04.底层requests
说一下爬虫第三方库的利器 requests
1.在网站上我们想去访问一个界面得到相应的内容 只需要鼠标点击一下 就能得到
2.在我们的代码中想去访问一个界面 就要用到requests去向服务器发送请求
requests具备的方法
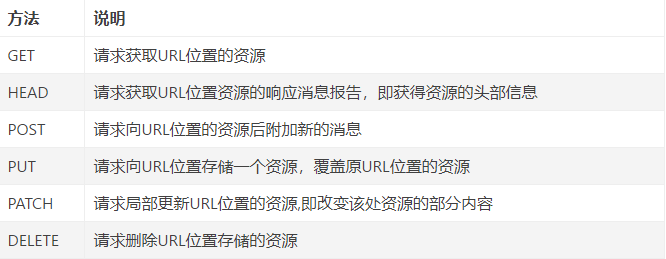
requests最常见的 get 和 post
1.get
import requests # 一个header header = { 'Accept':'', 'Accept-encoding':'', 'Connection':'', 'Cookie':'', 'Host':'', 'user-agent':'', } url = 'https://www.baidu.com/' requests.get(url,headers=header)
2.post
import requests # 一个header header = { 'Accept':'', 'Accept-encoding':'', 'Connection':'', 'Cookie':'', 'Host':'', 'user-agent':'', } data = { '':'', '':'' } url = 'https://www.baidu.com/' requests.get(url,headers=header,data=data)
可以看出 post请求方法比get请求多了一个data参数
但不止这些参数,例如还有:
proxies 代理ip
verify 证书设置
timeout 等待时间
实例:爬取百度首页
F12开发者工具 - F5刷新
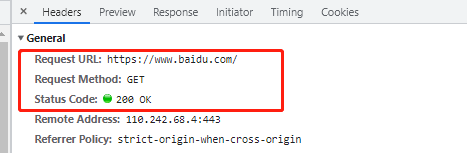
这里我们可以确定他的请求方法 以及他的返回状态码
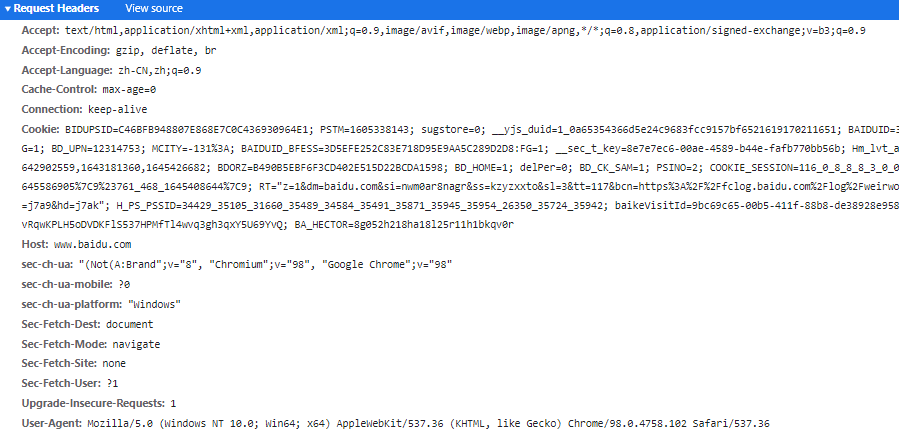
这里是他需要的header,通过测试我们可以去除无用的参数
最终代码:
import requests # 设置header header = { 'Host':'www.baidu.com', 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36', } # 目标网址 url = 'https://www.baidu.com/' # 确定使用get请求方法 并且赋给resp resp = requests.get(url,headers=header) # 打印源代码 print(resp.text)
输出内容:
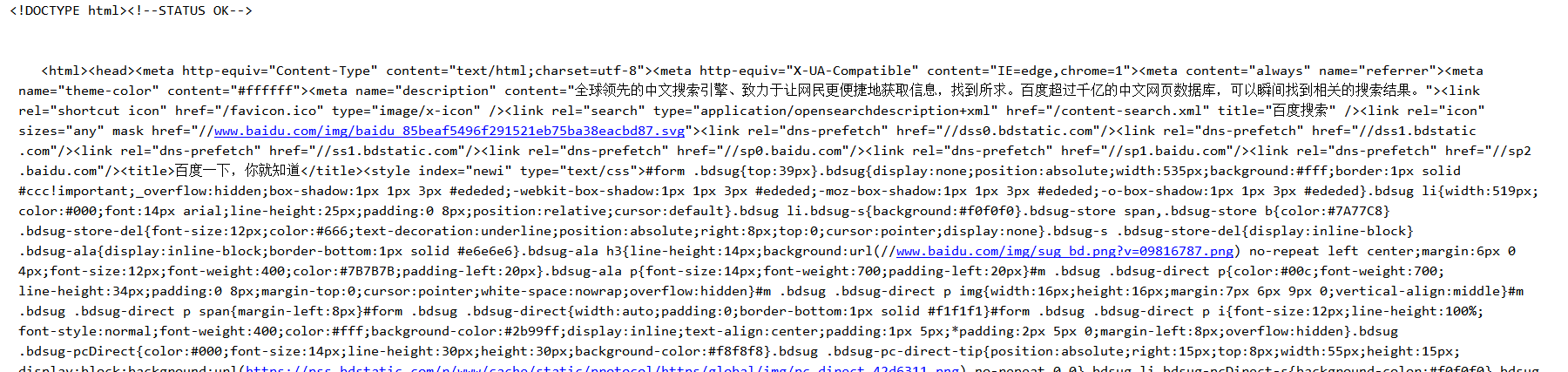
结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号