
cat userlist的理解
学习要求
Linux文件系统的三层抽象是什么?
写出Cat userlist的过程,要详述目录文件,i-node.数据块,要画图示意
假设块大小为4k, userlist的大小不小于10k,自己假设大小
Linux文件系统的三层抽象
文件系统可以用来储存文件内容,文件属性和目录。Unix把磁盘块分成了3个部分来储存上述信息。
超级块:文件系统中第一个块被称为超级块。这个块存放文件系统本身的结构信息。比如,超级块记录了每个区域的大小,超级块也存放未被使用的磁盘块的信息。
I-节点表:超级块的下一个部分就是i-节点表。每个i-节点就是一个对应一个文件/目录的结构,这个结构它包含了一个文件的长度、创建及修改时间、权限、所属关系、磁盘中的位置等信息。一个文件系统维护了一个索引节点的数组,每个文件或目录都与索引节点数组中的唯一一个元素对应。系统给每个索引节点分配了一个号码,也就是该节点在数组中的索引号,称为索引节点号
数据区:文件系统的第3个部分是数据区。文件的内容保存在这个区域。磁盘上所有块的大小都一样。如果文件包含了超过一个块的内容,则文件内容会存放在多个磁盘块中。一个较大的文件很容易分布上千个独产的磁盘块中。
写出Cat userlist的过程,要详述目录文件,i-node.数据块,要画图示意。
考虑以下指令:

当who命令完成时,文件系统中增加了一个存放命令who输出内容的新文件,cat命令读取文件内容并将其打印到了终端上
文件有内容和属性,内核将文件内容存放在数据区,文件属性存放在i-节点,文件名存放在目录
图片参考https://blog.csdn.net/zhizhengguan/article/details/117295661
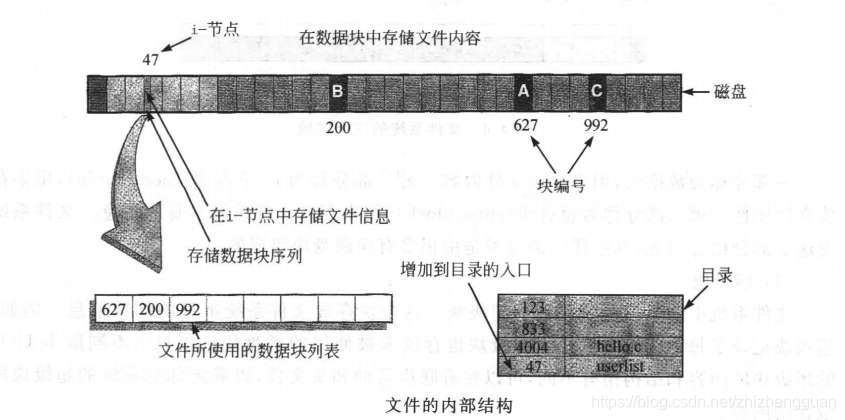
——cat的过程,实际上是读取文件并将其打印到终端的过程
具体来说:
(1)在目录中寻找文件名
文件名存储在目录文件中。内核在目录文件中寻找包含所在的记录对应编号的i-node节点
(2)定位i-节点号并读取内容
内核在文件系统中的i-node区域找到i-节点(假设为50)。定位一个i-节点一些简单的计算,所有的i-节点号大小相同,每个磁盘块都包含相同数量的i-节点。为了提高访问效率,内核有可能将i-节点置于缓冲区中。i-节点包含数据块编号的列表
(3)访问存储文件内容的数据块
通过以上调用构成,内核已经可以知道文件内容存放在哪些数据块上,以及它们的顺序。由于cat不断的调用read函数,使得内核不断将字节从磁盘复制到内核缓存区,进而到达用户空间
所有从文件读取数据的命令,比如,cat、cp、more、who等,都是将文件名传给open来访问文件内容,对open的每次调用都是先在目录中寻找文件名,然后根据目录中的i-节点号获得文件的属性,最终找到文件的内容。
inode具体信息
文件字节数
文件类型
文件权限
文件的User ID
文件的Group ID
文件在磁盘中的位置
文件的节点号
文件链接数
文件最后修改的时间
文件最后使用(读取或执行)的时间
文点自身最后改变的时间,如设置权限。


posted on 2022-10-22 15:43 20201321周慧琳 阅读(57) 评论(0) 编辑 收藏 举报

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具