

5分钟了解图数据库Neo4j的使用
1.图数据库安装与配置
1.1安装与配置
配置path = %NEO4J_HOME%\bin
启动命令:neo4j console
web访问:http://localhost:7474
1.2权限管理
:server change-password 修改密码
:server user list 可视化界面管理用户权限
:server disconnect 退出当前用户
2.从csv导入数据
(1)停掉服务
(2)删除 graph.db 目录
(3)报错,解决办法:将bin/neo4j-import.ps1文件的相对路径改为绝对路径
(4)准备CSV文件。举例如下,记录为电影,明星 以及其中存在的一个扮演角色关系。CSV格式为:
movies.csv
movieId:ID,title,year:int,:LABEL
tt0133093,"The Matrix",1999,Movie
tt0234215,"The Matrix Reloaded",2003,Movie;Sequel
tt0242653,"The Matrix Revolutions",2003,Movie;Sequel
actors.csv
personId:ID,name,:LABEL
keanu,"Keanu Reeves",Actor
laurence,"Laurence Fishburne",Actor
carrieanne,"Carrie-Anne Moss",Actor
roles.csv
:START_ID,role,:END_ID,:TYPE
keanu,"Neo",tt0133093,ACTED_IN
keanu,"Neo",tt0234215,ACTED_IN
keanu,"Neo",tt0242653,ACTED_IN
laurence,"Morpheus",tt0133093,ACTED_IN
laurence,"Morpheus",tt0234215,ACTED_IN
laurence,"Morpheus",tt0242653,ACTED_IN
carrieanne,"Trinity",tt0133093,ACTED_IN
carrieanne,"Trinity",tt0234215,ACTED_IN
carrieanne,"Trinity",tt0242653,ACTED_IN
(5) 导入命令:neo4j-import --into graph.db --nodes <节点1.csv> --nodes <节点2.csv> --relationships <关系.csv>
3.常见的CQL命令
以Movie、Actors、Roles 为例,图形如下:
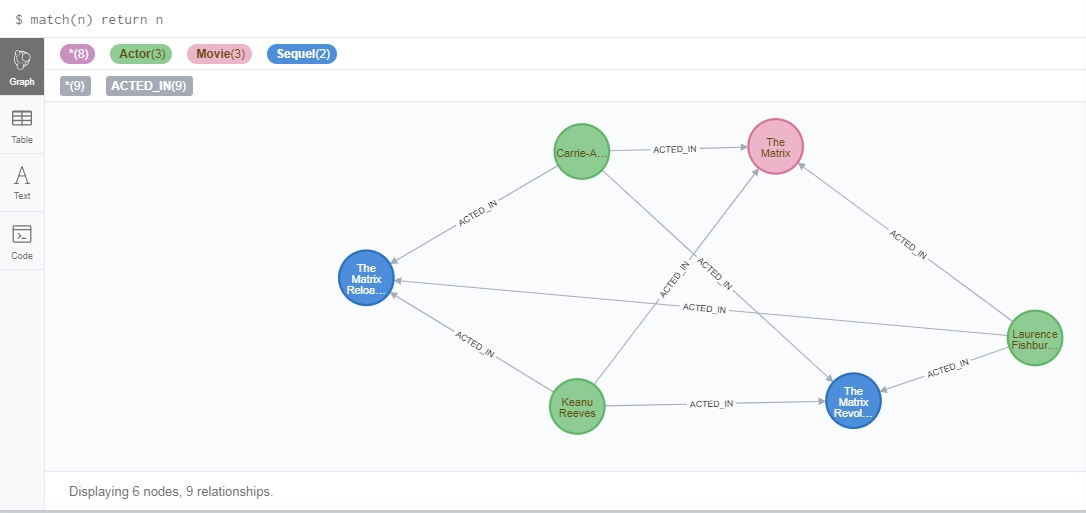
3.1查询
- 查询整个图形
match(n) return n
- 查询year小于2000的电影
match (n)
where n.year < 2000
return n
- 查询带有movie标签的节点
match(n:Movie)
return n
- 查询名字叫Keanu Reeves的演员
match (n{name:'Keanu Reeves'})
return n
- 查询与带Movie标签的节点相关的所有节点
match(n) -- (m:Movie)
return n
- 查询“Keanu Reeves”所有参演过的电影
match (n) -[r:ACTED_IN]-> (m:Movie)
where n.name = 'Keanu Reeves'
return m
match (n{name:'Keanu Reeves'}) -[r:ACTED_IN]-> (m:Movie)
return m
- 查询与“Keanu Reeves”同演过的人
match (a) -[:ACTED_IN]->(m)<-[:ACTED_IN]- (b)
return distinct b
3.2.创建
- 增加拍摄于2010年名叫“super man”的电影
create (n:Movie{title:'super man',year:2010})
return n
- 增加名叫“Jone”的演员
create (n:Actor{name:'Jone'})
return n
- 增加“Jone”和“super man”之间类型为ACTED_IN的关系
match (a{name:'Jone'}),(b{name:'super man'})
create (a) -[r:ACTED_IN]->(b)
return r
3.3更新
- 给“Jone”增加属性age = 40
match(n{name:'Jone'})
set n.age = 40
return n
- 给“super man”增加description = “Hot”
match(n{name:'super man'})
set n.description = 'Hot'
return n
- 给“Jone”和“super man”之间的关系增加description=“first”
match (a{name:'Jone'})-[r]->(b{name:'super man'})
set r.description = 'first'
return r
3.4删除
- 删除id不同,名字相同的重复的演员实体
match (a:Actor),(b:Actor)
where id(a) <> id(b) and a.name = b.name
delete b
return b
3.5函数
- 查询name=“Jone”的节点的ID
match (n{name:'Jone'})
return id(n)
- 查询“Jone”和“super man”之间关系类型
match (a{name:'Jone'})-[r]->(b{name:'super man'})
return type(r)
- 查询name=“Jone”的节点的所有属性名
match (n{name:'Jone'})
return keys(n)
- 查询name=“Jone”的节点的所有属性名及值
match (n{name:'Jone'})
return properties(n)
- 统计带标签“Movie”的节点数量
match (n:Movie)
with count(*) as f
return f
- 给所有节点增加时间戳
match (n)
set n.timestamp = timestamp()
3.6路径
- 查询与“Keanu Reeves”距离1-3度的节点
match (n{name:'Keanu Reeves'}) -[*1..3]- (m)
return m
- 查询“Laurence Fishburne”和“Keanu Reeves”的最短路径
match p = shortestPath ((a{name:'Laurence Fishburne'})-[*]-(b{name:'Keanu Reeves'}))
return p
4.Python实现neo4j的访问
from py2neo import Database, Graph, Node, Relationship # 建立连接 db = Database("http://127.0.0.1:7474") graph = Graph("bolt://127.0.0.1:7687", username="neo4j", password="123456") try: for node in graph.nodes: print(node) except: print("key error!") # 匹配 n = graph.nodes.match("Keanu Reeves") for i in n: print(i) try: for r in graph.relationships: print(r) except: print("key error!") # 提交任务 tx = graph.begin() a = Node("Actor", name="张鹤伦") tx.create(a) b = Node("Actor", name="杨九郎") ab = Relationship(a, "师兄弟", b) tx.create(ab) tx.commit() # 判断是否存在 isExists = graph.exists(ab) print("is Exists=" + str(isExists)) # 执行CQL命令 graph.run('create(p:Actor{name:"周九良"})') ans = graph.run('match(p:Actor) return p.name,p.born').to_ndarray() print(ans)
参考资料:

