
单张图像重建3D人手、人脸和人体
单张图像重建3D人手、人脸和人体

1. 论文简要
为了便于分析人类的行为、互动和情绪,本文从单目图像中计算出人体姿态、手姿态和面部表情的三维模型。为了实现这一点,本文使用数千个3D扫描来训练统一的人体3D模型,SMPL-X,它通过完全铰接的手和富有表情的脸来扩展SMPL。没有成对图像和标签,直接回归SMPL-X的参数是非常具有挑战性。因此,本文采用SMPLify方法,估计二维特征,然后优化模型参数来拟合特征。本文在以下几个重要方面对SMPLify进行了改进:
-
检测与脸、手和脚对应的2D特征,并将完整的SMPL-X模型与这些特征进行匹配;
-
使用一个大的动作捕捉数据集训练神经网络先验姿态;
-
定义了一种既快速又准确的渗透惩罚方法
-
自动检测性别和合适的身体模型(男性、女性或中性)
-
采用PyTorch实现实现了超过8倍的加速
本文使用新的方法SMPLify-X,使SMPL-X既适合于受控图像,也适合于自然图像,并且一个新的包含100张伪真实标签的图像数据集上评估3D精度。这是迈向从单目RGB数据自动表达人类动作捕获的重要一步。
论文和代码:https://smpl-x.is.tue.mpg.de
2. 背景介绍
人类通常是图片和视频的中心元素。理解他们的姿势,以及他们与世界的互动对整体场景理解至关重要。目前大多数的工作主要在2D上对人体姿态,人手关键点以及人脸进行研究,由于真实的场景是以3D为基础的,并且缺乏3D模型和丰富的3D数据,因此捕捉人体,人手和人脸的3D表面异常困难。为了解决这一问题,第一,需要构建能够自由表达整个人体的模型,第二,需要能够从单张图片中提取这样的模型。
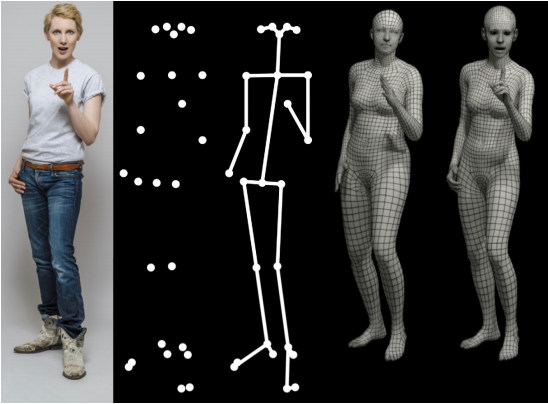
为此本文从从一个大型的三维扫描体中学习新的身体、脸和手模型。新的SMPL- X模型是基于SMPL的,并保留了该模型的优点:与图形软件兼容、简单的参数化、小尺寸、高效、可区分等。本文将SMPL与FLAME模型和MANO人手模型结合起来,然后将这个组合模型得到5586个3D扫描。通过从数据中学习模型,本文捕获了身体、脸和手的形状之间的自然关联。模型的表达能力可以在下图中看到,其中本文将SMPL-X拟合到表达性RGB图像中。SMPL-X免费用于研究用途。

目前有一些方法通过深度学习的方法从单张图片中回归出SMPL的参数,但是要估计带有人手和人脸的3D人体缺乏有效的训练数据。为了解决这一问题,首先,本文使用OpenPose ”自下而上“ 的估计身体、手、脚和脸的二维图像特征,然后使用SMPLify-X方法将SMPL-X模型 “自顶向下” 地匹配到这些2D特性。然后,本文对SMPLify做了几项重大改进。具体来说,本文使用VAE变分自动编码器从大数据集的运动捕捉数据中学习一种新的、性能更好的姿态先验。这个先验是至关重要的,因为从2D特征到3D姿态的映射是不明确的。其次,本文还定义了一个新的(自)渗透惩罚项,它明显比SMPLify中的近似方法更精确和有效;它仍然是可微的。本文训练了一个性别检测器,用它来自动决定使用男性、女性或中性的身体模型。最后,采用直接回归方法来估计SMPL参数的一个动机是SMPLify比较慢。这里本文用PyTorch实现来解决这个问题,通过多块gpu的计算能力,PyTorch实现比相应的Chumpy实现至少快8倍。
3. 相关研究
3.1 人体建模
身体,人脸和人手:3D身体建模的问题以前通过将身体分解成多个部分和分别建模来解决。本文关注的方法是从3D扫描中学习统计形状模型。由于3D人体扫描仪的存在,人们可以通过扫描来了解身体的形状,丰富的形状和姿态空间参数人手模型MANO也是采用的该方法。
统一模型:最相似的模型是Frank和SMPL+H。Frank将三种不同的模型整合到一起在一起:SMPL(无姿态混合形状)的身体,一个艺术家创建的手,和FaceWarehouse模型的脸。最终的模型并不完全真实。SMPL+H从3D扫描学习结合了SMPL身体与3D手模型。手部的形状变化来自全身扫描,而姿态依赖的变形则来自手部扫描的数据集。SMPL+H不包含可变形的人脸。
本文从公开的SMPL+H开始,并将公开的FLAME模型添加到其中。然而,与Frank不同的是,本文不是简单地把它移植到身体上。相反,本文采取完整的模型和拟合5586个3D扫描,并且学习形状和依赖姿势的混合形状。这将产生一个具有一致参数化的自然外观的模型。基于SMPL,它是可区分的并且很容易切换到已经使用SMPL的应用程序中。
3.2 人体结构推理
有很多方法可以从图像或RGB-D估计3D人脸,也有很多方法可以从这些数据估计手部。虽然有许多方法从单个图像估计三维关节的位置,这里本文关注的方法是提取一个完整的三维身体网格(mesh)。
4. 本文方法
下面介绍SMPL-X模型,以及SMPL-X模型拟合单张RGB图像的方法。相较于SMPLify模型,SMPLify模型运用了更好的先验姿态信息,更为详细的碰撞惩罚项,性别判断以及Pytorch的工程加速方法。
4.1 统一模型SMPL-X
本文创建统一的模型SMPL- X,同时对面部、手部和身体的形状参数进行联合训练。SMPL-X使用标准的基于顶点的线性混合蒙皮来学习纠正混合形状,顶点 \(N=10475\) , 关节点 \(K=54\) 包含包括脖子、下巴、眼球和手指的关节。SMPL-X定义为 \(M(\theta,\beta,\psi):\mathbb{R}^{|\theta| \times|\beta| \times|\psi|} \rightarrow \mathbb{R}^{3 N}\) , 姿态参数 \(\theta\in \mathbb{R}^{3(K+1)}\) , 其中 \(K\) 是除全局旋转的关键点的数量。将姿态参数 \(\theta\) 分解为 \(\theta_f\) 下巴关键点,\(\theta_h\) 指关节,\(\theta_b\) 为身体关键点。身体,人脸和人手的形态参数为 \(\beta\in{\mathbb{R}^{|\psi|}}\) 。更具体的表达是:
其中 \(B_S(\beta;\mathcal{S})=\sum_{n=1}^{|\beta|}\beta_n\mathcal{S}_n\) 是形状混合函数,\(\beta\) 是线性形状系数,\(|\beta|\) 为值,\(\mathcal{S}_n\in\mathbb{R}^{3N}\) 是由于不同的人捕捉到的形状变化顶点位移的标准正交主成分量,\(\mathcal{S}=\left[S_{1}, \ldots, S_{|\beta|}\right] \in \mathbb{R}^{3 N \times|\beta|}\) 是所有偏移量的矩阵形式。\(B_{P}(\theta ; \mathcal{P}): \mathbb{R}^{|\theta|} \rightarrow \mathbb{R}^{3 N}\) 为姿态混合形状函数,该函数添加校正顶点位移到模板mesh \(\bar{T}\) :
其中 \(R: \mathbb{R}^{|\theta|}\rightarrow \mathbb{R}^{9K}\) 是将位姿向量 \(\theta\) 映射到由部分相对旋转矩阵组成的向量的函数,这一过程使用Rodrigues公式来计算,\(R_n(\theta)\) 为 \(R(\theta)\) 的 \(n^{th}\) 元素,\(\theta^{*}\) 为剩余姿态向量,$ \mathcal{P}_{n}\in \mathbb{R}^{3N}$ 为顶点位移的标准正交主成分量,\(\mathcal{P}=[P_1,...,P_{9K}]\in \mathbb{R}^{3N\times 9K}\) 为姿态混合形状的矩阵。\(B_{E}(\psi ; \mathcal{E})=\sum_{n=1}^{|\psi|} \psi_{n} \mathcal{E}\) 混合形状函数,其中 \(\mathcal{E}\) 为由于面部表情捕捉变化的主分量和 \(ψ\) 是主成分系数。由于三维关节位置 \(J\) 在不同形状的身体之间是不同的,因此是身体形状的函数 \(J(\beta)=\mathcal{J}\left(\bar{T}+B_{S}(\beta ; \mathcal{S})\right)\) ,其中 \(\mathcal{J}\) 为一个稀疏线性回归器,从网格顶点回归三维关节位置。一个标准的线性混合蒙皮函数 \(W(.)\), 将 \(T_p(.)\) 中的顶点围绕估计关键点 \(J(\beta)\) 旋转。
本文从设计好的3D模板开始,其脸和手匹配FLAME和MANO的模板。本文将该模板拟合到4个三维人体扫描数据集上,得到作为SMPL-X的三维对准训练数据。形状空间参数 \(\{S\}\) 是在3800个A姿态校准上训练的,捕捉不同身份的变化。对1786种不同姿态的姿态对准进行身体姿态空间参数 \({W,P,J}\) 的训练。由于全身扫描的手和脸的分辨率有限,本文利用MANO和FLAME的参数分别从1500只手和3800个头部高分辨率扫描学习。更具体地说,本文利用了姿势空间,姿态修正混叠形状的MANO人手模型以及表达空间\(\mathcal{E}\) 的FLAME模型。
手指有30个关节,对应90个姿态参数(每个关节轴角旋转3个自由度)。SMPL-X为手使用了一个较低维的PCA姿态空间:\(\theta_{h}=\sum_{n=1}^{\left|m_{h}\right|} m_{h_{n}} \mathcal{M}\) ,其中 \(\mathcal{M}\) 是捕捉手指姿态变化的主成分量和 \(m_h\) 是对应的主成分分析系数。如上所述,本文利用MANO的主成分位姿空间,即在一个大的训练上三维关节人的手数据集。SMPL-X中的模型参数为1119: 75用于全局体旋转和身体,眼睛,下巴的关节,24个参数为较低维的手部姿势PCA空间,10个参数用于主体形状,10个参数用于面部表情。此外,还有单独的男性和女性模型,当性别已知时使用,当性别未知时使用两种性别构建的形状空间。SMPL-X具有现实性、表现力、可微分性和易于适应数据的特点。
4.2 拟合SMPL-X到单张图片(SMPLify)
为了使SMPL-X适合单个RGB图像(SMPLify- x),本文遵循SMPLify,但改进了它的各个方面。将SMPL-X拟合到图像作为一个优化问题,寻求目标函数的最小值:
其中 \(\theta_b\) , \(\theta_f\) 和 \(m_h\) 分别为身体,人脸和双手的姿态向量,\(\theta\) 是可优化的位姿参数的完整集合。身体姿态参数可以表示为 \(\theta_b(Z)\) ,其中 \(Z\in \mathbb{R}^{32}\) 低维空间构成。EJ(β,θ,K, Jest)为数据项,其中 \(E_{J}\left(\beta, \theta, K, J_{e s t}\right)\) 为数据项,\(E_{m_{h}}\left(m_{h}\right), E_{\theta_{f}}\left(\theta_{f}\right), E_{\beta}(\beta)\) 和 \(E_{\mathcal{E}}(\psi)\) 对手姿、面部姿、体型和面部表情的 \(L_2\)先验,对偏离中性状态者进行惩罚。由于SMPL-X的形状空间是根据单位方差进行缩放的,\(E_{\beta}(\beta)= ||\beta||^2\) 描述了SMPL-X训练数据集中被优化的形状参数与形状分布之间的马氏距离( Mahalanobis distance)。一种简单的优先惩罚方式为: \(E_{\alpha}\left(\theta_{b}\right)=\sum_{i \in(\text {elbows,knees})} \exp \left(\theta_{i}\right)\) ,只适用于肘部和膝盖的极端弯曲。
对于数据项,使用重投影损失来最小化估计的2D关节点 \(J_{est}\) 和SMPL-X每个3D关键点 \(R_{\theta}(J(\beta))_i\) 的2D投影的加权鲁棒距离,其中 \(R_θ(·)\) 是沿着运动学变换关节的函数。数据项的表达式为:
其中 \(\Pi_{K}\) 表示具有固有摄像机参数 \(K\) 的3D到2D投影,OpenPose提供在同一图像上的身体、手、脸和脚的关键点。为了考虑检测中的噪声,每个节点在数据项中的贡献由检测置信度评分 $ \omega_{i}$ 加权,\(\gamma_{i}\) 为退火优化的每个节点的权重,\(\rho\) 表示用于降低加权噪声检测的鲁棒吉曼-麦克卢尔误差函数( Geman-McClure)。
4.3 人体姿态先验
本文寻求一个先验身体姿势,惩罚不可能的姿势。SMPLify使用一种近似负对数的高斯混合模型训练的MoCap数据。虽然SMPLify先验是有效的,但我们发现SMPLify先验不够强。因此,使用变分自动编码器来训练身体姿态先验VPoser,它学习了人体姿态的潜在表示,并将潜在信息的分布正则化为正态分布。
上述公式(4)中 \(Z\in \mathbb{R}^{32}\) 是自编码网络的隐藏空间,\(R\in SO(3)\) 为每个关节 \(3\times 3\) 旋转矩阵作为网络输入和\(\hat{R}\) 代表的输出是一个形状相似矩阵。公式(4)中第二项为KL散度项,第三项为重建项,第四项和第五项引导潜在空间编码有效旋转矩阵。最后一项通过控制较小的网络权值 \(φ\) 防止过拟合。
4.4 碰撞惩罚
当将模型拟合到观测值时,常常有人体若干部位的自碰撞和穿透对于身体结构来说是不可能的。受到
SMPLify启发,用基于形状基元的碰撞模型来惩罚穿透。虽然这个模型计算效率很高,但它只是对人体的粗略近似。对于SMPL-X这样的模型,它也能模拟手指和面部细节,需要更精确的碰撞模型。为此,采用了采用了更为准确的碰撞的网格模型。首先通过使用边界体积层次结构(BVH)检测碰撞三角形 \(\mathcal{C}\) ,然后计算由三角形 \(\mathcal{C}\)和它们的法线 \(n\) 定义局部圆锥3D距离场 \(\Psi\)。穿透根据侵入的深度来惩罚,有效地由距离场中的位置来计算。对于两个碰撞的三角形 \(f_s\) 和 \(f_t\),入侵是双向的;\(f_t\) 的顶点 \(v_t\) 是距离场 \(\Psi_{f_s}\) 里的入侵者,反之亦然。
4.5 性别分类器
男人和女人有不同的比例和形状。因此,使用适当的身体模型来拟合2D数据意味着应该应用适当的形状空间。目前还没有一种方法能够自动将性别因素考虑到三维人体姿势的拟合中。在本工作中,训练一个性别分类器,j将全身和OpenPose关节的图像作为输入,并给被检测到的人分配一个性别标签。
4.6 速度优化
SMPLify采用了Chumpy和OpenDR,这使得优化速度变慢。为了保持优化易于处理,本文使用PyTorch和带有强Wolfe线性搜索的有限内存的BFGS优化器(L-BFGS) 。
5. 实验验证
5.1 数据集
数据集Expressive hands and faces dataset (EHF)。
5.2 实验对比
为了测试SMPL- x和SMPLify-X的有效性,本文与最相关的模型SMPL、SMPL+H和Frank进行比较,同时在EHF数据集上做了一组消融实验分析每个模块对整体精度的影响。


下图是在LSP数据集上SMPL-X的结果。一个强大的整体模型SMPL-X对身体、手和脸的自然富有表现力的重建。灰色显示了性别特征。蓝色表示性别分类器不确定。

6. 实验结论
在这项工作中,本文提出了SMPL-X模型联合捕捉身体,人脸和手。此外,本文还提出了SMPLify-X方法,通过SMPL-X拟合到单个RGB图像和2D关键点的方法。本文利用一种新的强大的身体姿态先验和一种快速准确的检测和惩罚渗透的方法,对歧义下的拟合进行了正则化处理。本文使用自然图像提供了广泛的定性结果,展示了SMPL-X的表达能力和SMPLify-X的有效性。本文引入了一个具有伪真实的数据集来进行定量评估,这表明了更具表现力的模型的重要性。在未来的工作中,本文将创建一个SMPL-X拟合的数据集,并用回归器来直接从RGB图像回归SMPL-X参数。本文相信,这项工作是向从RGB图像中表达捕捉身体、手和脸的重要一步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号