
neutron二
第四篇neutron— 网络实践
一、虚拟机获取 ip:
用 namspace 隔离 DHCP 服务
Neutron 通过 dnsmasq 提供 DHCP 服务,而 dnsmasq 通过 Linux Network Namespace 独立的为每个 network 服务隔离
在二层网络上,VLAN 可以将一个物理交换机分割成几个独立的虚拟交换机。类似地,在三层网络上,Linux network namespace 可以将一个物理三层网络分割成几个独立的虚拟三层网络。
每个 namespace 都有自己独立的网络栈,包括 route table,firewall rule,network interface device 等。
Neutron 通过 namespace 为每个 network 提供独立的 DHCP 和路由服务,从而允许租户创建重叠的网络。如果没有 namespace,网络就不能重叠,这样就失去了很多灵活性。
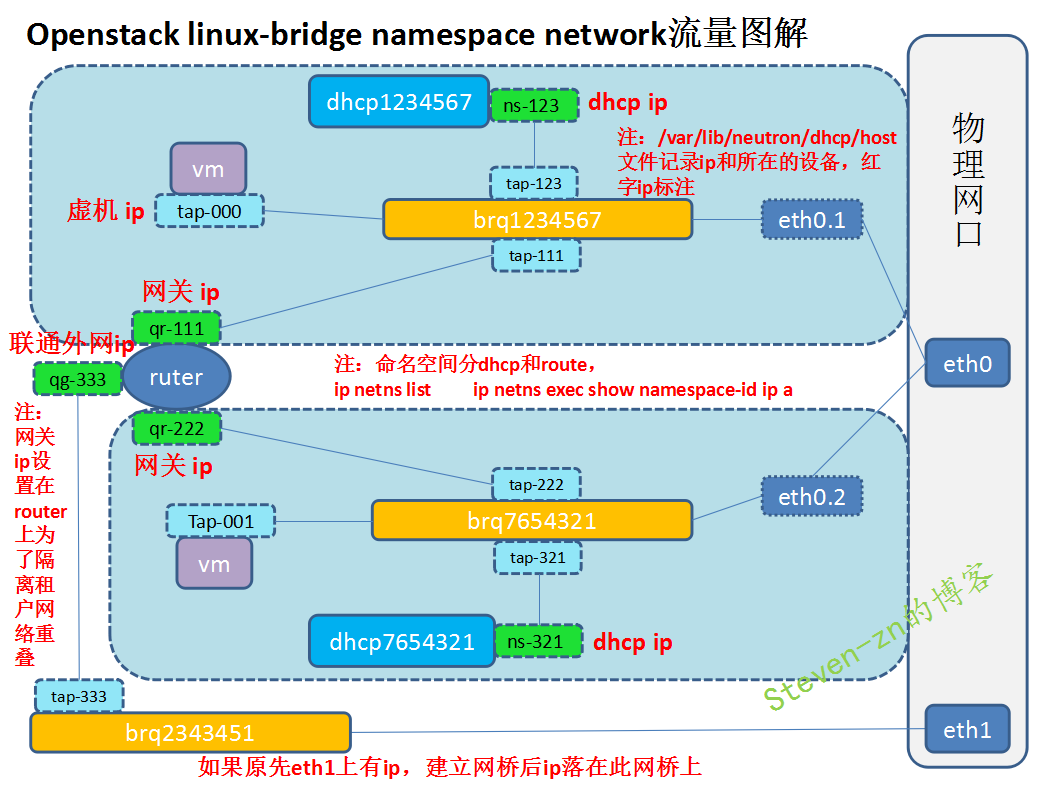
每个 dnsmasq 进程都位于独立的 namespace, 命名为 qdhcp-<network id>,例如 flat_net:
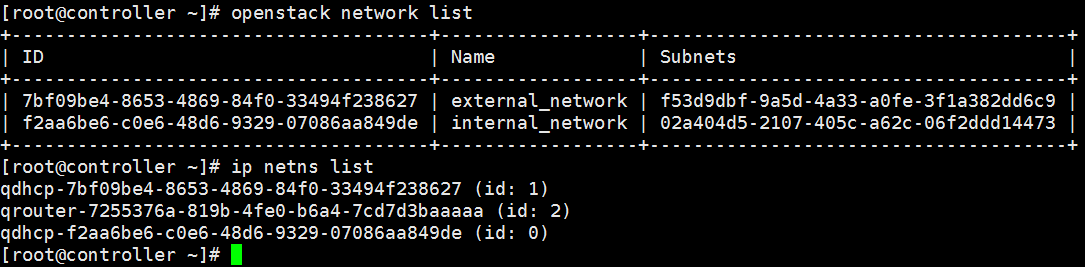
ip netns list 命令列出所有的 namespace
ip netns exec <network namespace name> <command> 管理 namespace
root namespace:
其实,宿主机本身也有一个 namespace,叫 root namespace,拥有所有物理和虚拟 interface device。物理 interface 只能位于 root namespace。
新创建的 namespace 默认只有一个 loopback device。管理员可以将虚拟 interface,例如 bridge,tap 等设备添加到某个 namespace。
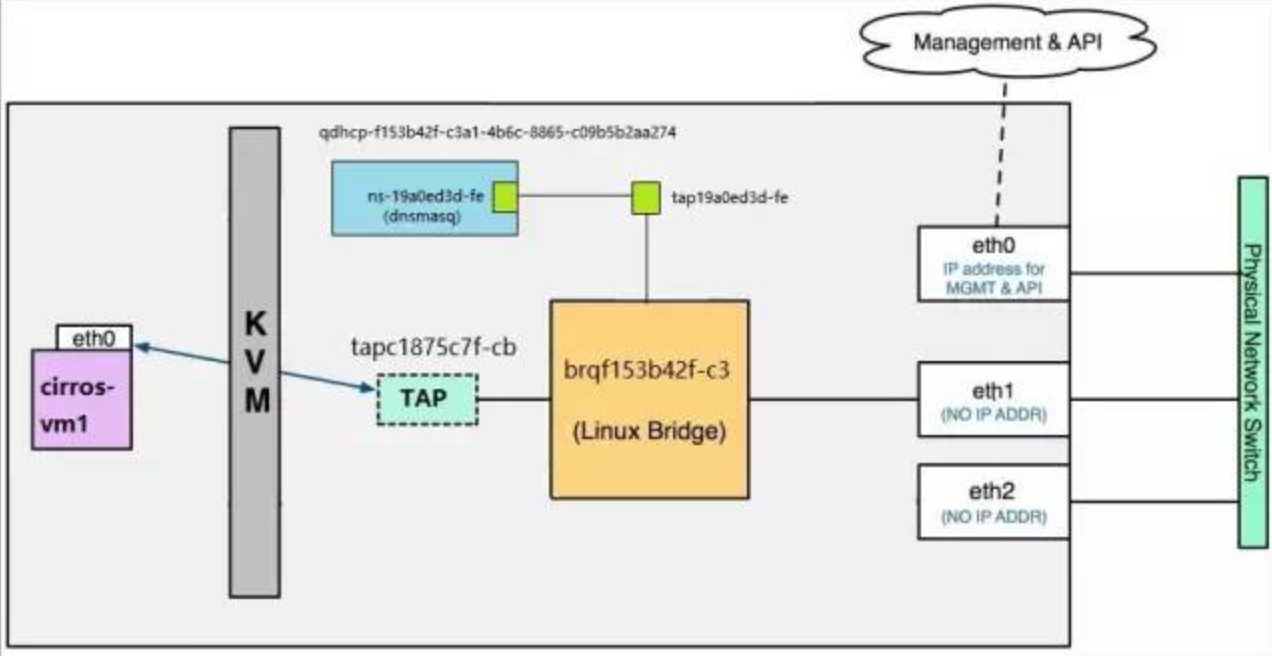
对于 flat_net 的 DHCP 设备 tap19a0ed3d-fe,需要将其放到 namespace qdhcp-7bf09be4-8653-4869-84f0-33494f238627 中,但这样会带来一个问题:tap19a0ed3d-fe 将无法直接与 root namespace 中的 bridge 设备 brqf153b42f-c3 连接。
Neutron 使用 veth pair 解决了这个问题。
veth pair 是一种成对出现的特殊网络设备,它们象一根虚拟的网线,可用于连接两个 namespace。向 veth pair 一端输入数据,在另一端就能读到此数据。
tap19a0ed3d-fe 与 ns-19a0ed3d-fe 就是一对 veth pair,它们将 qdhcp-f153b42f-c3a1-4b6c-8865-c09b5b2aa274 连接到 brqf153b42f-c3。
如下图所示:
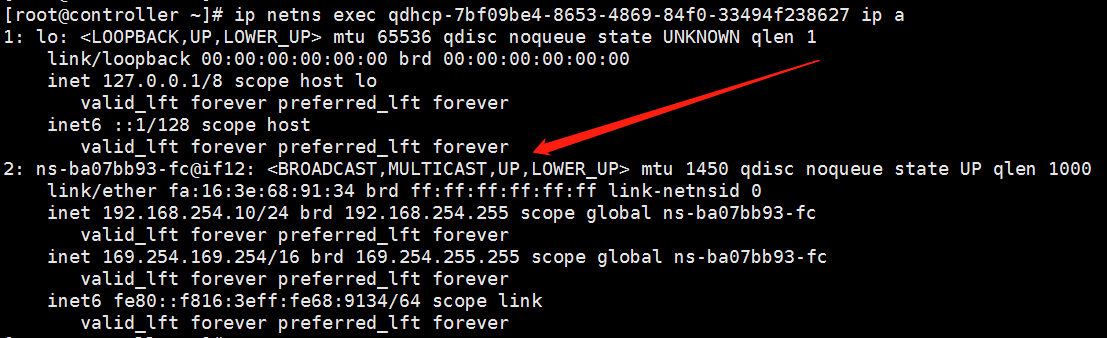
可以通过 ip netns exec qdhcp-7bf09be4-8653-4869-84f0-33494f238627 ip a命令查看ns-ba07bb93配置:
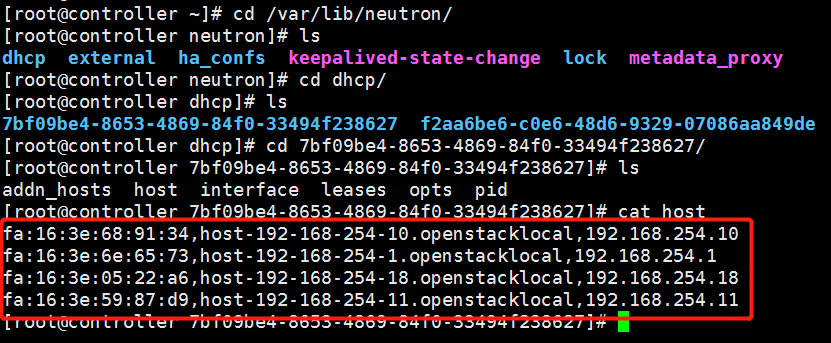
获取 dhcp IP 过程分析
在创建 instance 时,Neutron 会为其分配一个 port,里面包含了 MAC 和 IP 地址信息。这些信息会同步更新到 dnsmasq 的 host 文件。如下图所示:
同时 nova-compute 会设置虚机 VIF 的 MAC 地址。


一切准备就绪,instance 获取 IP 的过程如下:
1. vm 开机启动,发出 DHCPDISCOVER 广播,该广播消息在整个 net 中都可以被收到。
2. 广播到达 veth tap19a0ed3d-fe,然后传送给 veth pair 的另一端 ns-19a0ed3d-fe。dnsmasq 在它上面监听,dnsmasq 检查其 host 文件,发现有对应项,于是dnsmasq 以 DHCPOFFER 消息将 IP(192.168.254.18)、子网掩码(255.255.255.0)、地址租用期限等信息发送给 vm。
3. vm 发送 DHCPREQUEST 消息确认接受此 DHCPOFFER。
4. dnsmasq 发送确认消息 DHCPACK,整个过程结束。
二、VXLAN简介:
overlay network概念:
overlay network 是指建立在其他网络上的网络。overlay network 中的节点可以看作通过虚拟(或逻辑)链路连接起来的。overlay network 在底层可能由若干物理链路组成,但对于节点,不需要关心这些底层实现。
例如 P2P 网络就是 overlay network,隧道也是。vxlan 和 gre 都是基于隧道技术实现的,它们也都是 overlay network。
目前 linux bridge 只支持 vxlan,不支持 gre;
open vswitch 两者都支持。vxlan 与 gre 实现非常类似,而且 vxlan 用得较多,所以本教程只介绍 vxlan。
VXLAN简介:
VXLAN 为 Virtual eXtensible Local Area Network。正如名字所描述的,VXLAN 提供与 VLAN 相同的以太网二层服务,但拥有更强的扩展性和灵活性。与 VLAN 相比,
VXLAN 有下面几个优势:
1. 支持更多的二层网段。
VLAN 使用 12-bit 标记 VLAN ID,最多支持 4094 个 VLAN,这对大型云部署会成为瓶颈。VXLAN 的 ID (VNI 或者 VNID)则用 24-bit 标记,支持 16777216 个二层网段。
2. 能更好地利用已有的网络路径。
VLAN 使用 Spanning Tree Protocol 避免环路,这会导致有一半的网络路径被 block 掉。VXLAN 的数据包是封装到 UDP 通过三层传输和转发的,可以使用所有的路径。
3. 避免物理交换机 MAC 表耗尽。
由于采用隧道机制,TOR (Top on Rack) 交换机无需在 MAC 表中记录虚拟机的信息。
VXLAN 封装和包格式:
VXLAN 是将二层建立在三层上的网络。通过将二层数据封装到 UDP 的方式来扩展数据中心的二层网段数量。
VXLAN 是一种在现有物理网络设施中支持大规模多租户网络环境的解决方案。VXLAN 的传输协议是 IP + UDP。
VXLAN 定义了一个 MAC-in-UDP 的封装格式。在原始的 Layer 2 网络包前加上 VXLAN header,然后放到 UDP 和 IP 包中。通过 MAC-in-UDP 封装,VXLAN 能够在 Layer 3 网络上建立起了一条 Layer 2 的隧道。
VXLAN 包的格式如下:
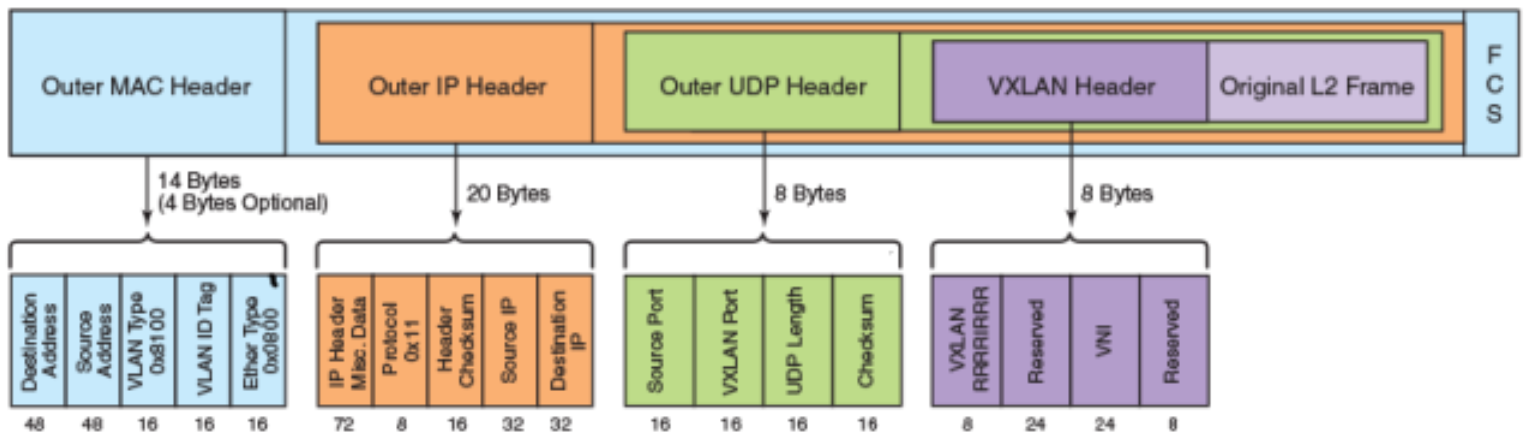
如上图所示,VXLAN 引入了 8-byte VXLAN header,其中 VNI 占 24-bit。VXLAN 和原始的 L2 frame 被封装到 UDP 包中。这 24-bit 的 VNI 用于标示不同的二层网段,能够支持 16777216 个 LAN。
VXLAN Tunnel Endpoint
VXLAN 使用 VXLAN tunnel endpoint (VTEP) 设备处理 VXLAN 的封装和解封。每个 VTEP 有一个 IP interface,配置了一个 IP 地址。VTEP 使用该 IP 封装 Layer 2 frame,并通过该 IP interface 传输和接收封装后的 VXLAN 数据包。
下面是 VTEP 的示意图:
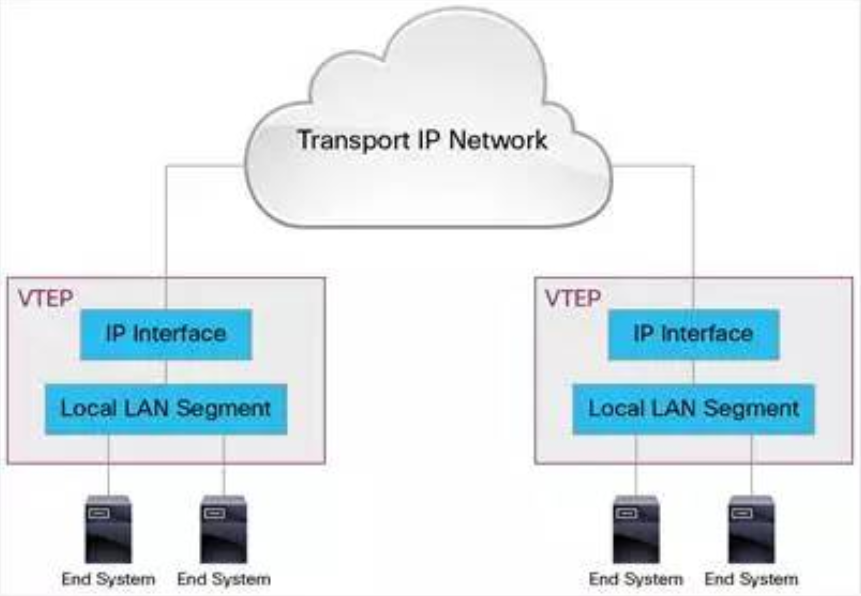
VXLAN 独立于底层的网络拓扑;反过来,两个 VTEP 之间的底层 IP 网络也独立于 VXLAN。VXLAN 数据包是根据外层的 IP header 路由的,该 header 将两端的 VTEP IP 作为源和目标 IP。
VXLAN 封装和转发包的过程,以及 Linux 对 VXLAN 的原生支持
VXLAN 包转发流程
VXLAN 在 VTEP 间建立隧道,通过 Layer 3 网络传输封装后的 Layer 2 数据。下面例子演示了数据如何在 VXLAN 上传输:
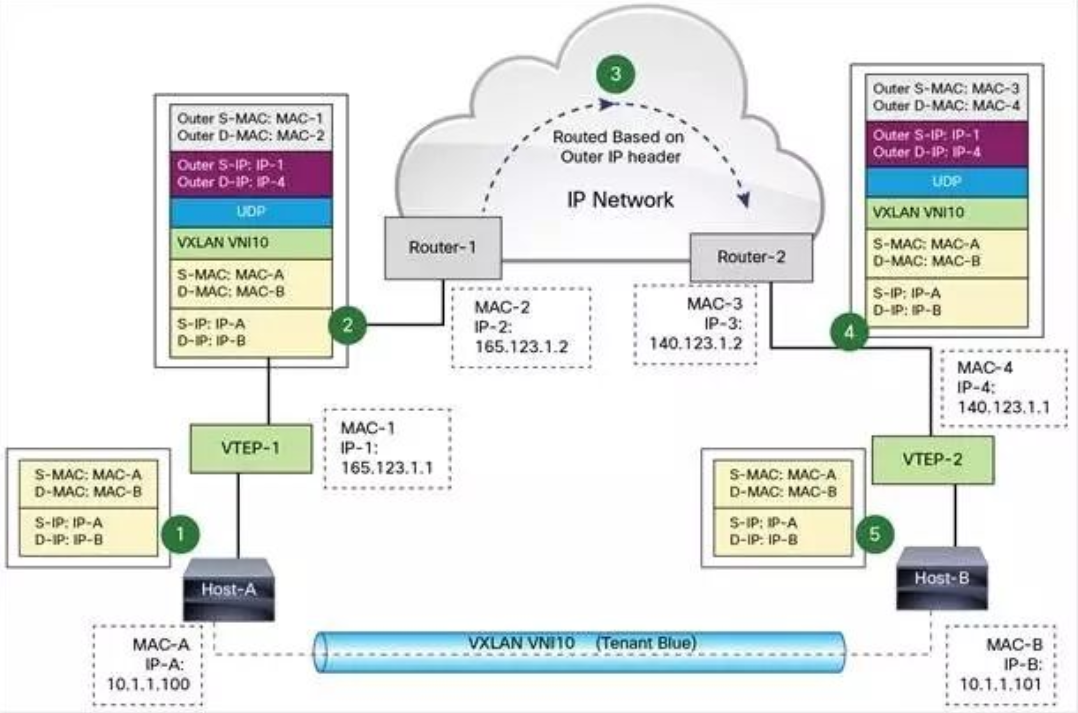
图中 Host-A 和 Host-B 位于 VNI 10 的 VXLAN,通过 VTEP-1 和 VTEP-2 之间建立的 VXLAN 隧道通信。数据传输过程如下:
1. Host-A 向 Host-B 发送数据时,Host-B 的 MAC 和 IP 作为数据包的目标 MAC 和 IP,Host-A 的 MAC 作为数据包的源 MAC 和 IP,然后通过 VTEP-1 将数据发送出去。
2. VTEP-1 从自己维护的映射表中找到 MAC-B 对应的 VTEP-2,然后执行 VXLAN 封装,加上 VXLAN 头,UDP 头,以及外层 IP 和 MAC 头。此时的外层 IP 头,目标地址为 VTEP-2 的 IP,源地址为 VTEP-1 的 IP。同时由于下一跳是 Router-1,所以外层 MAC 头中目标地址为 Router-1 的 MAC。
3. 数据包从 VTEP-1 发送出后,外部网络的路由器会依据外层 IP 头进行路由,最后到达与 VTEP-2 连接的路由器 Router-2。
4. Router-2 将数据包发送给 VTEP-2。VTEP-2 负责解封数据包,依次去掉外层 MAC 头,外层 IP 头,UDP 头 和 VXLAN 头。VTEP-2 依据目标 MAC 地址将数据包发送给 Host-B。
上面的流程我们看到 VTEP 是 VXLAN 的最核心组件,负责数据的封装和解封。隧道也是建立在 VTEP 之间的,VTEP 负责数据的传送。
VTEP 是如何提前获知 IP -- MAC -- VTEP 相关信息的呢?
答案是:
1. Neutron 知道每一个 port 的状态和信息; port 保存了 IP,MAC 相关数据。
2. instance 启动时,其 port 状态变化过程为:down -> build -> active。
3. 每当 port 状态发生变化时,Neutron 都会通过 RPC 消息通知各节点上的 Neutron agent,使得 VTEP 能够更新 VM 和 port 的相关信息。
VTEP 可以根据这些信息判断出其他 Host 上都有哪些 VM,以及它们的 MAC 地址,这样就能直接与之通信,从而避免了不必要的隧道连接和广播。
Linux 对 VXLAN 的支持
VTEP 可以由专有硬件来实现,也可以使用纯软件实现。目前比较成熟的 VTEP 软件实现包括:
1. 带 VXLAN 内核模块的 Linux
2. Open vSwitch
我们先来看 Linux 如何支持 VXLAN
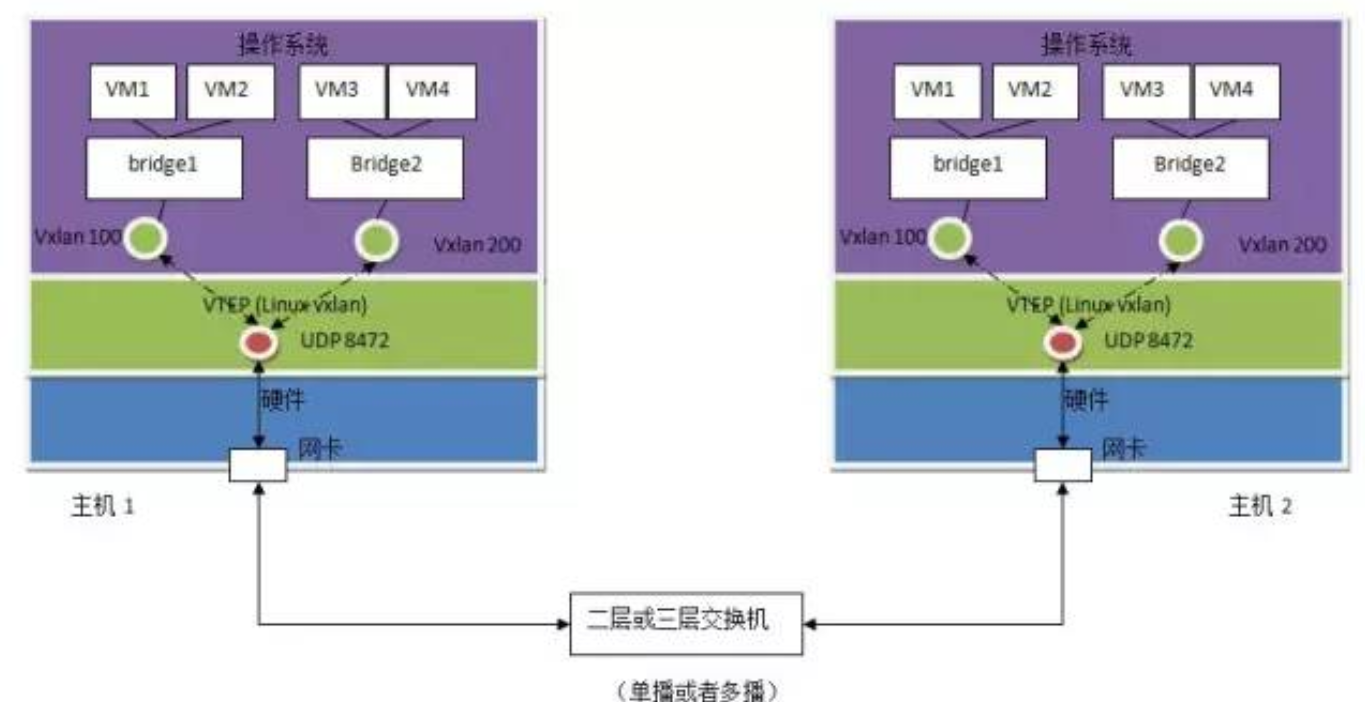
实现方式:
1. Linux vxlan 创建一个 UDP Socket,默认在 8472 端口监听。
2. Linux vxlan 在 UDP socket 上接收到 vxlan 包后,解包,然后根据其中的 vxlan ID 将它转给某个 vxlan interface,然后再通过它所连接的 linux bridge 转给虚机。
3. Linux vxlan 在收到虚机发来的数据包后,将其封装为多播 UDP 包,从网卡发出。
ML2 mechanism driver: Linux Bridge 和 Open vSwitch
网卡分配示例:
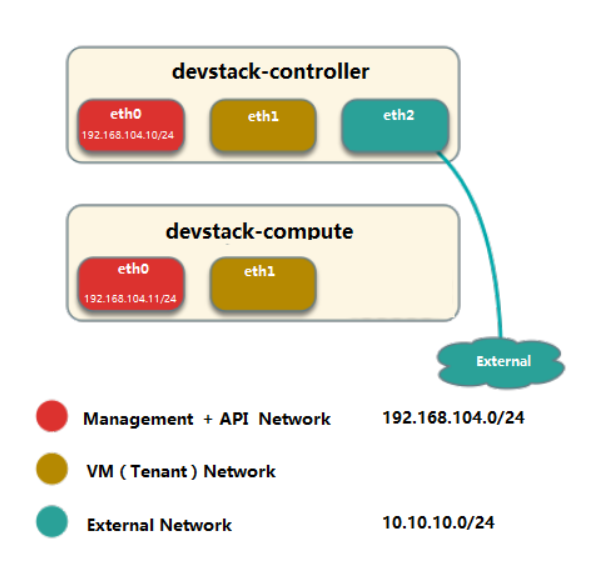
- 控制节点三个网卡(eth0, eth1, eth2),计算节点两网卡(eth0, eth1)。
- 合并 Management 和 API 网络,使用 eth0,IP 段为 192.168.104.0/24。
- VM 网络使用 eht1。
- 控制节点的 eth2 与 External 网络连接,IP 段为 10.10.10.0/24。
Linux Bridge :
Open vSwitch:
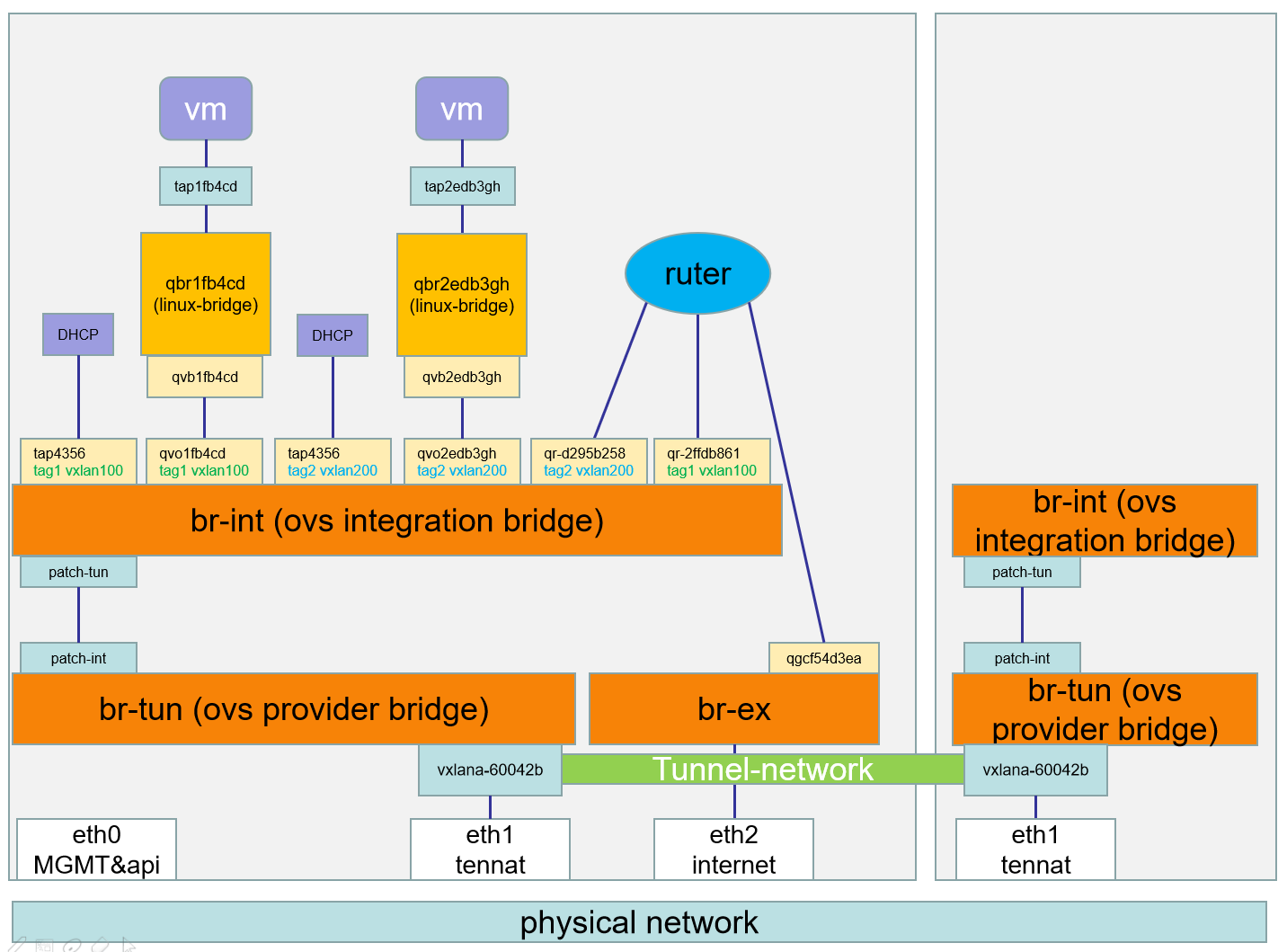
Open vSwitch 中的网络设备:
br-ex:连接外部(external)网络的网桥。
br-int:集成(integration)网桥,所有 instance 的虚拟网卡和其他虚拟网络设备都将连接到该网桥。
br-tun:隧道(tunnel)网桥,基于隧道技术的 VxLAN 和 GRE 网络将使用该网桥进行通信。
tap interface:命名为 tapXXXX。
linux bridge:命名为 qbrXXXX。
veth pair:命名为 qvbXXXX, qvoXXXX
OVS integration bridge:命名为 br-int。
OVS patch ports:命名为 int-br-ethX 和 phy-br-ethX(X 为 interface 的序号)。
OVS provider bridge:命名为 br-ethX(X 为 interface 的序号)。
物理 interface:命名为 ethX(X 为 interface 的序号)。
OVS tunnel bridge:命名为 br-tun。
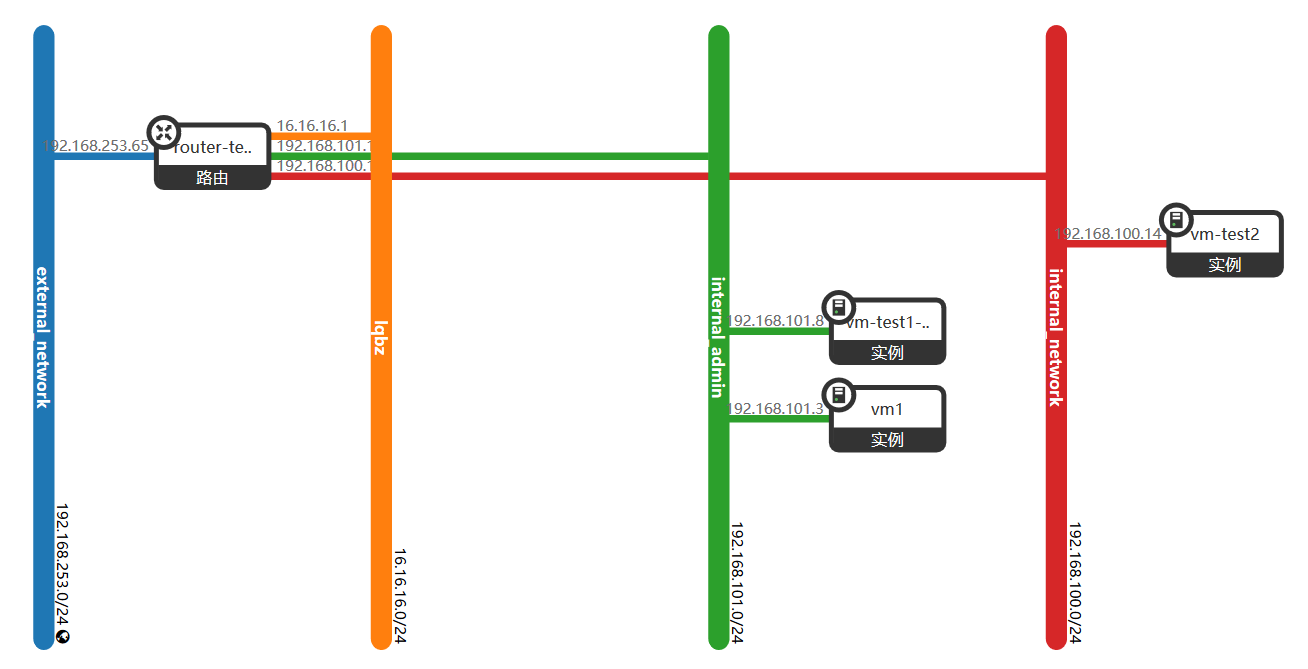
三、三层网络介绍:
虚拟机访问外网
(1)虚拟机中访问一个外网地址192.168.253.3,并用 traceroute 命令跟踪路由查看:
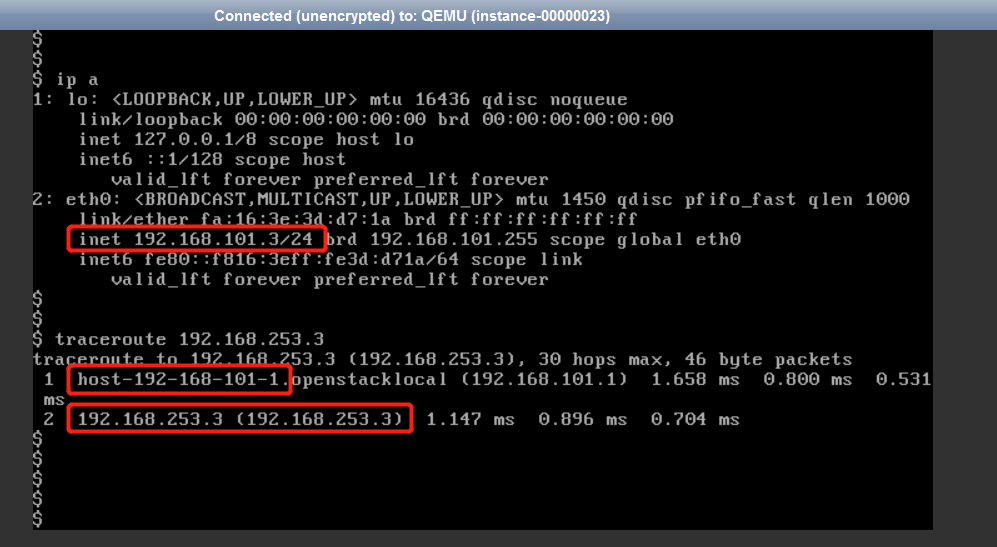
(2)根据网络拓扑,由于虚机访问外网要经过本网段的网关192.168.101.1,然后经过路由的外网接口转发出去,到达192.168.253.3
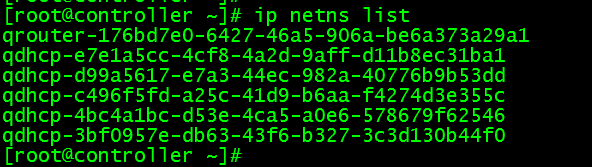
查看路由命名空间:
ip netns list
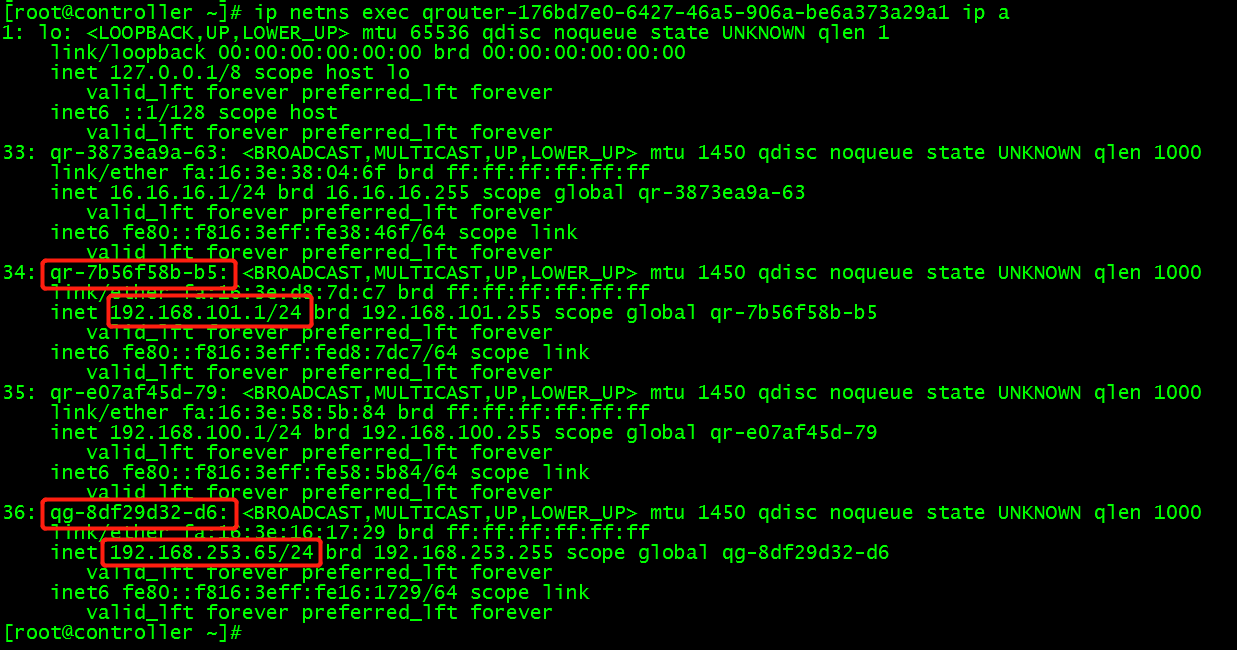
(3)查看路由命名空间的网络配置,查到路由连接外网的端口和ip:
ip netns exec qrouter-176bd7e0-6427-46a5-906a-be6a373a29a1 ip a
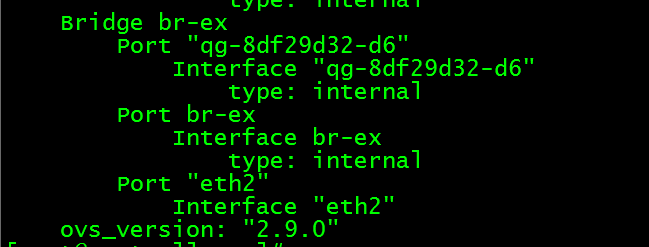
路由上的外网端口正好接到外网网桥br-ex上:ovs-vsctl show 查看
(4)查看路由iptables NAT 转发规则,记录对私网做的SNAT
ip netns exec qrouter-176bd7e0-6427-46a5-906a-be6a373a29a1 iptables -t nat -L
ip netns exec qrouter-176bd7e0-6427-46a5-906a-be6a373a29a1 iptables -t nat -S
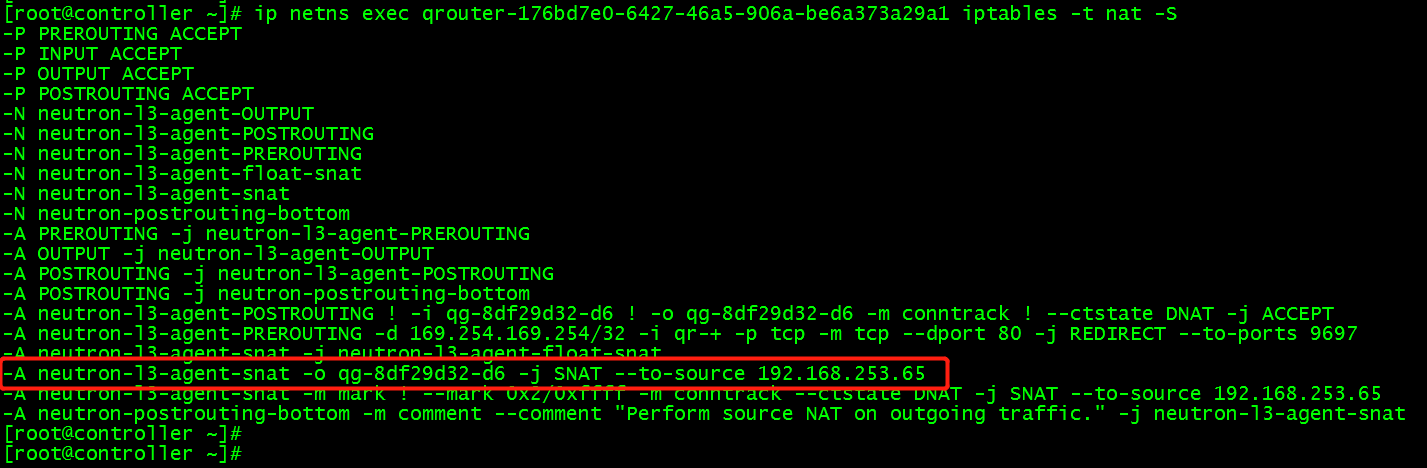
规则解释: -A neutron-l3-agent-snat -o qg-8df29d32-d6 -j SNAT --to-source 192.168.253.65 记录了流入接口qg-8df29d32-d6 的数据包做SNAT(基于源地址转发),将源地址修改为192.168.253.65
(5)验证:
在虚机 ping 192.168.253.3 时, 可以通过 tcpdump 分别观察 router 两个 interface 的 icmp 数据包来验证 SNAT 的行为:
在路由qrouter-176bd7e0-6427-46a5-906a-be6a373a29a1,可查到私有网络的网关接口qr-7b56f58b-b5,并在路由中抓取网关接口的icmp包:
ip netns exec qrouter-176bd7e0-6427-46a5-906a-be6a373a29a1 tcpdump -i qr-7b56f58b-b5 -n icmp

在路由中,抓取路由的外网接口qg-8df29d32-d6的icmp包:
ip netns exec qrouter-176bd7e0-6427-46a5-906a-be6a373a29a1 tcpdump -i qg-8df29d32-d6 -n icmp

外网访问虚机——floating ip原理
SNAT 让 instance 能够直接访问外网,但外网还不能直接访问 instance。因为 instance 没有外网 IP。这里 “直接访问 instance” 是指通信连接由外网发起,例如从外网 SSH 实例。
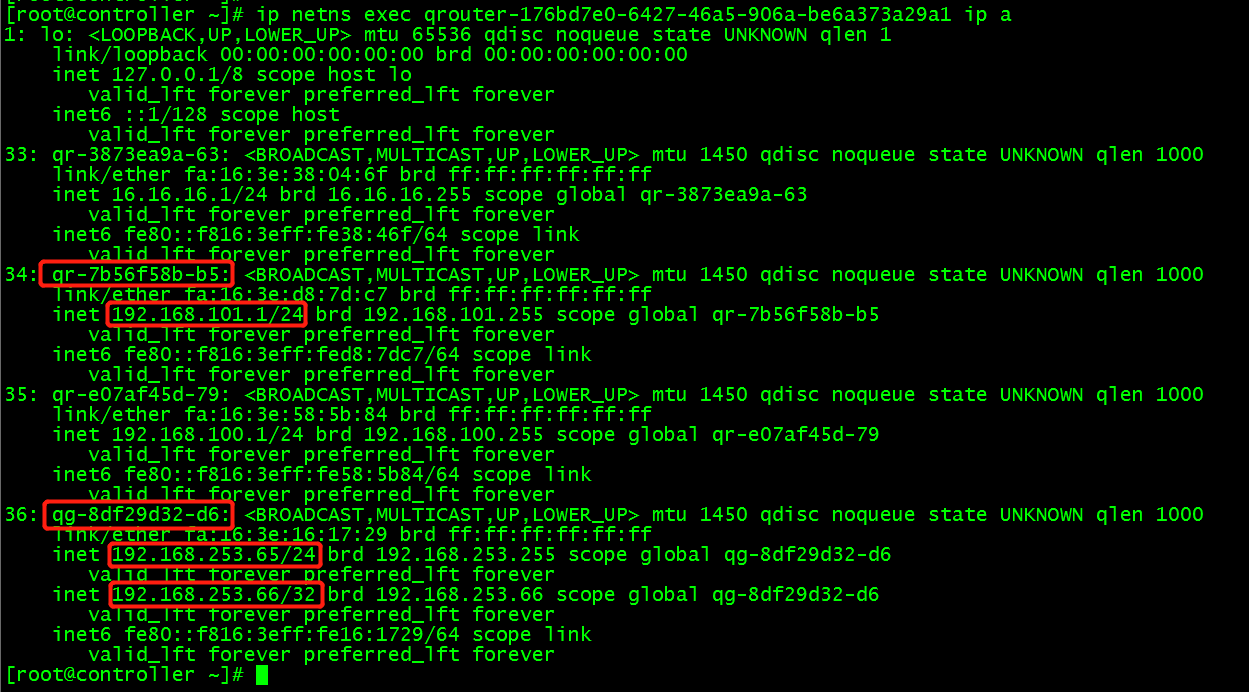
(1)首先将实例绑定浮动 ip192.168.253.66, floating IP 是配置在 router 的外网 interface 上的,再查看 router 的 interface 配置:
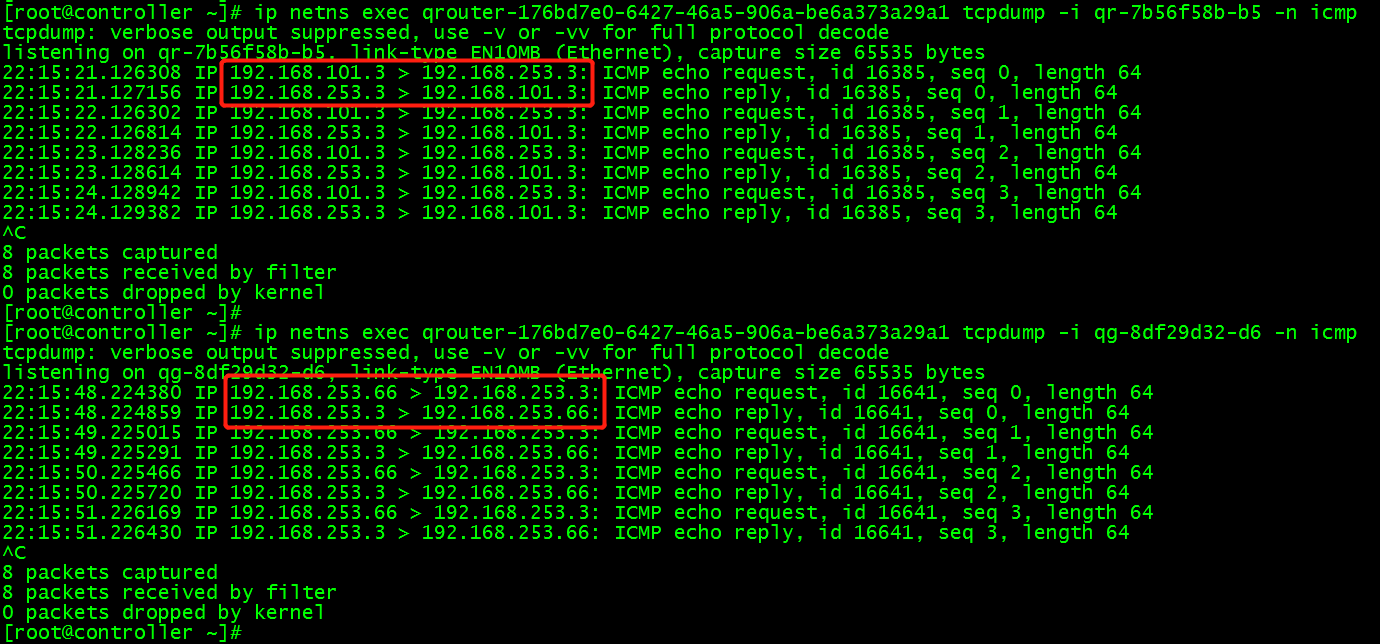
(2)在实例中ping 192.168.253.3 外网地址,在路由的qr-7b56f58b-b5 接口上,实例访问外网ip,外网ip将数据包转发回实例ip;但在路由的qg-8df29d32-d6 接口上,始终是通过 floating IP 192.168.253.66 与外网通信。
(3) 原因是在路由中iptables做了DNA T(基于目的地址转发),查看 router 的 NAT 规则:
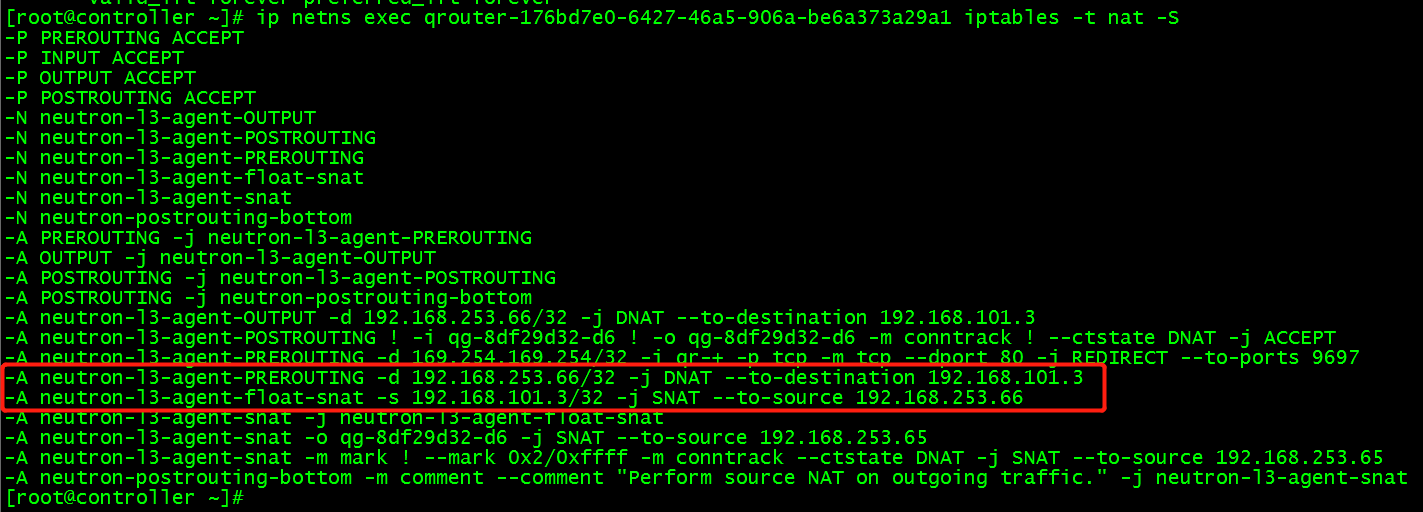
当 router 接收到从外网发来的包,如果目的地址是 floating IP 192.168.254.66,将目的地址修改为实例的 IP 192.168.101.3。这样外网的包就能送达到实例;
当实例发送数据到外网,源地址 192.168.101.3 将被修改为 floating IP 192.168.253.66;
四:neutron配置文件:
neutron.conf
[DEFAULT]
state_path = /var/lib/neutron
auth_strategy = keystone
core_plugin = ml2
service_plugins = router
dhcp_agent_notification = true
allow_overlapping_ips = True
notify_nova_on_port_status_changes = true
notify_nova_on_port_data_changes = true
transport_url = rabbit://openstack:admin@controller
[agent]
[cors]
[cors.subdomain]
[database]
connection = mysql+pymysql://neutron:NEUTRON_DBPASS@controller/neutron
[keystone_authtoken]
auth_uri = http://controller:5000
auth_url = http://controller:35357
memcached_servers = controller:11211
auth_type = password
project_domain_name = default
user_domain_name = default
project_name = service
username = neutron
password = neutron
[matchmaker_redis]
[nova]
region_name = RegionOne
auth_url = http://controller:35357
auth_type = password
project_domain_name = default
project_name = service
user_domain_name = default
username = nova
password = nova
[oslo_concurrency]
lock_path = $state_path/lock
[oslo_messaging_amqp]
[oslo_messaging_kafka]
[oslo_messaging_notifications]
[oslo_messaging_rabbit]
[oslo_messaging_zmq]
[oslo_middleware]
[oslo_policy]
[qos]
[quotas]
[ssl]
ml2_conf.ini
[DEFAULT]
[ml2]
type_drivers = flat,vxlan
tenant_network_types = vxlan
mechanism_drivers = openvswitch,l2population
extension_drivers = port_security
[ml2_type_flat]
[ml2_type_geneve]
[ml2_type_gre]
[ml2_type_vlan]
[ml2_type_vxlan]
vni_ranges = 1:1000
[securitygroup]
enable_ipset = true
openvswitch_agent.ini
[DEFAULT]
[agent]
tunnel_types = vxlan
l2_population = True
[ovs]
tunnel_bridge = br-tun
local_ip = 192.168.254.63
bridge_mappings =
[securitygroup]
firewall_driver = iptables_hybrid
enable_security_group = true
[xenapi]
l3_agent.ini
[DEFAULT]
interface_driver = openvswitch
external_network_bridge = br-ex
[agent]
[ovs]
metadata_agent.ini
[DEFAULT]
nova_metadata_ip = controller
metadata_proxy_shared_secret = METADATA_SECRET
[agent]
[cache]
dhcp_agent.ini
[DEFAULT]
interface_driver = openvswitch
dhcp_driver = neutron.agent.linux.dhcp.Dnsmasq
enable_isolated_metadata = true
[agent]
[ovs]
注意:配置完配置文件后,提前准备ovs外网用的网桥,之后同步数据库,启动服务:
(控制)yum install openstack-neutron openstack-neutron-ml2 openvswitch openstack-neutron-openvswitch ebtables -y
systemctl enable neutron-server.service neutron-dhcp-agent.service openvswitch neutron-openvswitch-agent neutron-metadata-agent.service
systemctl start neutron-server.service neutron-dhcp-agent.service openvswitch neutron-openvswitch-agent neutron-metadata-agent.service
ovs-vsctl add-br br-ex
ovs-vsctl add-port br-ex eth2
systemctl enable neutron-l3-agent.service
systemctl start neutron-l3-agent.service
(计算)yum install openvswitch openstack-neutron-openvswitch ebtables ipset
systemctl enable openvswitch neutron-openvswitch-agent
systemctl start openvswitch neutron-openvswitch-agent
systemctl stop openvswitch neutron-openvswitch-agent
