formatDate } /** * 获取输入日期的前几天的日期 * @param currentDate yyyyMMdd * @param i 获取前几天的日期 * @return yyyyMMdd */ def getCurrentDatePreDate(currentDate:String,i:Int) = { val sdf = new SimpleDateFormat("yyyyMMdd") val date: Date = sdf.parse(currentDate) val calendar = Calendar.getInstance() calendar.setTime(date) calendar.add(Calendar.DATE,-i) val per7Date = calendar.getTime sdf.format(per7Date) } }
8、根据TW_SONG_FTUR_D - 歌曲特征日统计表得到TW_SONG_RSI_D - 歌曲影响力指数日统计表数据
(1)在Hive中创建TW_SONG_RSI_D表

(2)编码将TW_SONG_FTUR_D - 歌曲特征日统计表得到TW_SONG_RSI_D - 歌曲影响力指数日统计表数据
类GenerateTmSongRsiD代码
package com.bjsxt.scala.musicproject.dm.content import java.util.Properties import com.bjsxt.scala.musicproject.common.ConfigUtils import org.apache.spark.sql.{SaveMode, SparkSession} /** * 根据 TW_SONG_FTUR_D 表得到 TW_SONG_RSI_D 歌曲影响力指数日统计表,同时得到mysql中的tm_song_rsi表 * */ object GenerateTmSongRsiD { private val localRun : Boolean = ConfigUtils.LOCAL_RUN private val hiveMetaStoreUris = ConfigUtils.HIVE_METASTORE_URIS private val hiveDataBase = ConfigUtils.HIVE_DATABASE private var sparkSession : SparkSession = _ private val mysqlUrl = ConfigUtils.MYSQL_URL private val mysqlUser = ConfigUtils.MYSQL_USER private val mysqlPassword = ConfigUtils.MYSQL_PASSWORD def main(args: Array[String]): Unit = { if(args.length < 1) { println(s"请输入数据日期,格式例如:年月日(20201231)") System.exit(1) } if(localRun){ sparkSession = SparkSession.builder().master("local") .appName("Generate_TM_Song_Rsi_D") .config("spark.sql.shuffle.partitions","1") .config("hive.metastore.uris",hiveMetaStoreUris) .enableHiveSupport().getOrCreate() sparkSession.sparkContext.setLogLevel("Error") }else{ sparkSession = SparkSession.builder().appName("Generate_TM_Song_Rsi_D").enableHiveSupport().getOrCreate() } val currentDate = args(0) //年月日 20201230 sparkSession.sql(s"use $hiveDataBase ") val dataFrame = sparkSession.sql( s""" | select | data_dt, --日期 | NBR, --歌曲ID | NAME, --歌曲名称 | SING_CNT, --当日点唱量 | SUPP_CNT, --当日点赞量 | RCT_7_SING_CNT, --近七天点唱量 | RCT_7_SUPP_CNT, --近七天点赞量 | RCT_7_TOP_SING_CNT, --近七天最高日点唱量 | RCT_7_TOP_SUPP_CNT, --近七天最高日点赞量 | RCT_30_SING_CNT, --近三十天点唱量 | RCT_30_SUPP_CNT, --近三十天点赞量 | RCT_30_TOP_SING_CNT, --近三十天最高日点唱量 | RCT_30_TOP_SUPP_CNT --近三十天最高日点赞量 | from TW_SONG_FTUR_D | where data_dt = ${currentDate} """.stripMargin) import org.apache.spark.sql.functions._ /** * 日周期-整体影响力 * 7日周期-整体影响力 * 30日周期-整体影响力 */ dataFrame.withColumn("RSI_1D",pow( //pow是平方 log(col("SING_CNT")/1+1)*0.63*0.8+log(col("SUPP_CNT")/1+1)*0.63*0.2 ,2)*10) .withColumn("RSI_7D",pow( (log(col("RCT_7_SING_CNT")/7+1)*0.63+log(col("RCT_7_TOP_SING_CNT")+1)*0.37)*0.8 + (log(col("RCT_7_SUPP_CNT")/7+1)*0.63+log(col("RCT_7_TOP_SUPP_CNT")+1)*0.37)*0.2 ,2)*10) .withColumn("RSI_30D",pow( (log(col("RCT_30_SING_CNT")/30+1)*0.63+log(col("RCT_30_TOP_SING_CNT")+1)*0.37)*0.8 + (log(col("RCT_30_SUPP_CNT")/30+1)*0.63+log(col("RCT_30_TOP_SUPP_CNT")+1)*0.37)*0.2 ,2)*10) .createTempView("TEMP_TW_SONG_FTUR_D") val rsi_1d = sparkSession.sql( s""" | select | "1" as PERIOD,NBR,NAME,RSI_1D as RSI, | row_number() over(partition by data_dt order by RSI_1D desc) as RSI_RANK | from TEMP_TW_SONG_FTUR_D """.stripMargin) val rsi_7d = sparkSession.sql( s""" | select | "7" as PERIOD,NBR,NAME,RSI_7D as RSI, | row_number() over(partition by data_dt order by RSI_7D desc) as RSI_RANK | from TEMP_TW_SONG_FTUR_D """.stripMargin) val rsi_30d = sparkSession.sql( s""" | select | "30" as PERIOD,NBR,NAME,RSI_30D as RSI, | row_number() over(partition by data_dt order by RSI_30D desc) as RSI_RANK | from TEMP_TW_SONG_FTUR_D """.stripMargin) rsi_1d.union(rsi_7d).union(rsi_30d).createTempView("result") //insert into table TW_SONG_RSI_D partition(data_dt=${currentDate}) select * from result sparkSession.sql( s""" |insert overwrite table TW_SONG_RSI_D partition(data_dt=${currentDate}) select * from result """.stripMargin) /** * 这里把 排名前30名的数据保存到mysql表中 */ val properties = new Properties() properties.setProperty("user",mysqlUser) properties.setProperty("password",mysqlPassword) properties.setProperty("driver","com.mysql.jdbc.Driver") sparkSession.sql( s""" | select ${currentDate} as data_dt,PERIOD,NBR,NAME,RSI,RSI_RANK from result where rsi_rank <=30 """.stripMargin).write.mode(SaveMode.Overwrite).jdbc(mysqlUrl,"tm_song_rsi",properties) println("**** all finished ****") } }
9、根据TW_SONG_FTUR_D - 歌曲特征日统计表得到TW_SINGER_RSI_D - 歌手影响力指数日统计表数据
(1)在Hive中创建TW_SINGER_RSI_D表
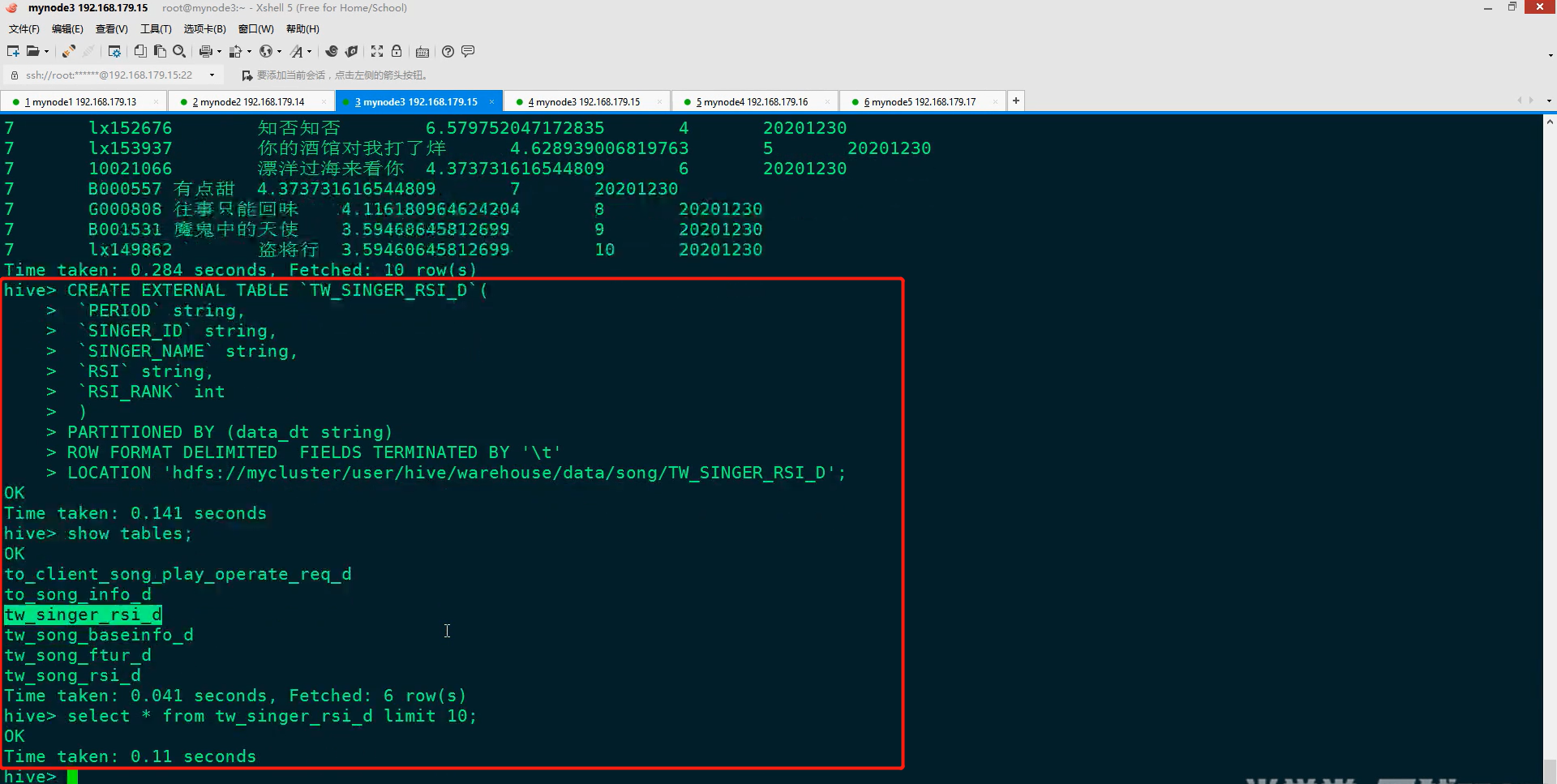
(2)编码将TW_SONG_FTUR_D - 歌曲特征日统计表得到TW_SINGER_RSI_D - 歌手影响力指数日统计表数据
类GenerateTmSingerRsiD代码
package com.bjsxt.scala.musicproject.dm.content import java.util.Properties import com.bjsxt.scala.musicproject.common.ConfigUtils import org.apache.spark.sql.{SaveMode, SparkSession} /** * 根据 TW_SONG_FTUR_D 表得到 TW_SINGER_RSI_D 歌手影响力指数日统计,同时得到mysql中的 tm_singer_rsi * */ object GenerateTmSingerRsiD { private val localRun : Boolean = ConfigUtils.LOCAL_RUN private val hiveMetaStoreUris = ConfigUtils.HIVE_METASTORE_URIS private val hiveDataBase = ConfigUtils.HIVE_DATABASE private var sparkSession : SparkSession = _ private val mysqlUrl = ConfigUtils.MYSQL_URL private val mysqlUser = ConfigUtils.MYSQL_USER private val mysqlPassword = ConfigUtils.MYSQL_PASSWORD def main(args: Array[String]): Unit = { if(args.length < 1) { println(s"请输入数据日期,格式例如:年月日(20201231)") System.exit(1) } if(localRun){ sparkSession = SparkSession.builder().master("local").appName("Generate_TM_Song_Rsi_D") .config("spark.sql.shuffle.partitions","1") .config("hive.metastore.uris",hiveMetaStoreUris).enableHiveSupport().getOrCreate() sparkSession.sparkContext.setLogLevel("Error") }else{ sparkSession = SparkSession.builder().appName("Generate_TM_Song_Rsi_D").enableHiveSupport().getOrCreate() } val currentDate = args(0) sparkSession.sql(s"use $hiveDataBase ") val dataFrame = sparkSession.sql( s""" | select | data_dt, | SINGER1ID, | SINGER1, | sum(SING_CNT) as SING_CNT, | sum(SUPP_CNT) as SUPP_CNT, | sum(RCT_7_SING_CNT) as RCT_7_SING_CNT, | sum(RCT_7_SUPP_CNT) as RCT_7_SUPP_CNT, | sum(RCT_7_TOP_SING_CNT) as RCT_7_TOP_SING_CNT, | sum(RCT_7_TOP_SUPP_CNT) as RCT_7_TOP_SUPP_CNT, | sum(RCT_30_SING_CNT) as RCT_30_SING_CNT, | sum(RCT_30_SUPP_CNT) as RCT_30_SUPP_CNT, | sum(RCT_30_TOP_SING_CNT) as RCT_30_TOP_SING_CNT, | sum(RCT_30_TOP_SUPP_CNT) as RCT_30_TOP_SUPP_CNT | from TW_SONG_FTUR_D | where data_dt = ${currentDate} | GROUP BY data_dt,SINGER1ID,SINGER1 """.stripMargin) import org.apache.spark.sql.functions._ /** * 日周期-整体影响力 * 7日周期-整体影响力 * 30日周期-整体影响力 */ dataFrame.withColumn("RSI_1D",pow( log(col("SING_CNT")/1+1)*0.63*0.8+log(col("SUPP_CNT")+1)*0.63*0.2 ,2)*10) .withColumn("RSI_7D",pow( (log(col("RCT_7_SING_CNT")/7+1)*0.63+log(col("RCT_7_TOP_SING_CNT")+1)*0.37)*0.8 + (log(col("RCT_7_SUPP_CNT")/7+1)*0.63+log(col("RCT_7_TOP_SUPP_CNT")+1)*0.37)*0.2 ,2)*10) .withColumn("RSI_30D",pow( (log(col("RCT_30_SING_CNT")/30+1)*0.63+log(col("RCT_30_TOP_SING_CNT")+1)*0.37)*0.8 + (log(col("RCT_30_SUPP_CNT")/30+1)*0.63+log(col("RCT_30_TOP_SUPP_CNT")+1)*0.37)*0.2 ,2)*10).createTempView("TEMP_TW_SONG_FTUR_D") val rsi_1d = sparkSession.sql( s""" | select | "1" as PERIOD,SINGER1ID,SINGER1,RSI_1D as RSI, | row_number() over(partition by data_dt order by RSI_1D desc) as RSI_RANK | from TEMP_TW_SONG_FTUR_D """.stripMargin) val rsi_7d = sparkSession.sql( s""" | select | "7" as PERIOD,SINGER1ID,SINGER1,RSI_7D as RSI, | row_number() over(partition by data_dt order by RSI_7D desc) as RSI_RANK | from TEMP_TW_SONG_FTUR_D """.stripMargin) val rsi_30d = sparkSession.sql( s""" | select | "30" as PERIOD,SINGER1ID,SINGER1,RSI_30D as RSI, | row_number() over(partition by data_dt order by RSI_30D desc) as RSI_RANK | from TEMP_TW_SONG_FTUR_D """.stripMargin) rsi_1d.union(rsi_7d).union(rsi_30d).createTempView("result") sparkSession.sql( s""" |insert overwrite table TW_SINGER_RSI_D partition(data_dt=${currentDate}) select * from result """.stripMargin) /** * 这里把 排名前30名的数据保存到mysql表中 */ val properties = new Properties() properties.setProperty("user",mysqlUser) properties.setProperty("password",mysqlPassword) properties.setProperty("driver","com.mysql.jdbc.Driver") sparkSession.sql( s""" | select ${currentDate} as data_dt,PERIOD,SINGER1ID,SINGER1,RSI,RSI_RANK from result where rsi_rank <=30 """.stripMargin).write.mode(SaveMode.Overwrite).jdbc(mysqlUrl,"tm_singer_rsi",properties) println("**** all finished ****") } }
10、Azkaban任务流调度
(1)Azkaban任务调度环境准备
编写创建表的脚本sql:create_1_alltables.sql(此处有6张表)

create_1_alltables.sql内容如下:
CREATE EXTERNAL TABLE IF NOT EXISTS `TO_CLIENT_SONG_PLAY_OPERATE_REQ_D`( `SONGID` string, `MID` string, `OPTRATE_TYPE` string, `UID` string, `CONSUME_TYPE` string, `DUR_TIME` string, `SESSION_ID` string, `SONGNAME` string, `PKG_ID` string, `ORDER_ID` string ) partitioned by (data_dt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TO_CLIENT_SONG_PLAY_OPERATE_REQ_D'; CREATE EXTERNAL TABLE `TO_SONG_INFO_D`( `NBR` string, `NAME` string, `OTHER_NAME` string, `SOURCE` int, `ALBUM` string, `PRDCT` string, `LANG` string, `VIDEO_FORMAT` string, `DUR` int, `SINGER_INFO` string, `POST_TIME` string, `PINYIN_FST` string, `PINYIN` string, `SING_TYPE` int, `ORI_SINGER` string, `LYRICIST` string, `COMPOSER` string, `BPM_VAL` int, `STAR_LEVEL` int, `VIDEO_QLTY` int, `VIDEO_MK` int, `VIDEO_FTUR` int, `LYRIC_FTUR` int, `IMG_QLTY` int, `SUBTITLES_TYPE` int, `AUDIO_FMT` int, `ORI_SOUND_QLTY` int, `ORI_TRK` int, `ORI_TRK_VOL` int, `ACC_VER` int, `ACC_QLTY` int, `ACC_TRK_VOL` int, `ACC_TRK` int, `WIDTH` int, `HEIGHT` int, `VIDEO_RSVL` int, `SONG_VER` int, `AUTH_CO` string, `STATE` int, `PRDCT_TYPE` string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TO_SONG_INFO_D'; CREATE EXTERNAL TABLE `TW_SINGER_RSI_D`( `PERIOD` string, `SINGER_ID` string, `SINGER_NAME` string, `RSI` string, `RSI_RANK` int ) PARTITIONED BY (data_dt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TW_SINGER_RSI_D'; CREATE EXTERNAL TABLE `TW_SONG_BASEINFO_D`( `NBR` string, `NAME` string, `SOURCE` int, `ALBUM` string, `PRDCT` string, `LANG` string, `VIDEO_FORMAT` string, `DUR` int, `SINGER1` string, `SINGER2` string, `SINGER1ID` string, `SINGER2ID` string, `MAC_TIME` int, `POST_TIME` string, `PINYIN_FST` string, `PINYIN` string, `SING_TYPE` int, `ORI_SINGER` string, `LYRICIST` string, `COMPOSER` string, `BPM_VAL` int, `STAR_LEVEL` int, `VIDEO_QLTY` int, `VIDEO_MK` int, `VIDEO_FTUR` int, `LYRIC_FTUR` int, `IMG_QLTY` int, `SUBTITLES_TYPE` int, `AUDIO_FMT` int, `ORI_SOUND_QLTY` int, `ORI_TRK` int, `ORI_TRK_VOL` int, `ACC_VER` int, `ACC_QLTY` int, `ACC_TRK_VOL` int, `ACC_TRK` int, `WIDTH` int, `HEIGHT` int, `VIDEO_RSVL` int, `SONG_VER` int, `AUTH_CO` string, `STATE` int, `PRDCT_TYPE` array<string> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS PARQUET LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TW_SONG_BASEINFO_D'; CREATE EXTERNAL TABLE `TW_SONG_FTUR_D`( `NBR` string, `NAME` string, `SOURCE` int, `ALBUM` string, `PRDCT` string, `LANG` string, `VIDEO_FORMAT` string, `DUR` int, `SINGER1` string, `SINGER2` string, `SINGER1ID` string, `SINGER2ID` string, `MAC_TIME` int, `SING_CNT` int, `SUPP_CNT` int, `USR_CNT` int, `ORDR_CNT` int, `RCT_7_SING_CNT` int, `RCT_7_SUPP_CNT` int, `RCT_7_TOP_SING_CNT` int, `RCT_7_TOP_SUPP_CNT` int, `RCT_7_USR_CNT` int, `RCT_7_ORDR_CNT` int, `RCT_30_SING_CNT` int, `RCT_30_SUPP_CNT` int, `RCT_30_TOP_SING_CNT` int, `RCT_30_TOP_SUPP_CNT` int, `RCT_30_USR_CNT` int, `RCT_30_ORDR_CNT` int ) PARTITIONED BY (data_dt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TW_SONG_FTUR_D'; CREATE EXTERNAL TABLE `TW_SONG_RSI_D`( `PERIOD` string, `NBR` string, `NAME` string, `RSI` string, `RSI_RANK` int ) PARTITIONED BY (data_dt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TW_SONG_RSI_D';
执行create_1_alltables.sql脚本
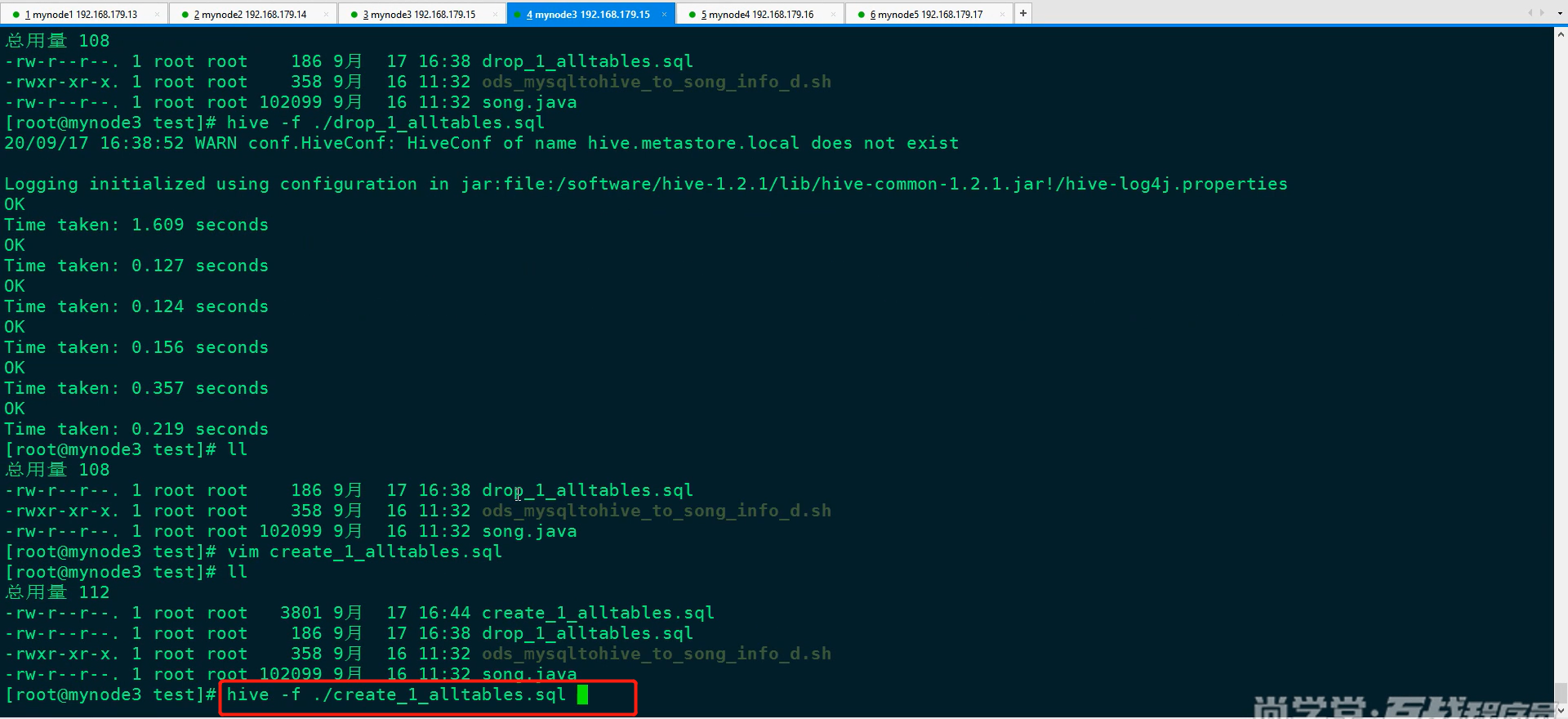
(2)Azkaban配置任务流脚本准备

#!/bin/bash currentDate=`date -d today +"%Y%m%d"` if [ x"$1" = x ]; then echo "====使用自动生成的今天日期====" else echo "====使用 azkaban 传入的时间====" currentDate=$1 fi echo "日期为 : $currentDate"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc cd /software/spark-2.3.1/bin sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.ods.ProduceClientLog /root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar $currentDate exit aabbcc
echo "all done!"
2)mysql 数据抽取数据到 Hive ODS 脚本 2extract_mysqldata_to_ods.sh :
#!/bin/bash ssh root@mynode3 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc cd /root/test sh ods_mysqltohive_to_song_info_d.sh exit aabbcc echo "all done!"
补充:脚本ods_mysqltohive_to_song_info_d.sh内容如下:

3)清洗歌库歌曲表脚本3produce_tw_song_baseinfo_d.sh:
#!/bin/bash ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc cd /software/spark-2.3.1/bin sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.tw.GenerateTwSongBaseinfoD /root/test/MusicProject-1.0-SNAPSHOT-jar- with-dependencies.jar exit aabbcc echo "all done!"
4)生成歌曲特征日统计表脚本 4produce_tw_song_ftur_d.sh:
#!/bin/bash currentDate=`date -d today +"%Y%m%d"` if [ x"$1" = x ]; then echo "====使用自动生成的今天日期====" else echo "====使用 azkaban 传入的时间====" currentDate=$1 fi echo "日期为 : $currentDate" ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc cd /software/spark-2.3.1/bin sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.eds.song.GenerateTwSongFturD /root/test/MusicProject-1.0-SNAPSHOT-jar-with -dependencies.jar $currentDate exit aabbcc echo "all done!"
5)生成歌曲热度表脚本 5produce_tw_song_rsi_d.sh:
#!/bin/bash currentDate=`date -d today +"%Y%m%d"` if [ x"$1" = x ]; then echo "====使用自动生成的今天日期====" else echo "====使用 azkaban 传入的时间====" currentDate=$1 fi echo "日期为 : $currentDate" ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc cd /software/spark-2.3.1/bin sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.dm.content.GenerateTwSongRsiD /root/test/MusicProject-1.0-SNAPSHOT-jar-with- dependencies.jar $currentDate exit aabbcc echo "all done!"
6)生成歌手热度表脚本 6produce_tw_singer_rsi_d.sh
#!/bin/bash currentDate=`date -d today +"%Y%m%d"` if [ x"$1" = x ]; then echo "====使用自动生成的今天日期====" else echo "====使用 azkaban 传入的时间====" currentDate=$1 fi echo "日期为 : $currentDate" ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc cd /software/spark-2.3.1/bin sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.dm.content.GenerateTwSingerRsiD /root/test/MusicProject-1.0-SNAPSHOT-jar-wit h-dependencies.jar $currentDate exit aabbcc echo "all done!"
(3)Azkaban配置任务流调度任务
1)启动Azkaban
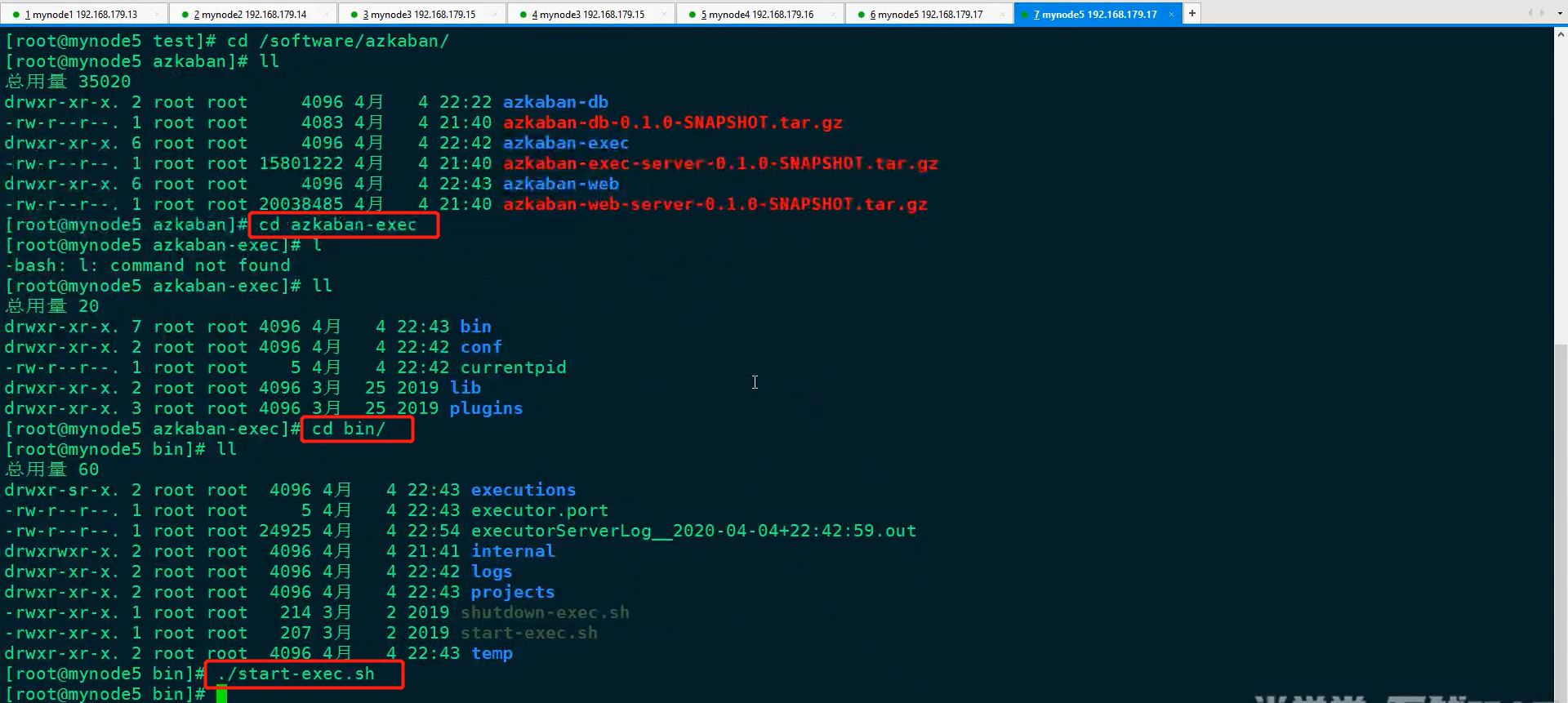
2)激活Azkaban

3)启动web

4)访问Azkaban,用户名和密码默认都为 Azkaban

登录之后就可以创建项目了。
5)创建项目
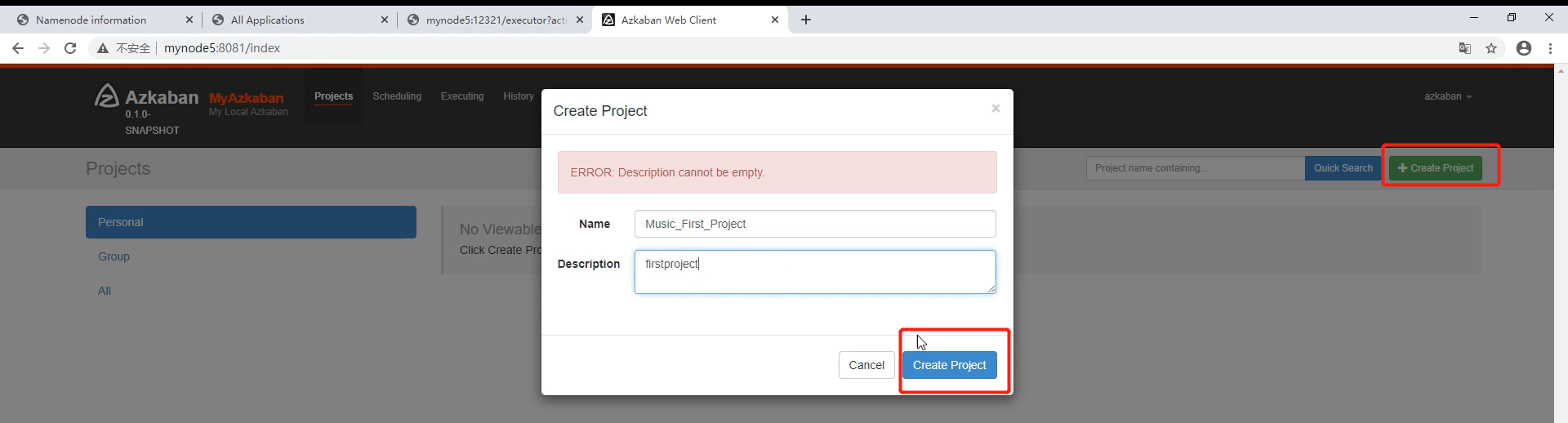
6)在本地创建6个.job文件,并压缩为一个压缩包。
6个.job文件中的内容分别如下:

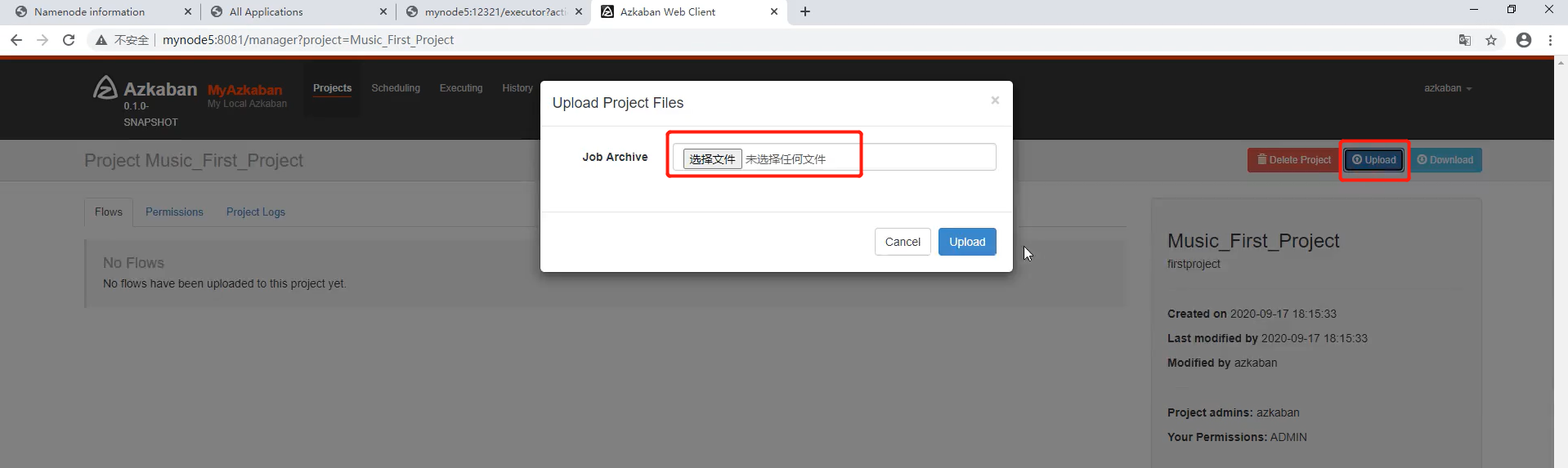
将6个.job文件压缩为一个压缩包:

上传压缩包:
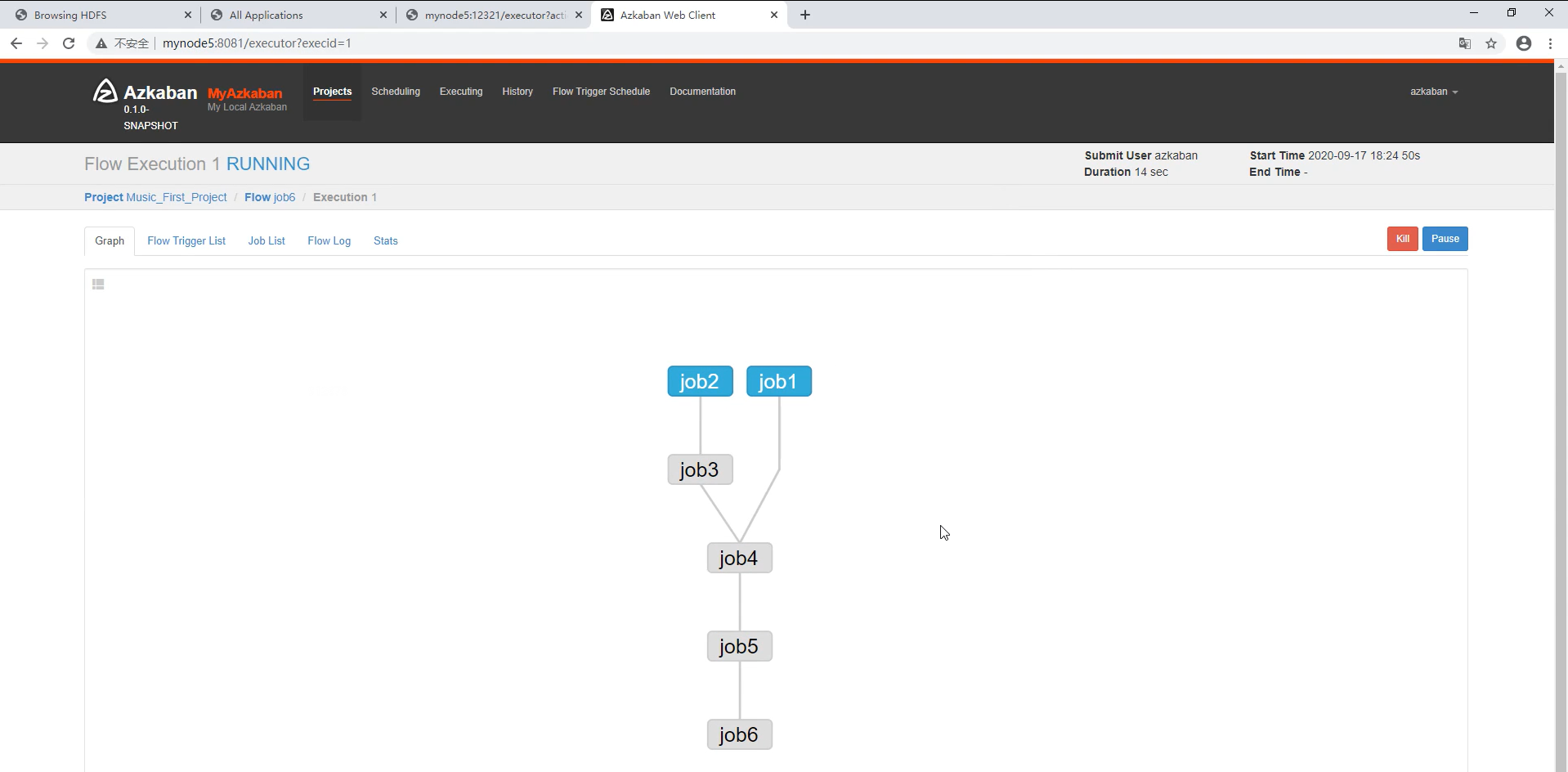
点Execute Flow,查看任务流

如下:
传参并执行:

若各个job均为蓝色,则说明任务流执行成功
结束!!!
package com.bjsxt.scala.musicproject.eds.content
import com.alibaba.fastjson.{JSON, JSONArray, JSONObject}
import com.bjsxt.scala.musicproject.common.{ConfigUtils, DateUtils}
import org.apache.spark.sql.{SaveMode, SparkSession}
import scala.collection.mutable.ListBuffer
/**
* 生成TW层 TW_SONG_BASEINFO_D 数据表
* 主要是读取Hive中的ODS层 TO_SONG_INFO_D 表生成 TW层 TW_SONG_BASEINFO_D表,
*
*/
object GenerateTwSongBaseinfoD {
val localRun : Boolean = ConfigUtils.LOCAL_RUN
val hiveMetaStoreUris = ConfigUtils.HIVE_METASTORE_URIS
val hiveDataBase = ConfigUtils.HIVE_DATABASE
var sparkSession : SparkSession = _
/**
* 定义使用到的UDF函数 对应的方法
*/
//获取专辑的名称
val getAlbumName : String => String = (albumInfo:String) => {
var albumName = ""
try{
val jsonArray: JSONArray = JSON.parseArray(albumInfo)
albumName = jsonArray.getJSONObject(0).getString("name")
}catch{
case e:Exception =>{
if(albumInfo.contains("《")&&albumInfo.contains("》")){
albumName = albumInfo.substring(albumInfo.indexOf('《'),albumInfo.indexOf('》')+1)
}else{
albumName = "暂无专辑"
}
}
}
albumName
}
//获取 发行时间
val getPostTime : String => String = (postTime:String) =>{
DateUtils.formatDate(postTime)
}
//获取歌手信息
val getSingerInfo : (String,String,String)=> String = (singerInfos:String,singer:String,nameOrId:String) => {
var singerNameOrSingerID = ""
try{
val jsonArray: JSONArray = JSON.parseArray(singerInfos)
if("singer1".equals(singer)&&"name".equals(nameOrId)&&jsonArray.size()>0){
singerNameOrSingerID = jsonArray.getJSONObject(0).getString("name")
}else if("singer1".equals(singer)&&"id".equals(nameOrId)&&jsonArray.size()>0){
singerNameOrSingerID = jsonArray.getJSONObject(0).getString("id")
}else if("singer2".equals(singer)&&"name".equals(nameOrId)&&jsonArray.size()>1){
singerNameOrSingerID = jsonArray.getJSONObject(1).getString("name")
}else if("singer2".equals(singer)&&"id".equals(nameOrId)&&jsonArray.size()>1){
singerNameOrSingerID = jsonArray.getJSONObject(1).getString("id")
}
}catch{
case e:Exception =>{
singerNameOrSingerID
}
}
singerNameOrSingerID
}
//获取 授权公司
val getAuthCompany:String => String = (authCompanyInfo :String) =>{
var authCompanyName = "乐心曲库"
try{
val jsonObject: JSONObject = JSON.parseObject(authCompanyInfo)
authCompanyName = jsonObject.getString("name")
}catch{
case e:Exception=>{
authCompanyName
}
}
authCompanyName
}
//获取产品类型
val getPrdctType : (String =>ListBuffer[Int]) = (productTypeInfo :String) => { // (String =>ListBuffer[Int])表示进来一个String,出去一个ListBuffer[Int]。
val list = new ListBuffer[Int]()
if(!"".equals(productTypeInfo.trim)){
val strings = productTypeInfo.stripPrefix("[").stripSuffix("]").split(",") //stripPrefix表示去前缀,stripSuffix表示去后缀
strings.foreach(t=>{
list.append(t.toDouble.toInt)
})
}
list
}
def main(args: Array[String]): Unit = {
if(localRun){//本地运行
sparkSession = SparkSession.builder().master("local").config("hive.metastore.uris",hiveMetaStoreUris).enableHiveSupport().getOrCreate()
}else{//集群运行
sparkSession = SparkSession.builder().enableHiveSupport().getOrCreate()
}
import org.apache.spark.sql.functions._ //导入函数,可以使用 udf、col 方法
//构建转换数据的udf
val udfGetAlbumName = udf(getAlbumName)
val udfGetPostTime = udf(getPostTime)
val udfGetSingerInfo = udf(getSingerInfo)
val udfGetAuthCompany = udf(getAuthCompany)
val udfGetPrdctType = udf(getPrdctType)
sparkSession.sql(s"use $hiveDataBase ") //表示使用默认Hive库hiveDataBase
sparkSession.table("TO_SONG_INFO_D") //加载Hive中表TO_SONG_INFO_D中的数据,准备清洗,使用sparkSession.table可以直接加载Hive中表的数据
.withColumn("ALBUM",udfGetAlbumName(col("ALBUM"))) //把Hive中的ODS层 TO_SONG_INFO_D 表中的ALBUM列传入getAlbumName方法中,获取专辑
.withColumn("POST_TIME",udfGetPostTime(col("POST_TIME")))
//给udf函数设置了SINGER_INFO、singer1、name三个参数,lit表示设置常数列,第1个参数表示要清洗的是歌手的信息,第2个参数表示是要singer1歌手的信息,第3个参数表示singer1歌手的name信息
.withColumn("SINGER1",udfGetSingerInfo(col("SINGER_INFO"),lit("singer1"),lit("name")))
//给udf函数设置了SINGER_INFO、singer1、name三个参数,lit表示设置常数列,第1个参数表示要清洗的是歌手的信息,第2个参数表示是要singer1歌手的信息,第3个参数表示singer1歌手的id信息
.withColumn("SINGER1ID",udfGetSingerInfo(col("SINGER_INFO"),lit("singer1"),lit("id")))
.withColumn("SINGER2",udfGetSingerInfo(col("SINGER_INFO"),lit("singer2"),lit("name")))
.withColumn("SINGER2ID",udfGetSingerInfo(col("SINGER_INFO"),lit("singer2"),lit("id")))
.withColumn("AUTH_CO",udfGetAuthCompany(col("AUTH_CO")))
.withColumn("PRDCT_TYPE",udfGetPrdctType(col("PRDCT_TYPE")))
//将清洗的结果注册为临时表TEMP_TO_SONG_INFO_D,表中包括的字段包括两部分,1、使用withColumn函数增加的列,2、原TO_SONG_INFO_D未被覆盖的所有列
.createTempView("TEMP_TO_SONG_INFO_D")
/**
* 清洗数据,将结果保存到 Hive TW_SONG_BASEINFO_D 表中
*/
sparkSession.sql(
"""
| select NBR,
| nvl(NAME,OTHER_NAME) as NAME,
| SOURCE,
| ALBUM,
| PRDCT,
| LANG,
| VIDEO_FORMAT,
| DUR,
| SINGER1,
| SINGER2,
| SINGER1ID,
| SINGER2ID,
| 0 as MAC_TIME,
| POST_TIME,
| PINYIN_FST,
| PINYIN,
| SING_TYPE,
| ORI_SINGER,
| LYRICIST,
| COMPOSER,
| BPM_VAL,
| STAR_LEVEL,
| VIDEO_QLTY,
| VIDEO_MK,
| VIDEO_FTUR,
| LYRIC_FTUR,
| IMG_QLTY,
| SUBTITLES_TYPE,
| AUDIO_FMT,
| ORI_SOUND_QLTY,
| ORI_TRK,
| ORI_TRK_VOL,
| ACC_VER,
| ACC_QLTY,
| ACC_TRK_VOL,
| ACC_TRK,
| WIDTH,
| HEIGHT,
| VIDEO_RSVL,
| SONG_VER,
| AUTH_CO,
| STATE,
| case when size(PRDCT_TYPE) =0 then NULL else PRDCT_TYPE end as PRDCT_TYPE
| from TEMP_TO_SONG_INFO_D
| where NBR != ''
""".stripMargin) //得到一个DataFrame
.write.format("Hive").mode(SaveMode.Overwrite).saveAsTable("TW_SONG_BASEINFO_D")//SaveMode.Overwrite表示使用全量覆盖的方式往表中写数据
println("**** all finished ****")
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号